


Die legendäre „Zauberwaffe“ der GPT-4 – MoE-Architektur (Mixed Expert), Sie können sie selbst verwenden!
Ein Guru für maschinelles Lernen erzählte auf Hugging Face, wie man ein komplettes MoE-System von Grund auf aufbaut.

Dieses Projekt wird vom Autor MakeMoE genannt und der Prozess von der Aufmerksamkeitskonstruktion bis zur Bildung eines vollständigen MoE-Modells wird ausführlich beschrieben.
Nach Angaben des Autors wurde MakeMoE von dem Makemore des OpenAI-Gründungsmitglieds Andrej Karpathy inspiriert und basiert darauf.
makemore ist ein Lehrprojekt für die Verarbeitung natürlicher Sprache und maschinelles Lernen, das Lernenden helfen soll, einige grundlegende Modelle zu verstehen und umzusetzen.
In ähnlicher Weise hilft MakeMoE den Lernenden auch dabei, im schrittweisen Aufbauprozess ein tieferes Verständnis des hybriden Expertenmodells zu erlangen.
Worum geht es in diesem „Leitfaden zum Händereiben“ genau?
Im Vergleich zu Karpathys Makemore ersetzt MakeMoE das isolierte Feedforward-Neuronale Netzwerk durch eine spärliche Expertenmischung und fügt gleichzeitig die notwendige Gating-Logik hinzu.
Da dabei die ReLU-Aktivierungsfunktion verwendet werden muss, wird gleichzeitig die Standardinitialisierungsmethode in makemore durch die Kaiming He-Methode ersetzt.

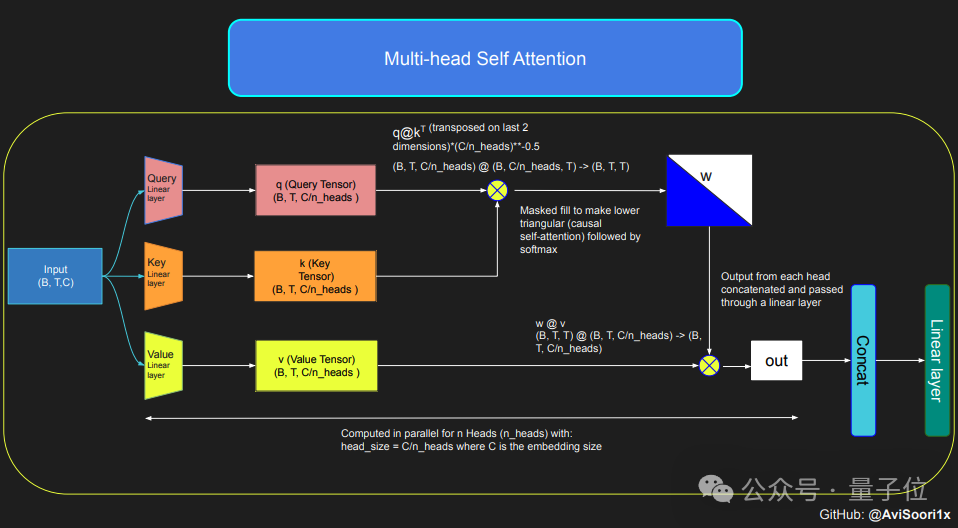
Wenn Sie ein MoE-Modell erstellen möchten, müssen Sie zunächst den Selbstaufmerksamkeitsmechanismus verstehen.
Das Modell wandelt zunächst die Eingabesequenz durch lineare Transformation in Parameter um, die durch Abfragen (Q), Schlüssel (K) und Werte (V) dargestellt werden.
Diese Parameter werden dann zur Berechnung der Aufmerksamkeitswerte verwendet, die bestimmen, wie viel Aufmerksamkeit das Modell jeder Position in der Sequenz bei der Generierung jedes Tokens schenkt.
Um die autoregressiven Eigenschaften des Modells beim Generieren von Text sicherzustellen, d. Dieser Mechanismus wird implementiert, indem der Aufmerksamkeitswert unverarbeiteter Positionen durch eine Maske auf negativ unendlich gesetzt wird, sodass die Gewichtung dieser Positionen Null wird.
Mehrkopfkausalität ermöglicht es dem Modell, mehrere solcher Aufmerksamkeitsberechnungen parallel durchzuführen, wobei sich jeder Kopf auf unterschiedliche Teile der Sequenz konzentriert.
 Nach Abschluss der Konfiguration des Selbstaufmerksamkeitsmechanismus können Sie das Expertenmodul erstellen. Das „Expertenmodul“ ist hier ein mehrschichtiges Perzeptron.
Nach Abschluss der Konfiguration des Selbstaufmerksamkeitsmechanismus können Sie das Expertenmodul erstellen. Das „Expertenmodul“ ist hier ein mehrschichtiges Perzeptron.
Jedes Expertenmodul enthält eine lineare Ebene, die den Einbettungsvektor auf eine größere Dimension abbildet, und dann über eine nichtlineare Aktivierungsfunktion (z. B. ReLU) und eine weitere lineare Ebene, um den Vektor wieder auf die ursprüngliche Einbettungsdimension abzubilden.
Dieses Design ermöglicht es jedem Experten, sich auf die Verarbeitung verschiedener Teile der Eingabesequenz zu konzentrieren, und nutzt das Gating-Netzwerk, um zu entscheiden, welche Experten bei der Generierung jedes Tokens aktiviert werden sollen.
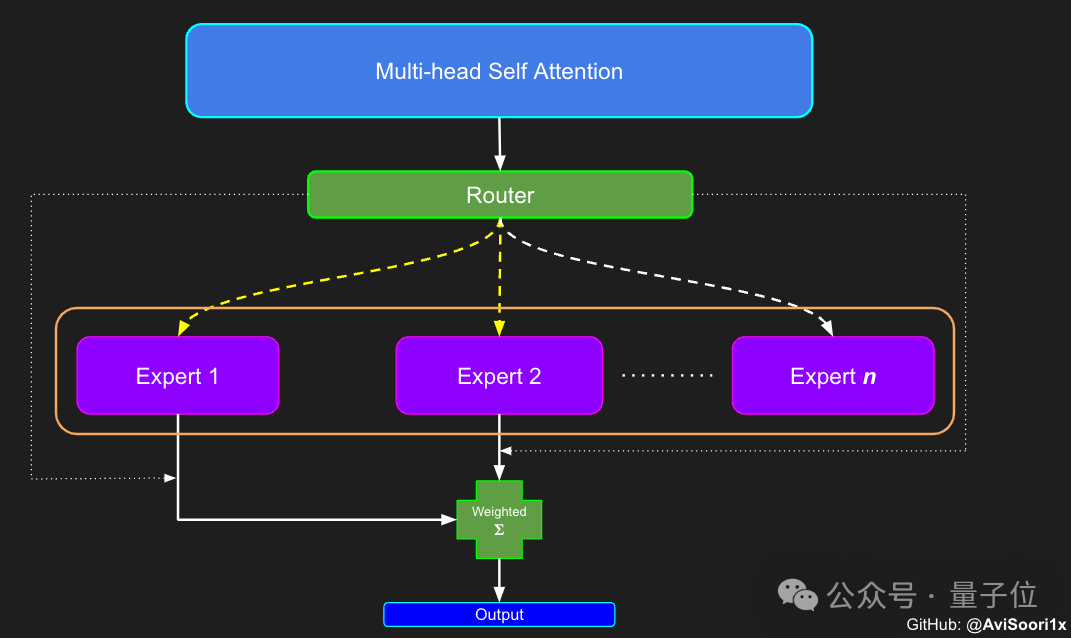 Der nächste Schritt besteht also darin, mit dem Aufbau der Komponente für die Zuweisung und Verwaltung von Experten zu beginnen – dem Gate-Control-Netzwerk.
Der nächste Schritt besteht also darin, mit dem Aufbau der Komponente für die Zuweisung und Verwaltung von Experten zu beginnen – dem Gate-Control-Netzwerk.
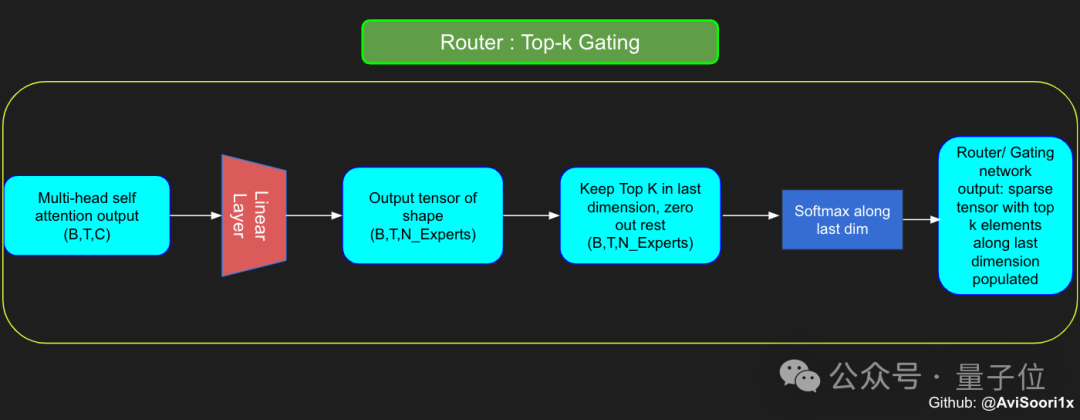
Das Gating-Netzwerk wird hier auch durch eine lineare Schicht implementiert, die die Ausgabe der Selbstaufmerksamkeitsschicht auf die Anzahl der Expertenmodule abbildet.
Die Ausgabe dieser linearen Ebene ist ein Bewertungsvektor. Jede Bewertung stellt die Bedeutung des entsprechenden Expertenmoduls für den aktuell verarbeiteten Token dar.
Das Gated-Netzwerk berechnet die Top-k-Werte dieses Bewertungsvektors, zeichnet seinen Index auf und wählt daraus dann die höchsten Top-k-Bewertungen aus, um die entsprechende Ausgabe des Expertenmoduls zu gewichten.
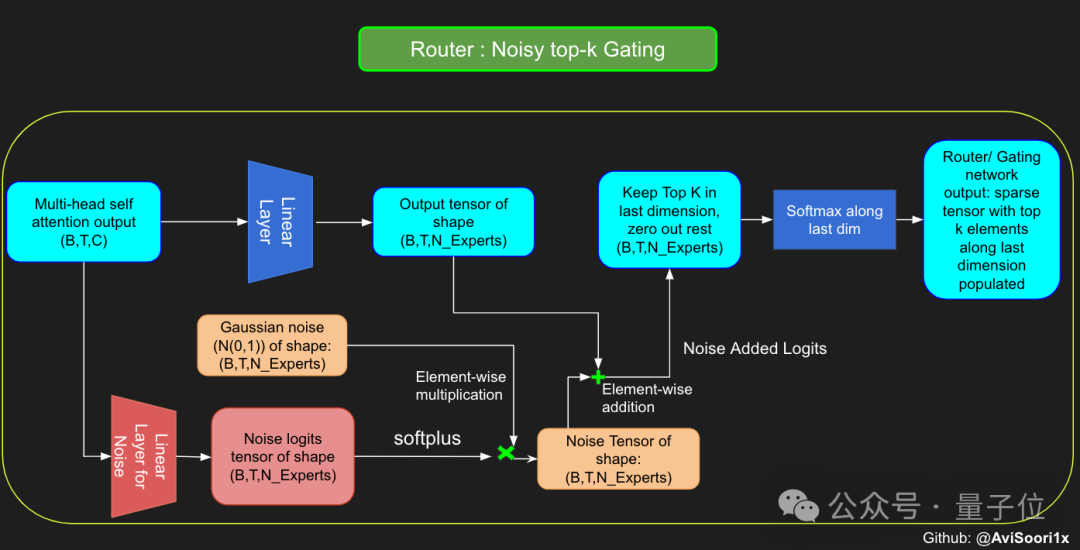
 Um die Erkundbarkeit des Modells während des Trainingsprozesses zu erhöhen, hat der Autor auch Rauschen eingeführt, um zu vermeiden, dass alle Token tendenziell von denselben Experten verarbeitet werden.
Um die Erkundbarkeit des Modells während des Trainingsprozesses zu erhöhen, hat der Autor auch Rauschen eingeführt, um zu vermeiden, dass alle Token tendenziell von denselben Experten verarbeitet werden.
Dieses Rauschen wird normalerweise durch Hinzufügen von zufälligem Gauß-Rauschen zum Bruchvektor erreicht.
 Nach Erhalt der Ergebnisse multipliziert das Modell selektiv die Top-k-Werte mit den Ausgaben der Top-k-Experten für den entsprechenden Token und addiert sie dann zu einer gewichteten Summe, um die Ausgabe des Modells zu bilden.
Nach Erhalt der Ergebnisse multipliziert das Modell selektiv die Top-k-Werte mit den Ausgaben der Top-k-Experten für den entsprechenden Token und addiert sie dann zu einer gewichteten Summe, um die Ausgabe des Modells zu bilden.
Abschließend fügen Sie diese Module zusammen, um ein MoE-Modell zu erhalten.
Für den oben genannten gesamten Prozess hat der Autor den entsprechenden Code bereitgestellt. Weitere Informationen hierzu finden Sie im Originalartikel.
Darüber hinaus hat der Autor auch End-to-End-Jupyter-Notizen erstellt, die beim Erlernen der einzelnen Module direkt ausgeführt werden können.
Wenn Sie Interesse haben, lernen Sie es schnell!
Originaladresse: https://huggingface.co/blog/AviSoori1x/makemoe-from-scratchNotizversion (GitHub): https://github.com/AviSoori1x/makeMoE/tree/main
Das obige ist der detaillierte Inhalt vonMoE-Leitfaden zum Bau großer Modelle: Nullbasierte manuelle Baumethoden, Tutorials auf Master-Niveau enthüllt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 So konvertieren Sie NEF in das JPG-Format
So konvertieren Sie NEF in das JPG-Format
 photoshare.db
photoshare.db
 Datenbank drei Paradigmen
Datenbank drei Paradigmen
 Was wird verteilt?
Was wird verteilt?
 Der Unterschied zwischen a++ und ++a
Der Unterschied zwischen a++ und ++a
 Gängige Codierungsmethoden
Gängige Codierungsmethoden
 Warum Windows nicht auf den angegebenen Gerätepfad oder die angegebene Datei zugreifen kann
Warum Windows nicht auf den angegebenen Gerätepfad oder die angegebene Datei zugreifen kann








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



