


Paper title:
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
Paper author:
Peijin Jia, Tuopu Wen, Ziang Luo, Mengmeng Yang, Kun Jiang, Zhiquan Lei, Xuewei Tang, Ziyuan Liu, Le Cui, Kehua Sheng, Bo Zhang, Diange Yang
For self-driving vehicles, high-definition (HD) maps can help improve the accuracy of their understanding (perception) of the environment. and navigation accuracy. However, manual mapping faces the problems of complexity and high cost. To this end, the current research integrates map construction into the BEV (bird's eye view) perception task. Constructing a rasterized HD map in the BEV space is regarded as a segmentation task, which can be understood as adding the use of something similar to FCN (full volume) after obtaining BEV features. segmentation head of the product network). For example, HDMapNet encodes sensor features via LSS (Lift, Splat, Shoot), and then employs multi-resolution FCN for semantic segmentation, instance detection, and direction prediction to build a map.
However, current such methods (pixel-based classification methods) still have inherent limitations, including the possibility of ignoring certain classification attributes, which may lead to distortion and interruption of medians and blurred pedestrian crossings. and other types of artifacts and noise, as shown in Figure 1(a). These problems not only affect the structural accuracy of the map, but may also directly affect the downstream path planning module of the autonomous driving system.
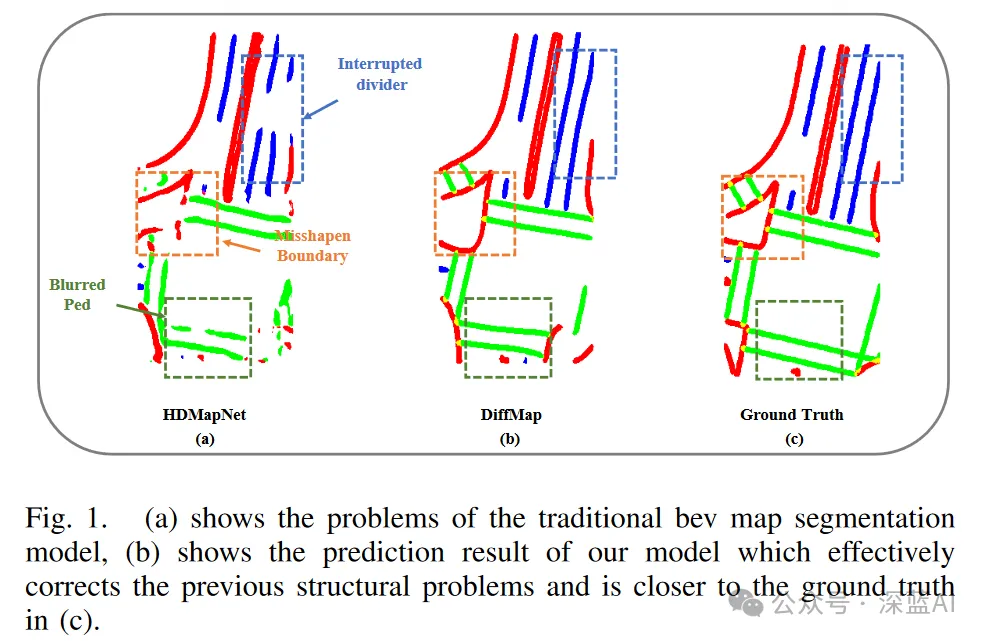
##▲Figure 1|Comparison of the effects of HDMapNet, DiffMap and GroundTruth
Therefore, it is best for the model to Consider the structural prior information of the HD map, such as the parallel and straight characteristics of lane lines. Some generative models have this ability in capturing the authenticity and inherent characteristics of images. For example, LDM (Latent Diffusion Model) has shown great potential in high-fidelity image generation and proven its effectiveness in tasks related to segmentation enhancement. In addition, control variables can be introduced to further guide image generation to meet specific control requirements. Therefore, applying generative models to capture map structure priors is expected to reduce segmentation artifacts and improve map construction performance.
In this article, the author mentions DiffMap network. For the first time, this network performs map-structured prior modeling on existing segmentation models and supports plug-and-play by using improved LDM as an enhancement module. DiffMap not only learns the map prior through the process of adding and removing noise to ensure that the output matches the current frame observation, it can also integrate BEV features as a control signal to ensure that the output matches the current frame observation. Experimental results show that DiffMap can effectively generate smoother and more reasonable map segmentation results, while greatly reducing artifacts and improving the overall map construction performance.
02 Related Work2.1 Semantic Map Construction
In traditional High Definition (HD) In map construction, semantic maps are usually manually or semi-automatically annotated based on lidar point clouds. Generally, a globally consistent map is constructed based on the SLAM algorithm, and semantic annotations are manually added to the map. However, this approach is time-consuming and labor-intensive and also presents significant challenges in updating the map, thus limiting its scalability and real-time performance.
HDMapNet proposes a method to dynamically build local semantic maps using on-board sensors. It encodes lidar point cloud and panoramic image features into Bird's Eye View (BEV) space and decodes them using three different heads, ultimately producing a vectorized local semantic map. SuperFusion focuses on building long-range high-precision semantic maps, using lidar depth information to enhance image depth estimation, and using image features to guide long-range lidar feature prediction. Then a map detection head similar to HDMapNet is used to obtain the semantic map. MachMap divides the task into polyline detection and polygon instance segmentation, and uses post-processing to refine the mask to obtain the final result. Subsequent research focuses on end-to-end online mapping to directly obtain vectorized high-definition maps. The dynamic construction of semantic maps without manual annotation effectively reduces construction costs.
2.2 Diffusion model applied to segmentation and detection
Denoising diffusion probabilistic models (DDPMs) are based on Marko A type of generative model based on husband chains, which has shown excellent performance in fields such as image generation, and has gradually been extended to various tasks such as segmentation and detection. SegDiff applies the diffusion model to the image segmentation task, where the UNet encoder used is further decoupled into three modules: E, F and G. Modules G and F encode the input image I and segmentation map respectively, which are then additively merged in E to iteratively refine the segmentation map. DDPMS uses a base segmentation model to generate an initial prediction prior and a diffusion model to refine the prior. DiffusionDet extends the diffusion model to the target detection framework and models target detection as a denoising diffusion process from the noise box to the target box.
Diffusion models are also used in the field of autonomous driving. For example, MagicDrive uses geometric constraints to synthesize street scenes, and Motiondiffuser extends the diffusion model to multi-agent motion prediction problems.
2.3 Map Prior
There are currently several methods that use a priori information (including explicit criteria map information and implicit time information) to enhance model robustness and reduce uncertainty in vehicle sensors. MapLite2.0 takes the standard definition (SD) prior map as the starting point and combines it with on-board sensors to infer local high-definition maps in real time. MapEx and SMERF leverage standard map data to improve lane awareness and topological understanding. SMERF adopts a Transformer-based standard map encoder to encode lane lines and lane types, and then calculates the cross-attention between the standard map information and sensor-based bird's-eye view (BEV) features to integrate the standard map information. NMP provides long-term memory capabilities for autonomous vehicles by combining past map prior data with current perception data. MapPrior combines discriminative and generative models, encoding preliminary predictions generated based on existing models as priors during the prediction phase, injecting the discrete latent space of the generative model, and then using the generative model to refine predictions. PreSight uses data from previous trips to optimize the city-scale neural radiation field, generate neural priors, and enhance online perception in subsequent navigation.
3.1 Preparation


3.2 Overall architecture
As shown in Figure 2. As a decoder, DiffMap incorporates the diffusion model into the semantic map segmentation model, which takes surrounding multi-view images and LiDAR point clouds as input, encodes them into BEV space and obtains fused BEV features. Then DiffMap is used as the decoder to generate segmentation maps. In the DiffMap module, BEV features are used as conditions to guide the denoising process.
 ▲Figure 2|DiffMap architecture ©️[Deep Blue AI] Compilation
▲Figure 2|DiffMap architecture ©️[Deep Blue AI] Compilation
◆Baseline of semantic map construction:The baseline mainly follows the BEV encoder-decoder paradigm. The encoder part is responsible for extracting features from the input data (LiDAR and/or camera data) and converting it into a high-dimensional representation. At the same time, the decoder usually acts as a segmentation head to map high-dimensional feature representations to corresponding segmentation maps. Baselines play two main roles in the overall framework: supervisor and controller. As a supervisor, the baseline generates segmentation results as auxiliary supervision. At the same time, as a controller, it provides intermediate BEV characteristics as conditional control variables to guide the generation process of the diffusion model.
◆DiffMap module: Following LDM, the author introduces the DiffMap module as a decoder in the baseline framework. LDM mainly consists of two parts: an image-aware compression module (such as VQVAE) and a diffusion model built using UNet. First, the encoder encodes the map segmentation ground truth into the latent space, where represents the low dimension of the latent space. Subsequently, diffusion and denoising are performed in a low-dimensional latent variable space, and a decoder is used to restore the latent space to the original pixel space.
First add noise through a diffusion process, and obtain a noise potential map at each time step, where. Then during the denoising process, UNet serves as the backbone network for noise prediction. In order to enhance the supervision part of the segmentation results, it is expected that the DiffMap model directly provides semantic features for instance-related predictions during training. Therefore, the author divides the UNet network structure into two branches, one branch is used to predict noise, such as the traditional diffusion model, and the other branch is used to predict noise in the latent space.
As shown in Figure 3. After obtaining the latent map prediction, it is decoded into the original pixel space as a semantic feature map. Then the instance predictions can be obtained from them according to the method proposed by HDMapNet, and the predictions of three different heads can be output: semantic segmentation, instance embedding and lane direction. These predictions are then used in a post-processing step to vectorize the map.

▲Figure 3|Denoising module
The entire process is a conditional generation process, and the map segmentation results are obtained based on the current sensor input. The probability distribution of the result can be modeled as, where represents the map segmentation result and represents the conditional control variable, that is, the BEV feature. The author uses two methods to integrate control variables here. First, since the BEV and BEV features have the same category and scale in the spatial domain, they will be adjusted to the latent space size, and then they are concatenated as the input of the denoising process, as shown in Equation 5.
Secondly, the cross-attention mechanism is integrated into each layer of the UNet network, as key/value and query. The formula of the cross-attention module is as follows:
3.3 Specific implementation
◆Training:

##◆Inference:

4.1 Experiment details
◆Dataset:In nuScenes dataset Verify DiffMap on. The nuScenes dataset contains multi-view images and point clouds of 1000 scenes, of which 700 scenes are used for training, 150 for validation, and 150 for testing. The nuScenes dataset also contains annotated HD map semantic labels.
◆Architecture: Use ResNet-101 as the backbone network of the camera branch, and use PointPillars as the LiDAR branch backbone network of the model. The segmentation head in the baseline model is a ResNet-18 based FCN network. For the autoencoder, VQVAE is employed, and the model is pre-trained on the nuScenes segmented map dataset to extract map features and compress the map into a base latent space. Finally, UNet is used to build the diffusion network.
◆Training details: Use the AdamW optimizer to train the VQVAE model for 30 epochs. The learning rate scheduler used is LambdaLR, which gradually reduces the learning rate in exponential decay mode with a decay factor of 0.95. The initial learning rate is set to , and the batch size is 8. Then, the diffusion model was trained from scratch using the AdamW optimizer for 30 epochs with an initial learning rate of 2e-4. The MultiStepLR scheduler is adopted, which adjusts the learning rate according to specified milestone time points (0.7, 0.9, 1.0) and a scaling factor of 1/3 at different training stages. Finally, the BEV segmentation result is set to a resolution of 0.15m, and the LiDAR point cloud is voxelized. The detection range of HDMapNet is [-30m, 30m]×[-15m, 15m]m, so the corresponding BEV map size is 400×200, while Superfusion uses [0m, 90m]×[-15m, 15m] and gets 600× 200 results. Due to the dimensionality constraints of LDM (8x downsampling in VAE and UNet), the size of the semantic ground truth map needs to be padded to a multiple of 64.
◆Inference details: The prediction results are obtained by performing the denoising process on the noise map 20 times under the current BEV feature conditions. The average of 3 samples is used as the final prediction result.
4.2 Evaluation indicators
Mainly conducts flat evaluations on map semantic segmentation and instance detection tasks. And it mainly focuses on three static map elements: lane boundaries, lane dividers and pedestrian crossings.


#4.3 Evaluation results
Table 1 shows the IoU score comparison for semantic map segmentation. DiffMap shows significant improvements in all intervals, achieving the best results especially on lane dividers and pedestrian crossings.
▲Table 1|IoU score comparison
▲Table 2|MAP score comparison As shown in Table 3, when the DiffMap paradigm is integrated into HDMapNet, it can be observed that DiffMap can improve the performance of HDMapNet whether using only the camera or the camera-lidar fusion method. This shows that the DiffMap method is effective in various segmentation tasks, including long-range and short-range detection. However, for boundaries, the performance of DiffMap is not good. This is because the shape structure of the boundary is not fixed and there are many unpredictable distortions, which makes it difficult to capture a priori structural features. 4.4 Ablation experiment Table 4 shows the impact of different downsampling factors in VQVAE on the detection results. By analyzing the behavior of DiffMap when the downsampling factor is 4, 8, and 16, we can see that when the downsampling factor is set to 8x, the best results are obtained. In addition, the author also measured the effect of deleting the prediction module related to the instance on the model The impact is shown in Table 5. Experiments show that adding this prediction further improves IOU. ▲Table 5|Ablation experiment results (whether prediction module is included) 4.5 Visualization #Figure 4 shows the comparison between DiffMap and the baseline (HDMapNet-fusion) in complex scenes. It is obvious that the baseline segmentation results ignore the shape properties and consistency within the elements. In contrast, DiffMap demonstrates the ability to correct for these issues, producing segmentation output that is well aligned with the map specification. Specifically, in cases (a), (b), (d), (e), (h), and (l), DiffMap effectively corrects inaccurately predicted crosswalks. In cases (c), (d), (h), (i), (j), and (l), DiffMap completes or removes inaccurate boundaries, making the results closer to realistic boundary geometries. Furthermore, in cases (b), (f), (g), (h), (k) and (l), DiffMap solves the problem of broken dividing lines and ensures the parallelism of adjacent elements. In this article, the author The designed DiffMap network is a new method that utilizes the latent diffusion model to learn map structure priors, thereby enhancing the traditional map segmentation model. This method can be used as an auxiliary tool for any map segmentation model, and its prediction results are significantly improved in both far and near detection scenarios. Since this method is highly scalable, it is suitable for studying other types of prior information. For example, the SD map prior can be integrated into the second module of DiffMap to enhance its performance. It is expected that progress in vectorized map construction will continue in the future. 
 ▲Table 3|Quantitative analysis results
▲Table 3|Quantitative analysis results ▲Table 4|Ablation experiment results
▲Table 4|Ablation experiment results
 ▲Figure 4|Qualitative analysis results
▲Figure 4|Qualitative analysis results05 Summary and future prospects
The above is the detailed content of DiffMap: the first network to use LDM to enhance high-precision map construction. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



