


Ein weiterer Alibaba-Artikel mit dem Titel „Dance Work“ sorgte nach AnimateAnyone für Aufsehen
Jetzt reicht es aus, ein Gesichtsfoto und eine einfache Beschreibung hochzuladen, und schon kann man überall tanzen!
Zum Beispiel das Tanzvideo von „Cleaning the Glass“ unten:
 Bild
Bild
Alles, was Sie tun müssen, ist ein Porträtfoto hochzuladen und die entsprechenden Eingabeaufforderungsinformationen einzugeben
In den goldenen Blättern des Herbstes, Ein Mädchen. Tragen Sie ein hellblaues Kleid und tanzen Sie mit einem Lächeln.
Wenn sich die Aufforderungen ändern, ändern sich auch der Hintergrund und die Kleidung der Figur. Wir können zum Beispiel noch ein paar Sätze ändern:
Ein Mädchen lächelt und tanzt in einem Holzhaus. Sie trägt einen Pullover und eine Hose.
Ein Mädchen lächelt und tanzt auf dem Times Square und trägt ein kleiderähnliches weißes Hemd mit langen Hosen.
 Bilder
Bilder
Dies ist Alis neueste Forschung – DreaMoving, die sich darauf konzentriert, jeden zu jeder Zeit und an jedem Ort tanzen zu lassen.
 Bilder
Bilder
Und nicht nur echte Menschen, sondern auch Zeichentrick- und Animationsfiguren können festgehalten werden~
 Bilder
Bilder
Sobald das Projekt herauskam, erregte es auch die Aufmerksamkeit vieler Internetnutzer Nachdem ich den Effekt gesehen hatte, nannte ich ihn „Unglaublich“~
 Bild
Bild
Also, wie wurde dieses Ergebnis erzielt? Wie wurde diese Forschung durchgeführt?
Obwohl das Aufkommen von Text-to-Video (T2V)-Modellen wie Stable Video Diffusion und Gen2 große Durchbrüche im Bereich der Videogenerierung gebracht hat, steht es immer noch vor vielen Herausforderungen
Zum Beispiel: In Bezug auf Datensätze mangelt es derzeit an Open-Source-Datensätzen für menschliche Tanzvideos und es ist schwierig, entsprechende genaue Textbeschreibungen zu erhalten, was es für Modelle schwierig macht, Videos mit Vielfalt, Bildkonsistenz und längerer Dauer zu erstellen
Und auch im Bereich der menschzentrierten Content-Generierung sind Personalisierung und Steuerbarkeit der generierten Ergebnisse zentrale Faktoren.
 Bilder
Bilder
Um diese beiden Herausforderungen zu bewältigen, begann das Alibaba-Team zunächst mit der Verarbeitung des Datensatzes
Die Forscher sammelten zunächst etwa 1.000 hochwertige menschliche Tanzvideos aus dem Internet. Anschließend schneiden sie diese Videos in etwa 6000 kurze Videos (jeweils 8 bis 10 Sekunden), um sicherzustellen, dass die Videoclips keine Übergänge und Spezialeffekte enthalten, was dem Training des Zeitmodells förderlich ist
Außerdem der Reihe nach Um Textbeschreibungen der Videos zu generieren, verwendeten sie Minigpt-v2 als Videountertitel (Video Captioner), insbesondere die „Grounding“-Version. Die Anweisung besteht darin, den Frame detailliert zu beschreiben.
Durch die Generierung von Untertiteln basierend auf dem zentralen Schlüsselbild können das Thema und der Hintergrundinhalt des Videoclips genau beschrieben werden
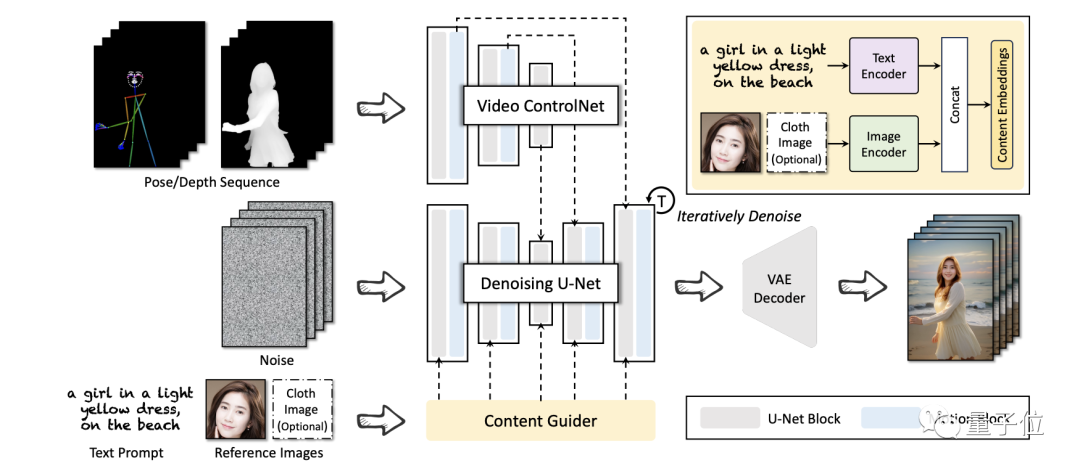
In Bezug auf den Rahmen schlug das Alibaba-Team ein Modell namens DreaMoving vor, das auf Stable Diffusion basiert.
Es besteht hauptsächlich aus drei neuronalen Netzen, darunter Denoising U-Net, Video ControlNet und Content Guider.
 Bilder
Bilder
Unter diesen ist Video ControlNet ein Bildsteuerungsnetzwerk, das nach jedem U-Net-Block in Motion Block eingefügt wird und die Steuersequenz (Pose oder Tiefe) in zusätzliche zeitliche Residuen verarbeitet.
Die Rauschunterdrückung von U-Net ist eine Ableitung von Stable-Diffusion U- Netz, mit Bewegungsblöcken zur Videogenerierung.
Der Content Guider überträgt eingegebene Textaufforderungen und Aussehensausdrücke (z. B. Gesichter) an den eingebetteten Inhalt.
Auf diese Weise ist DreaMoving in der Lage, qualitativ hochwertige, hochauflösende Videos
 Bilder
Bilder
zu generieren, aber leider gibt es derzeit keinen Open-Source-Code für das DreaMoving-Projekt.
Wer sich dafür interessiert, kann zunächst darauf achten und auf die Veröffentlichung des Open-Source-Codes warten~
Bitte beachten Sie den folgenden Link: [1]https://dreamoving.github.io/dreamoving/ [2]https:// arxiv.org/abs/2312.05107[3]https://twitter.com/ProperPrompter/status/1734192772465258499[4]https://github.com/dreamoving/dreamoving-project
Das obige ist der detaillierte Inhalt vonAli ist erneut innovativ: Sie können den Tanz „Cleaning the Glass' mit einem Satz und einem menschlichen Gesicht realisieren, und Kostüm und Hintergrund können frei gewechselt werden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So fangen Sie Zeichenfolgen in der Shell ab
So fangen Sie Zeichenfolgen in der Shell ab
 Pycharm-Methode zum Suchen von Dateien
Pycharm-Methode zum Suchen von Dateien
 So beheben Sie die Computermeldung, dass nicht genügend Arbeitsspeicher vorhanden ist
So beheben Sie die Computermeldung, dass nicht genügend Arbeitsspeicher vorhanden ist
 Verwendung von Eigenschaftsbeschreibungen
Verwendung von Eigenschaftsbeschreibungen
 So verwenden Sie Return in der C-Sprache
So verwenden Sie Return in der C-Sprache
 Einführung in häufig verwendete Windows-Registrierungsbefehle
Einführung in häufig verwendete Windows-Registrierungsbefehle
 Welche Designmuster verwendet Laravel?
Welche Designmuster verwendet Laravel?
 Was soll ich tun, wenn die sekundäre Webseite nicht geöffnet werden kann?
Was soll ich tun, wenn die sekundäre Webseite nicht geöffnet werden kann?

























