


Stability AI hat ein neues Mitglied in seiner großen Modellfamilie.
Gestern, nach der Einführung von Stable Diffusion und Stable Video Diffusion, stellte Stability AI der Community ein großes 3D-Videogenerierungsmodell „Stable Video 3D“ (kurz SV3D) vor.
Dieses Modell basiert auf Stable Video Diffusion. Sein Hauptvorteil besteht darin, dass es die Qualität der 3D-Generierung und die Konsistenz mehrerer Ansichten erheblich verbessert. Im Vergleich zum vorherigen von Stability AI eingeführten Stable Zero123 und dem gemeinsamen Open-Source-Modell Zero123-XL ist die Wirkung dieses Modells noch besser.
Derzeit unterstützt Stable Video 3D sowohl die kommerzielle Nutzung, für die der Beitritt zur Stability AI-Mitgliedschaft (Mitgliedschaft) erforderlich ist, als auch die nichtkommerzielle Nutzung, bei der Benutzer die Modellgewichte auf Hugging Face herunterladen können.

Stabilitäts-KI bietet zwei Modellvarianten, nämlich SV3D_u und SV3D_p. SV3D_u generiert Orbitalvideos auf der Grundlage einer einzelnen Bildeingabe, ohne dass Kameraeinstellungen erforderlich sind, während SV3D_p die Generierungsfähigkeiten durch die Anpassung eines einzelnen Bildes und einer Orbitalperspektive weiter erweitert, sodass Benutzer 3D-Videos entlang eines bestimmten Kamerapfads erstellen können.
Derzeit wurde das Forschungspapier zu Stable Video 3D mit drei Hauptautoren veröffentlicht.

Stable Video 3D hat erhebliche Fortschritte im Bereich der 3D-Generierung erzielt, insbesondere bei der Synthese neuartiger Ansichtsgenerierungen , NVS) Aspekte.
Frühere Methoden neigten oft dazu, das Problem begrenzter Betrachtungswinkel und inkonsistenter Eingaben zu lösen, während Stable Video 3D in der Lage ist, aus jedem gegebenen Winkel eine kohärente Ansicht zu liefern und gut zu verallgemeinern. Dadurch verbessert das Modell nicht nur die Posenkontrollierbarkeit, sondern sorgt auch für ein konsistentes Erscheinungsbild des Objekts über mehrere Ansichten hinweg, wodurch wichtige Probleme bei der realistischen und genauen 3D-Generierung weiter verbessert werden.
Wie in der Abbildung unten gezeigt, ist Stable Video 3D im Vergleich zu Stable Zero123 und Zero-XL in der Lage, neuartige Mehrfachansichten mit stärkeren Details, mehr Treue zum Eingabebild und konsistenteren Mehrfachansichten zu generieren.

Darüber hinaus nutzt Stable Video 3D seine Multi-View-Konsistenz, um 3D Neural Radiance Fields (NeRF) zu optimieren und die Qualität von 3D-Netzen zu verbessern, die direkt aus neuen Ansichten generiert werden.
Zu diesem Zweck hat Stability AI eine Maske für den Stichprobenverlust durch fraktionierte Destillation entwickelt, die die 3D-Qualität unsichtbarer Regionen in der vorhergesagten Ansicht weiter verbessert. Um Probleme mit der Beleuchtung zu vermeiden, verwendet Stable Video 3D ein entkoppeltes Beleuchtungsmodell, das mit 3D-Formen und -Texturen optimiert ist.
Das Bild unten zeigt ein Beispiel für eine verbesserte 3D-Netzgenerierung durch 3D-Optimierung bei Verwendung des Stable Video 3D-Modells und seiner Ausgabe.

Das Bild unten zeigt den Vergleich der mit Stable Video 3D generierten 3D-Netzergebnisse mit denen von EscherNet und Stable Zero123.

Architekturdetails
Die Architektur des Stable Video 3D-Modells ist in Abbildung 2 unten dargestellt. Es basiert auf der Stable Video Diffusion-Architektur und enthält ein UNet mit mehreren Ebenen, wobei jede Schicht Es enthält auch eine Folge von Restblöcken mit einer Conv3D-Schicht und zwei Transformatorblöcken mit Aufmerksamkeitsschichten (räumlich und zeitlich).
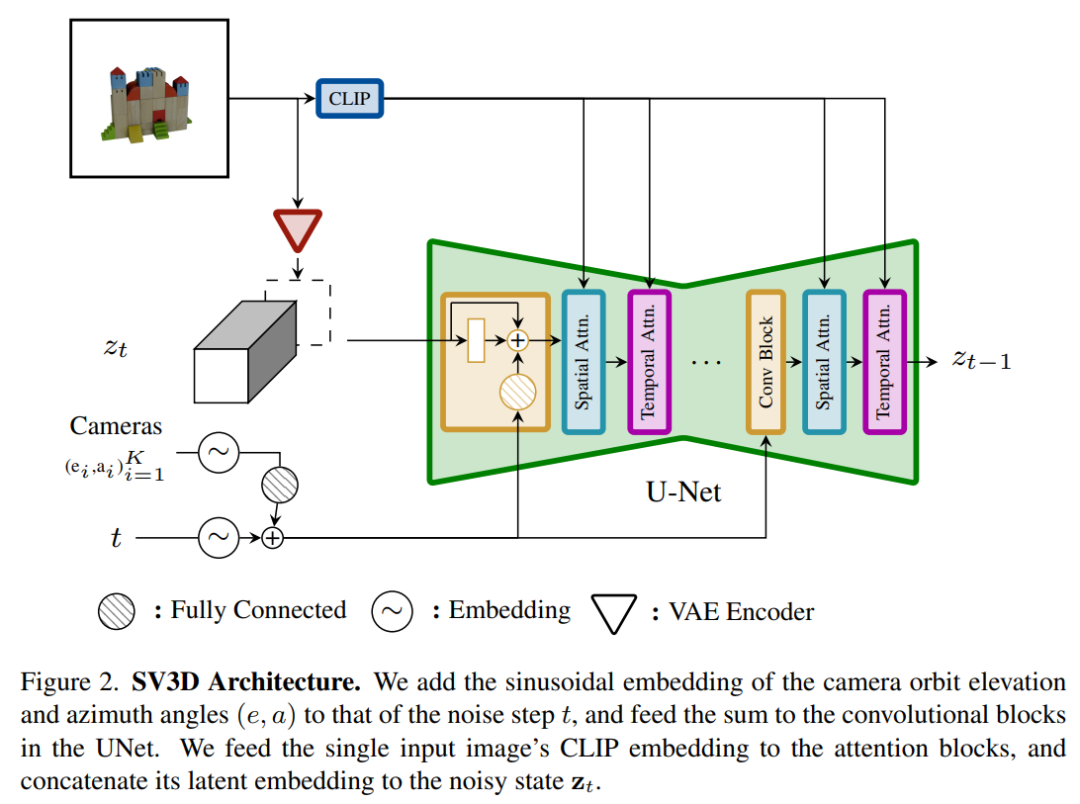
Der spezifische Prozess ist wie folgt:
(i) Löschen Sie die Vektorbedingungen „fps id“ und „motion Bucket id“, da sie nichts mit Stable Video 3D zu tun haben
(ii) Die Das bedingte Bild durchläuft den VAE-Encoder von Stable Video Diffusion, der in den latenten Raum eingebettet und dann im Rauschzeitschritt t mit dem Eingang zt für den latenten Rauschen verbunden wird, was zu UNet führt zu jedem Transformatorblock fungieren Queraufmerksamkeitsschichten als Schlüssel und Werte, und Abfragen werden zu Merkmalen der entsprechenden Schicht
(iv) Die Kamerabahn wird entlang des Diffusionsrauschen-Zeitschritts in den Restblock eingespeist. Die Kamerapositionswinkel ei und ai und der Rauschzeitschritt t werden zunächst in die sinusförmige Positionseinbettung eingebettet, dann werden die Kamerapositionseinbettungen zur linearen Transformation miteinander verkettet und zur Rauschzeitschritteinbettung hinzugefügt und schließlich in jeden Restblock eingespeist wird zu den Eingabemerkmalen des Blocks hinzugefügt.
Darüber hinaus hat Stability AI statische Umlaufbahnen und dynamische Umlaufbahnen entworfen, um die Auswirkungen von Kamerapositionsanpassungen zu untersuchen, wie in Abbildung 3 unten dargestellt.
Auf einer statischen Umlaufbahn dreht sich die Kamera im äquidistanten Azimut um das Objekt und verwendet dabei denselben Höhenwinkel wie das Zustandsbild. Der Nachteil dabei ist, dass Sie aufgrund des angepassten Höhenwinkels möglicherweise keine Informationen über die Ober- oder Unterseite des Objekts erhalten. In einer dynamischen Umlaufbahn können die Azimutwinkel ungleich sein und auch die Höhenwinkel jeder Ansicht können unterschiedlich sein.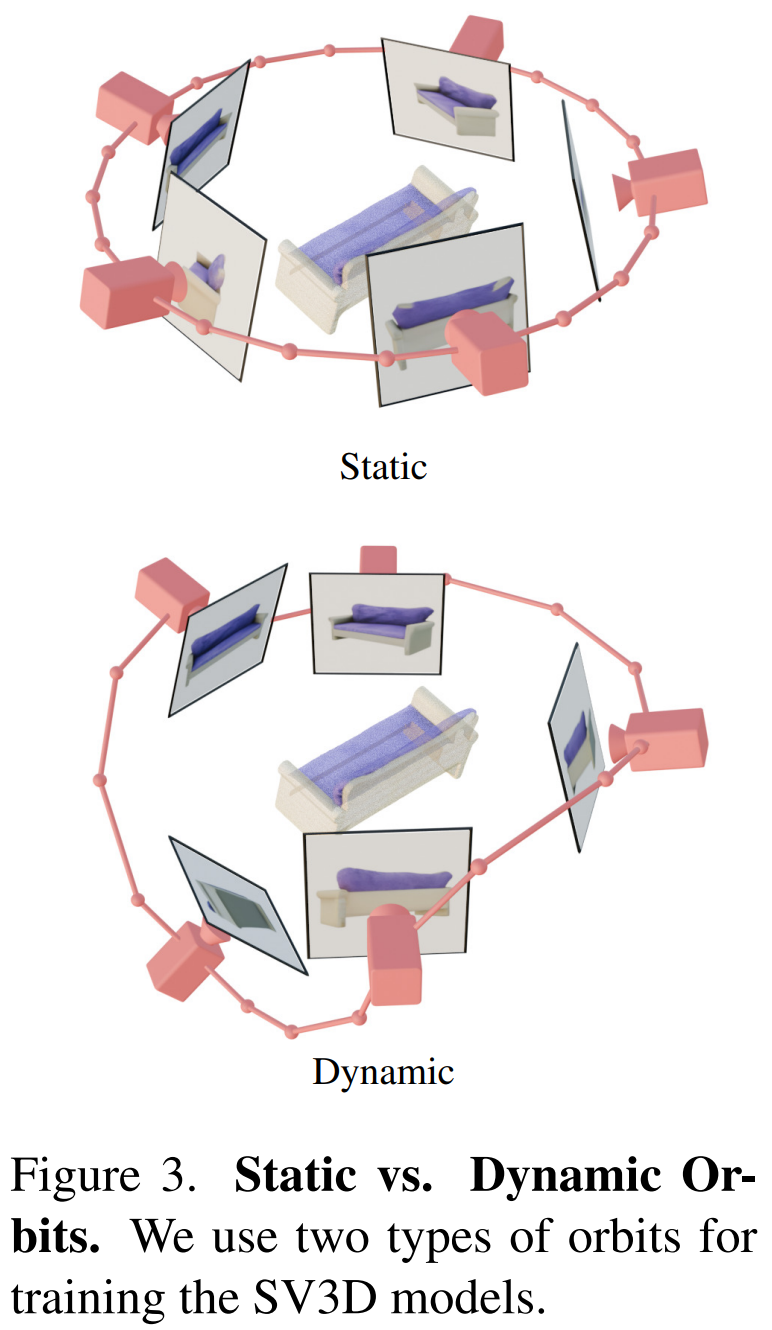
Um eine dynamische Umlaufbahn zu erstellen, tastet die Stabilitäts-KI eine statische Umlaufbahn ab, fügt ihrem Azimut ein kleines zufälliges Rauschen und ihrer Höhe eine zufällig gewichtete Kombination von Sinuskurven unterschiedlicher Frequenz hinzu. Dies sorgt für eine zeitliche Glätte und stellt sicher, dass die Kamerabahn entlang derselben Azimut- und Höhenschleife endet wie das Zustandsbild.
Experimentelle Ergebnisse
Tabelle 1 und Tabelle 3 zeigen die Ergebnisse von Stable Video 3D im Vergleich zu anderen Modellen auf statischen Umlaufbahnen und zeigen, dass sogar das Modell SV3D_u ohne Posenanpassung eine bessere Leistung erbringt als alle vorherigen Methoden.
Die Ergebnisse der Ablationsanalyse zeigen, dass SV3D_c und SV3D_p SV3D_u bei der Generierung statischer Trajektorien übertreffen, obwohl letzteres ausschließlich auf statischen Trajektorien trainiert wird.
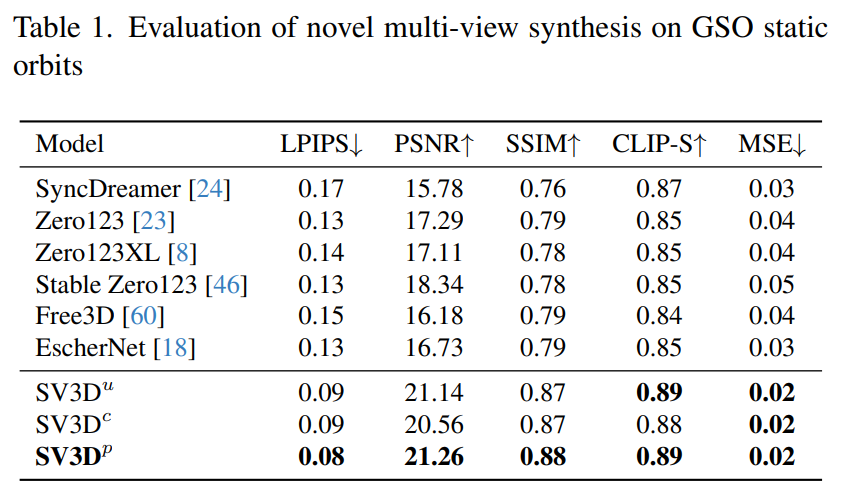
Tabelle 2 und Tabelle 4 unten zeigen die Generierungsergebnisse dynamischer Umlaufbahnen, einschließlich der Posenanpassungsmodelle SV3D_c und SV3D_p, wobei letzteres SOTA bei allen Metriken erreicht.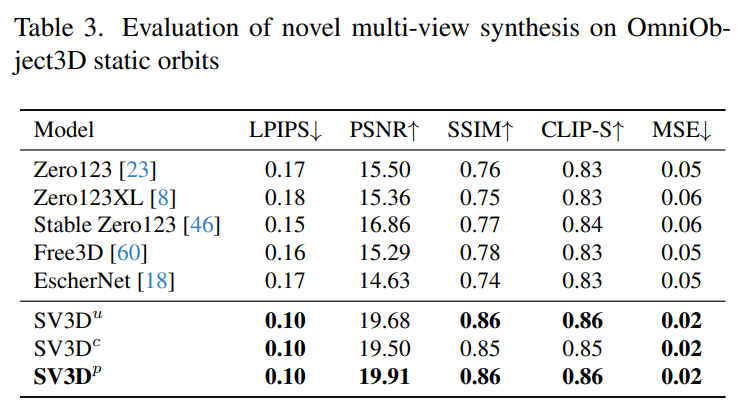
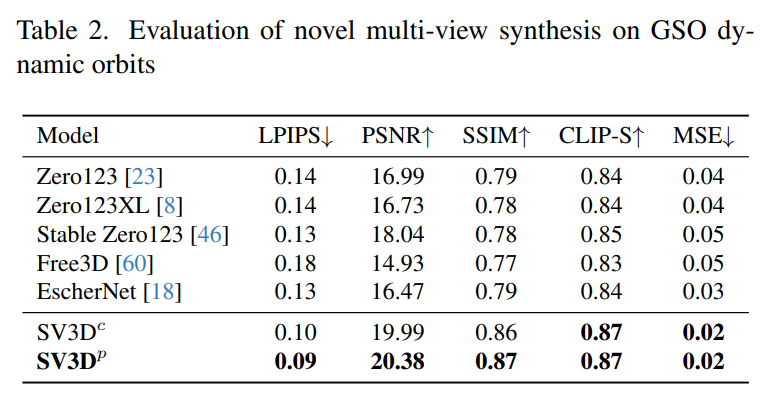
Die visuellen Vergleichsergebnisse in Abbildung 6 unten zeigen weiter, dass die von Stable Video 3D generierten Bilder im Vergleich zu früheren Arbeiten detaillierter, dem bedingten Bild treuer und über mehrere Perspektiven hinweg konsistenter sind .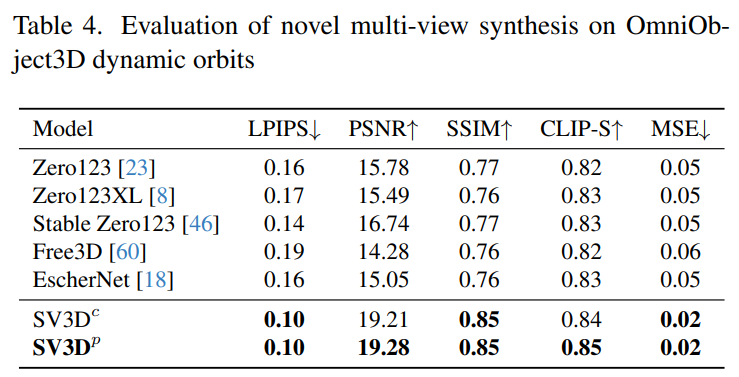
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonStable Video 3D feiert ein schockierendes Debüt: Ein einzelnes Bild erzeugt 3D-Videos ohne tote Winkel, und Modellgewichte werden geöffnet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































