


Im ersten Jahr der generativen KI ist das Arbeitstempo aller viel schneller geworden.
Besonders in diesem Jahr arbeiten alle hart daran, große Modelle auf den Markt zu bringen: In letzter Zeit haben in- und ausländische Technologieriesen und Start-up-Unternehmen abwechselnd große Modelle auf den Markt gebracht. Sobald die Pressekonferenz begann, waren sie alle dabei große Durchbrüche und jede aktualisierte wichtige Benchmark-Liste, entweder auf dem ersten Platz oder in der ersten Stufe.
Nachdem sie sich über den rasanten Fortschritt der Technologie aufgeregt haben, stellen viele Menschen fest, dass etwas nicht stimmt: Warum haben alle einen Anteil an der Nummer eins im Ranking? Was ist dieser Mechanismus?
Seitdem erregt auch das Thema „List-Swiping“ zunehmend Aufmerksamkeit.
In letzter Zeit stellen wir fest, dass es in WeChat Moments- und Zhihu-Communitys immer mehr Diskussionen zum Thema „Swiping in den Rankings“ großer Models gibt. Insbesondere ein Beitrag auf Zhihu: Wie bewerten Sie das Phänomen, dass im Tiangong Large Model Technical Report darauf hingewiesen wurde, dass viele große Modelle Daten vor Ort nutzen, um das Ranking zu verbessern? Es löste bei allen eine Diskussion aus.
Link: https://www.zhihu.com/question/628957425
Diese Forschung stammt von der „Tiangong“-Universität von Kunlun Wanwei. Das Modell Das Forschungsteam veröffentlichte Ende letzten Monats einen technischen Bericht über die Preprint-Papierplattform arXiv.

Link zum Papier: https://arxiv.org/abs/2310.19341
Das Papier selbst ist eine Einführung in Skywork-13B, eine große Sprachmodellreihe (LLM) von Tiangong. Die Autoren stellen eine zweistufige Trainingsmethode vor, die segmentierte Korpora verwendet und auf allgemeines Training bzw. domänenspezifisches erweitertes Training abzielt.
Wie bei neuen Untersuchungen zu großen Modellen üblich, gaben die Autoren an, dass ihr Modell bei beliebten Testbenchmarks nicht nur eine gute Leistung erbrachte, sondern auch bei vielen Aufgaben der chinesischen Branche das State-of-Art-Niveau (das beste in der Branche) erreichte . Gut).
Der entscheidende Punkt ist, dass der Bericht auch die tatsächlichen Auswirkungen vieler großer Modelle überprüft und darauf hinweist, dass einige andere große inländische Modelle im Verdacht stehen, opportunistisch zu sein. Dies ist Tabelle 8:
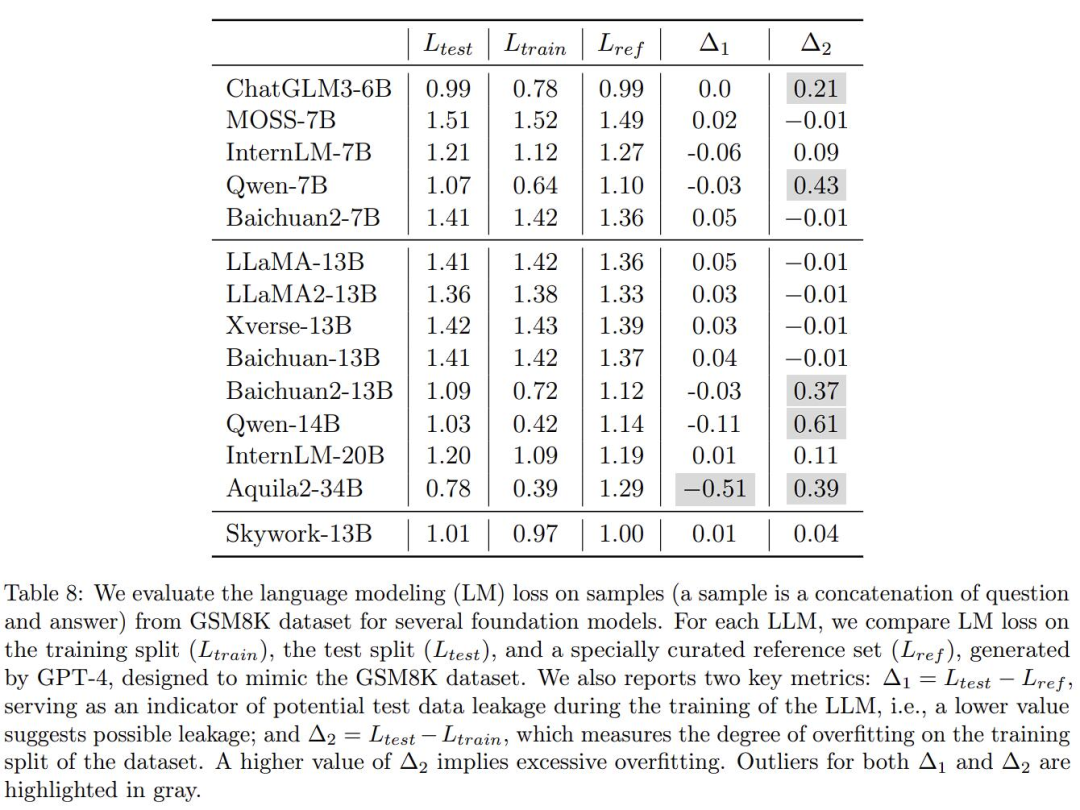
Hier verwendete der Autor GPT-4, um einige GSM8K-Beispiele zu generieren, um den Überanpassungsgrad mehrerer gängiger großer Modelle in der Branche anhand des mathematischen Anwendungsproblem-Benchmarks GSM8K zu überprüfen mit derselben Form wurden manuell auf Richtigkeit überprüft und diese Modelle anhand des generierten Datensatzes mit dem ursprünglichen Trainingssatz und Testsatz von GSM8K verglichen und der Verlust berechnet. Dann gibt es zwei Metriken:
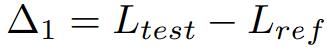
Δ1 dient als Indikator für potenzielle Testdatenlecks während des Modelltrainings, wobei niedrigere Werte auf mögliche Lecks hinweisen. Ohne Training am Testsatz sollte der Wert Null sein.
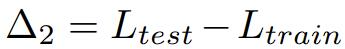
Δ2 misst den Grad der Überanpassung der Trainingsaufteilung des Datensatzes. Ein höherer Δ2-Wert bedeutet Überanpassung. Wenn es nicht auf dem Trainingssatz trainiert wurde, sollte der Wert Null sein.
Um es mit einfachen Worten zu erklären: Wenn ein Modell während des Trainings direkt die „echten Fragen“ und „Antworten“ im Benchmark-Test als Lernmaterialien verwendet und diese nutzen möchte, um Punkte zu erzielen, dann wird es hier abnormal sein.
Okay, die problematischen Bereiche von Δ1 und Δ2 sind oben sorgfältig grau hervorgehoben.
Netizens kommentierten, dass endlich jemand das offene Geheimnis der „Datensatzverschmutzung“ gelüftet habe.
Einige Internetnutzer sagten auch, dass der Intelligenzgrad großer Modelle immer noch von der Zero-Shot-Fähigkeit abhängt, die mit bestehenden Testbenchmarks nicht erreicht werden kann.

Bild: Screenshot aus Zhihu-Netizen-Kommentaren
In der Interaktion zwischen dem Autor und den Lesern sagte der Autor auch, dass er hofft, „jeder das Thema Betrug rationaler betrachten zu lassen. Es gibt immer noch eine große Lücke zwischen vielen Modellen und GPT4.“
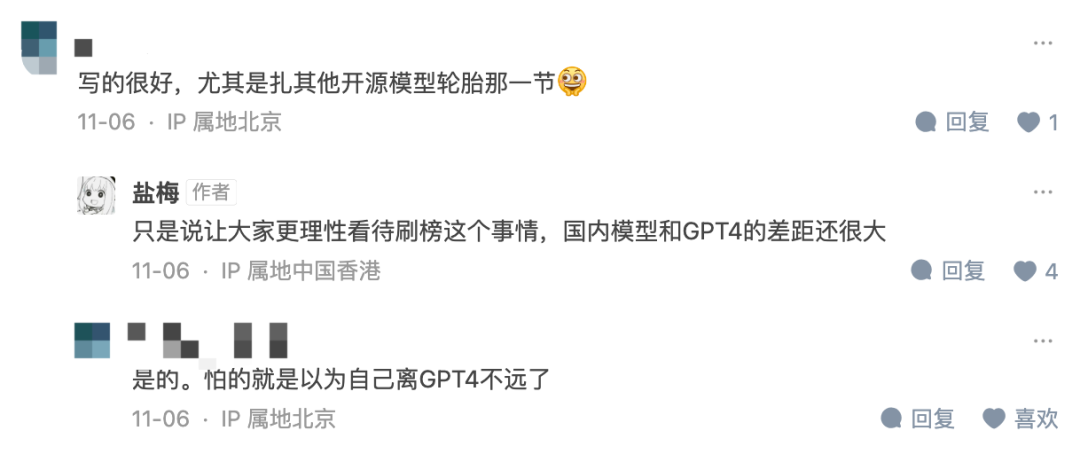
Bild: Screenshot des Zhizhihu-Artikels https://zhuanlan.zhihu.com/p/664985891
Tatsächlich ist dies kein vorübergehendes Phänomen . Seit der Einführung von Benchmark sind solche Probleme von Zeit zu Zeit aufgetreten, wie der Titel eines sehr ironischen Artikels auf arXiv im September dieses Jahres verdeutlichte: „Pretraining on the Test Set Is All You Need“.

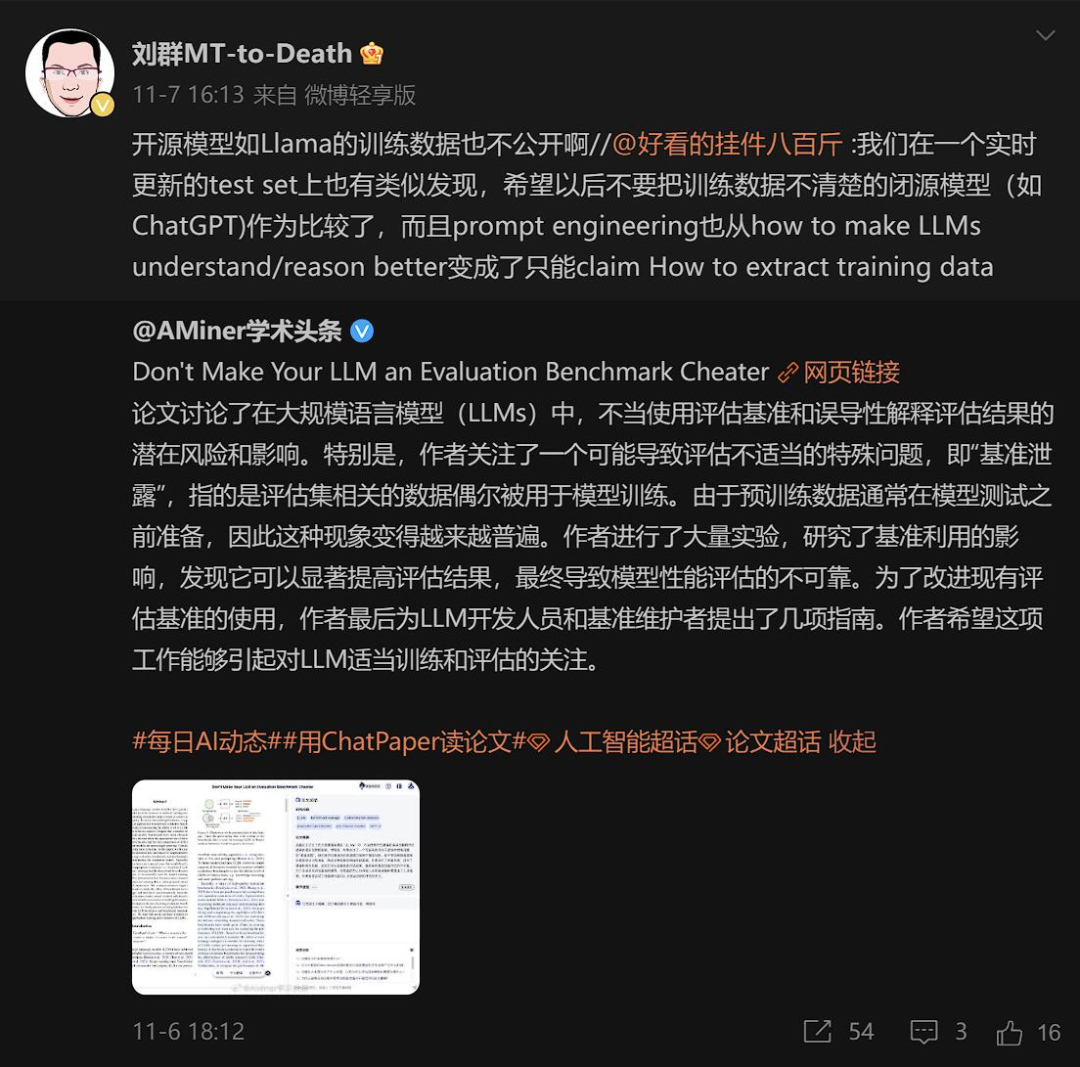
Darüber hinaus wies eine aktuelle formelle Studie der Renmin University und der University of Illinois at Urbana-Champaign auch auf Probleme bei der Bewertung großer Modelle hin. Der Titel ist sehr auffällig: „Machen Sie Ihr LLM nicht zu einem Evaluations-Benchmark-Betrüger“:

Link zum Papier: https://arxiv.org/abs/2311.01964
Das Papier weist darauf hin Das aktuelle heiße Feld großer Modelle ist den Menschen wichtig für Benchmark-Rankings, aber ihre Fairness und Zuverlässigkeit werden in Frage gestellt. Das Hauptproblem ist die Kontamination und Leckage von Daten, die unbeabsichtigt ausgelöst werden können, da wir bei der Vorbereitung des Korpus vor dem Training möglicherweise nicht den zukünftigen Bewertungsdatensatz kennen. GPT-3 stellte beispielsweise fest, dass der Datensatz „Children's Book Test“ im Pre-Training-Korpus enthalten war, und im LLaMA-2-Papier wurde erwähnt, dass kontextbezogene Webseiteninhalte aus dem BoolQ-Datensatz extrahiert werden.
Das Sammeln, Organisieren und Kennzeichnen von Datensätzen erfordert für viele Menschen einen hohen Aufwand. Wenn ein qualitativ hochwertiger Datensatz gut genug ist, um für die Auswertung verwendet zu werden, kann er natürlich auch von anderen zum Trainieren großer Modelle verwendet werden.
Andererseits wurden bei der Bewertung anhand vorhandener Benchmarks die Ergebnisse für die von uns bewerteten großen Modelle größtenteils durch die Ausführung auf einem lokalen Server oder durch API-Aufrufe erzielt. Während dieses Prozesses wurden alle unzulässigen Mittel (z. B. Datenkontamination), die zu abnormalen Verbesserungen der Bewertungsleistung führen könnten, nicht eingehend untersucht.
Was noch schlimmer ist, ist, dass die detaillierte Zusammensetzung des Trainingskorpus (z. B. Datenquellen) oft als das zentrale „Geheimnis“ bestehender großer Modelle angesehen wird. Dies erschwert die Untersuchung des Problems der Datenverschmutzung.
Mit anderen Worten, die Menge an hervorragenden Daten ist begrenzt und bei vielen Testsätzen sind GPT-4 und Llama-2 nicht unbedingt kein Problem. Beispielsweise wurde GSM8K im ersten Artikel erwähnt und GPT-4 erwähnte die Verwendung seines Trainingssatzes im offiziellen technischen Bericht.
Meinen Sie nicht, dass Daten sehr wichtig sind? Wird die Leistung eines großen Modells, das „echte Fragen“ verwendet, besser, weil die Trainingsdaten besser sind? Die Antwort ist nein.
Forscher haben experimentell herausgefunden, dass Benchmark-Lecks dazu führen können, dass große Modelle übertriebene Ergebnisse liefern: Beispielsweise kann ein 1,3-B-Modell bei einigen Aufgaben ein zehnmal so großes Modell übertreffen. Der Nebeneffekt besteht jedoch darin, dass die Leistung dieser großen testspezifischen Modelle bei anderen normalen Testaufgaben möglicherweise beeinträchtigt wird, wenn wir diese durchgesickerten Daten nur zur Feinabstimmung oder zum Training des Modells verwenden.
Daher schlägt der Autor vor, dass Forscher in Zukunft, wenn sie große Modelle bewerten oder neue Technologien untersuchen, Folgendes tun sollten:
Glücklicherweise hat dieses Thema begonnen, die Aufmerksamkeit aller auf sich zu ziehen, egal ob es sich um technische Berichte, Papierrecherchen oder Community-Diskussionen handelt, jeder hat begonnen, dem Thema „Swiping in der Rangliste“ großer Modelle Aufmerksamkeit zu schenken.
Was sind eure Meinungen und wirksamen Vorschläge dazu?
Das obige ist der detaillierte Inhalt vonNimmt das große Model Abkürzungen, um „die Rangliste zu übertreffen'? Das Problem der Datenverschmutzung verdient Aufmerksamkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 So verwenden Sie die Auswahlfunktion
So verwenden Sie die Auswahlfunktion
 Detaillierte Erläuterung des Setintervalls
Detaillierte Erläuterung des Setintervalls
 Verwendung von Oracle-Einsätzen
Verwendung von Oracle-Einsätzen
 Welche Entwicklungstools gibt es?
Welche Entwicklungstools gibt es?
 Konvertierung von RGB in Hexadezimal
Konvertierung von RGB in Hexadezimal
 Was tun, wenn der Remote-Desktop keine Verbindung herstellen kann?
Was tun, wenn der Remote-Desktop keine Verbindung herstellen kann?
 Selbststudium für Anfänger in C-Sprache ohne Grundkenntnisse
Selbststudium für Anfänger in C-Sprache ohne Grundkenntnisse








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



