


Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
End-to-End ist dieses Jahr eine sehr beliebte Richtung, die auch an UniAD vergeben wurde, aber es gibt auch viele Probleme im End-to-End-Bereich, z Da die Interpretierbarkeit gering ist, die Ausbildung schwierig zu konvergieren ist usw., haben einige Wissenschaftler auf diesem Gebiet ihre Aufmerksamkeit nach und nach auf die End-to-End-Interpretierbarkeit gerichtet. Heute werde ich Ihnen die neueste Arbeit zur End-to-End-Interpretierbarkeit vorstellen, ADAPT. Diese Methode basiert auf der Transformer-Architektur und nutzt Multitasking. Die gemeinsame Trainingsmethode gibt Fahrzeugaktionsbeschreibungen und Begründungen für jede Entscheidung durchgängig aus. Einige der Gedanken des Autors zu ADAPT sind wie folgt:
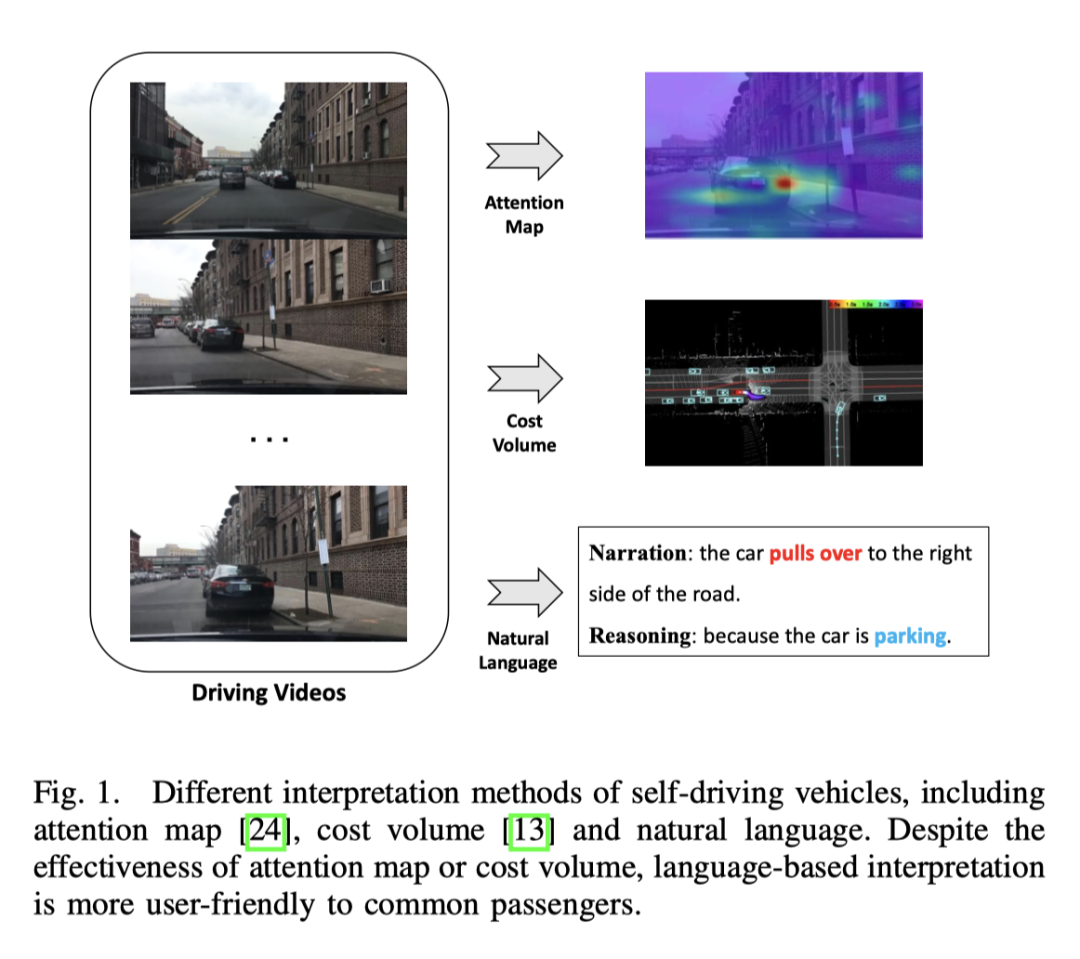
 Der Effekt ist immer noch sehr gut, besonders in der dritten dunklen Nachtszene fallen die Ampeln auf.
Der Effekt ist immer noch sehr gut, besonders in der dritten dunklen Nachtszene fallen die Ampeln auf.
Um natürliche Sätze mit flexiblen syntaktischen Strukturen zu generieren, verwenden einige Methoden Sequenzlerntechniken. Konkret nutzen diese Methoden Video-Encoder zum Extrahieren von Funktionen und Sprachdecoder zum Erlernen der visuellen Textausrichtung. Um Beschreibungen umfangreicher zu gestalten, verwenden diese Methoden auch Darstellungen auf Objektebene, um detaillierte objektbewusste Interaktionsfunktionen in Videos zu erhalten.
Obwohl bestehende Architekturen bestimmte Ergebnisse in der allgemeinen Richtung der Videountertitelung erzielt haben, können sie aus einfachen Gründen nicht direkt auf die Darstellung von Aktionen angewendet werden Durch die Übertragung von Videobeschreibungen auf Darstellungen autonomer Fahrhandlungen gehen einige wichtige Informationen verloren, wie z. B. Fahrzeuggeschwindigkeit usw., die für autonome Fahraufgaben von entscheidender Bedeutung sind. Wie diese multimodalen Informationen effektiv zur Bildung von Sätzen genutzt werden können, wird noch untersucht. PaLM-E leistet gute Arbeit in multimodalen Sätzen.
Durchgängiges autonomes FahrenDarüber hinaus modellieren einige Methoden das zukünftige Verhalten von Verkehrsteilnehmern wie Fahrzeugen, Radfahrern oder Fußgängern, um die Wegpunkte des Fahrzeugs vorherzusagen, während andere Methoden die Steuersignale des Fahrzeugs direkt auf der Grundlage von Sensoreingaben vorhersagen, ähnlich der Teilaufgabe „Vorhersage von Steuersignalen“ in diese Arbeit
Im Bereich des autonomen Fahrens basieren die meisten Interpretationsmethoden auf Vision, einige basieren auf LiDAR-Arbeit. Einige Methoden nutzen Aufmerksamkeitskarten, um unbedeutende Bildbereiche herauszufiltern und so das Verhalten autonomer Fahrzeuge nachvollziehbar und erklärbar erscheinen zu lassen. Die Aufmerksamkeitskarte kann jedoch einige weniger wichtige Regionen enthalten. Es gibt auch Methoden, die Lidar- und hochpräzise Karten als Eingabe verwenden, die Begrenzungsrahmen anderer Verkehrsteilnehmer vorhersagen und Ontologie verwenden, um den Entscheidungsprozess zu erklären. Darüber hinaus gibt es eine Möglichkeit, Online-Karten durch Segmentierung zu erstellen, um die Abhängigkeit von HD-Karten zu verringern. Obwohl visionäre oder Lidar-basierte Methoden gute Ergebnisse liefern können, lässt das Fehlen einer verbalen Erklärung das gesamte System komplex und schwer verständlich erscheinen. Eine Studie untersucht erstmals die Möglichkeit der Textinterpretation für autonome Fahrzeuge, indem Videofunktionen offline extrahiert werden, um Steuersignale vorherzusagen und die Aufgabe der Videobeschreibung auszuführen.
ADAPT-Methode
Die gesamte Struktur ist in zwei Aufgaben unterteilt: 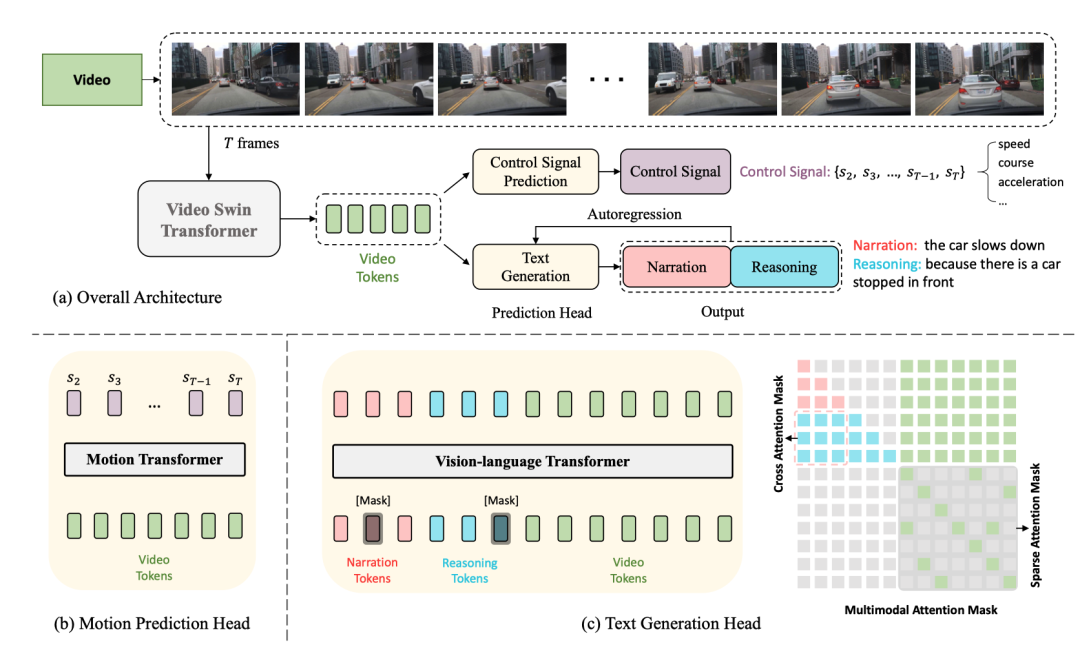
Driving Caption Generation (DCG): Videos eingeben, zwei Sätze ausgeben, den ersten Satz Beschreibung: Die Aktion des Autos, der zweite Satz beschreibt die Gründe für diese Aktion, z. B. „Das Auto beschleunigt, weil die Ampel grün wird“
Video-Encoder. Der Video-Swin-Transformer wird hier verwendet, um die eingegebenen Videobilder in Video-Feature-Tokens umzuwandeln.
, die Größe des Features ist
, wobei die Dimension des Kanals ist darüber Feature Nach der Tokenisierung werden Video-Tokens mit Abmessungen
erhalten, und dann wird ein MLP verwendet, um die Abmessungen anzupassen, um sie an die Einbettung von Text-Tokens anzupassen, und dann werden die Text-Tokens und Video-Tokens der Vision zugeführt -Sprachtransformator-Encoder zusammen, um Aktionsbeschreibungen und Begründungen zu generieren.. Jedes Steuersignal ist hier nicht unbedingt eindimensional, sondern kann mehrdimensional sein -dimensional, wie Geschwindigkeit, Beschleunigung, Richtung usw. gleichzeitig. Der Ansatz hier besteht darin, die Videofunktionen zu tokenisieren und über den Bewegungstransformator eine Reihe von Ausgangssignalen zu generieren. Es ist zu beachten, dass der erste Frame hier nicht enthalten ist, da der erste Frame bereitgestellt wird ist zu wenig dynamische Informationen
In diesem Rahmen wird aufgrund des gemeinsam genutzten Video-Encoders tatsächlich davon ausgegangen, dass die beiden Aufgaben von CSP und DCG auf der Ebene der Videodarstellung aufeinander abgestimmt sind. Der Ausgangspunkt ist, dass Aktionsbeschreibungen und Steuersignale unterschiedliche Ausdrücke feinkörniger Fahrzeugaktionen sind und sich Erklärungen zur Aktionsbegründung hauptsächlich auf die Fahrumgebung konzentrieren, die die Fahrzeugaktionen beeinflusst. Training mit gemeinsamem Training
Es ist zu beachten, dass es sich zwar um einen gemeinsamen Trainingsplatz handelt, dieser jedoch während der Inferenz leicht verständlich ist. Die Videos werden direkt gemäß dem Flussdiagramm eingegeben Ausgabesteuerung Das Signal reicht für die DCG-Aufgabe aus, die Beschreibung und Begründung wird Wort für Wort basierend auf der autoregressiven Methode generiert, beginnend bei [CLS] und endend bei [SEP] die Längenschwelle.Der verwendete Datensatz ist BDD-X. Dieser Datensatz enthält 7000 gepaarte Videos und Steuersignale. Jedes Video dauert etwa 40 Sekunden, die Bildgröße beträgt und die Frequenz beträgt FPS. Jedes Video weist 1 bis 5 Fahrzeugverhalten auf, z. B. Beschleunigen, Rechtsabbiegen und Zusammenfahren. Alle diese Aktionen wurden mit Text kommentiert, einschließlich Handlungserzählungen (z. B. „Das Auto hielt an“) und Begründungen (z. B. „Weil die Ampel rot war“). Insgesamt gibt es etwa 29.000 Verhaltensanmerkungspaare.
bezieht sich auf das Entfernen der CSP-Aufgabe und das Beibehalten nur der DCG-Aufgabe, was dem Training nur des Untertitelmodells entspricht Die Aufgabe ist immer noch nicht vorhanden, aber wenn Sie das DCG-Modul eingeben, müssen Sie zusätzlich zum Video-Tag auch das Steuersignal-Tag eingeben Der Argumentationseffekt ist deutlich besser. Obwohl der Effekt bei einem Steuersignaleingang verbessert wird, ist er immer noch nicht so gut wie der Effekt beim Hinzufügen einer CSP-Aufgabe. Nach dem Hinzufügen der CSP-Aufgabe ist die Fähigkeit, das Video auszudrücken und zu verstehen, stärker
kann so verstanden werden Genauigkeit, insbesondere wird das vorhergesagte Steuersignal abgeschnitten und die Formel lautet wie folgt
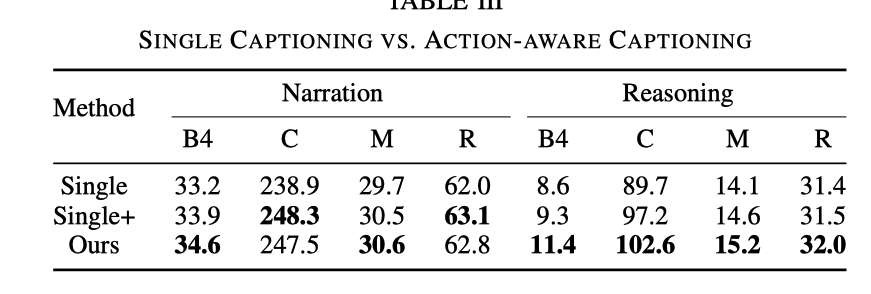
Der Einfluss verschiedener Arten von Steuersignalen
Im Experiment werden Geschwindigkeit und Kurs als grundlegende Signale verwendet. Experimente ergaben jedoch, dass die Wirkung bei Verwendung nur eines der Signale nicht so gut ist wie bei der gleichzeitigen Verwendung beider Signale. Die spezifischen Daten sind in der folgenden Tabelle aufgeführt:
Dies zeigt, dass die beiden Signale Geschwindigkeit und Richtung können dem Netzwerk helfen, die Handlungsbeschreibung und Argumentation besser zu lernen
Interaktion zwischen Handlungsbeschreibung und Argumentation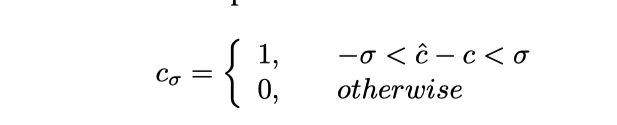
Der Einfluss der Abtastraten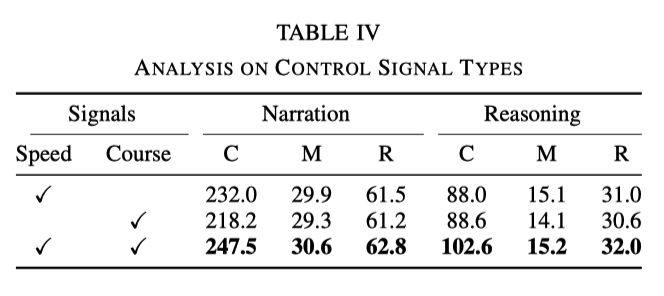
Dieses Ergebnis lässt sich erraten. Je mehr Frames verwendet werden, desto besser wird das Ergebnis, aber die entsprechende Geschwindigkeit wird auch langsamer, wie in der folgenden Tabelle gezeigt
Das obige ist der detaillierte Inhalt vonNeuer Titel: ADAPT: Eine vorläufige Untersuchung der Erklärbarkeit von End-to-End-Autonomem Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Verwendung von Elementen in Python
Verwendung von Elementen in Python
 So verbinden Sie ASP mit dem Zugriff auf die Datenbank
So verbinden Sie ASP mit dem Zugriff auf die Datenbank
 Tutorial zur Symboleingabe in voller Breite
Tutorial zur Symboleingabe in voller Breite
 So kaufen Sie Fil-Münzen
So kaufen Sie Fil-Münzen
 Computer Software
Computer Software
 Wie viel ist ein Bitcoin in RMB wert?
Wie viel ist ein Bitcoin in RMB wert?
 ETH-Marktanalyse heute
ETH-Marktanalyse heute












