


Purely visual annotation scheme mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution.
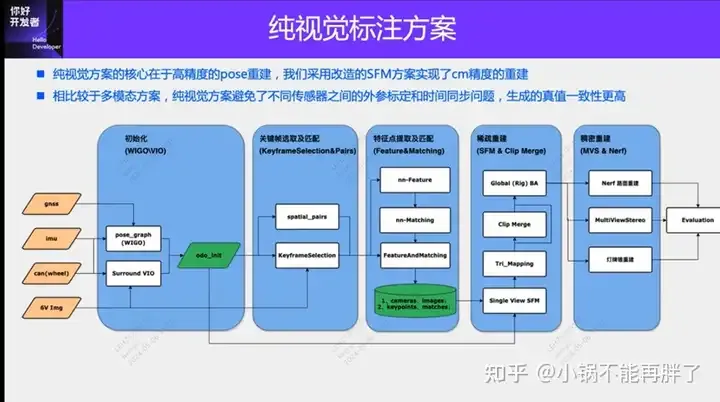
The core of the purely visual annotation solution lies in high-precision pose reconstruction. We use the Structure from Motion (SFM) pose reconstruction scheme to ensure reconstruction accuracy. However, traditional SFM, especially incremental SFM, is very slow and expensive in computational complexity. The computational complexity is O(n^4), where n is the number of images. This kind of reconstruction efficiency is unacceptable for data annotation of large-scale models. We have made some improvements to the SFM solution.
The improved clip reconstruction is mainly divided into three modules: 1) Use multi-sensor data, GNSS, IMU and wheel speedometer to construct pose_graph optimization and obtain the initial pose. We call this algorithm For Wheel-Imu-GNSS-Odometry (WIGO); 2) Feature extraction and matching of images, and triangulation directly using the initialized pose to obtain the initial 3D points; 3) Finally, a global BA (Bundle Adjustment) is performed. On the one hand, our solution avoids incremental SFM. On the other hand, different clips can implement parallel operations, thus greatly improving the efficiency of pose reconstruction. Compared with the existing incremental reconstruction, Efficiency improvements of 10 to 20 times can be achieved.
During the single reconstruction process, our solution has also made some optimizations. For example, we use Learning based features (Superpoint and Superglue), one is the feature point and the other is the matching method , to replace the traditional SIFT key points. The advantage of learning NN-Features is that on the one hand, rules can be designed in a data-driven manner to meet some customized needs and improve the robustness in some weak textures and dark lighting conditions; on the other hand, it can improve Efficiency of keypoint detection and matching. We have done some comparative experiments and found that the success rate of NN-features in night scenes will be approximately 4 times higher than that of SFIT, from 20% to 80%.
After obtaining the reconstruction result of a single Clip, we will aggregate multiple clips. Different from the existing HDmap mapping structure matching scheme, in order to ensure the accuracy of aggregation, we adopt feature point level aggregation, that is, the aggregation constraints between clips are carried out through the matching of feature points. This operation is similar to loop closure detection in SLAM. First, GPS is used to determine some candidate matching frames; then, feature points and descriptions are used to match images; finally, these loop closure constraints are combined to construct a global BA (Bundle Adjustment) and optimize. At present, the accuracy and RTE index of our solution far exceed some existing visual SLAM or mapping solutions.
Experiment: Use the colmap cuda version, use 180 pictures, 3848*2168 resolution, manually set internal parameters, and use the default settings for the rest. The sparse reconstruction takes about 15 minutes, and the entire dense reconstruction takes an extremely long time (1- 2h)
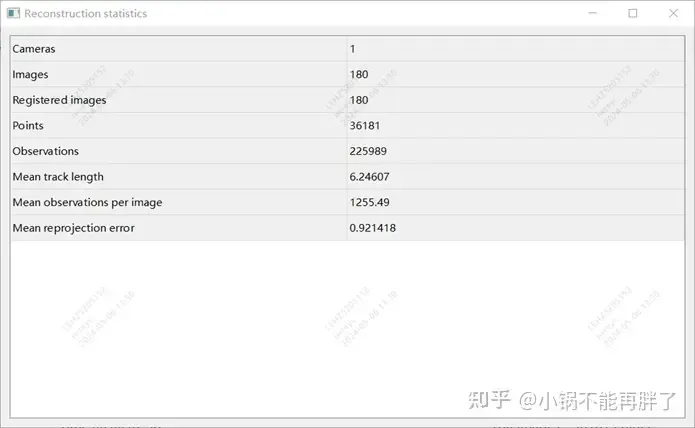
Reconstruction result statistics
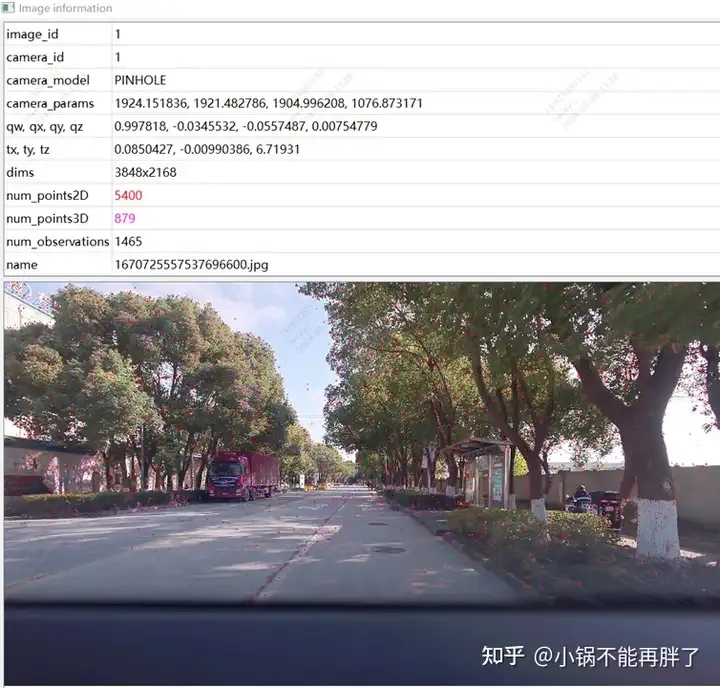
Feature point diagram

sparse reconstruction effect

Overall effect of the straight section

Ground cone effect

Effect of speed limit sign at height

Effect of intersection zebra crossing
It is easy to not converge, I tried another set of images There is no convergence: static ego filtering, forming a clip every 50-100m according to the movement of the vehicle; dynamic point filtering in high-dynamic scenes, tunnel scene pose
Use circumferential and panoramic multi-cameras: feature point matching map optimization, internal and external parameter optimization items, and use of existing odom.
https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
pyceres.solve(solver_options, bundle_adjuster.problem, summary)
3DGS accelerates dense reconstruction, otherwise it will take too long to accept
The above is the detailed content of The first pure visual static reconstruction of autonomous driving. For more information, please follow other related articles on the PHP Chinese website!
 Minimum configuration requirements for win10 system
Minimum configuration requirements for win10 system
 The difference between console cable and network cable
The difference between console cable and network cable
 How to implement color fonts in css
How to implement color fonts in css
 Rename the apk software
Rename the apk software
 Windows cannot configure this wireless connection
Windows cannot configure this wireless connection
 Introduction to the difference between javascript and java
Introduction to the difference between javascript and java
 Top ten digital currency exchanges
Top ten digital currency exchanges
 What does win11 activation status activity mean?
What does win11 activation status activity mean?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



