


Der Linux-Kernel enthält 4 Arten von IO-Schedulern, nämlich Noop IO-Scheduler, Anticipatory IO-Scheduler, Deadline IO-Scheduler und CFQ IO-Scheduler.
Normalerweise werden Lese- und Schreibverzögerungen auf der Festplatte dadurch verursacht, dass sich der Kopf zum Zylinder bewegt. Um diese Verzögerung zu beheben, wendet der Kernel hauptsächlich zwei Strategien an: Caching- und E/A-Planungsalgorithmen.
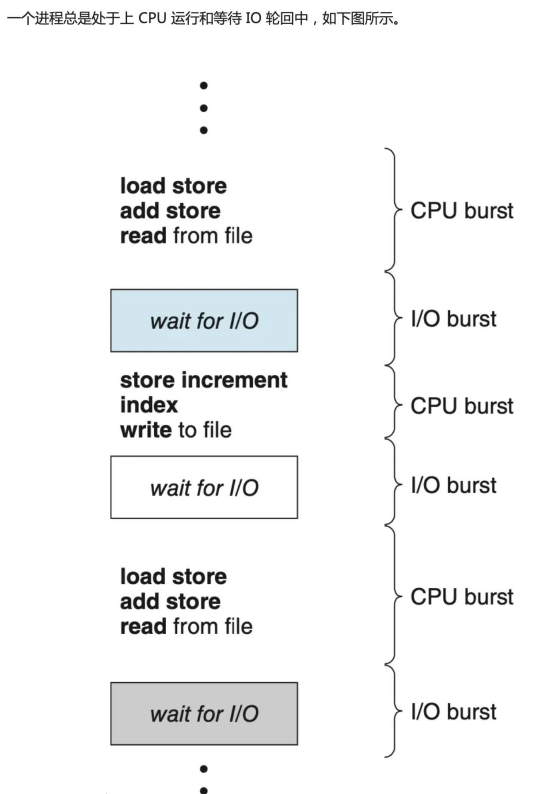
IO Scheduler (IO Scheduler) ist die Methode, mit der das Betriebssystem die Reihenfolge der Übermittlung von IO-Vorgängen auf Blockgeräten bestimmt. Es gibt zwei Existenzzwecke: Der eine besteht darin, den E/A-Durchsatz zu verbessern, und der andere darin, die E/A-Antwortzeit zu verkürzen.
Allerdings sind IO-Durchsatz und IO-Antwortzeit oft widersprüchlich. Um beides so gut wie möglich auszubalancieren, bietet der IO-Scheduler eine Vielzahl von Planungsalgorithmen zur Anpassung an verschiedene IO-Anfrageszenarien. Unter diesen ist DEANLINE der vorteilhafteste Algorithmus für zufällige Lese- und Schreibszenarien wie Datenbanken.
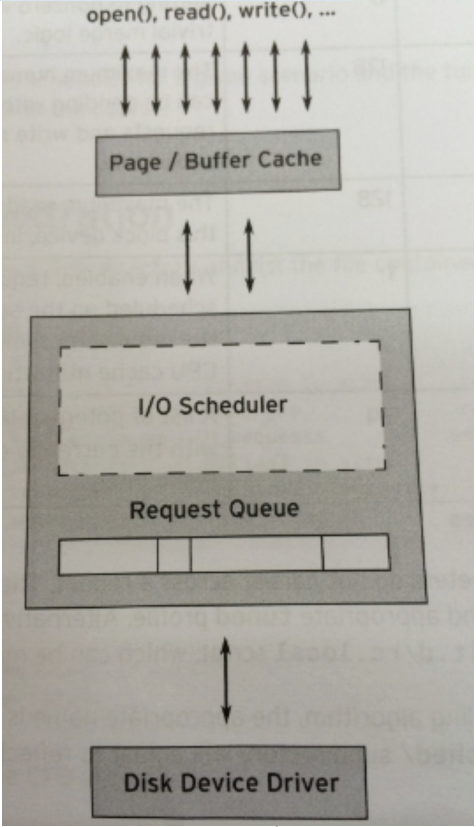
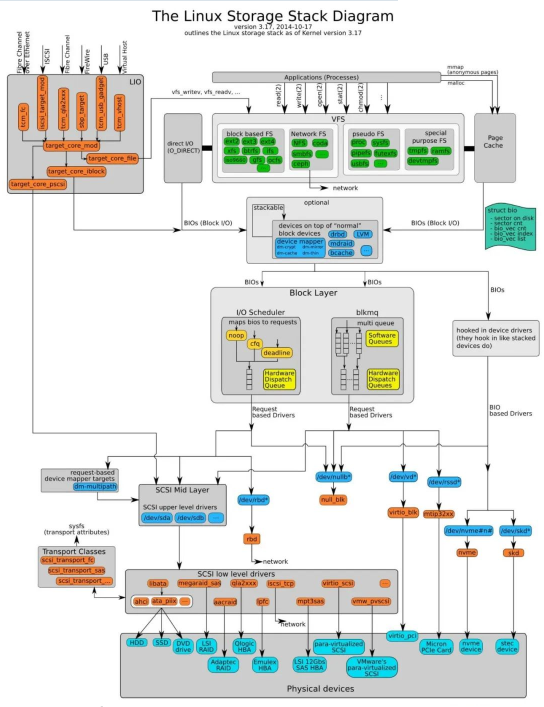
Der Speicherort des IO-Schedulers im Kernel-Stack ist wie folgt:
Das Tragischste an Blockgeräten ist die Festplattenrotation, die ein sehr zeitaufwändiger Prozess ist. Jedes Blockgerät oder jede Partition eines Blockgeräts entspricht seiner eigenen Anforderungswarteschlange (request_queue), und jede Anforderungswarteschlange kann einen E/A-Planer auswählen, um die übermittelten Anforderungen zu koordinieren.
Der Hauptzweck des I/O-Schedulers besteht darin, Anfragen entsprechend ihren entsprechenden Sektornummern auf dem Blockgerät anzuordnen, um Kopfbewegungen zu reduzieren und die Effizienz zu verbessern. Anfragen in der Anfragewarteschlange jedes Geräts werden der Reihe nach beantwortet.
Tatsächlich unterhält jeder Planer selbst zusätzlich zu dieser Warteschlange eine unterschiedliche Anzahl von Warteschlangen zur Verarbeitung übermittelter Anforderungen, und die Anforderung an der Spitze der Warteschlange wird zu gegebener Zeit in die Anforderungswarteschlange verschoben, um auf eine Antwort zu warten.

Die Hauptfunktion des IO-Planers besteht darin, den Bedarf an Festplattenrotation zu reduzieren. Wird hauptsächlich auf zwei Arten erreicht:
Jedes Gerät verfügt über eine eigene entsprechende Anforderungswarteschlange und alle Anforderungen befinden sich vor der Verarbeitung in der Anforderungswarteschlange. Wenn eine neue Anfrage eingeht und festgestellt wird, dass der Standort dieser Anfrage an eine vorherige Anfrage angrenzt, kann sie zu einer Anfrage zusammengeführt werden.
Wenn die zusammengeführte Datei nicht gefunden werden kann, wird sie nach der Drehrichtung der Festplatte sortiert. Normalerweise besteht die Aufgabe des E/A-Schedulers darin, zusammenzuführen und zu sortieren, ohne die Verarbeitungszeit einer einzelnen Anfrage zu sehr zu beeinträchtigen.
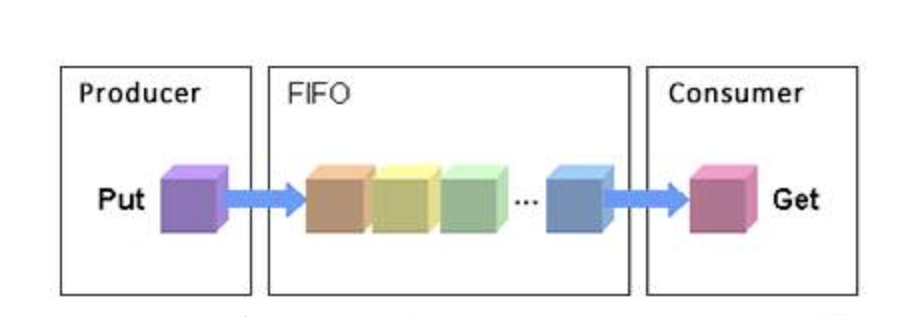
FIFO
Stellen Sie die Eingabe- und Ausgabeanforderungen in eine FIFO-Warteschlange und führen Sie dann die Eingabe- und Ausgabeanforderungen in der Warteschlange in der folgenden Reihenfolge aus: Wenn eine neue Anforderung eingeht:
Wenn es zusammengeführt werden kann, führen Sie es zusammen
Wenn es nicht zusammengeführt werden kann, wird versucht, es zu sortieren. Wenn die Anfragen in der Warteschlange bereits sehr alt sind, kann diese neue Anfrage nicht in die Warteschlange springen und nur am Ende platziert werden. Andernfalls fügen Sie es an der entsprechenden Position ein
Wenn es nicht zusammengeführt werden kann und keine geeignete Position zum Einfügen vorhanden ist, wird es am Ende der Anforderungswarteschlange platziert.
Anwendbare Szenarien
4.1 In Szenarien, in denen Sie die Reihenfolge der Eingabe- und Ausgabeanforderungen nicht ändern möchten;
4.2 Geräte mit intelligenteren Planungsalgorithmen für Ein- und Ausgabe, wie z. B. NAS-Speichergeräte4.3 Die Eingabe- und Ausgabeanforderungen der Oberschichtanwendung wurden sorgfältig optimiert4.4 Festplattengeräte mit nicht rotierendem Kopf, wie z. B. SSD-FestplattenSEIN (am besten versuchen)
IDLE(Leerlauf)
 Die maximale Wartezeit zum Lesen der FIFO-Warteschlange beträgt 500 ms und die maximale Wartezeit zum Schreiben der FIFO-Warteschlange beträgt 5 s (natürlich können diese Parameter manuell eingestellt werden).
Die Priorität der E/A-Anforderungen in der FIFO-Warteschlange ist höher als die in der CFQ-Warteschlange, und die Priorität der Lese-FIFO-Warteschlange ist höher als die Priorität der Schreib-FIFO-Warteschlange. Priorität kann wie folgt ausgedrückt werden:
Die maximale Wartezeit zum Lesen der FIFO-Warteschlange beträgt 500 ms und die maximale Wartezeit zum Schreiben der FIFO-Warteschlange beträgt 5 s (natürlich können diese Parameter manuell eingestellt werden).
Die Priorität der E/A-Anforderungen in der FIFO-Warteschlange ist höher als die in der CFQ-Warteschlange, und die Priorität der Lese-FIFO-Warteschlange ist höher als die Priorität der Schreib-FIFO-Warteschlange. Priorität kann wie folgt ausgedrückt werden:
“
FIFO (Lesen) > FIFO (Schreiben) > CFQ“
Der Fristalgorithmus garantiert die minimale Verzögerungszeit für eine bestimmte E/A-Anfrage. Aus diesem Grund sollte er für DSS-Anwendungen sehr gut geeignet sein.
Deadline ist eigentlich eine Verbesserung gegenüber Elevator:
1. Vermeiden Sie einige Anfragen, die nicht zu lange bearbeitet werden können.
2. Unterscheiden Sie zwischen Lesevorgängen und Schreibvorgängen.
deadline IO unterhält 3 Warteschlangen. Die erste Warteschlange ist die gleiche wie bei Elevator und versucht, nach physischem Standort zu sortieren. Die zweite und die dritte Warteschlange sind beide nach Zeit sortiert. Der Unterschied besteht darin, dass es sich bei der einen um eine Leseoperation und bei der anderen um eine Schreiboperation handelt.
Deadline IO unterscheidet zwischen Lesen und Schreiben, da der Designer davon ausgeht, dass die Anwendung, wenn sie eine Leseanforderung sendet, im Allgemeinen dort blockiert und wartet, bis das Ergebnis zurückgegeben wird. Die Schreibanforderung ist normalerweise nicht die Anforderung der Anwendung, in den Speicher zu schreiben, und der Hintergrundprozess schreibt sie dann zurück auf die Festplatte. Bei Bewerbungen wird in der Regel nicht abgewartet, bis das Schreiben abgeschlossen ist, bevor mit dem Fortfahren fortgefahren wird. Daher sollten Leseanfragen eine höhere Priorität haben als Schreibanfragen.
Bei diesem Design wird jede neue Anfrage zuerst in die erste Warteschlange gestellt. Der Algorithmus ist der gleiche wie der von Elevator und wird auch am Ende der Lese- oder Schreibwarteschlange hinzugefügt. Auf diese Weise verarbeiten wir zunächst einige Anfragen aus der ersten Warteschlange und erkennen gleichzeitig, ob die ersten paar Anfragen in der zweiten/dritten Warteschlange zu lange gewartet haben. Wenn sie einen Schwellenwert überschritten haben, werden sie verarbeitet. Dieser Schwellenwert beträgt 5 ms für Leseanfragen und 5 s für Schreibanfragen.
Persönlich denke ich, dass es am besten ist, diese Art von Partition nicht zum Aufzeichnen von Datenbankänderungsprotokollen zu verwenden, wie z. B. das Online-Protokoll von Oracle, das Binlog von MySQL usw. Denn diese Art von Schreibanforderung ruft normalerweise fsync auf. Wenn das Schreiben nicht abgeschlossen werden kann, wirkt sich dies auch stark auf die Anwendungsleistung aus.
CFQ und DEADLINE konzentrieren sich auf die Erfüllung verstreuter IO-Anfragen. Für kontinuierliche IO-Anfragen, wie z. B. sequentielles Lesen, gibt es keine Optimierung.
Um dem Szenario gemischter zufälliger E/A und sequentieller E/A gerecht zu werden, unterstützt Linux auch den ANTICIPATORY-Planungsalgorithmus. Basierend auf DEADLINE legt ANTICIPATORY ein Wartezeitfenster von 6 ms für jeden Lese-IO fest. Wenn das Betriebssystem innerhalb dieser 6 ms eine Lese-E/A-Anfrage von einem benachbarten Standort erhält, kann diese sofort erfüllt werden.
Die Wahl des IO-Scheduler-Algorithmus hängt sowohl von den Hardwareeigenschaften als auch von den Anwendungsszenarien ab.
Auf herkömmlichen SAS-Festplatten sind CFQ, DEADLINE und ANTICIPATORY eine gute Wahl; für dedizierte Datenbankserver bietet DEADLINE eine gute Leistung in Bezug auf Durchsatz und Antwortzeit.
Bei neuen Solid-State-Laufwerken wie SSD und Fusion IO ist jedoch möglicherweise der einfachste NOOP der beste Algorithmus, da die Optimierung der anderen drei Algorithmen auf der Verkürzung der Suchzeit basiert und Solid-State-Laufwerke keine so- Dies wird als Suchzeit bezeichnet. Und die E/A-Reaktionszeit ist sehr kurz.
Das obige ist der detaillierte Inhalt vonVerstehen Sie die vier wichtigsten IO-Planungsalgorithmen des Linux-Kernels in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































