


Die Zeitreihenfusion ist ein wirksamer Weg, um die Wahrnehmungsfähigkeit der 3D-Zielerkennung beim autonomen Fahren zu verbessern. Die aktuelle Methode weist jedoch Probleme wie Kosten und Mehraufwand auf, wenn sie in tatsächlichen autonomen Fahrszenarien angewendet wird. Der neueste Forschungsartikel „Abfragebasierte explizite Bewegungs-Timing-Fusion zur 3D-Zielerkennung“ schlug eine neue Timing-Fusion-Methode in NeurIPS 2023 vor, die spärliche Abfragen als Objekt der Timing-Fusion verwendet und explizite Bewegungsinformationen verwendet, um Timing-Aufmerksamkeitsmatrizen zu generieren, an die man sich anpassen kann die Eigenschaften großräumiger Punktwolken. Diese Methode wurde von Forschern der Huazhong University of Science and Technology und Baidu vorgeschlagen und heißt QTNet: eine zeitliche Fusionsmethode zur 3D-Zielerkennung basierend auf Abfrage und expliziter Bewegung. Experimente haben gezeigt, dass QTNet nahezu ohne Mehrkosten konsistente Leistungsverbesserungen für Punktwolken, Bilder und multimodale Detektoren bewirken kann. Link zum Papier: https://openreview.net/pdf?id =gySmwdmVDF
Code Link: https://github.com/AlmoonYsl/QTNet
Aufgrund der Bewegung des eigenen Fahrzeugs in tatsächlichen Szenen sind die Punktwolken/Bilder der beiden Frames in Koordinatensystemen häufig falsch ausgerichtet, und in praktischen Anwendungen ist es unmöglich, alle historischen Frames im aktuellen Frame erneut weiterzuleiten durch das Netzwerk zur Extraktion von Merkmalen ausgerichteter Punktwolken/Bilder. Daher verwendet dieser Artikel die Speicherbank, um nur die aus historischen Frames erhaltenen Abfragemerkmale und die entsprechenden Erkennungsergebnisse zu speichern, um wiederholte Berechnungen zu vermeiden. 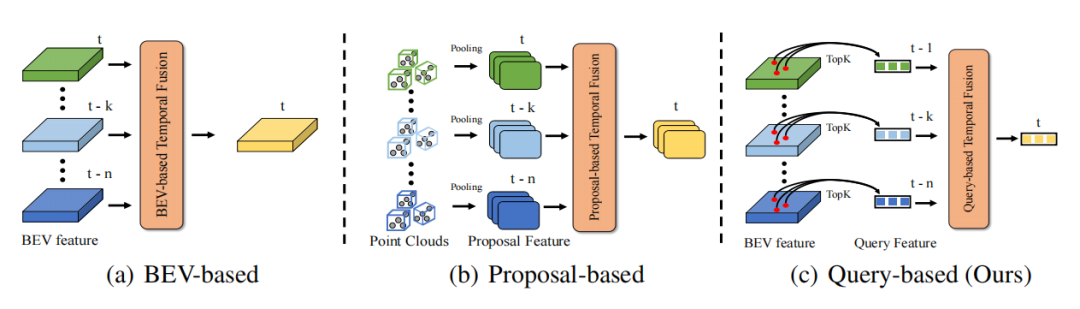
Wie im Framework-Diagramm gezeigt, umfasst QTNet einen 3D-Objektdetektor mit einer 3D-DETR-Struktur (LiDAR, Kamera und Multimodal sind verfügbar), eine Speicherbank und ein bewegungsgesteuertes Temporal Modeling Module (MTM) für die Timing-Fusion. QTNet erhält die Abfragemerkmale und Erkennungsergebnisse des entsprechenden Frames über den 3D-Zieldetektor der DETR-Struktur und sendet die erhaltenen Abfragemerkmale und Erkennungsergebnisse in einer FIFO-Methode (First-In, First-Out-Warteschlange) an die Speicherbank. Die Anzahl der Speicherbänke wird auf die Anzahl der Frames eingestellt, die für die Timing-Fusion erforderlich sind. Für die Timing-Fusion liest QTNet Daten aus der Speicherbank, beginnend mit dem entferntesten Moment, und verwendet das MTM-Modul, um iterativ alle Funktionen in der Speicherbank vom -Frame zum -Frame zu fusionieren, um die Abfragefunktionen des aktuellen zu verbessern Rahmen und Verfeinern des Erkennungsergebnisses entsprechend dem aktuellen Rahmen basierend auf der erweiterten Abfragefunktion.
Konkret verschmilzt QTNet die Abfragefunktionen und der -Frames mit den - und -Frames und erhält die erweiterten Abfragefunktionen der -Frames. Anschließend verschmilzt QTNet die Abfragefunktionen der Frames und . Auf diese Weise wird es durch Iteration kontinuierlich in den -Rahmen integriert. Beachten Sie, dass das hier verwendete MTM vom -Frame bis zum -Frame alle Parameter gemeinsam nutzt.
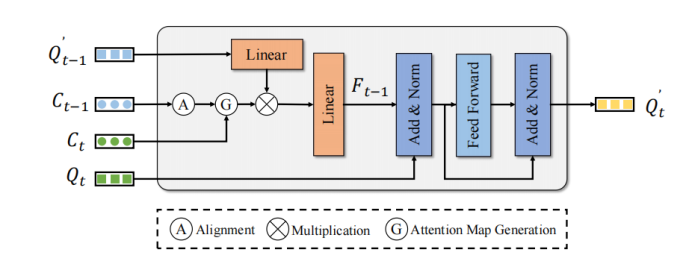
MTM verwendet die Mittelpunktposition des Objekts, um explizit die Aufmerksamkeitsmatrix von Frame Query und Frame Query zu generieren. Gegeben sind die Ego-Pose-Matrix und , der Mittelpunkt des Objekts und die Geschwindigkeit. Zuerst verwendet MTM die Ego-Pose und die Geschwindigkeitsinformationen der Objektvorhersage, um das Objekt im vorherigen Frame zum nächsten Frame zu bewegen und die Koordinatensysteme der beiden Frames auszurichten:
Dann übergibt der Frame-Objektmittelpunkt und den rahmenkorrigierter Mittelpunkt Konstruieren Sie eine euklidische Kostenmatrix. Um mögliche falsche Übereinstimmungen zu vermeiden, verwendet dieser Artikel außerdem die Kategorie und den Distanzschwellenwert , um die Aufmerksamkeitsmaske zu erstellen:
Die Umwandlung der Kostenmatrix in die Aufmerksamkeitsmatrix ist das ultimative Ziel
Die Aufmerksamkeitsmatrix wird verwendet. Die erweiterten Abfragefunktionen des -Frames werden verwendet, um die Timing-Funktionen zu aggregieren, um die Abfragefunktionen des -Frames zu verbessern:
Die endgültigen erweiterten Abfragefunktionen des Frames werden durch einfaches FFN auf die entsprechenden Erkennungsergebnisse verfeinert, um den Effekt einer verbesserten Erkennungsleistung zu erzielen.
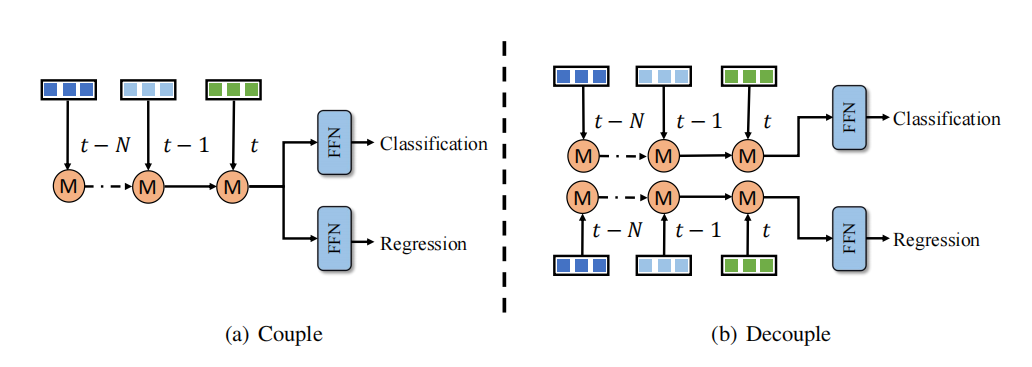
Es wird beobachtet, dass beim Klassifizierungs- und Regressionslernen der zeitlichen Fusion ein Ungleichgewichtsproblem besteht. Eine Lösung besteht darin, zeitliche Fusionszweige für die Klassifizierung bzw. Regression zu entwerfen. Dieser Entkopplungsansatz erhöht jedoch den Rechenaufwand und die Latenz, was für die meisten Methoden nicht akzeptabel ist. Im Gegensatz dazu nutzt QTNet ein effizientes Timing-Fusion-Design, seine Rechenkosten und Verzögerungen sind vernachlässigbar und es bietet eine bessere Leistung als das gesamte 3D-Erkennungsnetzwerk. Daher verwendet dieser Artikel die Entkopplungsmethode von Klassifizierungs- und Regressionszweigen bei der Zeitreihenfusion, um eine bessere Erkennungsleistung bei vernachlässigbaren Kosten zu erzielen, wie in der Abbildung dargestellt. Bild/Multimodalität
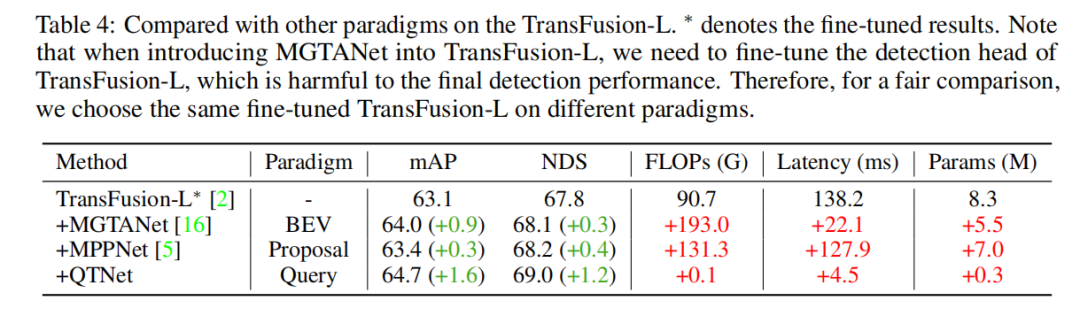
Für praktische Anwendungen ist der Kostenaufwand der Timing-Fusion sehr wichtig. In diesem Artikel werden Analysen und Experimente zu QTNet hinsichtlich Berechnungsumfang, Verzögerung und Parameterumfang durchgeführt. Die Ergebnisse zeigen, dass im Vergleich zum gesamten Netzwerk der Rechenaufwand, die Zeitverzögerungen und die Parametermengen von QTNet, die durch unterschiedliche Basislinien verursacht werden, vernachlässigbar sind, insbesondere die Berechnungsmenge verwendet nur 0,1 G FLOPs (LiDAR-Basislinie)
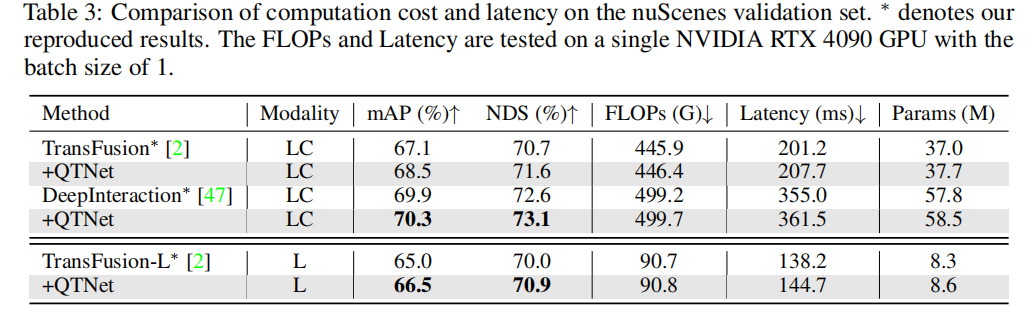
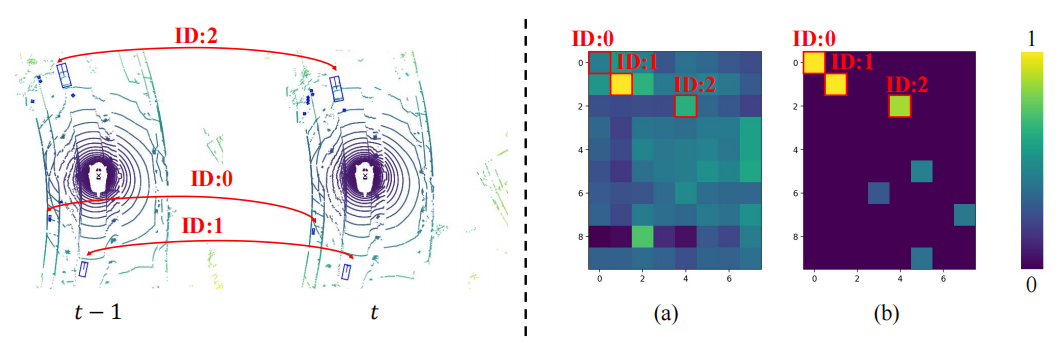
Um die Überlegenheit des abfragebasierten Timing-Fusion-Paradigmas zu überprüfen, haben wir verschiedene repräsentative hochmoderne Timing-Fusion-Methoden zum Vergleich ausgewählt. Durch experimentelle Ergebnisse wurde festgestellt, dass der auf dem Abfrageparadigma basierende Timing-Fusion-Algorithmus effizienter ist als der auf dem BEV- und Vorschlagsparadigma basierende. Mit nur 0,1 G FLOPs und 4,5 ms Overhead zeigte QTNet eine bessere Leistung, während die Gesamtparametermenge nur 0,3 Millionen betrug 3-Frame-Zeitfusion. Experimentelle Ergebnisse zeigen, dass die einfache Verwendung von Cross Attention zur Modellierung zeitlicher Beziehungen keinen offensichtlichen Effekt hat. Bei Verwendung von MTM verbessert sich jedoch die Erkennungsleistung erheblich, was die Bedeutung einer expliziten Bewegungsführung in großräumigen Punktwolken verdeutlicht. Darüber hinaus wurde durch Ablationsexperimente festgestellt, dass das Gesamtdesign von QTNet sehr leicht und effizient ist. Bei Verwendung von 4 Datenrahmen für die Timing-Fusion beträgt die Berechnungsmenge von QTNet nur 0,24 G FLOPs und die Verzögerung beträgt nur 6,5 Millisekunden Als Cross Attention kombiniert dieser Artikel zwei Die Aufmerksamkeitsmatrix von Objekten zwischen Frames wird visualisiert, wobei dieselbe ID dasselbe Objekt zwischen zwei Frames darstellt. Es kann festgestellt werden, dass die von MTM generierte Aufmerksamkeitsmatrix (b) diskriminierender ist als die von Cross Attention generierte Aufmerksamkeitsmatrix (a), insbesondere die Aufmerksamkeitsmatrix zwischen kleinen Objekten. Dies zeigt, dass die durch explizite Bewegung gesteuerte Aufmerksamkeitsmatrix es dem Modell erleichtert, die Zuordnung von Objekten zwischen zwei Bildern durch physikalische Modellierung herzustellen. In diesem Artikel wird nur kurz auf die Frage der physikalischen Etablierung von Timing-Korrelationen bei der Timing-Fusion eingegangen. Dennoch lohnt es sich zu untersuchen, wie sich Timing-Korrelationen besser konstruieren lassen.
In diesem Artikel werden Szenensequenzen als Objekt für die visuelle Analyse von Erkennungsergebnissen verwendet. Es kann festgestellt werden, dass sich das kleine Objekt in der unteren linken Ecke ausgehend vom
-Frame schnell vom Fahrzeug entfernt, was dazu führt, dass die Basislinie das Objekt im 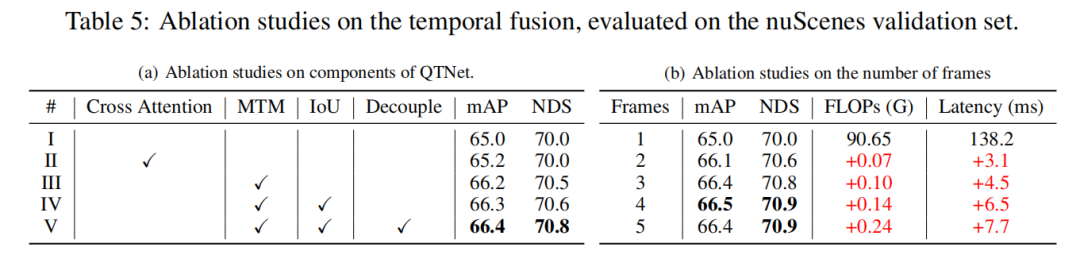
 Zusammenfassung dieses Artikels
Zusammenfassung dieses Artikels
Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/s9tkF_rAP2yUEkn6tp9eUQ
Das obige ist der detaillierte Inhalt vonQTNet: Neue zeitliche Fusionslösung für Punktwolken, Bilder und multimodale Detektoren (NeurIPS 2023). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Empfohlene Tools zur Festplattenerkennung
Empfohlene Tools zur Festplattenerkennung
 Der Unterschied zwischen Export und Exportstandard
Der Unterschied zwischen Export und Exportstandard
 Kostenloser Website-Domainname
Kostenloser Website-Domainname
 Was bedeutet Mesh-Netzwerk?
Was bedeutet Mesh-Netzwerk?
 Lösung für das Problem, dass das Win7-System nicht starten kann
Lösung für das Problem, dass das Win7-System nicht starten kann
 Vue allgemeine Anweisungen
Vue allgemeine Anweisungen
 So lesen Sie Py-Dateien in Python
So lesen Sie Py-Dateien in Python
 Was ist besser, zuerst zu lernen, C-Sprache oder C++?
Was ist besser, zuerst zu lernen, C-Sprache oder C++?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



