


Kürzlich haben die Peking-Universität in Stanford und die beliebten Pika Labs gemeinsam eine Studie veröffentlicht, die die Fähigkeiten vinzentinischer Diagramme mit großem Modell auf ein neues Niveau gehoben hat.

Papieradresse: https://arxiv.org/pdf/2401.11708.pdf
Codeadresse: https://github.com/YangLing0818/RPG-DiffusionMaster
Vorgeschlagen von der Autor des Papiers Es wird ein innovativer Ansatz verfolgt, um das Text-zu-Bild-Generierungs-/Bearbeitungs-Framework zu verbessern, indem die Inferenzfähigkeiten multimodaler großer Sprachmodelle (MLLM) genutzt werden.
Mit anderen Worten zielt diese Methode darauf ab, die Leistung von Textgenerierungsmodellen bei der Verarbeitung komplexer Textaufforderungen mit mehreren Attributen, Beziehungen und Objekten zu verbessern.
Ohne weitere Umschweife, hier ist das Bild:

Ein grünes Zwillingsschwanzmädchen in orangefarbenem Kleid sitzt auf dem Sofa, während links unter einem großen Fenster ein unordentlicher Schreibtisch steht, auf dem sich ein lebhaftes Aquarium befindet Oben rechts auf dem Sofa, realistischer Stil.
Ein Mädchen mit zwei Schwänzen in einem orangefarbenen Kleid sitzt auf dem Sofa. Oben rechts befindet sich ein unordentliches Aquarium ist realistischer Stilismus.
Angesichts mehrerer Objekte mit komplexen Beziehungen sind die Struktur des gesamten Bildes und die vom Modell vorgegebene Beziehung zwischen Personen und Objekten sehr vernünftig und lassen die Augen des Betrachters leuchten.
Für die gleiche Aufforderung werfen wir einen Blick auf die Leistung des aktuellen hochmodernen SDXL und DALL·E 3:

Werfen wir einen Blick auf das neue Framework, wenn es verfügbar ist geht es darum, mehrere Attribute mit mehreren Objekten zu verbinden. Von links nach rechts: ein blondes europäisches Mädchen mit Pferdeschwanz in einem weißen Hemd, ein afrikanisches Mädchen mit braunen Locken in einem blauen Hemd, das mit einem Vogel bedruckt ist, und ein asiatischer Junge Männer mit schwarzen kurzen Haaren im Anzug gehen glücklich über den Campus.
 Von links nach rechts ein europäisches Mädchen in einem weißen Hemd mit blondem Pferdeschwanz, ein afrikanisches Mädchen mit braunen Locken, das ein blaues Hemd mit einem Vogelaufdruck trägt Darauf und ein Mädchen im Anzug spaziert ein junger asiatischer Mann mit kurzen schwarzen Haaren glücklich über den Campus.
Von links nach rechts ein europäisches Mädchen in einem weißen Hemd mit blondem Pferdeschwanz, ein afrikanisches Mädchen mit braunen Locken, das ein blaues Hemd mit einem Vogelaufdruck trägt Darauf und ein Mädchen im Anzug spaziert ein junger asiatischer Mann mit kurzen schwarzen Haaren glücklich über den Campus.
Die Forscher nannten dieses Framework RPG (Recaption, Plan and Generate) und verwendeten MLLM als globalen Planer, um den komplexen Bildgenerierungsprozess in mehrere einfachere Generierungsaufgaben innerhalb von Unterregionen zu zerlegen.
Das Papier schlägt eine komplementäre Regionsdiffusion vor, um die Generierung von Regionskombinationen zu erreichen, und integriert außerdem die textgesteuerte Bildgenerierung und -bearbeitung in einem geschlossenen Regelkreis in das RPG-Framework, wodurch die Generalisierungsfähigkeiten verbessert werden.
Experimente zeigen, dass das in diesem Artikel vorgeschlagene RPG-Framework die aktuellen hochmodernen Textbilddiffusionsmodelle, einschließlich DALL·E 3 und SDXL, übertrifft, insbesondere bei der Objektsynthese mehrerer Kategorien und der semantischen Ausrichtung von Textbildern. 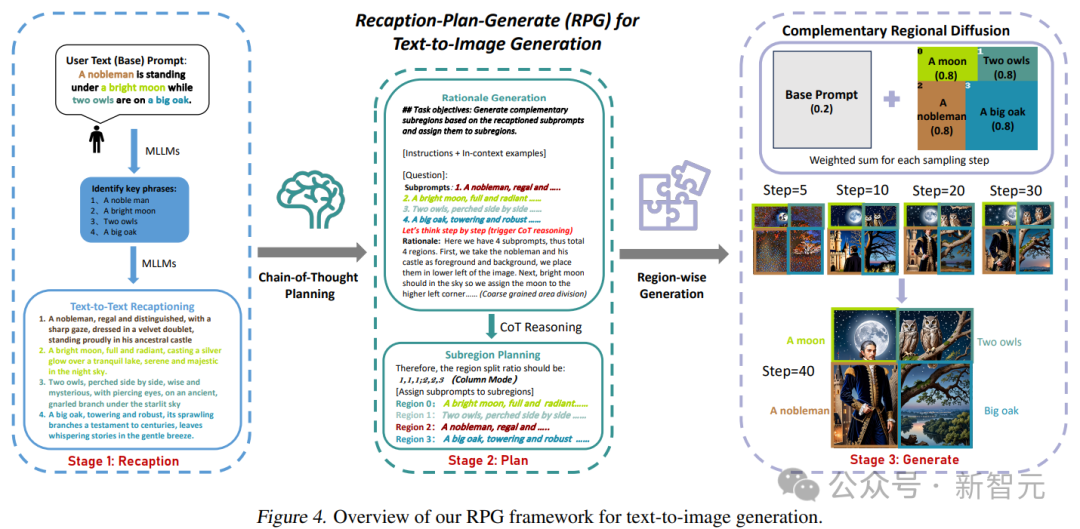
Es ist erwähnenswert, dass das RPG-Framework weitgehend mit verschiedenen MLLM-Architekturen (wie MiniGPT-4) und Diffusions-Backbone-Netzwerken (wie ControlNet) kompatibel ist.
RPG
Das aktuelle Vincentian-Graphmodell weist zwei Hauptprobleme auf: 1. Layoutbasierte oder aufmerksamkeitsbasierte Methoden können nur eine grobe räumliche Orientierung bieten und haben Schwierigkeiten, mit überlappenden Objekten umzugehen. 2. Feedbackbasierte Methoden erfordern Collect hochwertige Feedbackdaten und verursachen zusätzliche Schulungskosten.Um diese Probleme zu lösen, schlugen Forscher drei Kernstrategien von RPG vor, wie in der folgenden Abbildung dargestellt:
Anhand einer komplexen Textaufforderung mit mehreren Entitäten und Beziehungen wird zunächst MLLM verwendet, um es zu zerlegen grundlegende Hinweise und hochbeschreibende Unterhinweise; anschließend wird der Bildraum mithilfe der CoT-Planung des multimodalen Modells in komplementäre Regionen unterteilt, um das Bild jeder Unterregion unabhängig zu erzeugen; Die Aggregation wird bei jedem Stichprobenschritt durchgeführt.
wandelt Texthinweise in hochbeschreibende Hinweise um und sorgt so für ein informationsverbessertes Hinweisverständnis und eine semantische Ausrichtung in Diffusionsmodellen.
Verwenden Sie MLLM, um Schlüsselphrasen in der Benutzeraufforderung y zu identifizieren und die darin enthaltenen Unterelemente abzurufen:
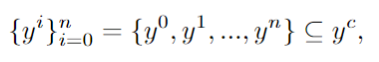
Verwenden Sie LLM, um die Textaufforderung in verschiedene Unteraufforderungen zu zerlegen und diese detaillierter neu zu beschreiben :
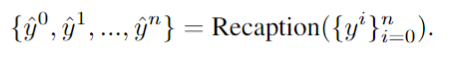
Auf diese Weise können für jeden Unterhinweis dichtere, feinkörnigere Details generiert werden, um die Wiedergabetreue der generierten Bilder effektiv zu verbessern und die semantischen Unterschiede zwischen Hinweisen und Bildern zu verringern.
unterteilt den Bildraum in komplementäre Unterregionen und weist jeder Unterregion unterschiedliche Unterhinweise zu, während die Generierungsaufgabe in mehrere einfachere Unteraufgaben unterteilt wird.
Konkret ist der Bildraum H×B in mehrere komplementäre Bereiche unterteilt, und jede Enhancer-Eingabeaufforderung ist einem bestimmten Bereich R zugeordnet:
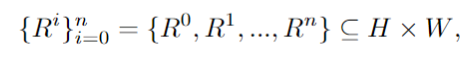
Verwenden Sie die leistungsstarke Denkketten-Argumentationsfähigkeit von MLLM und führen Sie aus effektive Zonierung. Durch die Analyse der abgerufenen Zwischenergebnisse können detaillierte Prinzipien und präzise Anweisungen für die anschließende Bildsynthese generiert werden.
In jedem rechteckigen Unterbereich werden von Unterhinweisen geleitete Inhalte unabhängig generiert und dann in der Größe geändert und so verbunden, dass diese Unterbereiche räumlich zusammengeführt werden.
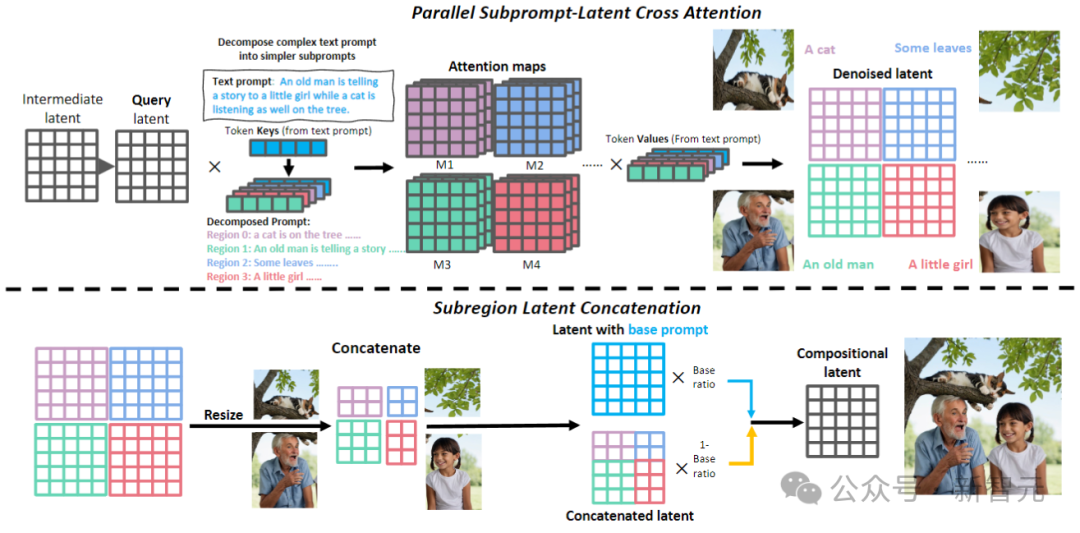
Diese Methode löst effektiv das Problem großer Modelle, die Schwierigkeiten mit der Handhabung überlappender Objekte haben. Darüber hinaus erweitert das Papier dieses Framework, um es an Bearbeitungsaufgaben anzupassen, indem es eine konturbasierte Regionsdiffusion verwendet, um inkonsistente Regionen, die geändert werden müssen, präzise zu bearbeiten.
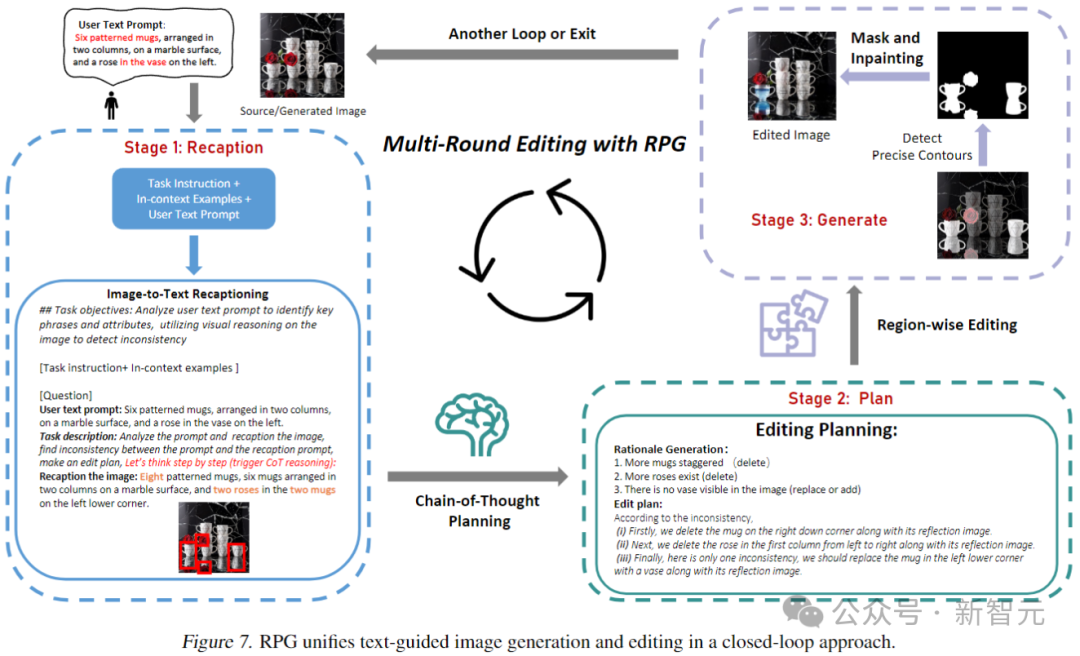
wie im Bild oben gezeigt. In der Nacherzählphase verwendet RPG MLLM als Untertitel, um das Quellbild nachzuerzählen, und nutzt seine leistungsstarken Argumentationsfunktionen, um feinkörnige semantische Unterschiede zwischen dem Bild und dem Zielhinweis zu identifizieren und direkt zu analysieren, wie das Eingabebild mit dem Zielhinweis übereinstimmt.
Verwenden Sie MLLM (GPT-4, Gemini Pro usw.), um Unterschiede zwischen Eingabe und Ziel hinsichtlich numerischer Genauigkeit, Eigenschaftsbindungen und Objektbeziehungen zu überprüfen. Das resultierende multimodale Verständnis-Feedback wird zur inferenziellen Bearbeitungsplanung an das MLLM übermittelt.
Werfen wir einen Blick auf die Leistung des Generierungseffekts in den oben genannten drei Aspekten. Der erste ist die Attributbindung und vergleicht SDXL, DALL·E 3 und LMD+:

Das können wir insgesamt sehen Drei Tests Von den Spielen spiegelt nur RPG am genauesten wider, was die Eingabeaufforderungen beschreiben.
Dann ist da noch die numerische Genauigkeit, die Anzeigereihenfolge ist die gleiche wie oben (SDXL, DALL·E 3, LMD+, RPG):

-Ich habe nicht erwartet, dass das Zählen ziemlich schwierig ist für das große Vincent-Figurenmodell Ja, RPG besiegt den Gegner leicht.
Der letzte Punkt besteht darin, komplexe Beziehungen in der Eingabeaufforderung wiederherzustellen:

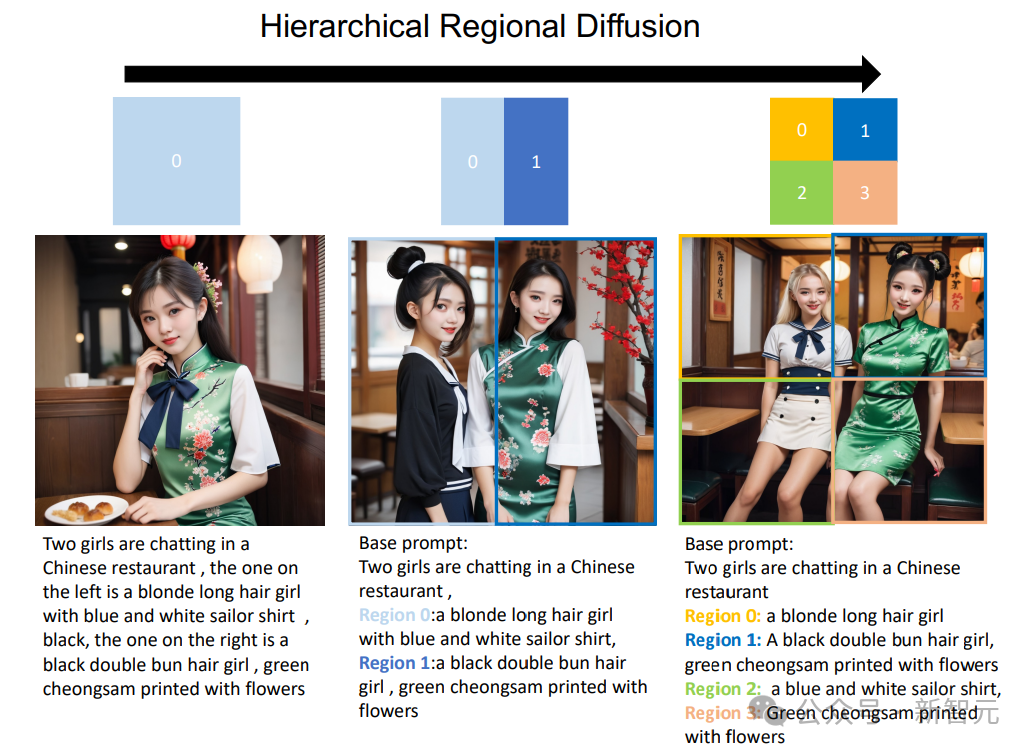
Darüber hinaus kann die Zonenverteilung auf ein hierarchisches Format erweitert werden, das bestimmte Unterregionen in kleinere Unterregionen unterteilt.
Wie in der Abbildung unten gezeigt, kann RPG erhebliche Verbesserungen bei der Text-zu-Bild-Generierung erzielen, wenn eine Hierarchie der Regionssegmentierung hinzugefügt wird. Dies bietet eine neue Perspektive für die Bewältigung komplexer Generierungsaufgaben und ermöglicht die Generierung von Bildern beliebiger Zusammensetzung.
Das obige ist der detaillierte Inhalt vonVincent Tus neues SOTA! Pika, die Peking-Universität und Stanford starten gemeinsam ein multimodales RPG, um zur Lösung zweier großer Probleme von Wenshengtu beizutragen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So legen Sie fest, dass beide Enden in CSS ausgerichtet sind
So legen Sie fest, dass beide Enden in CSS ausgerichtet sind
 Telnet-Befehl
Telnet-Befehl
 So konfigurieren Sie Maven in der Idee
So konfigurieren Sie Maven in der Idee
 So lösen Sie dns_probe_possible
So lösen Sie dns_probe_possible
 Was sind die formellen Handelsplattformen für digitale Währungen?
Was sind die formellen Handelsplattformen für digitale Währungen?
 Was bedeutet es, wenn eine Nachricht gesendet, aber von der anderen Partei abgelehnt wurde?
Was bedeutet es, wenn eine Nachricht gesendet, aber von der anderen Partei abgelehnt wurde?
 So implementieren Sie die JSP-Paging-Funktion
So implementieren Sie die JSP-Paging-Funktion
 Abfragetool für Registrierungsdomänennamen
Abfragetool für Registrierungsdomänennamen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



