


Die Einführung des 2D-Diffusionsmodells hat den Prozess der Bildinhaltserstellung erheblich vereinfacht und Innovationen in die 2D-Designbranche gebracht. In den letzten Jahren wurde dieses Verbreitungsmodell auf die 3D-Erstellung ausgeweitet, wodurch die Arbeitskosten in Anwendungen wie VR, AR, Robotik und Spielen gesenkt wurden. Viele Studien haben damit begonnen, die Verwendung vorab trainierter 2D-Diffusionsmodelle sowie NeRFs-Methoden zu untersuchen, die den Scored Distillation Sampling (SDS)-Verlust nutzen. Allerdings erfordern SDS-basierte Methoden in der Regel stundenlange Ressourcenoptimierung und verursachen oft geometrische Probleme in Grafiken, wie zum Beispiel das vielschichtige Janus-Problem
Andererseits können Forscher dies erreichen, ohne viel Zeit mit der Optimierung jeder Ressource zu verbringen Es wurden auch verschiedene Versuche unternommen, die generierten 3D-Diffusionsmodelle zu diversifizieren. Diese Methoden erfordern in der Regel die Erfassung von 3D-Modellen/Punktwolken mit realen Daten für das Training. Für reale Bilder sind solche Trainingsdaten jedoch schwer zu erhalten. Da aktuelle 3D-Diffusionsmethoden in der Regel auf einem zweistufigen Training basieren, führt dies zu einem verschwommenen und schwer zu entstörenden latenten Raum auf nicht klassifizierten, sehr unterschiedlichen 3D-Datensätzen, was eine qualitativ hochwertige Darstellung zu einer dringenden Herausforderung macht.
Um dieses Problem zu lösen, haben einige Forscher einstufige Modelle vorgeschlagen, aber die meisten dieser Modelle zielen nur auf bestimmte einfache Kategorien ab und weisen eine schlechte Verallgemeinerung auf. Daher besteht das Ziel der Forscher in diesem Artikel darin, schnell zu erreichen. Realistische und vielseitige 3D-Generierung. Zu diesem Zweck schlugen sie DMV3D vor. DMV3D ist ein neues einstufiges Diffusionsmodell für alle Kategorien, das 3D-NeRF direkt basierend auf der Eingabe von Modelltext oder einem einzelnen Bild generieren kann. In nur 30 Sekunden kann DMV3D auf einer einzigen A100-GPU eine Vielzahl von hochauflösenden 3D-Bildern erzeugen.
 Konkret handelt es sich bei DMV3D um ein 2D-Bilddiffusionsmodell mit mehreren Ansichten, das die Rekonstruktion und Darstellung von 3D-NeRF in seinen Entrauscher integriert und in einer End-to-End-Methode ohne direkte 3D-Überwachung trainiert wird. Dadurch werden die Probleme vermieden, die beim separaten Training von 3D-NeRF-Encodern für die Latentraumdiffusion (z. B. zweistufige Modelle) und langwierigen Optimierungsmethoden für jedes Objekt (z. B. SDS) auftreten können.
Konkret handelt es sich bei DMV3D um ein 2D-Bilddiffusionsmodell mit mehreren Ansichten, das die Rekonstruktion und Darstellung von 3D-NeRF in seinen Entrauscher integriert und in einer End-to-End-Methode ohne direkte 3D-Überwachung trainiert wird. Dadurch werden die Probleme vermieden, die beim separaten Training von 3D-NeRF-Encodern für die Latentraumdiffusion (z. B. zweistufige Modelle) und langwierigen Optimierungsmethoden für jedes Objekt (z. B. SDS) auftreten können.
Das Wesentliche der Methode in diesem Artikel Das Obige ist eine 3D-Rekonstruktion basierend auf dem Rahmen der 2D-Mehrfachansichtsdiffusion. Dieser Ansatz ist von der RenderDiffusion-Methode inspiriert, einer Methode zur 3D-Generierung über Single-View-Diffusion. Die Einschränkung der RenderDiffusion-Methode besteht jedoch darin, dass die Trainingsdaten Vorkenntnisse über eine bestimmte Kategorie erfordern und die Objekte in den Daten bestimmte Winkel oder Posen erfordern, sodass ihre Verallgemeinerung schlecht ist und sie für keinen Objekttyp 3D generieren kann
Den Forschern zufolge ist im Vergleich dazu nur ein Satz von vier spärlichen Mehrfachansichtprojektionen erforderlich, die ein Objekt enthalten, um ein nicht verdecktes 3D-Objekt zu beschreiben. Diese Trainingsdaten stammen aus der menschlichen räumlichen Vorstellungskraft, die es Menschen ermöglicht, aus planaren Ansichten um mehrere Objekte herum ein vollständiges 3D-Objekt zu konstruieren. Diese Vorstellung ist normalerweise sehr präzise und spezifisch. Bei der Anwendung dieser Eingabe muss jedoch noch die Aufgabe der 3D-Rekonstruktion unter spärlichen Ansichten gelöst werden. Dies ist ein seit langem bestehendes Problem, das selbst dann eine große Herausforderung darstellt, wenn die Eingabe verrauscht ist
Unsere Methode ist in der Lage, eine 3D-Generierung basierend auf einem einzelnen Bild/Text zu erreichen. Für die Bildeingabe fixieren sie eine spärliche Ansicht als rauschfreie Eingabe und führen bei anderen Ansichten eine Rauschunterdrückung durch, ähnlich wie beim 2D-Bild-Inpainting. Um eine textbasierte 3D-Generierung zu erreichen, verwendeten die Forscher aufmerksamkeitsbasierte Textbedingungen und typunabhängige Klassifikatoren, die üblicherweise in 2D-Diffusionsmodellen verwendet werden.
Sie verwendeten während des Trainings nur die Bildraumüberwachung und verwendeten einen großen Datensatz, der aus synthetisierten Objaverse-Bildern und real erfassten MVImgNet-Bildern bestand. Den Ergebnissen zufolge hat DMV3D bei der Einzelbild-3D-Rekonstruktion das SOTA-Niveau erreicht und übertrifft damit frühere SDS-basierte Methoden und 3D-Diffusionsmodelle. Darüber hinaus ist die textbasierte Methode zur 3D-Modellgenerierung auch besser als die vorherige Methode Adresse: https://justimyhxu.github.io/projects/dmv3d/
Werfen wir einen Blick auf den erzeugten 3D-Bildeffekt.


Wie trainiere und folgere ich ein einstufiges 3D-Diffusionsmodell?
Die Forscher stellten zunächst ein neues Diffusions-Framework vor, das einen rekonstruktionsbasierten Denoiser verwendet, um verrauschte Multi-View-Bilder für die 3D-Erzeugung zu entrauschen. Zweitens schlugen sie einen neuen Multi-View-Denoiser vor, der auf der Diffusion basiert Zeitschritt, wodurch Multi-View-Bilder durch 3D-NeRF-Rekonstruktion und -Rendering schrittweise entrauscht werden. Schließlich wird das Modell weiter verbreitet, um Text- und Bildanpassungen zu unterstützen und so Steuerbarkeit zu generieren.
Der Inhalt, der neu geschrieben werden muss, ist: Multi-View-Diffusion und Rauschunterdrückung. Neu geschriebener Inhalt: Diffusion aus mehreren Blickwinkeln und Rauschunterdrückung
Diffusion aus mehreren Blickwinkeln. Die im 2D-Diffusionsmodell verarbeitete ursprüngliche x_0-Verteilung ist eine einzelne Bildverteilung im Datensatz. Stattdessen betrachten wir eine gemeinsame Verteilung von Bildern mit mehreren Ansichten 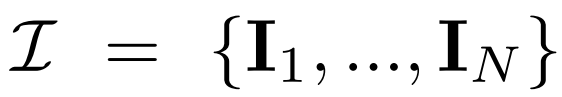 , wobei jede Gruppe
, wobei jede Gruppe  eine Bildbeobachtung derselben 3D-Szene (Asset) aus Sicht C = {c_1, .. ., c_N} ist. Der Diffusionsprozess entspricht der unabhängigen Durchführung einer Diffusionsoperation für jedes Bild unter Verwendung desselben Rauschplans, wie in Gleichung (1) unten dargestellt.
eine Bildbeobachtung derselben 3D-Szene (Asset) aus Sicht C = {c_1, .. ., c_N} ist. Der Diffusionsprozess entspricht der unabhängigen Durchführung einer Diffusionsoperation für jedes Bild unter Verwendung desselben Rauschplans, wie in Gleichung (1) unten dargestellt.
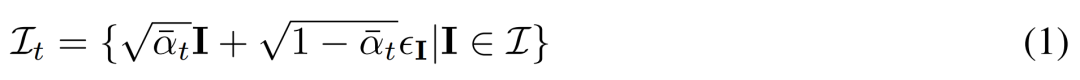
Rekonstruktionsbasierte Rauschunterdrückung. Die Umkehrung des 2D-Diffusionsprozesses ist im Wesentlichen die Rauschunterdrückung. In diesem Artikel schlagen Forscher vor, 3D-Rekonstruktion und Rendering zu verwenden, um eine Rauschunterdrückung von 2D-Mehrfachansichtsbildern zu erreichen und gleichzeitig saubere 3D-Modelle für die 3D-Generierung auszugeben. Insbesondere verwenden sie das 3D-Rekonstruktionsmodul E (・), um die 3D-Darstellung S aus dem verrauschten Mehrfachansichtsbild 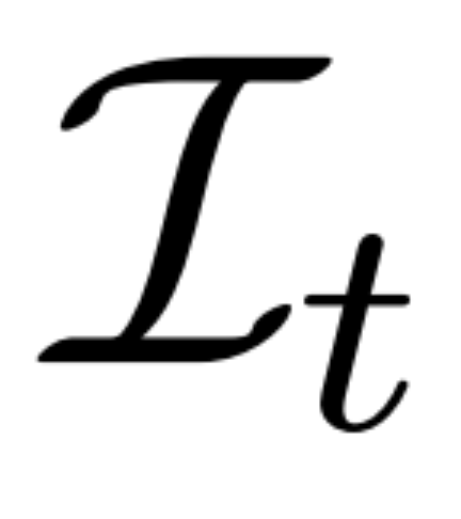 zu rekonstruieren, und verwenden das differenzierbare Renderingmodul R (・), um das entrauschte Bild zu rendern, wie im Folgenden gezeigt Formel (2) wie gezeigt.
zu rekonstruieren, und verwenden das differenzierbare Renderingmodul R (・), um das entrauschte Bild zu rendern, wie im Folgenden gezeigt Formel (2) wie gezeigt.
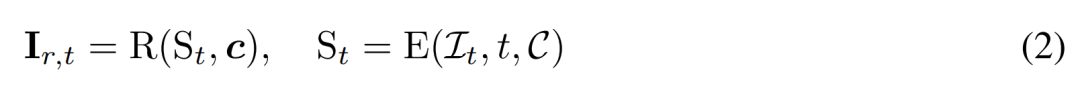
Rekonstruktionsbasierter Multi-View-Denoiser
Die Forscher bauten einen Multi-View-Denoiser auf Basis von LRM und verwendeten ein großes Transformatormodell, um aus verrauschten Posenbildern mit spärlicher Ansicht eine saubere Drei zu rekonstruieren -Ebenen-NeRF wird generiert, und dann wird das Rendering des rekonstruierten Dreiebenen-NeRF als entrauschte Ausgabe verwendet.
Rekonstruktion und Rendering. Wie in Abbildung 3 unten dargestellt, verwendet der Forscher einen Vision Transformer (DINO), um das Eingabebild 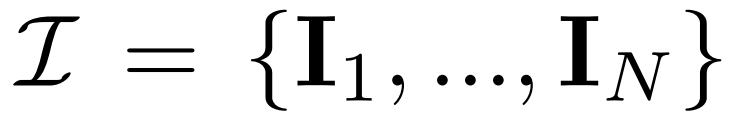 in ein 2D-Token umzuwandeln, und verwendet dann den Transformator, um die erlernte Drei-Ebenen-Positionseinbettung auf die endgültige Drei-Ebenen-Position abzubilden stellen die 3D-Darstellung der Anlage dar. Die vorhergesagten drei Ebenen werden als nächstes verwendet, um Volumendichte und Farbe über einen MLP für differenzierbare Volumenwiedergabe zu dekodieren.
in ein 2D-Token umzuwandeln, und verwendet dann den Transformator, um die erlernte Drei-Ebenen-Positionseinbettung auf die endgültige Drei-Ebenen-Position abzubilden stellen die 3D-Darstellung der Anlage dar. Die vorhergesagten drei Ebenen werden als nächstes verwendet, um Volumendichte und Farbe über einen MLP für differenzierbare Volumenwiedergabe zu dekodieren.
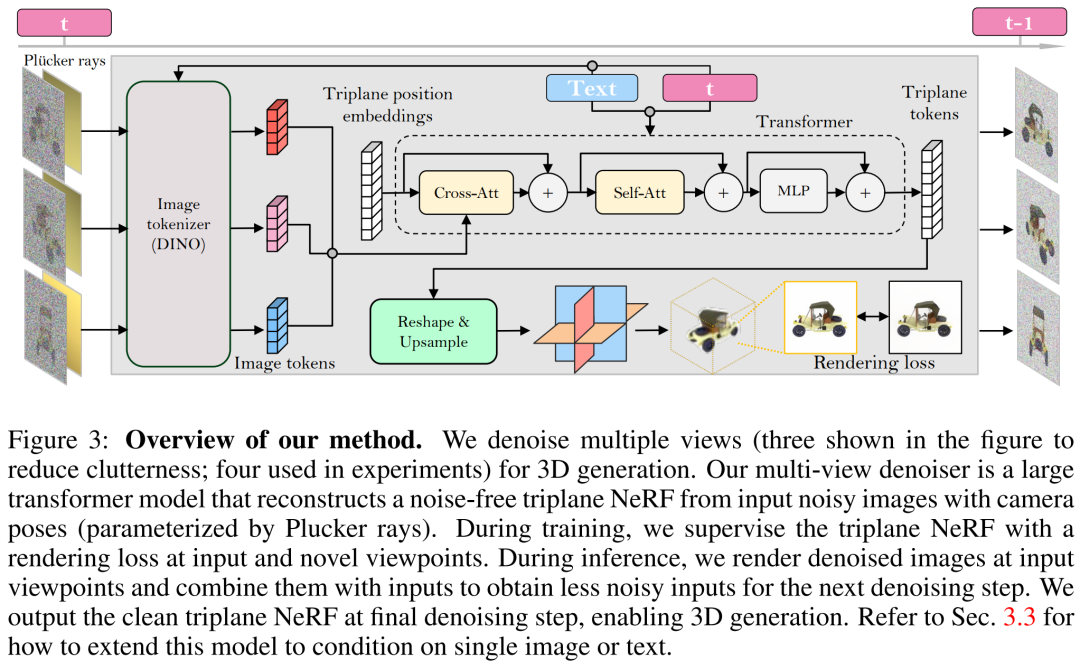
Zeitanpassung. Im Vergleich zum CNN-basierten DDPM (Denoising Diffusion Probabilistic Model) erfordert unser transformatorbasiertes Modell ein anderes zeitliches Anpassungsdesign.
Beim Training des Modells in diesem Artikel wies der Forscher darauf hin, dass bei sehr unterschiedlichen intrinsischen und extrinsischen Parameterdatensätzen der Kamera (wie MVImgNet) Eingabekameraanpassungen effektiv gestaltet werden müssen, um dem Modell zu helfen, die Kamera zu verstehen und zu funktionieren 3D-Argumentation
Beim Umschreiben des Inhalts müssen Sie die Sprache des Originaltextes in Chinesisch konvertieren, die Bedeutung des Originaltextes ändert sich jedoch nicht
Die obige Methode ermöglicht es dem vom Forscher vorgeschlagenen Modell, als bedingungsloses generatives Modell zu dienen. Sie beschreiben, wie man bedingte Entrauscher 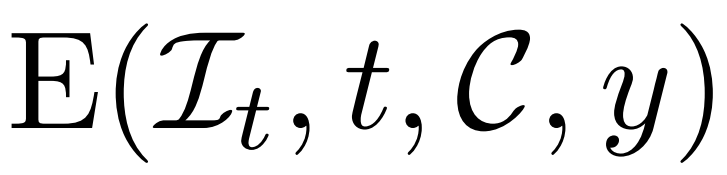 nutzt, um bedingte Wahrscheinlichkeitsverteilungen zu modellieren, wobei y Text oder Bilder darstellt, um eine kontrollierbare 3D-Generierung zu erreichen.
nutzt, um bedingte Wahrscheinlichkeitsverteilungen zu modellieren, wobei y Text oder Bilder darstellt, um eine kontrollierbare 3D-Generierung zu erreichen.
In Bezug auf die Bildkonditionierung schlugen die Forscher eine einfache und effektive Strategie vor, die keine Änderungen an der Architektur des Modells erfordert
Textkonditionierung. Um ihrem Modell Textkonditionierung hinzuzufügen, verwendeten die Forscher eine Strategie ähnlich der stabilen Diffusion. Sie verwenden einen CLIP-Textencoder, um Texteinbettungen zu generieren und diese mithilfe von Queraufmerksamkeit in einen Denoiser einzufügen.
Der Inhalt, der neu geschrieben werden muss, ist: Training und Schlussfolgerung
Training. Während der Trainingsphase tasten wir die Zeitschritte t gleichmäßig innerhalb des Bereichs [1, T] ab und fügen Rauschen gemäß der Kosinusplanung hinzu. Sie tasten das Eingabebild anhand zufälliger Kamerapositionen ab und nehmen außerdem zufällig zusätzliche neue Blickwinkel auf, um das Rendering im Hinblick auf eine bessere Qualität zu überwachen.
Der Forscher verwendet das bedingte Signal y, um die Schlussfolgerung des Trainingsziels zu minimieren. Während der Inferenzphase wählten wir Standpunkte aus, die das Objekt gleichmäßig kreisförmig umgaben, um eine gute Abdeckung der resultierenden 3D-Assets zu gewährleisten. Sie haben den Kamera-Marktwinkel für die vier Ansichten auf 50 Grad festgelegt.
Experimentelle Ergebnisse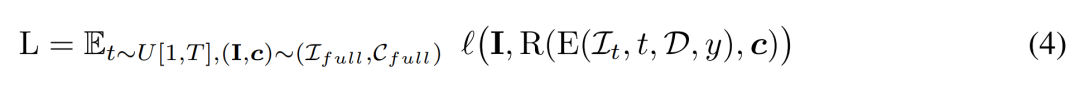
Im Experiment verwendeten die Forscher den AdamW-Optimierer, um ihr Modell mit einer anfänglichen Lernrate von 4e^-4 zu trainieren. Sie verwendeten 3.000 Schritte Aufwärmen und Kosinusabfall für diese Lernrate, verwendeten 256 × 256 Eingabebilder zum Trainieren des Rauschunterdrückungsmodells und verwendeten 128 × 128 zugeschnittene Bilder für das überwachte Rendering
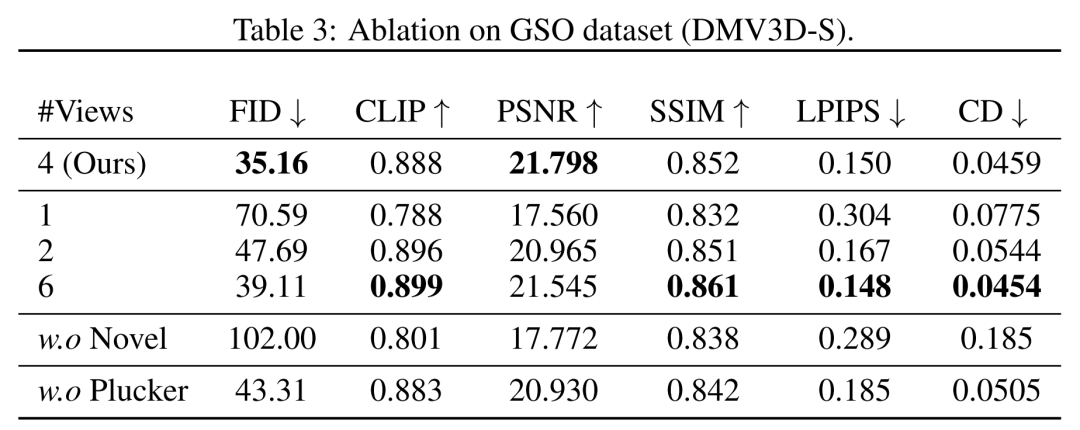
Die quantitativen Ergebnisse der GSO- und ABO-Testsätze sind in Tabelle 1 unten aufgeführt. Unser Modell übertrifft alle Basismethoden und erreicht neue SOTA für alle Metriken in beiden Datensätzen. Die von unserem Modell generierten Ergebnisse weisen bessere geometrische Details und Erscheinungsbilddetails auf als die Basislinien. Hohe Qualität, dieses Ergebnis kann qualitativ nachgewiesen werden Abbildung 4
DMV3D ist ein einstufiges Modell mit 2D-Bildern als Trainingsziel. Im Gegensatz dazu erfordert es keine individuelle Optimierung jedes Assets und kann diffuses Rauschen eliminieren und direkt 3D-NeRF-Modelle generieren. Insgesamt ist DMV3D in der Lage, schnell 3D-Bilder zu generieren und die besten Einzelbild-3D-Rekonstruktionsergebnisse zu erzielen. Die Forscher verglichen DMV3D mit Shap-E und Point-E, die ebenfalls schnelles Denken in allen Kategorien unterstützen. Die Forscher ließen diese drei Modelle basierend auf 50 Textaufforderungen von Shap-E generieren und verwendeten die CLIP-Genauigkeit und die durchschnittliche Genauigkeit von zwei verschiedenen ViT-Modellen, um die Generierungsergebnisse auszuwerten, wie in Tabelle 2 dargestellt
Laut den Daten in der Tabelle zeigt DMV3D die beste Genauigkeit. Wie aus den qualitativen Ergebnissen in Abbildung 5 ersichtlich ist, enthalten die von DMV3D generierten Grafiken im Vergleich zu den von anderen Modellen generierten Ergebnissen offensichtlich umfangreichere geometrische und Erscheinungsbilddetails und die Ergebnisse sind auch realistischer muss umgeschrieben werden Ja: Andere Ergebnisse

In Bezug auf die Generierung mehrerer Instanzen kann das in diesem Dokument vorgeschlagene Modell ähnlich wie andere Diffusionsmodelle eine Vielzahl von Beispielen basierend auf zufälligen Eingaben generieren, wie gezeigt in Abbildung 1, die die Generalisierbarkeit der vom Modell generierten Ergebnisse zeigt.

DMV3D verfügt über umfassende Flexibilität und Vielseitigkeit in den Anwendungen und verfügt über ein starkes Entwicklungspotenzial im Bereich der 3D-Generierungsanwendungen. Wie in Abbildung 1 und Abbildung 2 dargestellt, kann die Methode dieses Artikels beliebige Objekte in 2D-Fotos in Bildbearbeitungsanwendungen durch Methoden wie Segmentierung (z. B. SAM) in 3D-Dimensionen umwandeln.
Bitte lesen Sie das Originalpapier, um mehr zu erfahren Viele technische Details und Versuchsergebnisse
Das obige ist der detaillierte Inhalt vonDie neue Technologie von Adobe: Die Erstellung von 3D-Bildern mit dem A100 dauert nur 30 Sekunden und bringt Texte und Bilder in Bewegung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



