Insgesamt10000 bezogener Inhalt gefunden

Call for Papers丨IJCAI'23 Large Model Forum, hervorragende Einreichungen werden zur Veröffentlichung in AI Open und JCST empfohlen
Artikeleinführung:Im ersten Call for Papers des LLM@IJCAI'23Symposiums werden herausragende eingereichte Paper zur Veröffentlichung in „AIOpen“ und „JCST“ empfohlen. Large-Scale Language Models (LLMs) wie ChatGPT und GPT-4 haben den Bereich der künstlichen Intelligenz mit ihren überlegenen Fähigkeiten beim Verstehen und Generieren natürlicher Sprache revolutioniert. LLMs werden häufig in verschiedenen Anwendungen verwendet, beispielsweise in Sprachassistenten, Empfehlungssystemen, Inhaltsgenerierungsmodellen (wie ChatGPT) und Text-zu-Bild-Modellen (wie Dall-E) usw. Diese leistungsstarken Modelle stellen jedoch auch erhebliche Herausforderungen für ihren sicheren und ethischen Einsatz dar. Wie stellen wir sicher, dass LLMs fair, sicher, die Privatsphäre schützend, erklärbar und kontrollierbar sind? Bereitstellung von a. akademischen Forschern und Praktikern aus der Industrie
2023-05-27
Kommentar 0
945
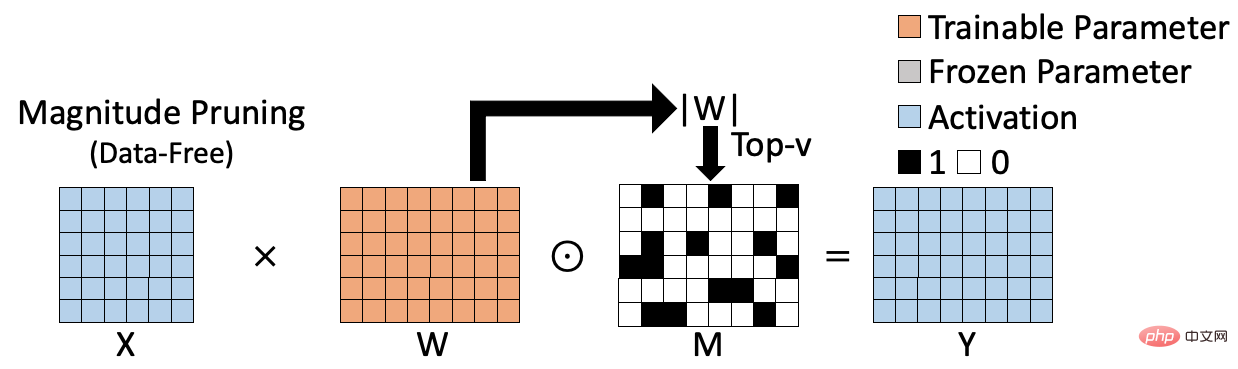
Diese spärliche Trainingsmethode für große Modelle mit hoher Genauigkeit und geringem Ressourcenverbrauch wurde gefunden.
Artikeleinführung:Kürzlich wurde der Artikel „Parameter-Efficient Sparsity for Large Language Models Fine-Tuning“ von Alibaba Cloud Machine Learning PAI zum Sparse-Training großer Modelle von der IJCAI 2022, der führenden Konferenz für künstliche Intelligenz, angenommen. Das Papier schlägt einen Parameter-effizienten Sparse-Trainingsalgorithmus PST vor. Durch die Analyse des Wichtigkeitsindex von Gewichten wird der Schluss gezogen, dass er zwei Merkmale aufweist: niedrigen Rang und Struktur. Basierend auf dieser Schlussfolgerung führt der PST-Algorithmus zwei Sätze kleiner Matrizen ein, um die Wichtigkeit von Gewichten zu berechnen. Im Vergleich dazu ist eine Matrix erforderlich, die so groß ist wie das Gewicht, um den Wichtigkeitsindex zu speichern und die Menge an Parametern zu aktualisieren Aktualisierung für spärliches Training ist stark reduziert. Vergleichen Sie häufig verwendete Sparse-Trainings
2023-04-13
Kommentar 0
1420
So installieren Sie das Win7-Betriebssystem auf dem Computer
Artikeleinführung:Unter den Computer-Betriebssystemen ist das WIN7-System ein sehr klassisches Computer-Betriebssystem. Wie installiert man also das Win7-System? Der folgende Editor stellt detailliert vor, wie Sie das Win7-System auf Ihrem Computer installieren. 1. Laden Sie zunächst das Xiaoyu-System herunter und installieren Sie die Systemsoftware erneut auf Ihrem Desktop-Computer. 2. Wählen Sie das Win7-System aus und klicken Sie auf „Dieses System installieren“. 3. Beginnen Sie dann mit dem Herunterladen des Image des Win7-Systems. 4. Stellen Sie nach dem Herunterladen die Umgebung bereit und klicken Sie nach Abschluss auf Jetzt neu starten. 5. Nach dem Neustart des Computers erscheint die Windows-Manager-Seite. Wir wählen die zweite. 6. Kehren Sie zur Pe-Schnittstelle des Computers zurück, um die Installation fortzusetzen. 7. Starten Sie nach Abschluss den Computer neu. 8. Kommen Sie schließlich zum Desktop und die Systeminstallation ist abgeschlossen. Ein-Klick-Installation des Win7-Systems
2023-07-16
Kommentar 0
1157
PHP-Einfügesortierung
Artikeleinführung::Dieser Artikel stellt hauptsächlich die PHP-Einfügesortierung vor. Studenten, die sich für PHP-Tutorials interessieren, können darauf zurückgreifen.
2016-08-08
Kommentar 0
1010
图解找出PHP配置文件php.ini的路径的方法,_PHP教程
Artikeleinführung:图解找出PHP配置文件php.ini的路径的方法,。图解找出PHP配置文件php.ini的路径的方法, 近来,有不博友问php.ini存在哪个目录下?或者修改php.ini以后为何没有生效?基于以上两个问题,
2016-07-13
Kommentar 0
761

Huawei bringt zwei neue kommerzielle KI-Speicherprodukte großer Modelle auf den Markt, die eine Leistung von 12 Millionen IOPS unterstützen
Artikeleinführung:IT House berichtete am 14. Juli, dass Huawei kürzlich neue kommerzielle KI-Speicherprodukte „OceanStorA310 Deep Learning Data Lake Storage“ und „FusionCubeA3000 Training/Pushing Hyper-Converged All-in-One Machine“ herausgebracht habe. Beamte sagten, dass „diese beiden Produkte grundlegendes Training ermöglichen“. KI-Modelle, Branchenmodelltraining, segmentiertes Szenariomodelltraining und Inferenz sorgen für neuen Schwung.“ ▲ Bildquelle Huawei IT Home fasst zusammen: OceanStorA310 Deep Learning Data Lake Storage ist hauptsächlich auf einfache/industrielle große Modell-Data-Lake-Szenarien ausgerichtet, um eine Datenregression zu erreichen . Umfangreiches Datenmanagement im gesamten KI-Prozess von der Erfassung und Vorverarbeitung bis hin zum Modelltraining und der Inferenzanwendung. Offiziell erklärt, dass OceanStorA310 Single Frame 5U die branchenweit höchsten 400 GB/s unterstützt
2023-07-16
Kommentar 0
1487


