
Diese Website veröffentlicht Kolumnen mit akademischem und technischem Inhalt. In den letzten Jahren hat die AIxiv-Kolumne dieser Website mehr als 2.000 Berichte erhalten, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Erkunden Sie ein neues Reich des Videoverständnisses, das Mamba-Modell führt einen neuen Trend in der Computer-Vision-Forschung an! Die Einschränkungen traditioneller Architekturen wurden durchbrochen. Das Zustandsraummodell Mamba hat mit seinen einzigartigen Vorteilen bei der Verarbeitung langer Sequenzen revolutionäre Veränderungen im Bereich des Videoverständnisses gebracht. Ein Forschungsteam der Universität Nanjing, des Shanghai Artificial Intelligence Laboratory, der Fudan-Universität und der Zhejiang-Universität hat eine bahnbrechende Arbeit veröffentlicht. Sie werfen einen umfassenden Blick auf Mambas vielfältige Rollen bei der Videomodellierung, schlagen die Video Mamba Suite für 14 Modelle/Module vor und führen eine eingehende Bewertung von 12 Videoverständnisaufgaben durch. Die Ergebnisse sind spannend: Mamba zeigt sowohl bei videospezifischen als auch bei videoverbalen Aufgaben ein starkes Potenzial und erreicht eine ideale Balance aus Effizienz und Leistung. Dies ist nicht nur ein Technologiesprung, sondern auch ein starker Impuls für die zukünftige Videoverständnisforschung. 
- Papiertitel: Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
- Papierlink: https://arxiv.org/abs/2403.09626
- Code-Link: https ://github.com/OpenGVLab/video-mamba-suite
Im heutigen, sich schnell entwickelnden Bereich der Computer Vision ist die Videoverständnistechnologie zu einer der wichtigsten treibenden Kräfte für den Branchenfortschritt geworden. Viele Forscher widmen sich der Erforschung und Optimierung verschiedener Deep-Learning-Architekturen, um eine tiefere Analyse von Videoinhalten zu erreichen. Von den frühen rekurrenten neuronalen Netzen (RNN) und dreidimensionalen Faltungs-Neuronalen Netzen (3D CNN) bis zum derzeit mit Spannung erwarteten Transformer-Modell hat jeder Technologiesprung unser Verständnis und unsere Anwendung von Videodaten erheblich erweitert. Insbesondere das Transformer-Modell hat mit seiner hervorragenden Leistung in mehreren Bereichen des Videoverständnisses bemerkenswerte Erfolge erzielt, einschließlich, aber nicht beschränkt auf, Zielerkennung, Bildsegmentierung und multimodale Beantwortung von Fragen. Angesichts der inhärenten Eigenschaften ultralanger Sequenzen von Videodaten weist das Transformer-Modell jedoch auch seine inhärenten Einschränkungen auf: Aufgrund der quadratischen Zunahme der Rechenkomplexität wird es äußerst schwierig, ultralange Videosequenzen direkt zu modellieren. In diesem Zusammenhang hat sich die Architektur des Zustandsraummodells – repräsentiert durch Mamba – als zeitgemäß herauskristallisiert. Mit ihrem Vorteil der linearen Rechenkomplexität zeigt sie ein starkes Potenzial für die Verarbeitung langer Sequenzdaten, die die Grundlage des Transformers bilden Modell. Substitution bietet Möglichkeiten. Dennoch gibt es bei der aktuellen Anwendung der Zustandsraummodellarchitektur im Bereich des Videoverständnisses noch einige Einschränkungen: Erstens konzentriert sie sich hauptsächlich auf globale Videoverständnisaufgaben wie Klassifizierung und Abruf, zweitens werden hauptsächlich direkte räumlich-zeitliche Modellierungsmethoden untersucht Die Erforschung vielfältigerer Modellierungsmethoden ist jedoch noch unzureichend. Um diese Einschränkungen zu überwinden und das Potenzial des Mamba-Modells im Bereich des Videoverständnisses umfassend zu bewerten, hat das Forschungsteam sorgfältig die Video-Mamba-Suite (Video-Mamba-Suite) entwickelt. Diese Suite soll die bestehende Forschung ergänzen und die vielfältigen Rollen und potenziellen Vorteile von Mamba beim Videoverständnis durch eine Reihe eingehender Experimente und Analysen untersuchen. Das Forschungsteam teilte die Anwendung des Mamba-Modells in vier verschiedene Rollen ein und erstellte dementsprechend eine Video-Mamba-Suite mit 14 Modellen/Modulen. Nach einer umfassenden Auswertung von 12 Videoverständnisaufgaben zeigen die experimentellen Ergebnisse nicht nur das große Potenzial von Mamba bei der Verarbeitung von Video- und Videosprachaufgaben, sondern belegen auch die hervorragende Balance zwischen Effizienz und Leistung. Die Autoren freuen sich darauf, dass diese Arbeit Referenzressourcen und Erkenntnisse für zukünftige Forschungen auf dem Gebiet des Videoverständnisses liefert. 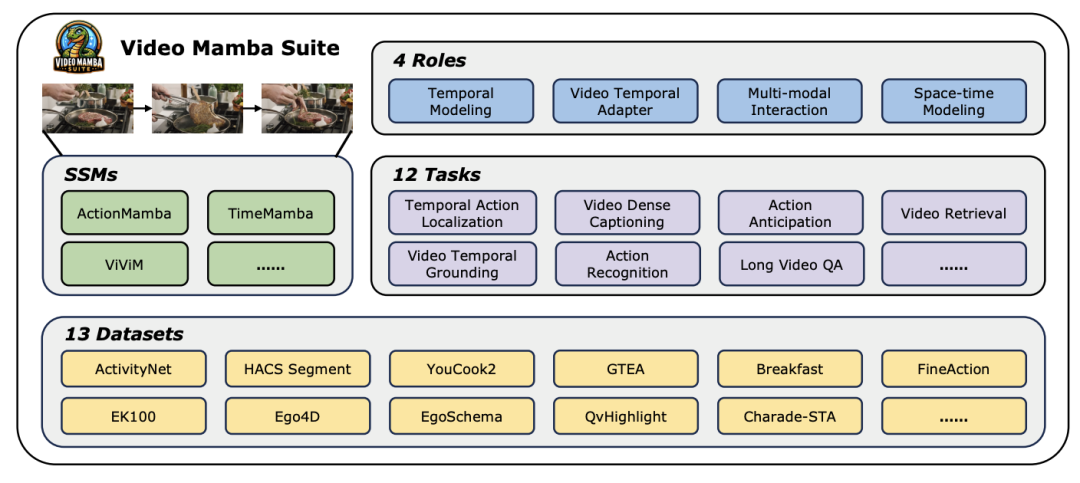
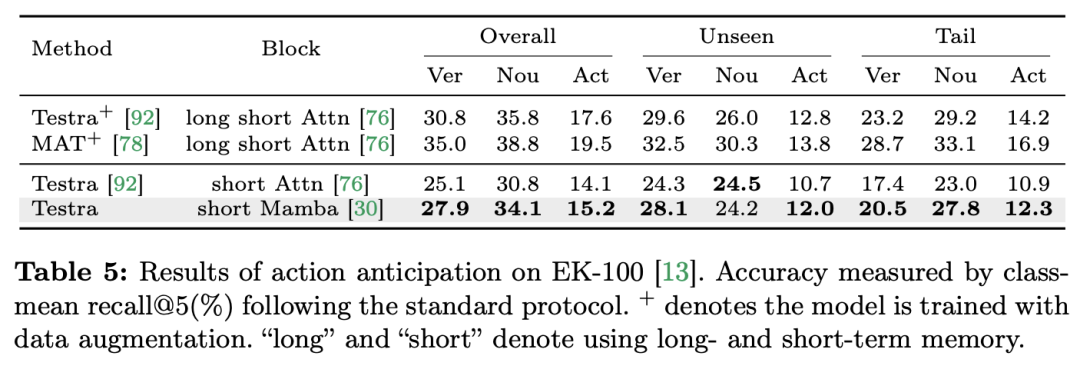
Videoverständnis ist ein grundlegendes Thema in der Computer-Vision-Forschung. Sein Kern besteht darin, die räumlich-zeitliche Dynamik im Video zu erfassen und daraus die Art der Aktivität und ihre Entwicklung zu identifizieren und abzuleiten Verfahren. Derzeit ist die Architekturerforschung für das Videoverständnis hauptsächlich in drei Richtungen unterteilt. Erstens modellieren rahmenbasierte Feature-Codierungsmethoden die zeitliche Abhängigkeit durch wiederkehrende Netzwerke (wie GRU und LSTM), aber diese segmentierte räumlich-zeitliche Modellierungsmethode ist schwierig, gemeinsame räumlich-zeitliche Informationen zu erfassen. Zweitens ermöglicht die Verwendung dreidimensionaler Faltungskerne die gleichzeitige Betrachtung räumlicher und zeitlicher Korrelationen in Faltungs-Neuronalen Netzen. Mit dem großen Erfolg von Transformer-Modellen in den Bereichen Sprache und Bild haben Video-Transformer-Modelle auch im Bereich des Videoverständnisses erhebliche Fortschritte gemacht und Fähigkeiten über RNNs und 3D-CNNs hinaus demonstriert. Video Transformer verarbeitet die Zeit- oder Raumzeitinformationen im Video auf einheitliche Weise, indem es das Video in eine Reihe von Tokens kapselt und den Aufmerksamkeitsmechanismus verwendet, um globale Kontextinteraktion und datenabhängige dynamische Berechnungen zu implementieren. Aufgrund der begrenzten Recheneffizienz von Video Transformer bei der Verarbeitung langer Videos sind jedoch einige Variantenmodelle entstanden, die ein Gleichgewicht zwischen Geschwindigkeit und Leistung herstellen. In jüngster Zeit haben Zustandsraummodelle (SSMs) ihre Vorteile im Bereich der Verarbeitung natürlicher Sprache (NLP) unter Beweis gestellt. Moderne SSMs weisen starke Darstellungsfähigkeiten bei der Modellierung langer Sequenzen auf und behalten gleichzeitig die lineare Zeitkomplexität bei. Dies liegt daran, dass ihr Auswahlmechanismus es überflüssig macht, den vollständigen Kontext zu speichern. Insbesondere das Mamba-Modell integriert zeitveränderliche Parameter in SSM und schlägt einen hardwarebewussten Algorithmus für effizientes Training und Inferenz vor. Die hervorragende Skalierungsleistung von Mamba zeigt, dass es eine vielversprechende Alternative zu Transformer sein kann. Gleichzeitig ist Mamba aufgrund seiner hohen Leistung und Effizienz sehr gut für Videoverständnisaufgaben geeignet. Obwohl es einige erste Versuche gab, die Anwendung von Mamba in der Bild-/Videomodellierung zu untersuchen, ist seine Wirksamkeit beim Videoverständnis noch unklar. Der Mangel an umfassender Forschung zum Potenzial von Mamba beim Videoverstehen schränkt die weitere Erforschung seiner Fähigkeiten bei verschiedenen videobezogenen Aufgaben ein. Als Reaktion auf die oben genannten Probleme untersuchte das Forschungsteam das Potenzial von Mamba im Bereich des Videoverständnisses. Ziel ihrer Forschung ist es zu bewerten, ob Mamba in diesem Bereich eine brauchbare Alternative zu Transformers sein kann. Dazu beschäftigten sie sich zunächst mit der Frage, wie man über Mambas unterschiedliche Rollen beim Verständnis von Video nachdenken sollte. Auf dieser Grundlage untersuchten sie weiter, welche Aufgaben Mamba besser meisterte. Der Artikel unterteilt Mambas Rolle bei der Videomodellierung in die folgenden vier Kategorien: 1) zeitliches Modell, 2) zeitliches Modul, 3) multimodales Interaktionsnetzwerk, 4) räumlich-zeitliches Modell. Für jede Rolle untersuchte das Forschungsteam ihre Videomodellierungsfunktionen für verschiedene Videoverständnisaufgaben. Um Manba fair gegen Transformer antreten zu lassen, wählte das Forschungsteam sorgfältig Vergleichsmodelle aus, die auf Standard- oder modifizierten Transformer-Architekturen basieren. Auf dieser Grundlage erhielten sie eine Video Mamba Suite mit 14 Modellen/Modulen, die für 12 Videoverständnisaufgaben geeignet sind. Das Forschungsteam hofft, dass die Video Mamba Suite in Zukunft eine grundlegende Ressource für die Erforschung SSM-basierter Videoverständnismodelle werden kann. Mamba als Video-Timing-ModellAufgaben und Daten: Das Forschungsteam bewertete Mambas Leistung bei fünf Video-Timing-Aufgaben: Lokalisierung (HACS Segment), Temporal Action Segmentation (GTEA), Dense Video Captioning (ActivityNet, YouCook), Video Segment Captioning (ActivityNet, YouCook) und Action Prediction (Epic-Kitchen-100). 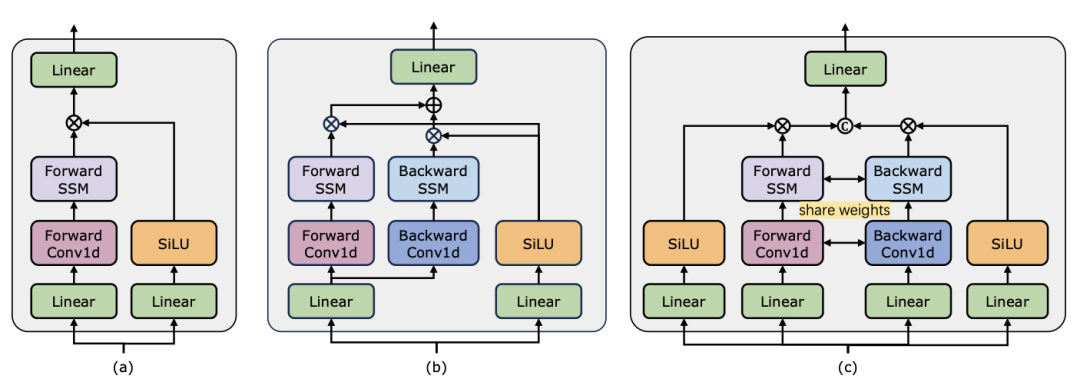 Baseline und Challenger: Das Forschungsteam wählte Transformer-basierte Modelle als Basis für jede Aufgabe. Zu diesen Basismodellen gehören insbesondere ActionFormer, ASFormer, Testra und PDVC. Um einen Mamba-Challenger zu bauen, ersetzten sie das Transformer-Modul im Basismodell durch ein Mamba-basiertes Modul, das wie oben gezeigt drei Module umfasste: das ursprüngliche Mamba (a), ViM (b) und ursprünglich das DBM (c). vom Forschungsteam entworfenes Modul. Es ist erwähnenswert, dass der Artikel die Leistung des Basismodells mit der des ursprünglichen Mamba-Moduls in einer Aktionsvorhersageaufgabe vergleicht, die kausale Schlussfolgerungen beinhaltet. Ergebnisse und Analyse: Das Papier zeigt die Vergleichsergebnisse verschiedener Modelle zu vier Aufgaben. Insgesamt verfügen einige Transformer-basierte Modelle jedoch über Aufmerksamkeitsvarianten zur Verbesserung der Leistung. Die folgende Tabelle zeigt die überlegene Leistung der Mamba-Serie im Vergleich zu den vorhandenen Methoden der Transformer-Serie.Mamba für multimodale Interaktion Der Artikel verwendet die Video-Temporal-Lokalisierungsaufgabe (VTG), um die Leistung von Mamba zu bewerten. Zu den abgedeckten Datensätzen gehören QvHighlight und Charade-STA.
Baseline und Challenger: Das Forschungsteam wählte Transformer-basierte Modelle als Basis für jede Aufgabe. Zu diesen Basismodellen gehören insbesondere ActionFormer, ASFormer, Testra und PDVC. Um einen Mamba-Challenger zu bauen, ersetzten sie das Transformer-Modul im Basismodell durch ein Mamba-basiertes Modul, das wie oben gezeigt drei Module umfasste: das ursprüngliche Mamba (a), ViM (b) und ursprünglich das DBM (c). vom Forschungsteam entworfenes Modul. Es ist erwähnenswert, dass der Artikel die Leistung des Basismodells mit der des ursprünglichen Mamba-Moduls in einer Aktionsvorhersageaufgabe vergleicht, die kausale Schlussfolgerungen beinhaltet. Ergebnisse und Analyse: Das Papier zeigt die Vergleichsergebnisse verschiedener Modelle zu vier Aufgaben. Insgesamt verfügen einige Transformer-basierte Modelle jedoch über Aufmerksamkeitsvarianten zur Verbesserung der Leistung. Die folgende Tabelle zeigt die überlegene Leistung der Mamba-Serie im Vergleich zu den vorhandenen Methoden der Transformer-Serie.Mamba für multimodale Interaktion Der Artikel verwendet die Video-Temporal-Lokalisierungsaufgabe (VTG), um die Leistung von Mamba zu bewerten. Zu den abgedeckten Datensätzen gehören QvHighlight und Charade-STA. 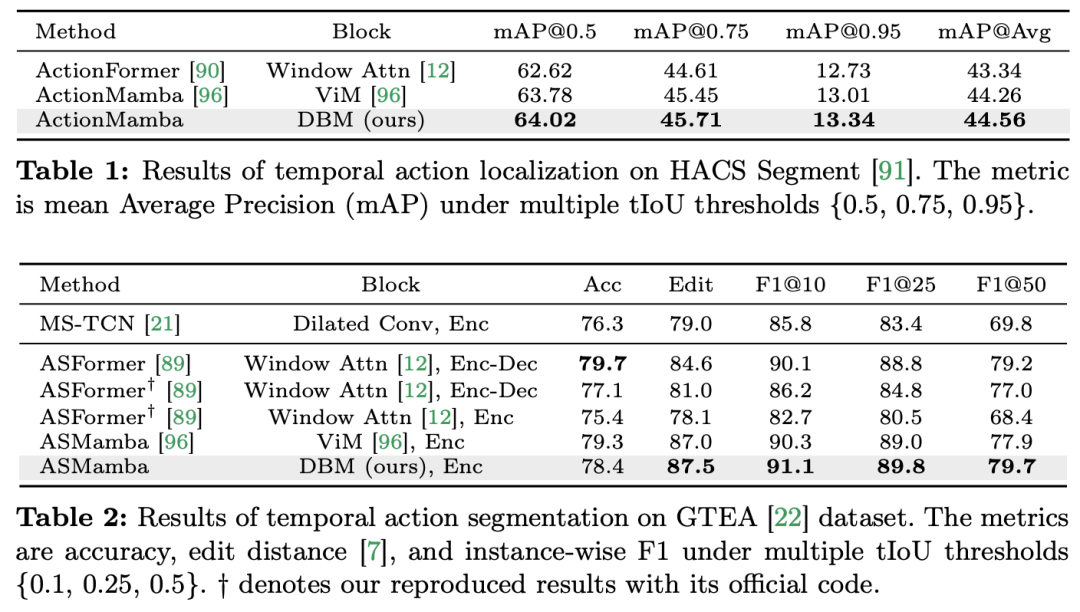
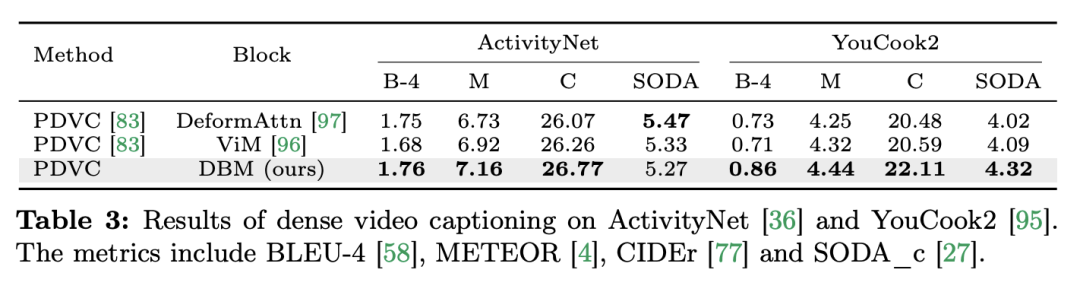 Aufgaben und Daten
Aufgaben und Daten
: Das Forschungsteam bewertete Mambas Leistung bei fünf zeitlichen Videoaufgaben: zeitliche Aktionslokalisierung (HACS-Segment), zeitliche Aktionssegmentierung (GTEA), dichte Videountertitel (ActivityNet, YouCook), Videoabsatzuntertitel (ActivityNet, YouCook) und Aktionsvorhersage (Epic-Kitchen-100).
: Das Forschungsteam nutzte UniVTG, um ein Mamba-basiertes VTG-Modell zu erstellen. UniVTG übernimmt Transformer als multimodales Interaktionsnetzwerk. Angesichts der Videofunktionen und Textfunktionen fügen sie zunächst erlernbare Standorteinbettungen und Modalitätstypeinbettungen für jede Modalität hinzu, um Standort- und Modalitätsinformationen beizubehalten. Die Text- und Video-Tokens werden dann zu einer gemeinsamen Eingabe verkettet, die weiter in den multimodalen Transformer-Encoder eingespeist wird. Schließlich werden die texterweiterten Videofunktionen extrahiert und in den Vorhersagekopf eingespeist. Um einen modalübergreifenden Mamba-Konkurrenten zu schaffen, entschied sich das Forschungsteam dafür, bidirektionale Mamba-Blöcke zu stapeln, um einen multimodalen Mamda-Encoder zu bilden, der die Transformer-Basislinie ersetzt.
Ergebnisse und Analyse
: In diesem Dokument wird die Leistung mehrerer Modelle mithilfe von QvHighlight getestet. Mamba hat einen durchschnittlichen mAP von 44,74, was eine deutliche Verbesserung im Vergleich zu Transformer darstellt. Auf Charade-STA zeigt die Mamba-basierte Methode eine ähnliche Wettbewerbsfähigkeit wie Transformer. Dies zeigt, dass Mamba das Potenzial hat, mehrere Modalitäten effektiv zu integrieren. Angesichts der Tatsache, dass Mamba ein Modell ist, das auf linearem Scannen basiert, während Transformer auf globaler Markeninteraktion basiert, glaubt das Forschungsteam intuitiv, dass die Position von Text in der Markensequenz den Effekt der multimodalen Aggregation beeinflussen kann. Um dies zu untersuchen, beziehen sie verschiedene Text-Visual-Fusion-Methoden in die Tabelle ein und zeigen in der Abbildung vier verschiedene Markierungsanordnungen. Die Schlussfolgerung ist, dass die besten Ergebnisse erzielt werden, wenn Textbedingungen links von visuellen Merkmalen verschmolzen werden. QvHighlight hat weniger Einfluss auf diese Fusion, während Charade-STA besonders empfindlich auf die Position des Textes reagiert, was auf die Eigenschaften des Datensatzes zurückzuführen sein kann.
Mamba als Video-Timing-Adapter Zusätzlich zur Bewertung der Leistung von Mamba bei der Post-Timing-Modellierung untersuchte das Forschungsteam auch seine Wirksamkeit als Video-Timing-Adapter. Das Two Towers-Modell wird vorab trainiert, indem kontrastives Videotext-Lernen auf egozentrischen Daten durchgeführt wird, die 4 Millionen Videoclips mit feinkörniger Erzählung enthalten. Aufgaben und Daten: Das Forschungsteam bewertete Mambas Leistung bei fünf Video-Zeitaufgaben, darunter: Temporal Action Localization (HACS-Segment), Temporal Action Segmentation (GTEA), Dense Video Subtitles (ActivityNet, YouCook), Video Absatzuntertitel (ActivityNet, YouCook) und Handlungsvorhersage (Epic-Kitchen-100). Baseline und Challenger: TimeSformer verwendet separate räumlich-zeitliche Aufmerksamkeitsblöcke, um räumliche und zeitliche Beziehungen in Videos separat zu modellieren. Zu diesem Zweck führte das Forschungsteam einen bidirektionalen Mamba-Block als Timing-Adapter ein, um die ursprüngliche Timing-Selbstaufmerksamkeit zu ersetzen und separate räumlich-zeitliche Interaktionen zu verbessern. Für einen fairen Vergleich bleibt die räumliche Aufmerksamkeitsebene in TimeSformer unverändert. Hier verwendete das Forschungsteam ViM-Blöcke als Timing-Module und nannte das resultierende Modell TimeMamba. Es ist erwähnenswert, dass der Standard-ViM-Block mehr Parameter hat (etwas mehr als 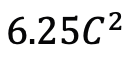 ) als der Selbstaufmerksamkeitsblock, wobei C die Merkmalsdimension ist. Daher wird das Expansionsverhältnis E des ViM-Blocks im Papier auf 1 gesetzt, wodurch seine Parametergröße für einen fairen Vergleich auf
) als der Selbstaufmerksamkeitsblock, wobei C die Merkmalsdimension ist. Daher wird das Expansionsverhältnis E des ViM-Blocks im Papier auf 1 gesetzt, wodurch seine Parametergröße für einen fairen Vergleich auf 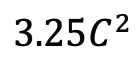 reduziert wird. Zusätzlich zur gewöhnlichen Restverbindungsform, die von TimeSformer verwendet wird, untersuchte das Forschungsteam auch die Anpassung des Frozen-Stils. Im Folgenden sind 5 Adapterstrukturen aufgeführt:
reduziert wird. Zusätzlich zur gewöhnlichen Restverbindungsform, die von TimeSformer verwendet wird, untersuchte das Forschungsteam auch die Anpassung des Frozen-Stils. Im Folgenden sind 5 Adapterstrukturen aufgeführt: 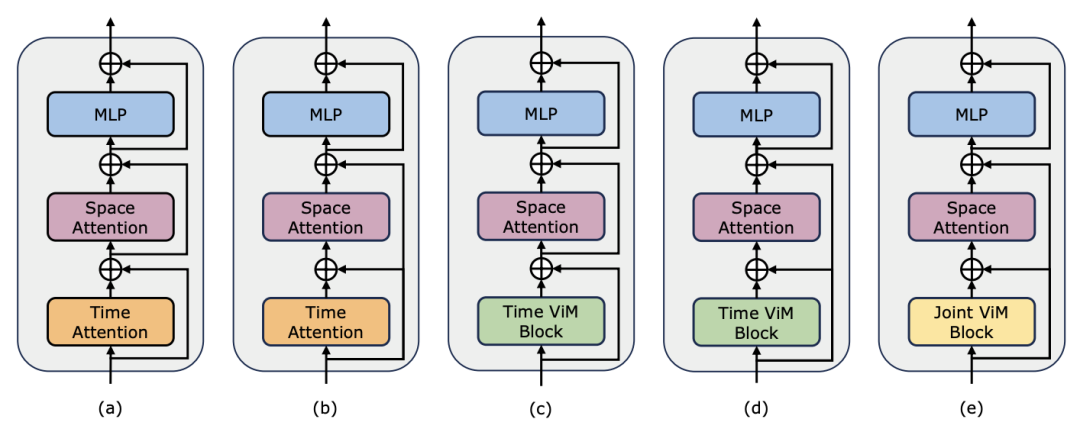
1. Zero-Shot-Multi-Instanz-Abruf. Das Forschungsteam bewertete zunächst verschiedene Modelle mit separaten raumzeitlichen Interaktionen in der Tabelle und stellte fest, dass die in der Arbeit wiedergegebenen Restverbindungen im Frozen-Stil mit denen von LaViLa übereinstimmten. Beim Vergleich des Original- und des Frozen-Stils ist es nicht schwer zu erkennen, dass der Frozen-Stil immer bessere Ergebnisse liefert. Darüber hinaus übertrifft das ViM-basierte zeitliche Modul bei derselben Anpassungsmethode stets das aufmerksamkeitsbasierte zeitliche Modul. Es ist erwähnenswert, dass der im Artikel verwendete zeitliche ViM-Block weniger Parameter aufweist als der zeitliche Selbstaufmerksamkeitsblock, was die bessere Parameternutzung und Informationsextraktionsfähigkeit des selektiven Mamba-Scannens hervorhebt. Darüber hinaus verifizierte das Forschungsteam den Raum-Zeit-ViM-Block weiter. Der raumzeitliche ViM-Block ersetzt den zeitlichen ViM-Block durch eine gemeinsame raumzeitliche Modellierung über die gesamte Videosequenz. Überraschenderweise führt der räumlich-zeitliche ViM-Block trotz der Einführung der globalen Modellierung tatsächlich zu einer Leistungsverschlechterung. Zu diesem Zweck vermutet das Forschungsteam, dass scanbasierte räumlich-zeitliche Verfahren die vorab trainierte räumliche Aufmerksamkeitsblockade zerstören könnten, um eine räumliche Merkmalsverteilung zu erzeugen. Das Folgende sind die experimentellen Ergebnisse: 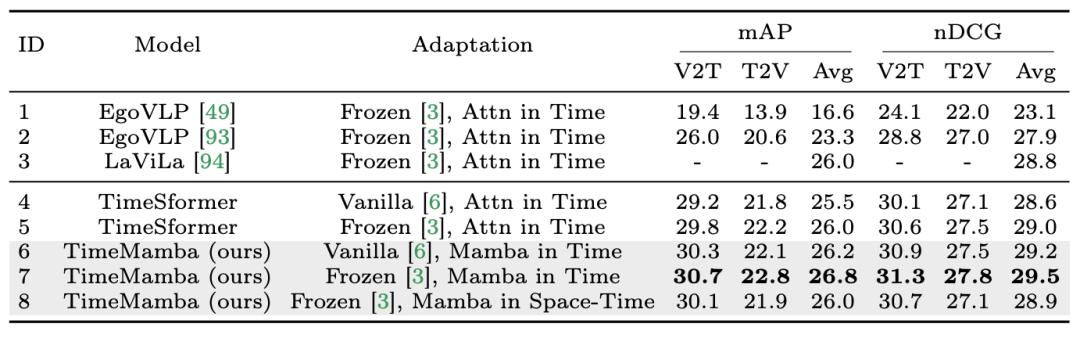
2. Feinabstimmung des Multi-Instanz-Abrufs und der Aktionserkennung. Das Forschungsteam verwendet weiterhin fein abgestimmte, vorab trainierte 16-Frame-Modelle für den Epic-Kitchens-100-Datensatz zum Abrufen mehrerer Instanzen und zur Aktionserkennung. Aus den experimentellen Ergebnissen geht hervor, dass TimeMamba TimeSformer im Zusammenhang mit der Verberkennung deutlich übertrifft und 2,8 Prozentpunkte übersteigt, was zeigt, dass TimeMamba feinkörniges Timing effektiv modellieren kann. 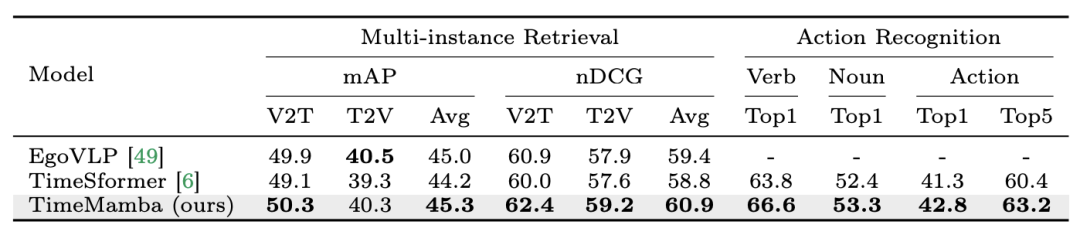
3. Kein Beispiel für lange Fragen und Antworten. Das Forschungsteam bewertete außerdem die Leistung des Modells bei Fragen und Antworten mit langen Videos im EgoSchema-Datensatz. Das Folgende sind die experimentellen Ergebnisse: 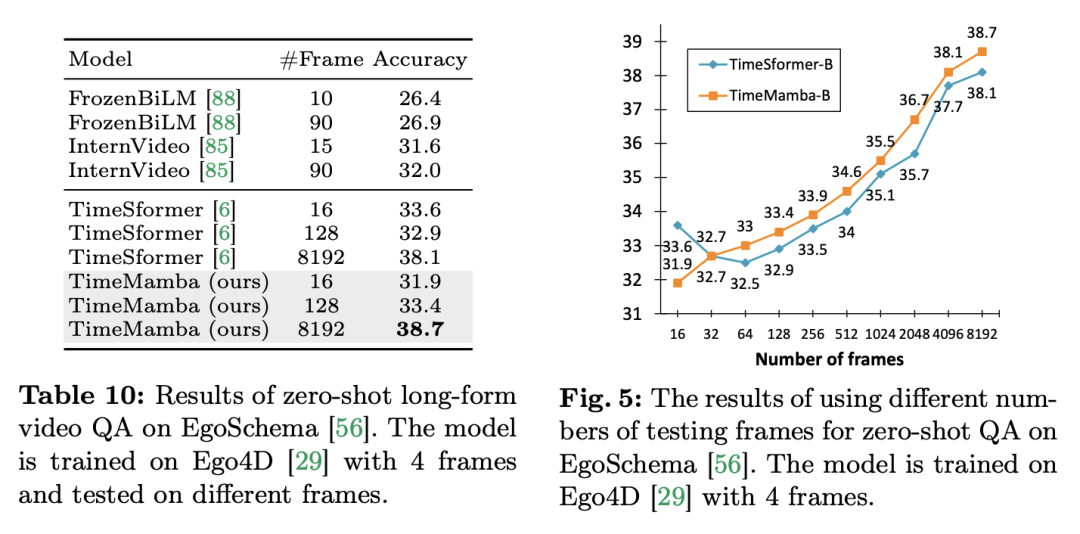
Sowohl TimeSformer als auch TimeMamba übertreffen nach dem Vortraining auf Ego4D die Leistung großer vorab trainierter Modelle (wie InternVideo). Darüber hinaus erhöhte das Forschungsteam kontinuierlich die Anzahl der Testbilder beginnend mit dem Video mit einem festen FPS, um die Auswirkungen der zeitlichen Modellierungsfähigkeiten von ViM-Blöcken für lange Videos zu untersuchen. Obwohl beide Modelle mit 4 Frames vorab trainiert sind, verbessert sich die Leistung von TimeMamba und TimeSformer mit zunehmender Anzahl an Frames stetig. Mittlerweile sind deutliche Verbesserungen bei der Verwendung von 8192 Frames zu beobachten. Wenn die Eingaberahmen 32 überschreiten, profitiert TimeMamba im Allgemeinen von mehr Rahmen als TimeSformer, was auf die Überlegenheit temporärer ViM-Blöcke bei der zeitlichen Selbstaufmerksamkeit hinweist. Mamba für räumlich-zeitliche ModellierungAufgaben und Daten: Darüber hinaus bewertet das Papier auch Mambas Fähigkeiten bei der Raum-Zeit-Modellierung, insbesondere in Epic-Kitchens – Die Leistung des Modells Beim Zero-Shot-Multi-Instanz-Abruf werden 100 Datensätze ausgewertet. Baseline und Konkurrenten: ViViT und TimeSformer untersuchen die Transformation von ViT mit räumlicher Aufmerksamkeit in ein Modell mit gemeinsamer räumlich-zeitlicher Aufmerksamkeit. Auf dieser Grundlage erweiterte das Forschungsteam das räumliche selektive Scannen des ViM-Modells um das räumlich-zeitliche selektive Scannen. Nennen Sie dieses erweiterte Modell ViViM. Das Forschungsteam verwendete zur Initialisierung das auf ImageNet-1K vorab trainierte ViM-Modell. Das ViM-Modell enthält einen CLS-Token, der in die Mitte der flachen Token-Sequenz eingefügt wird. Die folgende Abbildung zeigt, wie das ViM-Modell in ViViM konvertiert wird. Fügen Sie für eine bestimmte Eingabe mit M Frames ein CLS-Token in die Mitte der Token-Sequenz ein, die jedem Frame entspricht. Darüber hinaus fügte das Forschungsteam eine zeitliche Positionseinbettung hinzu, die für jeden Frame auf Null initialisiert wurde. Die abgeflachte Videosequenz wird dann in das ViViM-Modell eingegeben. Die Ausgabe des Modells wird durch Berechnen des Durchschnitts der CLS-Tokens für jeden Frame erhalten. 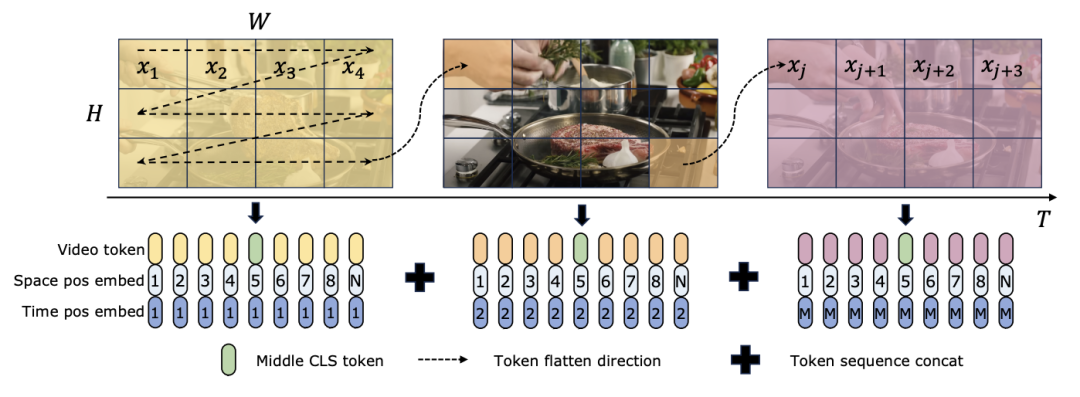
Ergebnisse und Analyse: In der Arbeit werden die Ergebnisse von ViViM beim Multi-Instanz-Retrieval ohne Stichprobe weiter untersucht. Temporale Modelle führen eine Multi-Instanz-Abrufleistung ohne Stichprobe durch. Beim Vergleich von ViT und ViViM, die beide auf ImageNet-1K vorab trainiert wurden, kann beobachtet werden, dass ViViM ViT übertrifft. Obwohl der Leistungsunterschied zwischen ViT-S und ViM-S auf ImageNet-1K gering ist (79,8 vs. 80,5), zeigt interessanterweise ViViM-S eine deutliche Verbesserung beim Zero-Shot-Multi-Instanz-Abruf (+2,1 mAP @Avg). dass ViViM bei der Modellierung langer Sequenzen sehr effektiv ist und somit die Leistung verbessert. 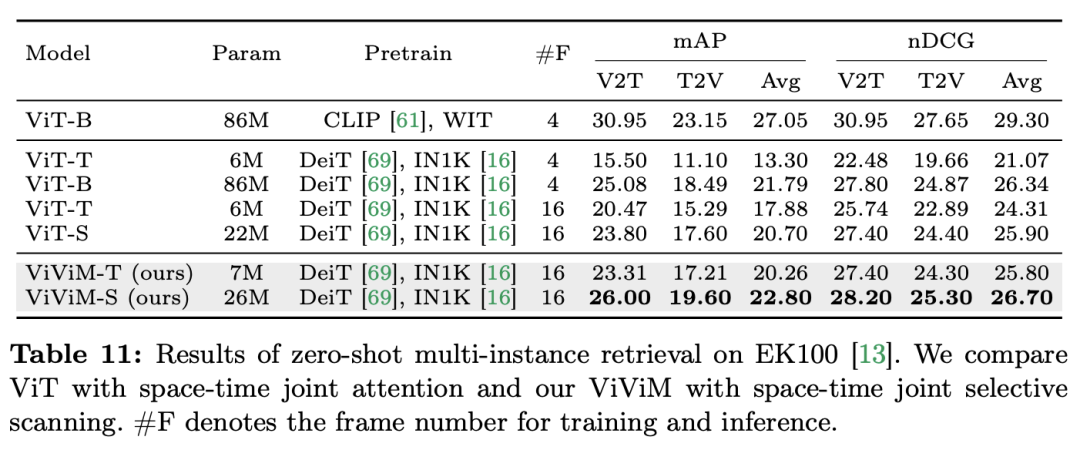
FazitDieses Papier demonstriert das Potenzial von Mamba als praktikable Alternative zu herkömmlichen Transformern, indem es seine Leistung im Bereich des Videoverständnisses umfassend bewertet. Mithilfe der Video Mamba Suite, die aus 14 Modellen/Modulen für 12 Videoverständnisaufgaben besteht, demonstrierte das Forschungsteam die Fähigkeit von Mamba, komplexe raumzeitliche Dynamiken effizient zu bewältigen. Mamba liefert nicht nur eine überlegene Leistung, sondern erreicht auch ein besseres Effizienz-Leistungs-Verhältnis. Diese Ergebnisse unterstreichen nicht nur die Eignung von Mamba für Videoanalyseaufgaben, sondern eröffnen auch neue Möglichkeiten für seine Anwendung im Bereich Computer Vision. Zukünftige Arbeiten können die Anpassungsfähigkeit von Mamba weiter untersuchen und seinen Nutzen auf komplexere multimodale Videoverständnisherausforderungen ausweiten. Das obige ist der detaillierte Inhalt vonIn 12 Videoverständnisaufgaben besiegte Mamba zunächst Transformer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Warum kann ich die letzte leere Seite in Word nicht löschen?
Warum kann ich die letzte leere Seite in Word nicht löschen?
 odm
odm








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



