


Bei der Definition eines Sprachmodells werden häufig grundlegende Wortsegmentierungsmethoden verwendet, um Sätze in Wörter, Unterwörter oder Zeichen zu unterteilen. Die Unterwortsegmentierung ist seit langem die beliebteste Wahl, da sie ein Gleichgewicht zwischen Trainingseffizienz und der Fähigkeit schafft, Wörter außerhalb des Wortschatzes zu verarbeiten. Einige Studien haben jedoch auf Probleme bei der Unterwortsegmentierung hingewiesen, wie z. B. mangelnde Robustheit im Umgang mit Tippfehlern, Änderungen in der Rechtschreibung und Groß-/Kleinschreibung sowie morphologische Veränderungen. Daher müssen diese Probleme beim Entwurf von Sprachmodellen sorgfältig berücksichtigt werden, um die Genauigkeit und Robustheit des Modells zu verbessern.
Daher haben einige Forscher einen Ansatz gewählt, der Bytesequenzen verwendet, d. h. durch eine End-to-End-Zuordnung von Rohdaten zu Vorhersageergebnissen ohne Wortsegmentierung. Im Vergleich zu Unterwortmodellen lassen sich Sprachmodelle auf Byte-Ebene leichter auf verschiedene Schreibformen und morphologische Veränderungen verallgemeinern. Die Modellierung von Text als Bytes bedeutet jedoch, dass die generierten Sequenzen länger sind als die entsprechenden Unterwörter. Um die Effizienz zu verbessern, muss dies durch eine Verbesserung der Architektur erreicht werden.
Autoregressive Transformer nimmt eine dominierende Stellung in der Sprachmodellierung ein, aber sein Effizienzproblem ist besonders ausgeprägt. Der Rechenaufwand steigt quadratisch mit zunehmender Sequenzlänge, was zu einer schlechten Skalierbarkeit für lange Sequenzen führt. Um dieses Problem zu lösen, komprimierten die Forscher die interne Darstellung des Transformers, um lange Sequenzen verarbeiten zu können. Ein Ansatz besteht darin, einen längenbewussten Modellierungsansatz zu entwickeln, der Gruppen von Token innerhalb einer Zwischenschicht zusammenführt und so den Rechenaufwand senkt. Kürzlich haben Yu et al. eine Methode namens MegaByte Transformer vorgeschlagen. Es verwendet Bytefragmente fester Größe, um komprimierte Formen als Unterwörter zu simulieren und so den Rechenaufwand zu reduzieren. Allerdings ist dies derzeit möglicherweise nicht die beste Lösung und erfordert weitere Forschung und Verbesserung.
In einer aktuellen Studie stellten Wissenschaftler der Cornell University ein effizientes und einfaches Sprachmodell auf Byte-Ebene namens MambaByte vor. Dieses Modell ist eine direkte Verbesserung der kürzlich eingeführten Mamba-Architektur. Die Mamba-Architektur basiert auf der State-Space-Model-Methode (SSM), während MambaByte einen effizienteren Auswahlmechanismus einführt, wodurch die Leistung bei der Verarbeitung diskreter Daten wie Text verbessert wird und außerdem eine effiziente GPU-Implementierung bereitgestellt wird. Die Forscher beobachteten kurz die Verwendung von unverändertem Mamba und stellten fest, dass es einen großen Rechenengpass bei der Sprachmodellierung beseitigen konnte, wodurch Patches überflüssig wurden und die verfügbaren Rechenressourcen voll ausgenutzt wurden.

In Experimenten verglichen sie MambaByte mit den Architekturen Transformers, SSM und MegaByte (Patching). Diese Architekturen werden unter festen Parameter- und Recheneinstellungen sowie anhand mehrerer Langtextdatensätze bewertet. Abbildung 1 fasst ihre wichtigsten Ergebnisse zusammen.
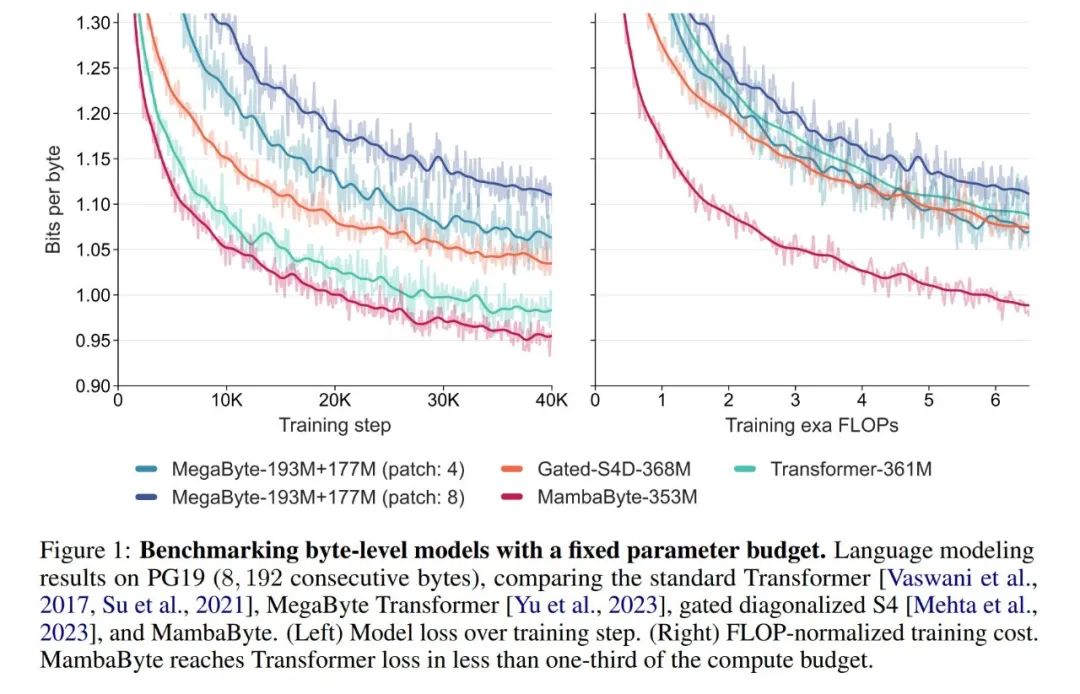
Im Vergleich zu Transformern auf Byte-Ebene bietet MambaByte eine schnellere und leistungsfähigere Lösung, während gleichzeitig die Recheneffizienz deutlich verbessert wurde. Die Forscher verglichen auch tokenfreie Sprachmodelle mit aktuellen Subword-Modellen auf dem neuesten Stand der Technik und stellten fest, dass MambaByte in dieser Hinsicht wettbewerbsfähig ist und längere Sequenzen verarbeiten kann. Die Ergebnisse dieser Studie zeigen, dass MambaByte eine leistungsstarke Alternative zu bestehenden Tokenizern sein kann, die auf ihnen basieren, und voraussichtlich die Weiterentwicklung des End-to-End-Lernens fördern wird.
SSM verwendet Differentialgleichungen erster Ordnung, um die zeitliche Entwicklung verborgener Zustände zu modellieren. Lineares zeitinvariantes SSM hat bei einer Vielzahl von Deep-Learning-Aufgaben gute Ergebnisse gezeigt. Allerdings argumentierten die Mamba-Autoren Gu und Dao kürzlich, dass es der konstanten Dynamik dieser Methoden an einer eingabeabhängigen Kontextauswahl in versteckten Zuständen mangelt, die für Aufgaben wie die Sprachmodellierung notwendig sein könnte. Daher schlugen sie die Mamba-Methode vor, die dynamisch definiert wird, indem eine gegebene Eingabe x(t) ∈ R, ein verborgener Zustand h(t) ∈ R^n und eine Ausgabe y(t) ∈ R als zeitlich variierender kontinuierlicher Zustand verwendet wird zum Zeitpunkt t ist:
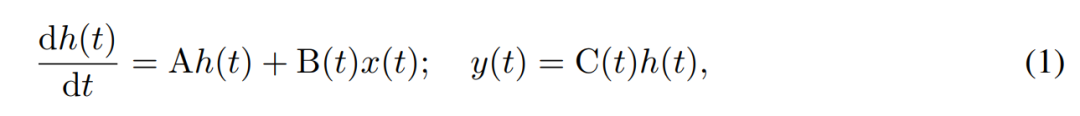
Seine Parameter sind die diagonale zeitinvariante Systemmatrix A∈R^(n×n) und die zeitvariablen Eingabe- und Ausgabematrizen B (t)∈R^ (n× 1) und C (t)∈R^(1×n).
Um diskrete Zeitreihen wie Bytes zu modellieren, muss die kontinuierliche Zeitdynamik in (1) durch Diskretisierung angenähert werden. Dies führt zu einer diskreten latenten Wiederholung mit neuen Matrizen A, B und C bei jedem Zeitschritt, d in der Sprache Diese Schleife wird während der Modellgenerierung angewendet. Die Diskretisierung erfordert, dass jede Eingabeposition einen Zeitschritt hat, nämlich Δ[k], entsprechend x [k] = x (t_k) von
. Aus Δ[k] können dann die zeitdiskreten Matrizen A, B und C berechnet werden. Abbildung 2 zeigt, wie Mamba diskrete Sequenzen modelliert. 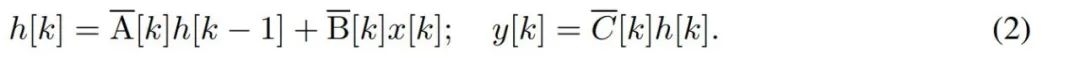
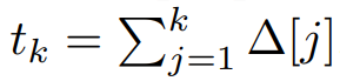 In Mamba ist der SSM-Term eingabeselektiv, das heißt, B, C und Δ werden als Funktionen der Eingabe x [k]∈R^d definiert:
In Mamba ist der SSM-Term eingabeselektiv, das heißt, B, C und Δ werden als Funktionen der Eingabe x [k]∈R^d definiert:
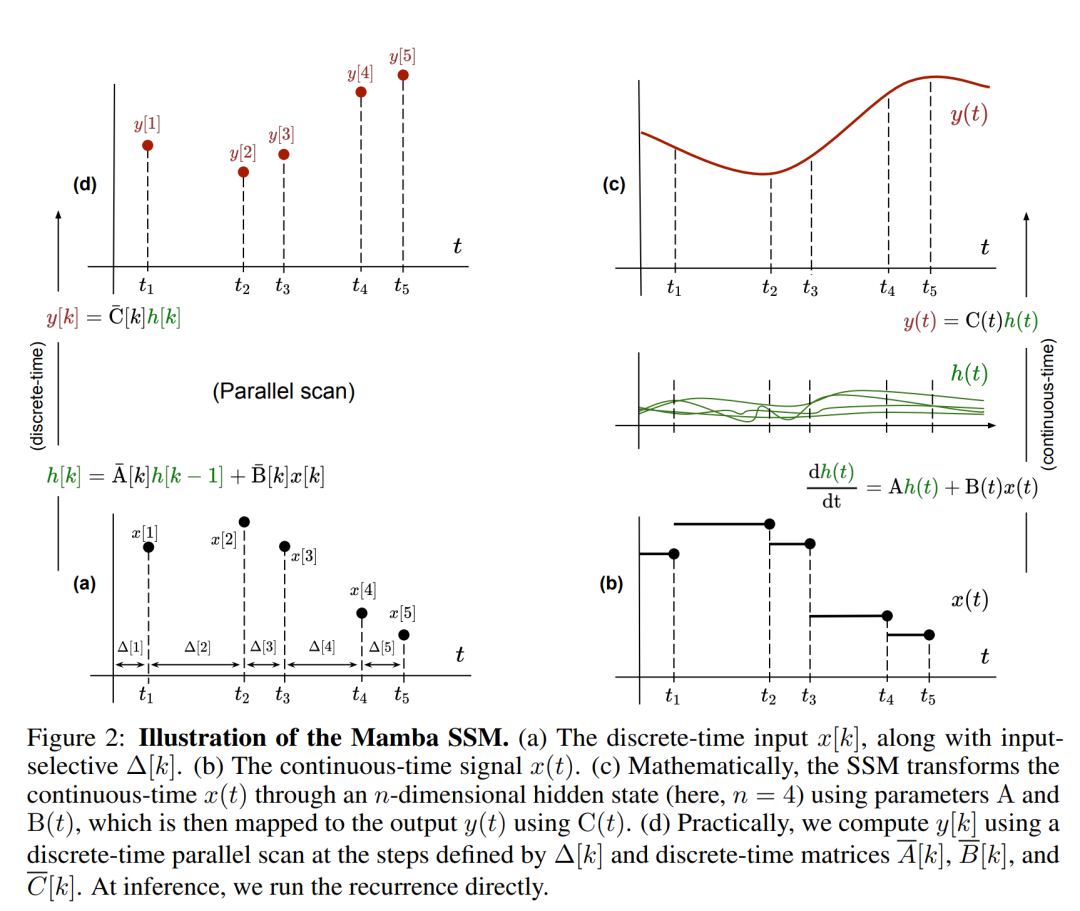
wobei W_B ∈ R^(n×d) (C ist ähnlich definiert), W_Δ ∈ R^(d×r) und W_R ∈ R^(r×d) (für einige r ≪d) lernbare Gewichte sind, und Softplus gewährleistet Positivität. Beachten Sie, dass für jede Eingabedimension d die SSM-Parameter A, B und C gleich sind, die Anzahl der Zeitschritte Δ jedoch unterschiedlich ist. Dies führt zu einer verborgenen Zustandsgröße von n × d für jeden Zeitschritt k.
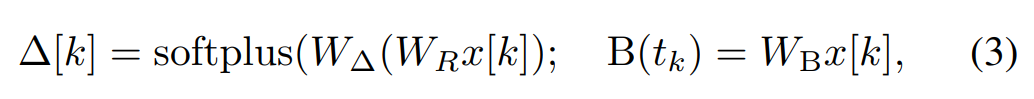 Mamba bettet diese SSM-Schicht in ein vollständiges Sprachmodell für neuronale Netze ein. Konkret verwendet das Modell eine Reihe von Gating-Schichten, die von früheren Gating-SSMs inspiriert sind. Abbildung 3 zeigt die Mamba-Architektur, die eine SSM-Schicht mit einem Gated Neural Network kombiniert.
Mamba bettet diese SSM-Schicht in ein vollständiges Sprachmodell für neuronale Netze ein. Konkret verwendet das Modell eine Reihe von Gating-Schichten, die von früheren Gating-SSMs inspiriert sind. Abbildung 3 zeigt die Mamba-Architektur, die eine SSM-Schicht mit einem Gated Neural Network kombiniert.
Paralleler Scan der linearen Wiederholung. Zur Trainingszeit haben die Autoren Zugriff auf die gesamte Sequenz x, was eine effizientere Berechnung der linearen Wiederholung ermöglicht. Untersuchungen von Smith et al. [2023] zeigen, dass die sequentielle Wiederholung bei linearem SSM mithilfe effizienter paralleler Scans effizient berechnet werden kann. Für Mamba ordnet der Autor die Wiederholung zunächst L-Tupelsequenzen zu, wobei e_k =
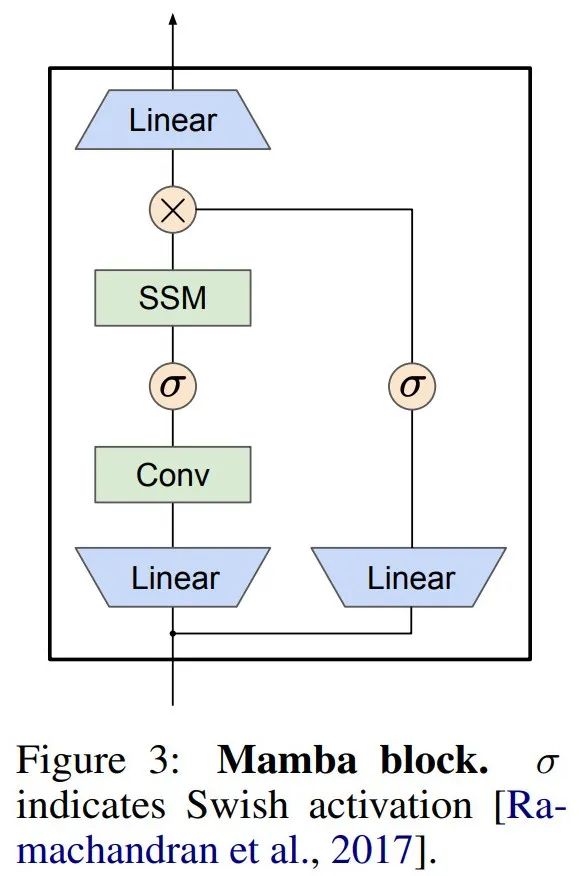 , und definiert dann einen Assoziationsoperator
, und definiert dann einen Assoziationsoperator
, so dass  . Schließlich wenden sie parallele Scans an, um die Sequenz zu berechnen
. Schließlich wenden sie parallele Scans an, um die Sequenz zu berechnen  . Im Allgemeinen dauert dies
. Im Allgemeinen dauert dies 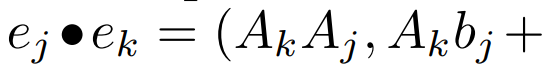
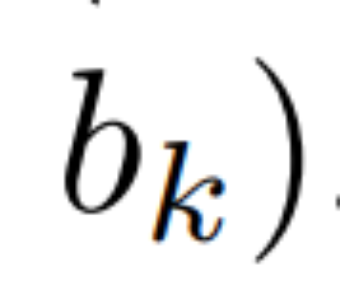 Zeit, wenn L/2-Prozessoren verwendet werden, wobei
Zeit, wenn L/2-Prozessoren verwendet werden, wobei 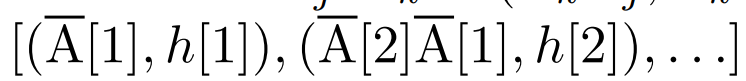 die Kosten der Matrixmultiplikation sind. Beachten Sie, dass A eine Diagonalmatrix ist und die lineare Wiederholung parallel in
die Kosten der Matrixmultiplikation sind. Beachten Sie, dass A eine Diagonalmatrix ist und die lineare Wiederholung parallel in 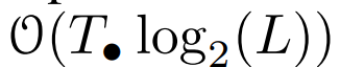 Zeit und O (nL) Raum berechnet werden kann. Parallele Scans mit Diagonalmatrizen laufen ebenfalls sehr effizient und erfordern nur O (nL) FLOPs.
Zeit und O (nL) Raum berechnet werden kann. Parallele Scans mit Diagonalmatrizen laufen ebenfalls sehr effizient und erfordern nur O (nL) FLOPs.
Tabelle 2 zeigt die Bits pro Byte (BPB) für jeden Datensatz. In diesem Experiment verwenden die Modelle MegaByte758M+262M und MambaByte die gleiche Anzahl von FLOPs pro Byte (siehe Tabelle 1). Die Autoren stellten fest, dass MambaByte MegaByte bei allen Datensätzen durchweg übertraf. Darüber hinaus weisen die Autoren darauf hin, dass sie MambaByte aufgrund von Finanzierungsengpässen nicht auf den gesamten 80 B-Bytes trainieren konnten, MambaByte jedoch MegaByte mit 63 % weniger Rechenaufwand und 63 % weniger Trainingsdaten immer noch übertraf. Darüber hinaus übertrifft MambaByte-353M Transformer und PerceiverAR im Byte-Maßstab.
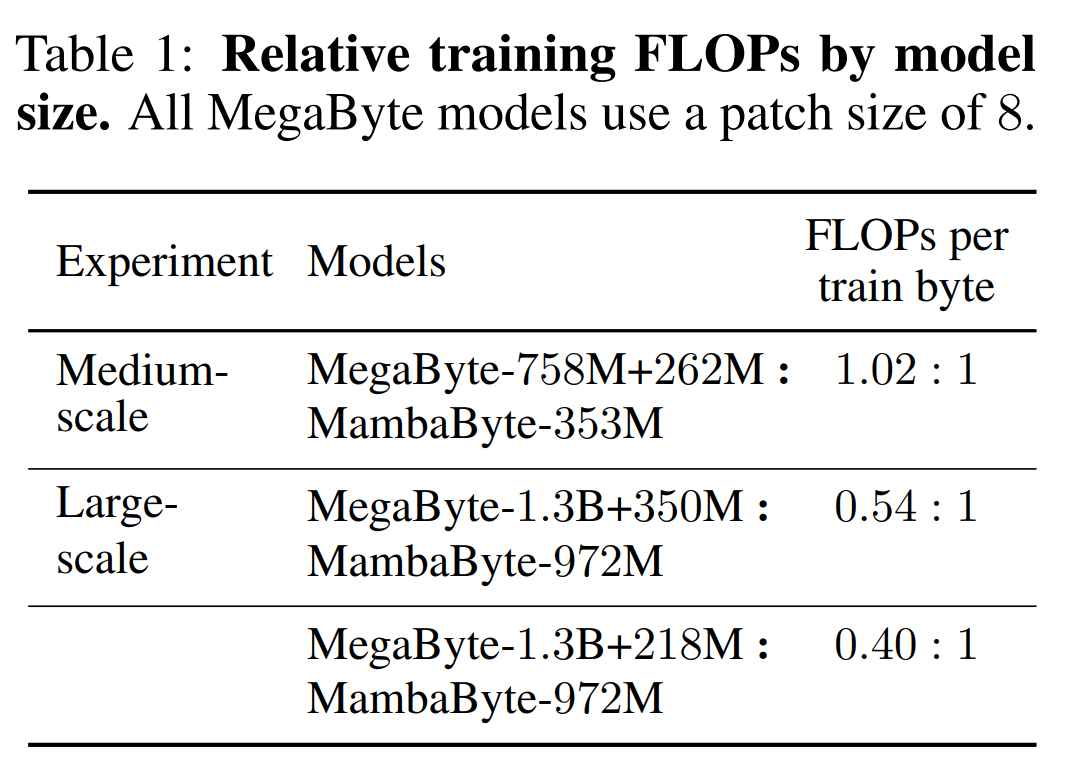
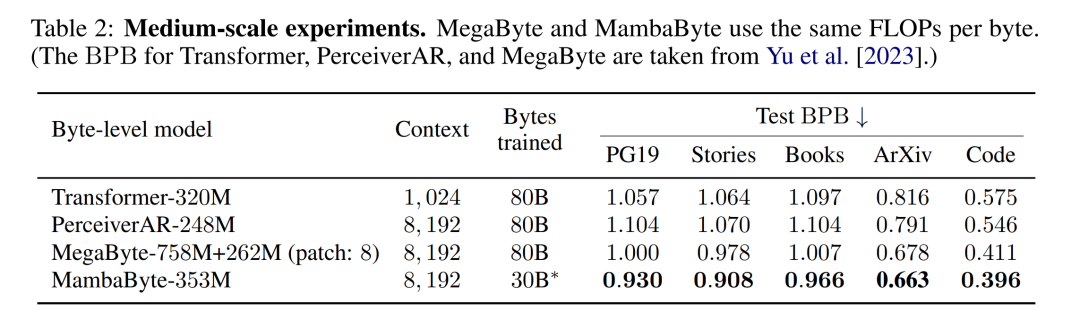
Warum schneidet MambaByte in so wenigen Trainingsschritten besser ab als ein viel größeres Modell? Abbildung 1 untersucht diese Beziehung weiter, indem Modelle mit der gleichen Anzahl von Parametern betrachtet werden. Die Abbildung zeigt, dass bei MegaByte-Modellen mit derselben Parametergröße das Modell mit weniger Eingabepatching eine bessere Leistung erbringt, nach der Berechnung der Normalisierung jedoch eine ähnliche Leistung erbringt. Tatsächlich ist der Transformer in voller Länge zwar in absoluten Zahlen langsamer, verhält sich aber nach der rechnerischen Normalisierung ähnlich wie MegaByte. Im Gegensatz dazu kann der Wechsel zur Mamba-Architektur die Rechennutzung und Modellleistung erheblich verbessern.
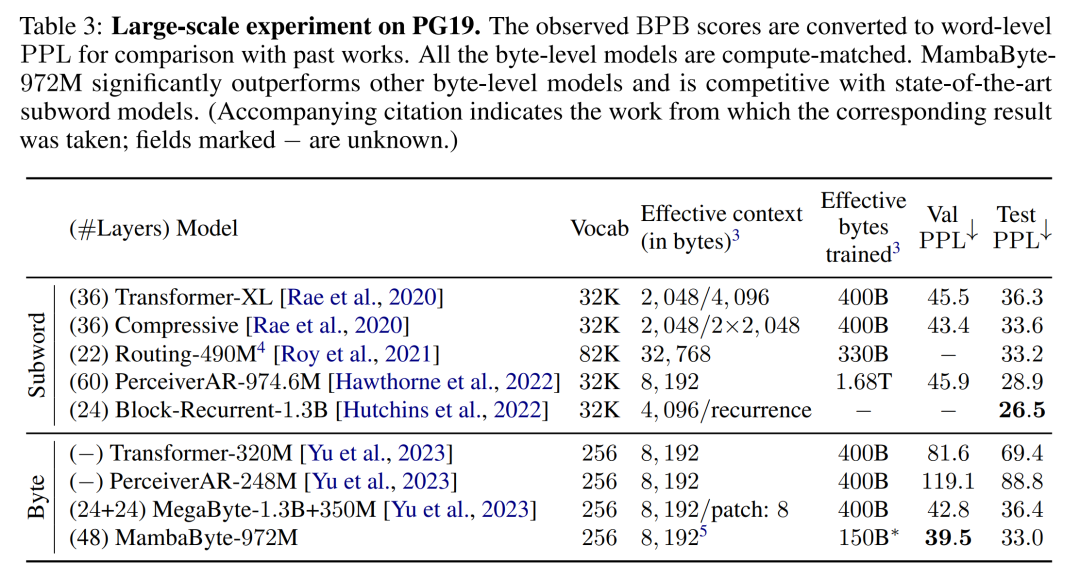
Basierend auf diesen Erkenntnissen vergleicht Tabelle 3 größere Versionen dieser Modelle im PG19-Datensatz. In diesem Experiment verglichen die Autoren MambaByte-972M mit MegaByte-1.3B+350M und anderen Modellen auf Byte-Ebene sowie mehreren SOTA-Subwortmodellen. Sie fanden heraus, dass MambaByte-972M alle Modelle auf Byte-Ebene übertraf und mit Subwort-Modellen konkurrenzfähig war, selbst wenn es mit nur 150 B-Bytes trainiert wurde.
Textgenerierung. Autoregressive Inferenz in Transformer-Modellen erfordert die Zwischenspeicherung des gesamten Kontexts, was sich erheblich auf die Generierungsgeschwindigkeit auswirkt. Bei MambaByte gibt es diesen Engpass nicht, da es nur einen zeitlich variablen verborgenen Zustand pro Schicht beibehält, sodass die Zeit pro Generierungsschritt konstant ist. Tabelle 4 vergleicht die Textgenerierungsgeschwindigkeit von MambaByte-972M und MambaByte-1.6B mit MegaByte-1.3B+350M auf einer A100 80 GB PCIe GPU. Obwohl MegaByte die Generierungskosten durch Patchen erheblich reduziert, stellten sie fest, dass MambaByte bei ähnlichen Parametereinstellungen aufgrund der Verwendung der Schleifengenerierung 2,6-mal schneller ist.

Das obige ist der detaillierte Inhalt vonOhne die Aufteilung in Token kann Mamba auf diese Weise auch effizient direkt aus Bytes lernen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie die Auswahlfunktion
So verwenden Sie die Auswahlfunktion
 Der Unterschied zwischen PHP und JS
Der Unterschied zwischen PHP und JS
 Tutorial zur Symboleingabe in voller Breite
Tutorial zur Symboleingabe in voller Breite
 BTC-Preis heute
BTC-Preis heute
 Wie viele Menschen können Sie mit Douyin großziehen?
Wie viele Menschen können Sie mit Douyin großziehen?
 Die Rolle von Isset in PHP
Die Rolle von Isset in PHP
 Die Funktion des Zwischenrelais
Die Funktion des Zwischenrelais
 Was tun bei Verbindungsfehlern?
Was tun bei Verbindungsfehlern?
 Welches Format ist m4a?
Welches Format ist m4a?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



