


Multimodale KI-Systeme zeichnen sich durch ihre Fähigkeit aus, verschiedene Arten von Daten, einschließlich natürlicher Sprache, Bild, Audio usw., zu verarbeiten und zu lernen, um ihre Verhaltensentscheidungen zu steuern. In jüngster Zeit hat die Forschung zur Integration visueller Daten in große Sprachmodelle (wie GPT-4V) wichtige Fortschritte gemacht, aber die Frage, wie Bildinformationen effektiv in ausführbare Operationen für KI-Systeme umgewandelt werden können, steht immer noch vor Herausforderungen. Um die Transformation von Bildinformationen zu erreichen, besteht eine gängige Methode darin, Bilddaten in entsprechende Textbeschreibungen umzuwandeln, woraufhin das KI-System auf der Grundlage der Beschreibungen arbeitet. Dies kann durch überwachtes Lernen an vorhandenen Bilddatensätzen erfolgen, wodurch das KI-System die Bild-zu-Text-Zuordnungsbeziehung automatisch lernen kann. Darüber hinaus kann mit Methoden des Reinforcement Learning auch gelernt werden, Entscheidungen auf Basis von Bildinformationen durch Interaktion mit der Umgebung zu treffen. Eine andere Methode besteht darin, Bildinformationen direkt mit einem Sprachmodell zu kombinieren, um
In einem kürzlich erschienenen Artikel schlugen Forscher ein multimodales Modell vor, das speziell für KI-Anwendungen entwickelt wurde, und führten das Konzept des „funktionalen Tokens“ ein.
Papiertitel: Octopus v3: Technischer Bericht für On-Device Sub-Billion Multimodal AI Agent
Papierlink: https://arxiv.org/pdf/2404.11459.pdf
Modellgewichte und Inferenz Code: https://www.nexa4ai.com/apply
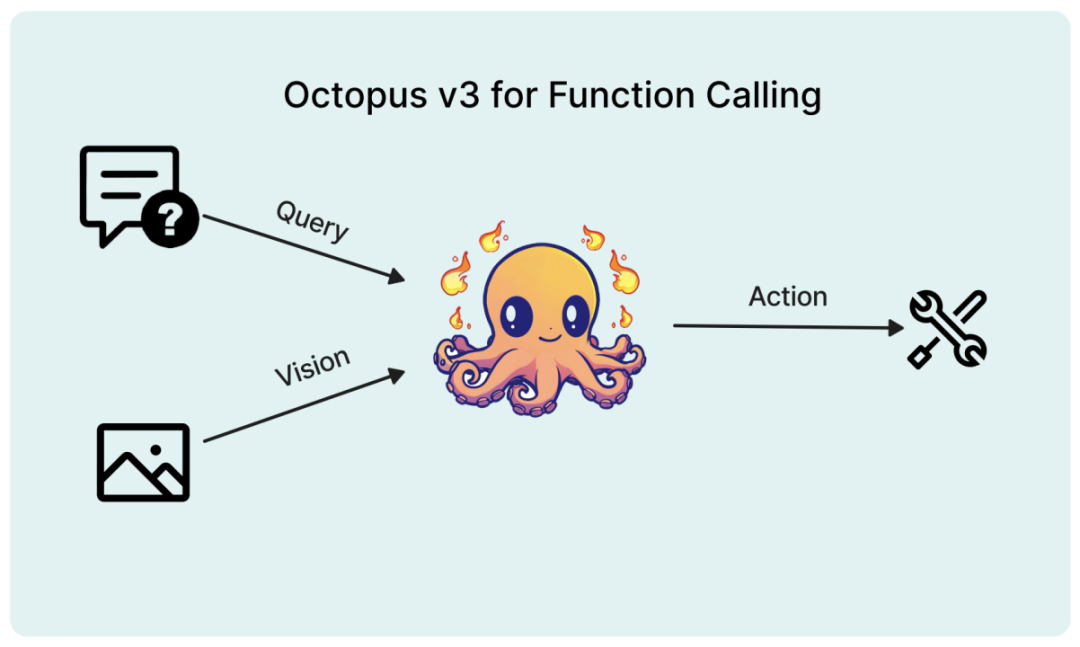
Dieses Modell kann Edge-Geräte vollständig unterstützen, und Forscher haben seine Parametermenge auf innerhalb von 1 Milliarde optimiert. Ähnlich wie GPT-4 beherrscht dieses Modell sowohl Englisch als auch Chinesisch. Experimente haben gezeigt, dass das Modell auf verschiedenen ressourcenbeschränkten Endgeräten, einschließlich Raspberry Pi, effizient laufen kann.
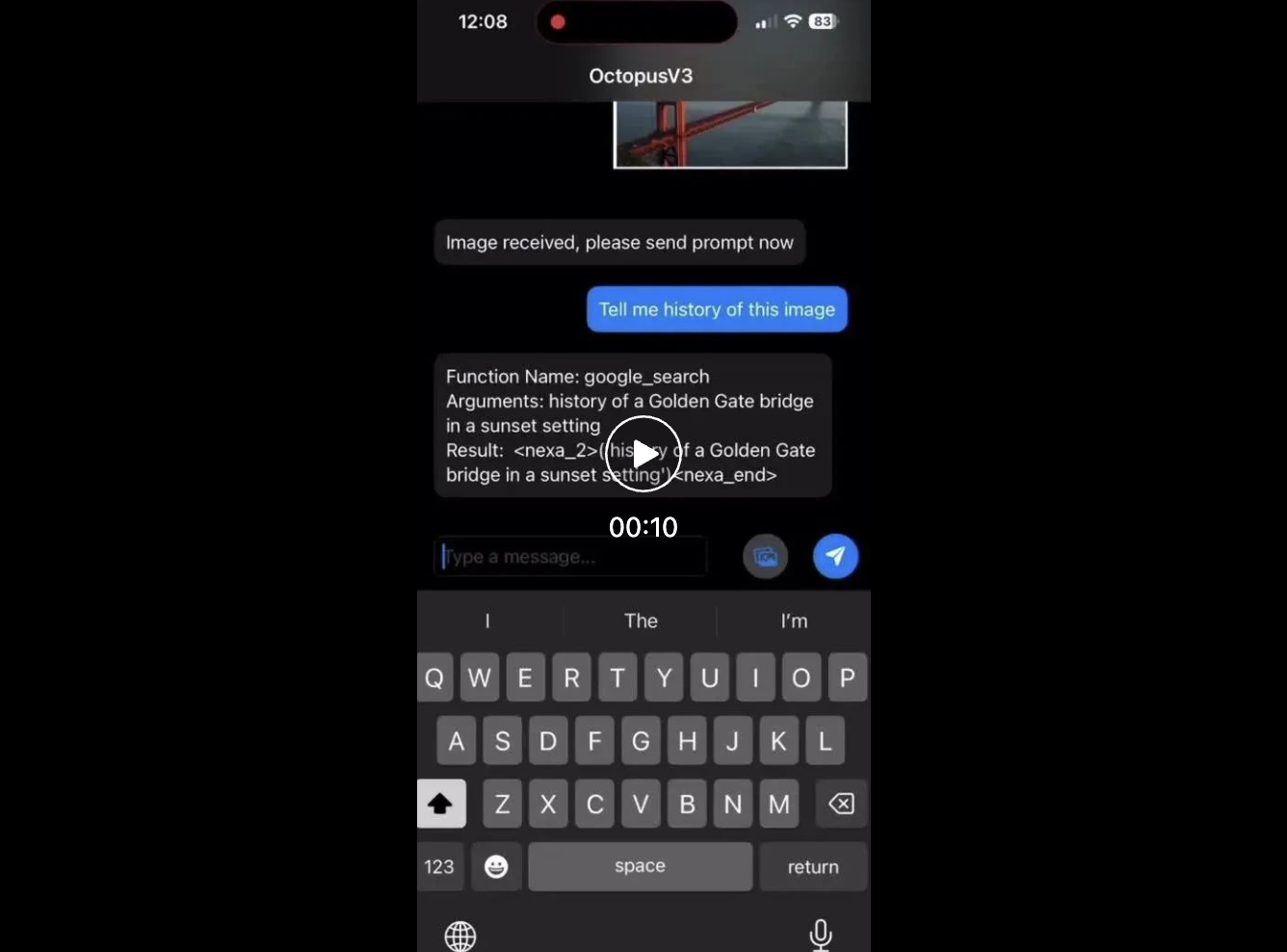
Forschungshintergrund
Die rasante Entwicklung der Technologie der künstlichen Intelligenz hat die Art und Weise der Mensch-Computer-Interaktion völlig verändert und eine Reihe intelligenter KI-Systeme hervorgebracht, die komplexe Aufgaben ausführen und Entscheidungen auf der Grundlage verschiedener Eingabeformen wie natürlicher Sprache und Vision treffen können. Von diesen Systemen wird erwartet, dass sie alles automatisieren, von einfachen Aufgaben wie Bilderkennung und Sprachübersetzung bis hin zu komplexen Anwendungen wie medizinische Diagnose und autonomes Fahren. Multimodale Sprachmodelle bilden den Kern dieser intelligenten Systeme und ermöglichen es ihnen, durch die Verarbeitung und Integration multimodaler Daten wie Text, Bilder und sogar Audio und Video menschennahe Antworten zu verstehen und zu generieren. Im Vergleich zu traditionellen Sprachmodellen, die sich hauptsächlich auf die Textverarbeitung und -generierung konzentrieren, stellen multimodale Sprachmodelle einen großen Fortschritt dar. Durch die Einbeziehung visueller Informationen sind diese Modelle in der Lage, den Kontext und die Semantik der Eingabedaten besser zu verstehen, was zu einer genaueren und relevanteren Ausgabe führt. Die Fähigkeit, multimodale Daten zu verarbeiten und zu integrieren, ist von entscheidender Bedeutung für die Entwicklung multimodaler KI-Systeme, die gleichzeitig Aufgaben wie Sprache und visuelle Informationen verstehen können, beispielsweise visuelle Beantwortung von Fragen, Bildnavigation, multimodale Stimmungsanalyse usw.
Eine der Herausforderungen bei der Entwicklung multimodaler Sprachmodelle besteht darin, visuelle Informationen effektiv in ein Format zu kodieren, das das Modell verarbeiten kann. Dies geschieht in der Regel mit Hilfe neuronaler Netzwerkarchitekturen wie Visual Transformers (ViT) und Convolutional Neural Networks (CNN). Die Fähigkeit, hierarchische Merkmale aus Bildern zu extrahieren, wird häufig bei Computer-Vision-Aufgaben genutzt. Mithilfe dieser Architekturen als Modelle kann man lernen, komplexere Darstellungen aus Eingabedaten zu extrahieren. Darüber hinaus ist die transformatorbasierte Architektur nicht nur in der Lage, Abhängigkeiten über große Entfernungen zu erfassen, sondern leistet auch gute Dienste beim Verständnis der Beziehungen zwischen Objekten in Bildern. In den letzten Jahren sehr beliebt. Diese Architekturen ermöglichen es Modellen, aussagekräftige Merkmale aus Eingabebildern zu extrahieren und sie in Vektordarstellungen umzuwandeln, die mit Texteingaben kombiniert werden können.
Eine weitere Möglichkeit, visuelle Informationen zu kodieren, ist die Bild-Tokenisierung, bei der das Bild in kleinere diskrete Einheiten oder Token unterteilt wird. Dieser Ansatz ermöglicht es dem Modell, Bilder ähnlich wie Text zu verarbeiten, was eine nahtlosere Integration der beiden Modalitäten ermöglicht. Bild-Token-Informationen können zusammen mit der Texteingabe in das Modell eingespeist werden, sodass es sich auf beide Modalitäten konzentrieren und eine genauere und kontextbezogenere Ausgabe erzeugen kann. Beispielsweise verwendet das von OpenAI entwickelte DALL-E-Modell eine Variante von VQ-VAE (Vector Quantized Variational Autoencoder), um Bilder zu symbolisieren, sodass das Modell neuartige Bilder basierend auf Textbeschreibungen generieren kann. Die Entwicklung kleiner, effizienter Modelle, die auf vom Benutzer bereitgestellte Abfragen und Bilder reagieren können, wird tiefgreifende Auswirkungen auf die zukünftige Entwicklung von KI-Systemen haben. Diese Modelle können auf ressourcenbeschränkten Geräten wie Smartphones und IoT-Geräten eingesetzt werden und erweitern so deren Anwendungsbereich und Szenarios. Durch die Nutzung der Leistungsfähigkeit multimodaler Sprachmodelle können diese kleinen Systeme Benutzeranfragen auf natürlichere und intuitivere Weise verstehen und darauf reagieren und dabei den vom Benutzer bereitgestellten visuellen Kontext berücksichtigen. Dies eröffnet die Möglichkeit für ansprechendere, personalisierte Mensch-Maschine-Interaktionen, wie etwa virtuelle Assistenten, die visuelle Empfehlungen basierend auf Benutzerpräferenzen bereitstellen, oder Smart-Home-Geräte, die Einstellungen basierend auf den Gesichtsausdrücken des Benutzers anpassen.
Darüber hinaus wird erwartet, dass die Entwicklung multimodaler KI-Systeme die Technologie der künstlichen Intelligenz demokratisieren und einem breiteren Spektrum von Benutzern und Branchen zugute kommen wird. Kleinere und effizientere Modelle können auf weniger leistungsstarker Hardware trainiert werden, wodurch die für die Bereitstellung erforderlichen Rechenressourcen und der Energieverbrauch reduziert werden. Dies kann zu einer weit verbreiteten Anwendung von KI-Systemen in verschiedenen Bereichen wie medizinischer Versorgung, Bildung, Unterhaltung, E-Commerce usw. führen und letztendlich die Art und Weise, wie Menschen leben und arbeiten, verändern.
Verwandte Arbeit
Multimodale Modelle haben aufgrund ihrer Fähigkeit, mehrere Datentypen wie Text, Bilder, Audio usw. zu verarbeiten und zu lernen, große Aufmerksamkeit auf sich gezogen. Diese Art von Modell kann die komplexen Wechselwirkungen zwischen verschiedenen Modalitäten erfassen und deren komplementäre Informationen nutzen, um die Leistung verschiedener Aufgaben zu verbessern. Vision-Language Pre-Trained (VLP)-Modelle wie ViLBERT, LXMERT, VisualBERT usw. lernen die Ausrichtung von visuellen und Textmerkmalen durch modalübergreifende Aufmerksamkeit, um reichhaltige multimodale Darstellungen zu generieren. Multimodale Transformatorarchitekturen wie MMT, ViLT usw. verfügen über verbesserte Transformatoren zur effizienten Handhabung mehrerer Modalitäten. Forscher haben auch versucht, andere Modalitäten wie Audio- und Gesichtsausdrücke in Modelle zu integrieren, beispielsweise Modelle zur multimodalen Stimmungsanalyse (MSA), Modelle zur multimodalen Emotionserkennung (MER) usw. Durch die Nutzung der komplementären Informationen verschiedener Modalitäten erreichen multimodale Modelle eine bessere Leistung und Generalisierungsfähigkeit als einmodale Methoden.
Terminalsprachmodelle werden als Modelle mit weniger als 7 Milliarden Parametern definiert, da Forscher herausgefunden haben, dass es selbst mit Quantisierung sehr schwierig ist, ein Modell mit 13 Milliarden Parametern auf Edge-Geräten auszuführen. Zu den jüngsten Fortschritten in diesem Bereich gehören Googles Gemma 2B und 7B, Stable Diffusions Stable Code 3B und Metas Llama 7B. Interessanterweise zeigt die Forschung von Meta, dass kleine Sprachmodelle im Gegensatz zu großen Sprachmodellen bei tiefen und schmalen Architekturen eine bessere Leistung erbringen. Weitere Techniken, die für das Terminalmodell von Vorteil sind, umfassen die in MobileLLM vorgeschlagene Einbettungsfreigabe, gruppierte Abfrageaufmerksamkeit und sofortige Blockgewichtsfreigabe. Diese Ergebnisse unterstreichen die Notwendigkeit, bei der Entwicklung kleiner Sprachmodelle für Endanwendungen andere Optimierungsmethoden und Entwurfsstrategien zu berücksichtigen als bei großen Modellen.
Octopus-Methode
Die Haupttechnologie, die bei der Entwicklung des Octopus v3-Modells verwendet wird. Zwei Schlüsselaspekte der multimodalen Modellentwicklung sind die Integration von Bildinformationen mit Texteingaben und die Optimierung der Fähigkeit des Modells, Aktionen vorherzusagen.
Visuelle Informationskodierung
In der Bildverarbeitung gibt es viele Methoden zur Kodierung visueller Informationen, und häufig wird die Einbettung versteckter Ebenen verwendet. Beispielsweise wird die Einbettung versteckter Schichten des VGG-16-Modells für Stilübertragungsaufgaben verwendet. Das CLIP-Modell von OpenAI demonstriert die Fähigkeit, Text- und Bildeinbettungen auszurichten, indem es seinen Bild-Encoder zum Einbetten von Bildern nutzt. Methoden wie ViT nutzen fortschrittlichere Technologien wie die Bild-Tokenisierung. Die Forscher bewerteten verschiedene Bildcodierungstechniken und stellten fest, dass die CLIP-Modellmethode am effektivsten war. Daher verwendet dieser Artikel ein CLIP-basiertes Modell für die Bildcodierung.
Funktions-Token
Ähnlich wie bei der Tokenisierung, die auf natürliche Sprache und Bilder angewendet wird, können bestimmte Funktionen auch als Funktions-Token gekapselt werden. Die Forscher führten eine Trainingsstrategie für diese Token ein, die sich auf die Technologie natürlicher Sprachmodelle zur Verarbeitung unsichtbarer Wörter stützte. Diese Methode ähnelt word2vec und bereichert die Semantik des Tokens durch seinen Kontext. Beispielsweise können Hochsprachenmodelle zunächst Schwierigkeiten mit komplexen chemischen Begriffen wie PEGylierung und Endosomal Escape haben. Aber durch kausale Sprachmodellierung, insbesondere durch Training an einem Datensatz, der diese Begriffe enthält, kann das Modell diese Begriffe lernen. Ebenso können funktionale Token durch parallele Strategien erlernt werden, wobei das Octopus v2-Modell eine leistungsstarke Plattform für solche Lernprozesse bietet. Untersuchungen zeigen, dass der Definitionsraum funktionaler Token unendlich ist, sodass jede spezifische Funktion als Token dargestellt werden kann.
Mehrstufiges Training
Um ein leistungsstarkes multimodales KI-System zu entwickeln, haben Forscher eine Modellarchitektur übernommen, die kausale Sprachmodelle und Bildkodierer integriert. Der Trainingsprozess dieses Modells ist in mehrere Phasen unterteilt. Zunächst werden das kausale Sprachmodell und der Bildkodierer separat trainiert, um ein Grundmodell zu erstellen. Anschließend werden die beiden Komponenten zusammengeführt und ausgerichtet und trainiert, um Bild- und Textverarbeitungsfähigkeiten zu synchronisieren. Auf dieser Basis wird die Methode von Octopus v2 genutzt, um das Lernen funktionaler Token zu fördern. In der letzten Trainingsphase liefern diese funktionalen Token, die mit der Umgebung interagieren, Feedback zur weiteren Optimierung des Modells. Daher haben die Forscher in der letzten Phase das verstärkende Lernen übernommen und ein anderes großes Sprachmodell als Belohnungsmodell ausgewählt. Diese iterative Trainingsmethode verbessert die Fähigkeit des Modells, multimodale Informationen zu verarbeiten und zu integrieren.
Modellbewertung
In diesem Abschnitt werden die experimentellen Ergebnisse des Modells vorgestellt und mit den Auswirkungen der Integration von GPT-4V- und GPT-4-Modellen verglichen. Im Vergleichsexperiment verwendeten die Forscher zunächst GPT-4V (gpt-4-turbo) zur Verarbeitung von Bildinformationen. Die extrahierten Daten werden dann in das GPT-4-Framework (gpt-4-turbo-preview) eingespeist, das alle Funktionsbeschreibungen kontextualisiert und Fear-Shot-Learning anwendet, um die Leistung zu verbessern. In der Demonstration wandelten die Forscher 10 häufig verwendete Smartphone-APIs in funktionale Token um und bewerteten deren Leistung, wie in den folgenden Abschnitten beschrieben.
Es ist erwähnenswert, dass dieser Artikel zwar nur 10 funktionale Token zeigt, das Modell jedoch mehr Token trainieren kann, um ein allgemeineres KI-System zu erstellen. Die Forscher fanden heraus, dass für ausgewählte APIs Modelle mit weniger als 1 Milliarde Parametern als multimodale KI vergleichbar mit der Kombination von GPT-4V und GPT-4 funktionierten.
Darüber hinaus ermöglicht die Skalierbarkeit des Modells in diesem Artikel die Einbeziehung einer breiten Palette funktionaler Token, wodurch hochspezialisierte KI-Systeme erstellt werden können, die für bestimmte Bereiche oder Szenarien geeignet sind. Diese Anpassungsfähigkeit macht unseren Ansatz besonders wertvoll in Branchen wie dem Gesundheitswesen, dem Finanzwesen und dem Kundenservice, wo KI-gesteuerte Lösungen die Effizienz und das Benutzererlebnis erheblich verbessern können.
Unter allen unten aufgeführten Funktionsnamen gibt Octopus zur besseren Demonstration nur Funktionstoken aus, z. B.
E-Mail senden

SMS senden

Google-Suche

Amazon Shopping

Smart Recycling

Verloren und Gefunden

Innenarchitektur
„Instacart Shopping“: „DoorDash Delivery“: „Haustierbetreuung“
Funktions-Token ist derzeit autorisiert. Der Forscher ermutigt Entwickler, sich im Rahmen dieses Artikels zu beteiligen und unter der Voraussetzung der Einhaltung der Lizenzvereinbarung frei zu innovieren. In zukünftigen Forschungen wollen die Forscher einen Trainingsrahmen entwickeln, der zusätzliche Datenmodalitäten wie Audio und Video berücksichtigen kann. Darüber hinaus haben Forscher herausgefunden, dass visuelle Eingaben erhebliche Latenzzeiten verursachen können, und optimieren derzeit die Inferenzgeschwindigkeit.
Das obige ist der detaillierte Inhalt vonWie kann OctopusV3 mit weniger als 1 Milliarde Parametern mit GPT-4V und GPT-4 verglichen werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So beheben Sie einen DNS-Fehler
So beheben Sie einen DNS-Fehler
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 Der Unterschied zwischen großer Funktion und max
Der Unterschied zwischen großer Funktion und max
 Lösung für Sitzungsfehler
Lösung für Sitzungsfehler
 Was sind die ASP-Entwicklungstools?
Was sind die ASP-Entwicklungstools?
 Der Computer ist infiziert und kann nicht eingeschaltet werden
Der Computer ist infiziert und kann nicht eingeschaltet werden
 So kaufen Sie Bitcoin
So kaufen Sie Bitcoin
 Lösung für fehlende xlive.dll
Lösung für fehlende xlive.dll








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



