


Wenn Sie jemals mit einem Konversations-KI-Bot interagiert haben, werden Sie sich an einige sehr frustrierende Momente erinnern. Zum Beispiel wurden die wichtigen Dinge, die Sie im Gespräch am Vortag erwähnt haben, von der KI völlig vergessen...
Das liegt daran, dass sich die meisten aktuellen LLMs nur an einen begrenzten Kontext erinnern können, genau wie Studenten, die sich für Prüfungen pauken, ein wenig quer- Die Untersuchung werde „die Wahrheit ans Licht bringen“.
Wäre es nicht beneidenswert, wenn ein KI-Assistent Gespräche von vor Wochen oder Monaten in einem Chat kontextbezogen referenzieren könnte oder wenn Sie den KI-Assistenten bitten könnten, einen Bericht zusammenzufassen, der Tausende von Seiten lang ist?
Damit sich LLM besser erinnern und mehr Inhalte merken kann, haben Forscher hart gearbeitet. Kürzlich haben Forscher vom MIT, Meta AI und der Carnegie Mellon University eine Methode namens „StreamingLLM“ vorgeschlagen, die es Sprachmodellen ermöglicht, Endlostext reibungslos zu verarbeiten /pdf/2309.17453.pdf
 Projektadresse: https://github.com/mit-han-lab/streaming-llm
Projektadresse: https://github.com/mit-han-lab/streaming-llm
 Schauen wir uns als nächstes die technischen Details an.
Schauen wir uns als nächstes die technischen Details an.
Methodeninnovation
 Im Allgemeinen ist LLM durch das Aufmerksamkeitsfenster während der Vorschulung begrenzt. Obwohl bereits viel daran gearbeitet wurde, diese Fenstergröße zu erweitern und die Trainings- und Inferenzeffizienz zu verbessern, ist die akzeptable Sequenzlänge von LLM immer noch begrenzt, was für eine dauerhafte Bereitstellung nicht geeignet ist.
Im Allgemeinen ist LLM durch das Aufmerksamkeitsfenster während der Vorschulung begrenzt. Obwohl bereits viel daran gearbeitet wurde, diese Fenstergröße zu erweitern und die Trainings- und Inferenzeffizienz zu verbessern, ist die akzeptable Sequenzlänge von LLM immer noch begrenzt, was für eine dauerhafte Bereitstellung nicht geeignet ist.
In diesem Artikel stellte der Forscher zunächst das Konzept der LLM-Streaming-Anwendung vor und stellte die Frage: „Kann LLM mit unendlich langen Eingaben bereitgestellt werden, ohne Effizienz und Leistung zu beeinträchtigen?“
1. In der Decodierungsphase speichert das transformatorbasierte LLM den Schlüssel- und Wertstatus (KV) aller vorherigen Token, wie in Abbildung 1 dargestellt a) Dies kann zu einer übermäßigen Speichernutzung und einer erhöhten Dekodierungslatenz führen.
2 Das vorhandene Modell verfügt nur über begrenzte Längenextrapolationsfunktionen, d Bei längerem Betrieb nimmt die Leistung ab.
Eine intuitive Methode heißt Window Attention (Abbildung 1 b). Diese Methode verwaltet nur ein Schiebefenster mit fester Größe für den KV-Status des neuesten Tokens. Dies gewährleistet jedoch eine stabile Speichernutzung und Dekodierung Geschwindigkeit, nachdem der Cache voll ist, aber sobald die Sequenzlänge die Cache-Größe überschreitet oder auch nur den KV des ersten Tokens entfernt, stürzt das Modell ab. Eine andere Methode besteht darin, das Schiebefenster neu zu berechnen (siehe Abbildung 1 c). Diese Methode rekonstruiert den KV-Status des neuesten Tokens für jedes generierte Token. Die Leistung ist zwar leistungsstark, erfordert jedoch die Berechnung der sekundären Aufmerksamkeit Das Ergebnis ist deutlich langsamer, was bei echten Streaming-Anwendungen nicht ideal ist.
Bei der Untersuchung des Fensteraufmerksamkeitsversagens entdeckten Forscher ein interessantes Phänomen: Laut Abbildung 2 wird den anfänglichen Tags eine große Anzahl von Aufmerksamkeitswerten zugewiesen, unabhängig davon, ob diese Tags mit der Sprachmodellierungsaufgabe zusammenhängen
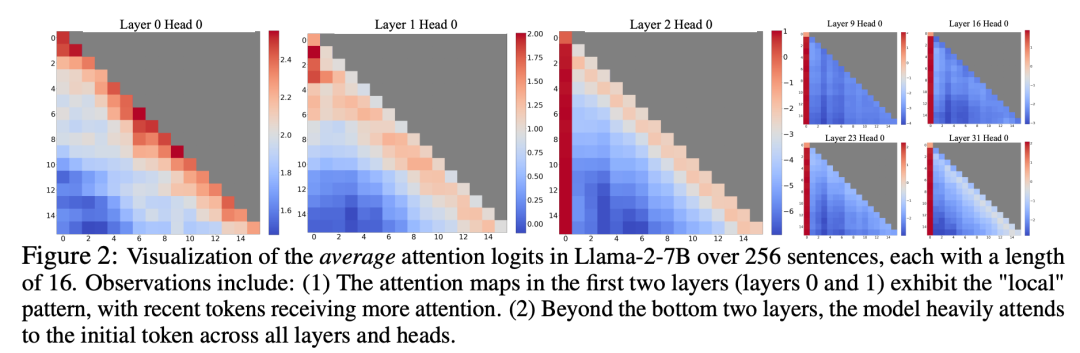
Forscher nennen diese Token „Aufmerksamkeitspools“: Obwohl ihnen die semantische Bedeutung fehlt, nehmen sie einen großen Teil der Aufmerksamkeitswerte ein. Die Forscher führen dieses Phänomen auf Softmax zurück (wobei die Summe der Aufmerksamkeitswerte aller Kontext-Tokens 1 sein muss). Selbst wenn die aktuelle Abfrage keine starke Übereinstimmung unter vielen vorherigen Token aufweist, muss das Modell diese unerwünschten Aufmerksamkeiten dennoch übertragen . Werte werden irgendwo zugewiesen, sodass sie in der Summe 1 ergeben. Der Grund, warum das anfängliche Token zu einem „Pool“ wird, ist intuitiv: Aufgrund der Eigenschaften der autoregressiven Sprachmodellierung ist das anfängliche Token für fast alle nachfolgenden Token sichtbar, was es einfacher macht, sie als Aufmerksamkeitspool zu trainieren.
Basierend auf den oben genannten Erkenntnissen schlug der Forscher StreamingLLM vor. Dies ist ein einfaches und effizientes Framework, das es mit begrenzten Aufmerksamkeitsfenstern trainierten Aufmerksamkeitsmodellen ermöglicht, unendlich lange Texte ohne Feinabstimmung zu verarbeiten.
StreamingLLM macht sich die Tatsache zunutze, dass Aufmerksamkeitspools hohe Aufmerksamkeitswerte haben. Tatsächlich können diese Aufmerksamkeitspools beibehalten werden Machen Sie die Verteilung der Aufmerksamkeitswerte nahe an eine Normalverteilung. Daher muss StreamingLLM nur den KV-Wert des Aufmerksamkeitspool-Tokens (nur 4 anfängliche Token reichen aus) und den KV-Wert des Schiebefensters beibehalten, um die Aufmerksamkeitsberechnung zu verankern und die Leistung des Modells zu stabilisieren.
Verwendung von StreamingLLM, einschließlich Llama-2-[7,13,70] B, MPT-[7,30] B, Falcon-[7,40] B und Pythia [2.9,6.9,12] B Das Modell kann 4 Millionen Token oder mehr zuverlässig simulieren.
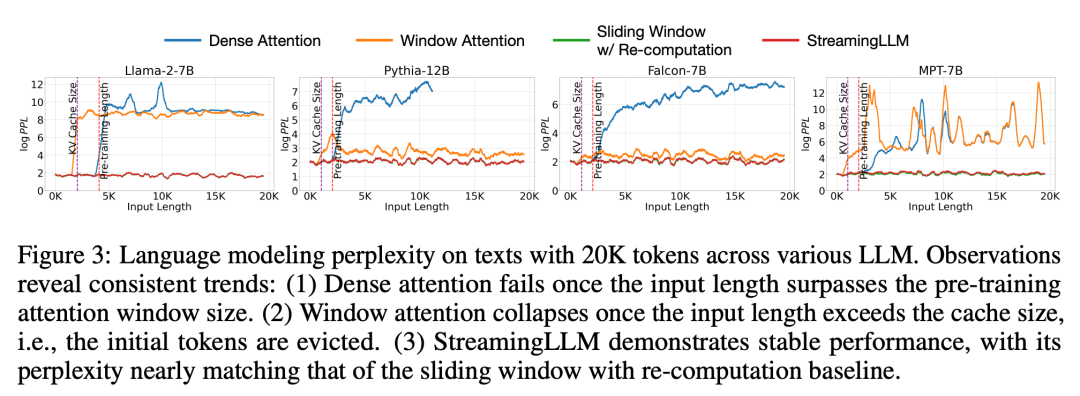
Im Vergleich zur Neuberechnung des Schiebefensters ist StreamingLLM 22,2-mal schneller, ohne die Leistung zu beeinträchtigen vergleichbar mit der Oracle-Basislinie, die das Schiebefenster neu berechnet. Wenn gleichzeitig die Eingabelänge das Vortrainingsfenster überschreitet, schlägt die dichte Aufmerksamkeit fehl, und wenn die Eingabelänge die Cache-Größe überschreitet, bleibt die Fensteraufmerksamkeit hängen, was dazu führt, dass die anfänglichen Tags aussortiert werden
Abbildung 5 Weiter: Die Zuverlässigkeit von StreamingLLM wird demonstriert und es kann Text ungewöhnlicher Größe verarbeiten, darunter mehr als 4 Millionen Token, die verschiedene Modellfamilien und -größen abdecken. Zu diesen Modellen gehören Llama-2-[7,13,70] B, Falcon-[7,40] B, Pythia-[2.8,6.9,12] B und MPT-[7,30] B
Anschließend bestätigten die Forscher die Hypothese des „Aufmerksamkeitspools“ und bewiesen, dass das Sprachmodell vorab trainiert werden kann und während der Streaming-Bereitstellung nur ein Aufmerksamkeitspool-Token erfordert. Konkret schlagen sie vor, zu Beginn aller Trainingsbeispiele ein zusätzliches lernbares Token als ausgewiesenen Aufmerksamkeitspool hinzuzufügen. Indem die Forscher ein Sprachmodell mit 160 Millionen Parametern vorab von Grund auf trainierten, zeigten sie, dass unsere Methode die Leistung des Modells aufrechterhalten kann. Dies steht in scharfem Gegensatz zu aktuellen Sprachmodellen, die die Wiedereinführung mehrerer anfänglicher Token als Aufmerksamkeitspools erfordern, um das gleiche Leistungsniveau zu erreichen.
Abschließend verglichen die Forscher die Dekodierungslatenz und Speichernutzung von StreamingLLM mit dem neu berechneten Schiebefenster und testeten es mit den Modellen Llama-2-7B und Llama-2-13B auf einer einzelnen NVIDIA A6000-GPU. Den Ergebnissen in Abbildung 10 zufolge nimmt die Dekodierungsgeschwindigkeit von StreamingLLM mit zunehmender Cache-Größe linear zu, während die Dekodierungsverzögerung quadratisch zunimmt. Experimente haben gezeigt, dass StreamingLLM eine beeindruckende Geschwindigkeitssteigerung erzielt, wobei die Geschwindigkeit jedes Tokens um das bis zu 22,2-fache erhöht wird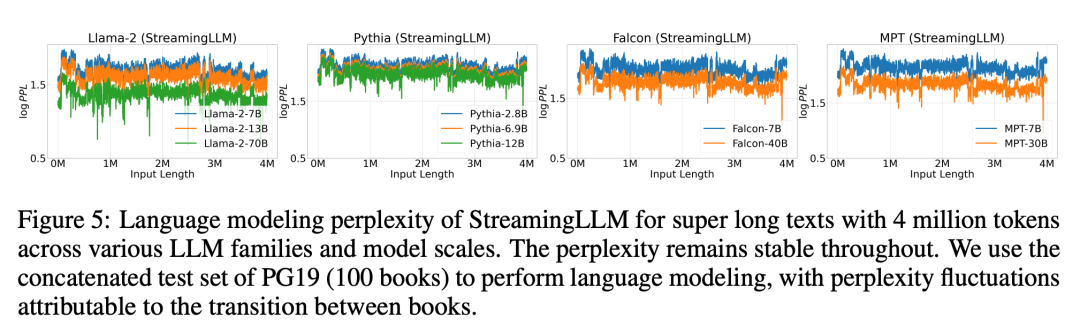
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonMit bis zu 4 Millionen Token-Kontexten und einer 22-mal schnelleren Inferenz erfreut sich StreamingLLM großer Beliebtheit und hat auf GitHub 2,5.000 Sterne erhalten.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



