



Um mit verschiedenen komplexen Audio- und Videokommunikationsszenarien umzugehen, wie z. B. Szenarien mit mehreren Geräten, mehreren Personen und mehreren Geräuschen, ist die Streaming-Media-Kommunikationstechnologie nach und nach zu einer unverzichtbaren Technologie im Leben der Menschen geworden . Um ein besseres subjektives Erlebnis zu erzielen und den Benutzern ein klares und echtes Hören zu ermöglichen, kombiniert die Streaming-Audio-Technologielösung traditionelle maschinelles Lernen und KI-basierte Sprachverbesserungslösungen und nutzt Lösungen der Deep-Neural-Network-Technologie, um eine Reduzierung des Sprachrauschens und eine Echounterdrückung zu erreichen. Störende Spracheliminierung und Audiokodierung und -dekodierung usw., um die Audioqualität bei der Echtzeitkommunikation zu schützen.
Als führende internationale Konferenz auf dem Gebiet der Sprachsignalverarbeitungsforschung repräsentiert Interspeech seit jeher die modernste Forschungsrichtung auf dem Gebiet der Akustik und umfasst unter anderem eine Reihe von Artikeln zu Algorithmen zur Audiosignal-Sprachverbesserung , Volcano Engine Streaming Audio Insgesamt 4 Forschungsarbeiten des Teams wurden von der Konferenz angenommen, darunter Sprachverbesserung, KI-basierte Kodierung und Dekodierung, Echounterdrückung und unüberwachte adaptive Sprachverbesserung.
Es ist erwähnenswert, dass das gemeinsame Team von ByteDance und NPU im Bereich der unbeaufsichtigten adaptiven Sprachverbesserung die Unteraufgabe der unbeaufsichtigten domänenadaptiven Konversationssprachverbesserung (unüberwachte Domäne) des diesjährigen CHiME (Computational Hearing in Multisource Environments) erfolgreich abgeschlossen hat. Challenge. Adaption zur Konversationssprachverbesserung (UDASE) gewann die Meisterschaft (https://www.chimechallenge.org/current/task2/results). Die CHiME Challenge ist ein wichtiger internationaler Wettbewerb, der 2011 von namhaften Forschungseinrichtungen wie dem französischen Institut für Informatik und Automatisierung, der Universität Sheffield in Großbritannien und dem Mitsubishi Electronics Research Laboratory in den Vereinigten Staaten ins Leben gerufen wurde Herausfordernde Fernprobleme im Bereich der Sprachforschung fanden dieses Jahr zum siebten Mal statt. Zu den teilnehmenden Teams an früheren CHiME-Wettbewerben gehören die University of Cambridge im Vereinigten Königreich, die Carnegie Mellon University in den Vereinigten Staaten, die Johns Hopkins University, NTT in Japan, Hitachi Academia Sinica und andere international renommierte Universitäten und Forschungseinrichtungen sowie die Tsinghua University. Universität der Chinesischen Akademie der Wissenschaften, Institut für Akustik der Chinesischen Akademie der Wissenschaften, NPU, iFlytek und andere führende inländische Universitäten und Forschungsinstitute.
In diesem Artikel werden die wichtigsten Szenarioprobleme und technischen Lösungen vorgestellt, die durch diese vier Artikel gelöst werden. Teilen Sie die Denkweise und Praxis des Streaming-Audio-Teams von Volcano Engine im Bereich der Sprachverbesserung, basierend auf KI-Encoder, Echounterdrückung und unbeaufsichtigter adaptiver Sprache Erweiterung.
Papieradresse: https://www.isca-speech.org/archive/interspeech_2023/le23_interspeech.html
Eingeschränkt aufgrund von Latenz und Rechenressourcen Die Sprachverbesserung in Echtzeit-Audio- und Videokommunikationsszenarien verwendet normalerweise Eingabefunktionen, die auf Filterbänken basieren. Durch Filterbänke wie Mel und ERB wird das ursprüngliche Spektrum in niedrigerdimensionale Teilbänder komprimiert. Im Teilbandbereich ist die Ausgabe des auf Deep Learning basierenden Sprachverbesserungsmodells die Sprachverstärkung des Teilbands, die den Anteil der Zielsprachenergie darstellt. Allerdings ist das verbesserte Audiosignal über den komprimierten Subbandbereich aufgrund des Verlusts spektraler Details verschwommen, was häufig eine Nachbearbeitung zur Verbesserung der Harmonischen erfordert. RNNoise und PercepNet verwenden Kammfilter, um Harmonische zu verbessern. Aufgrund der Grundfrequenzschätzung und der Berechnung der Kammfilterverstärkung sowie der Modellentkopplung können sie jedoch nicht durchgängig optimiert werden. DeepFilterNet verwendet einen Zeit-Frequenz-Domänenfilter, um interharmonisches Rauschen zu unterdrücken. nutzt jedoch nicht explizit die grundlegende Frequenzinformation der Sprache. Als Reaktion auf die oben genannten Probleme schlug das Team eine Methode zur Verbesserung der Sprachharmonik vor, die auf einem lernbaren Kammfilter basiert. Diese Methode kombiniert Grundfrequenzschätzung und Kammfilterung, und die Verstärkung des Kammfilters kann durchgängig optimiert werden. Experimente zeigen, dass diese Methode mit einem ähnlichen Rechenaufwand wie bestehende Methoden eine bessere harmonische Verbesserung erzielen kann.
Um die Schwierigkeit der Grundfrequenzschätzung zu verringern und einen durchgängigen Betrieb der gesamten Verbindung zu ermöglichen, wird der zu schätzende Zielgrundfrequenzbereich diskretisiert N diskrete Grundfrequenzen und mithilfe eines Klassifikators geschätzt. 1 Dimension wird hinzugefügt, um nicht stimmhafte Frames darzustellen, und die endgültige Modellausgabe ist die Wahrscheinlichkeit von N+1 Dimensionen. In Übereinstimmung mit CREPE verwendet das Team Gaußsche Glättungsfunktionen als Trainingsziele und binäre Kreuzentropie als Verlustfunktion:
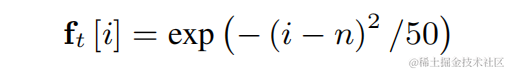
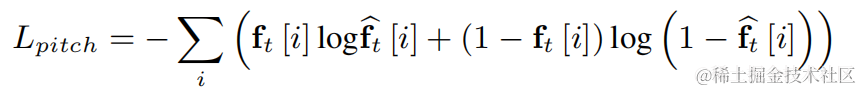
Für jede der oben genannten diskreten Basisfrequenzen verwendet das Team einen FIR-Filter ähnlich wie PercepNet für die Kammfilterung, die als modulierte Impulsfolge ausgedrückt werden kann:
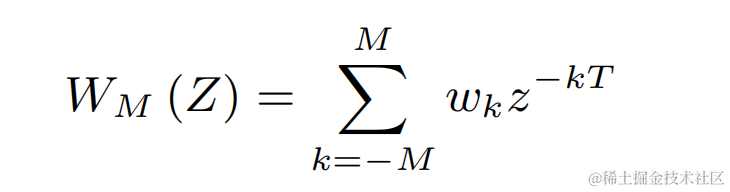
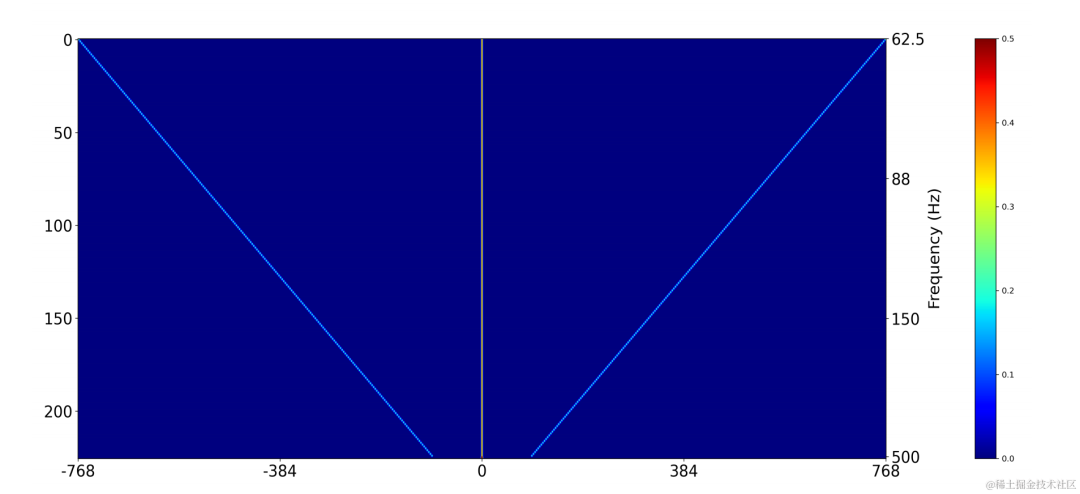
Verwenden Sie eine zweidimensionale Faltungsschicht (Conv2D), um während des Trainings gleichzeitig die Filterergebnisse aller diskreten Grundfrequenzen zu berechnen. Das Gewicht der zweidimensionalen Faltung kann als Matrix in der folgenden Abbildung ausgedrückt werden Dimensionen, und jede Dimension wird verwendet Die obige Filterinitialisierung:
Multiplizieren Sie die One-Hot-Beschriftung der Zielgrundfrequenz und die Ausgabe der zweidimensionalen Faltung, um das Filterergebnis zu erhalten, das der Grundfrequenz jedes Rahmens entspricht :

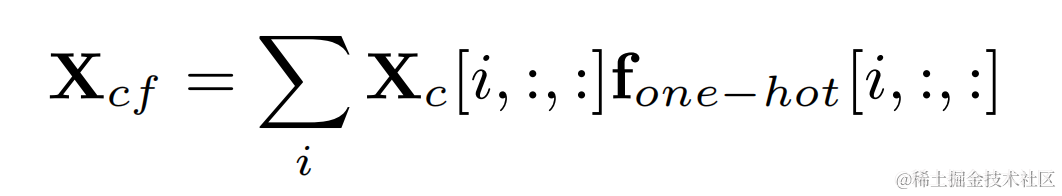
Audio nach harmonischer Verbesserung Addieren Sie das ursprüngliche Audiogewicht und multiplizieren Sie es mit der Subbandverstärkung, um die endgültige Ausgabe zu erhalten:
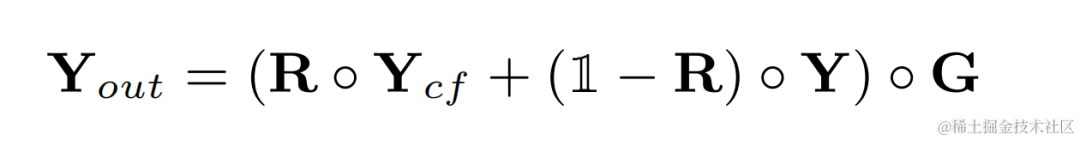
Während der Inferenz muss jeder Frame nur das Filterergebnis von einem berechnen Grundfrequenz, daher ist der Rechenaufwand dieser Methode gering.
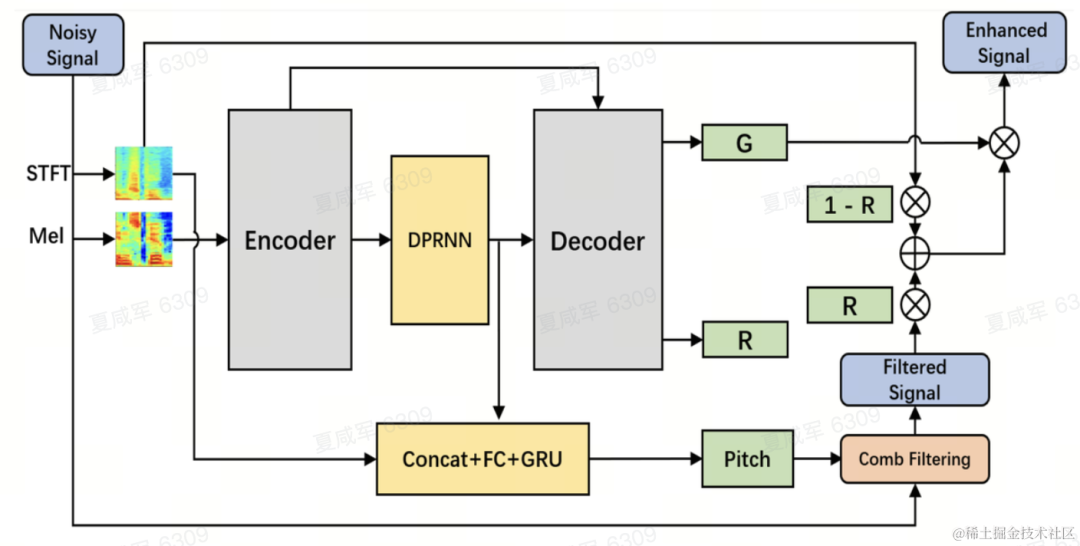
Das Team verwendet das Dual-Path Convolutional Recurrent Network (DPCRN) als Rückgrat des Sprachverbesserungsmodells und fügt einen grundlegenden Frequenzschätzer hinzu. Der Encoder und der Decoder verwenden eine tiefentrennbare Faltung, um eine symmetrische Struktur zu bilden. Der Decoder verfügt über zwei parallele Zweige, die die Teilbandverstärkung G bzw. den Gewichtungskoeffizienten R ausgeben. Der Eingang zum Grundfrequenzschätzer ist der Ausgang des DPRNN-Moduls und das lineare Spektrum. Der Berechnungsbetrag dieses Modells beträgt etwa 300 Millionen MACs, wovon der Berechnungsbetrag der Kammfilterung etwa 0,53 Millionen MACs beträgt.
Im Experiment wurden die VCTK-DEMAND- und DNS4-Challenge-Datensätze für das Training verwendet, und die Verlustfunktion der Sprachverbesserung und die Grundfrequenzschätzung wurden für das Multitasking-Lernen verwendet.
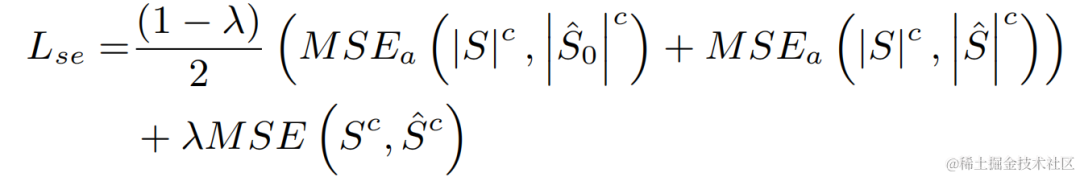
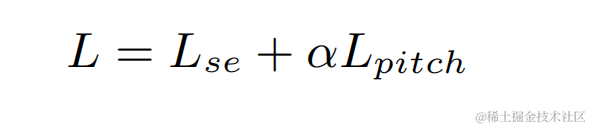
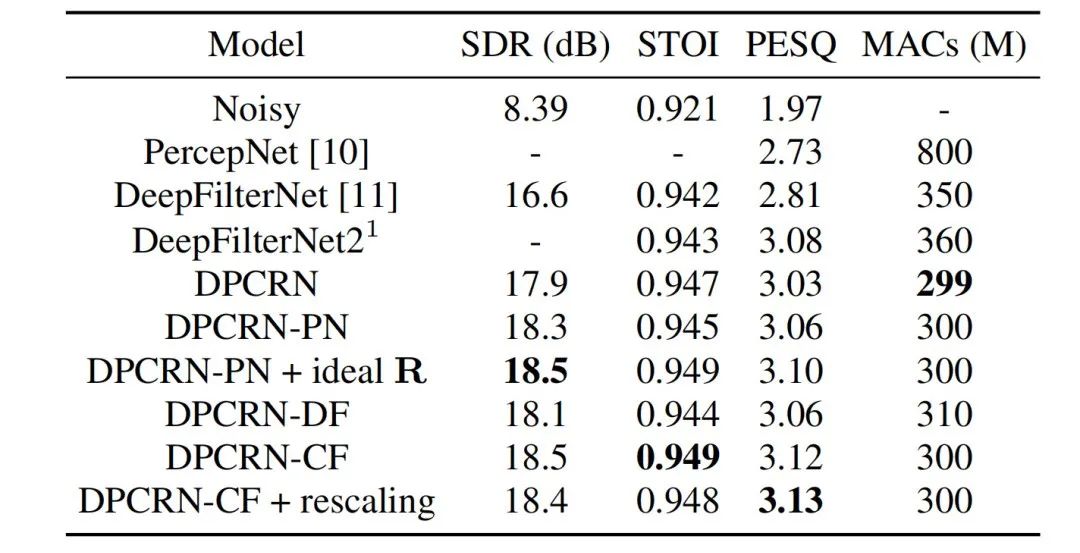
Das vorgeschlagene lernbare Kammfiltermodell wurde mit Modellen verglichen, die den Kammfilter von PercepNet und den Filteralgorithmus von DeepFilterNet verwendeten. Sie heißen DPCRN-CF bzw. DPCRN-DF. Auf dem VCTK-Testsatz zeigt die in diesem Artikel vorgeschlagene Methode Vorteile gegenüber bestehenden Methoden.
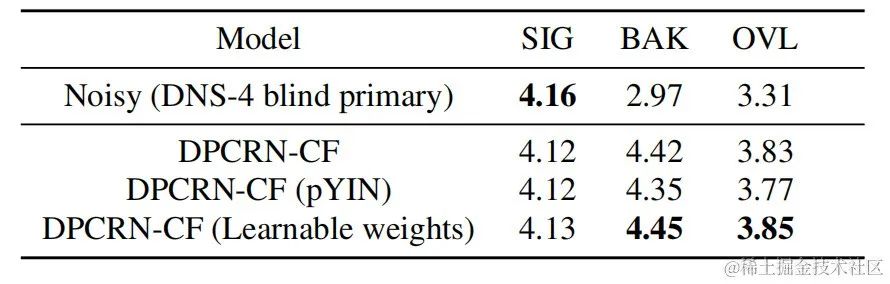
Gleichzeitig führte das Team Ablationsexperimente zur Grundfrequenzschätzung und zu lernbaren Filtern durch. Experimentelle Ergebnisse zeigen, dass End-to-End-Lernen bessere Ergebnisse liefert als die Verwendung signalverarbeitungsbasierter Grundfrequenzschätzungsalgorithmen und Filtergewichte.
Papieradresse: https://www.isca-speech.org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
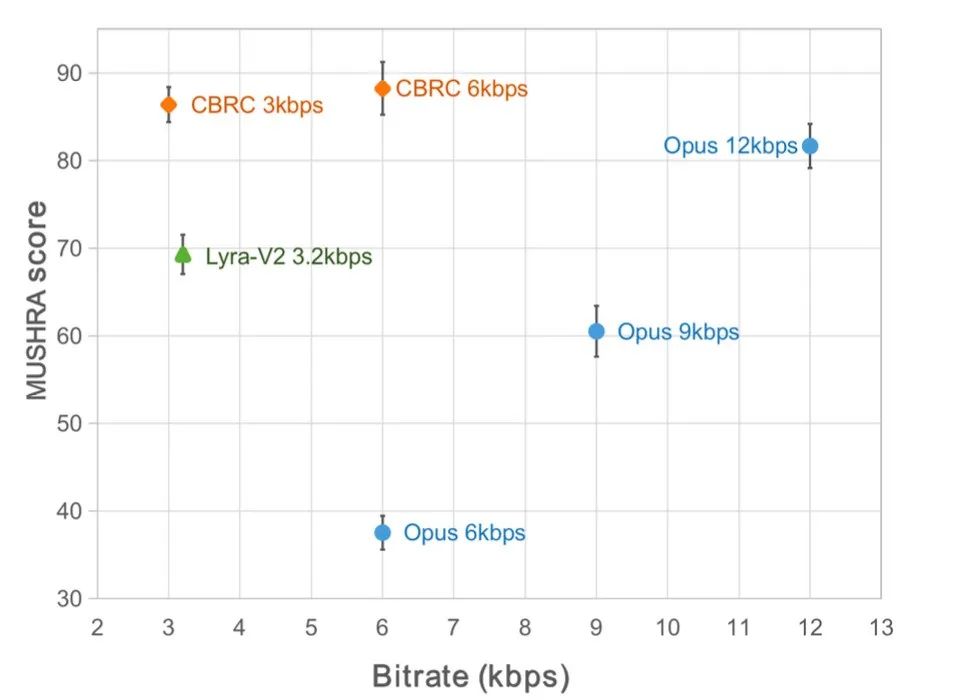
In den letzten Jahren wurden viele neuronale Netzwerkmodelle für Sprachcodierungsaufgaben mit niedriger Bitrate verwendet. Einige End-to-End-Modelle nutzen jedoch die Intra-Frame-bezogenen Informationen nicht vollständig aus, und der eingeführte Quantisierer hat große Auswirkungen Quantisierungsfehler, die zu einer schlechten Audioqualität nach der Kodierung führen. Um die Qualität des End-to-End-Audio-Encoders für neuronale Netzwerke zu verbessern, schlug das Streaming-Audio-Team einen End-to-End-Codec für neuronale Sprache vor, nämlich CBRC (Convolutional and Bidirektional Recurrent Neural Codec). CBRC verwendet eine verschachtelte Struktur aus 1D-CNN (eindimensionale Faltung) und Intra-BRNN (bidirektionales rekurrentes neuronales Intra-Frame-Netzwerk), um die Intra-Frame-Korrelation effektiver zu nutzen. Darüber hinaus nutzt das Team den Group-wise and Beam-search Residual Vector Quantizer (GB-RVQ) in CBRC, um das Quantisierungsrauschen zu reduzieren. CBRC kodiert 16-kHz-Audio mit einer Rahmenlänge von 20 ms ohne zusätzliche Systemverzögerung und eignet sich für Echtzeit-Kommunikationsszenarien. Experimentelle Ergebnisse zeigen, dass die Sprachqualität der CBRC-Kodierung mit einer Bitrate von 3 kbit/s besser ist als die von Opus mit 12 kbit/s.
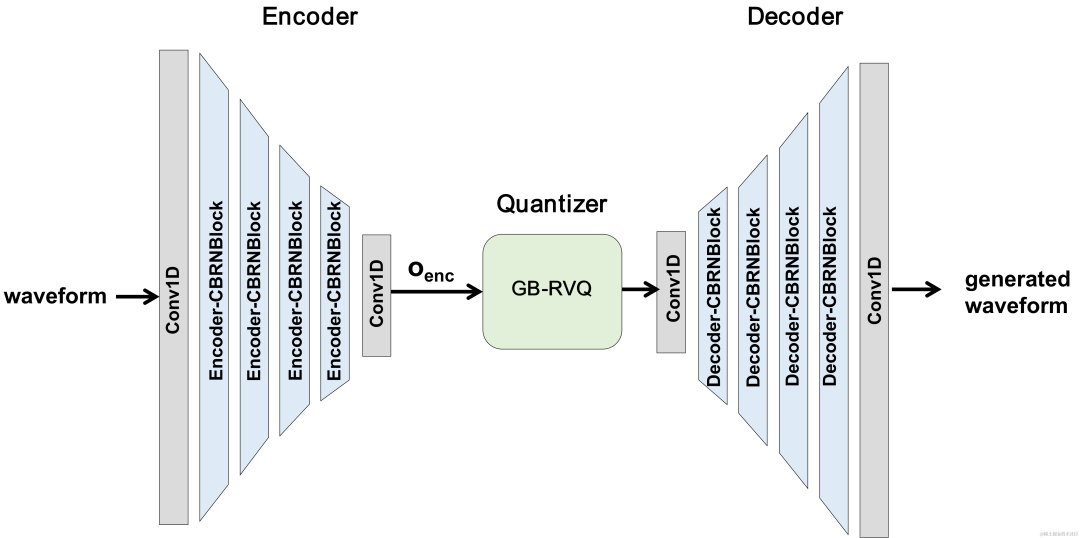
CBRC-Gesamtstruktur
Encoder verwendet 4 kaskadierte CBRNBlocks zum Extrahieren von Audiofunktionen. Jeder CBRNBlock besteht aus drei ResidualUnits zum Extrahieren von Features und einer eindimensionalen Faltung, die die Downsampling-Rate steuert. Jedes Mal, wenn die Features im Encoder heruntergerechnet werden, wird die Anzahl der Feature-Kanäle verdoppelt. ResidualUnit besteht aus einem Restfaltungsmodul und einem verbleibenden bidirektionalen wiederkehrenden Netzwerk, in dem die Faltungsschicht eine kausale Faltung verwendet, während die bidirektionale GRU-Struktur in Intra-BRNN nur 20 ms Intra-Frame-Audiofunktionen verarbeitet. Das Decoder-Netzwerk ist die Spiegelstruktur des Encoders und verwendet eine eindimensionale transponierte Faltung zum Upsampling. Die verschachtelte Struktur von 1D-CNN und Intra-BRNN ermöglicht es dem Encoder und Decoder, die 20 ms Audio-Intra-Frame-Korrelation voll auszunutzen, ohne zusätzliche Verzögerung einzuführen.
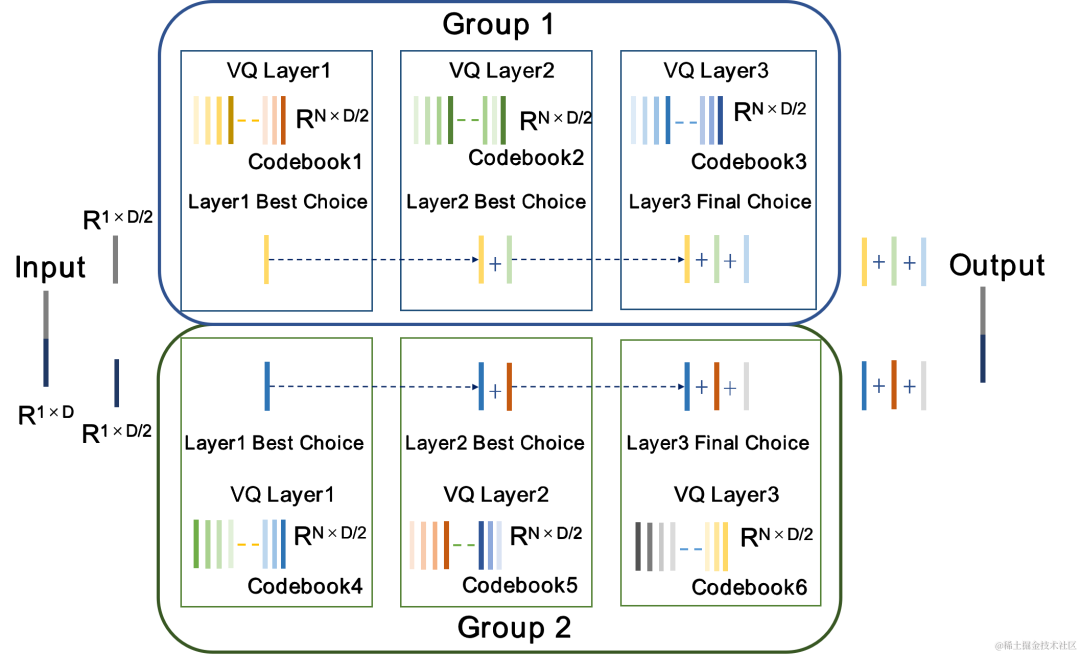
? . RVQ verwendet eine Kaskade von mehrschichtigen Vektorquantisierern (VQ), um Merkmale zu komprimieren. Jede VQ-Schicht quantisiert den Quantisierungsrest der vorherigen VQ-Schicht, wodurch die Anzahl der Codebuchparameter einer einzelnen VQ-Schicht erheblich reduziert werden kann Bitrate. Das Team schlug zwei bessere Quantisiererstrukturen in CBRC vor, nämlich den gruppenweisen RVQ und den Beam-Search-Restvektorquantisierer (Beam-Search RVQ).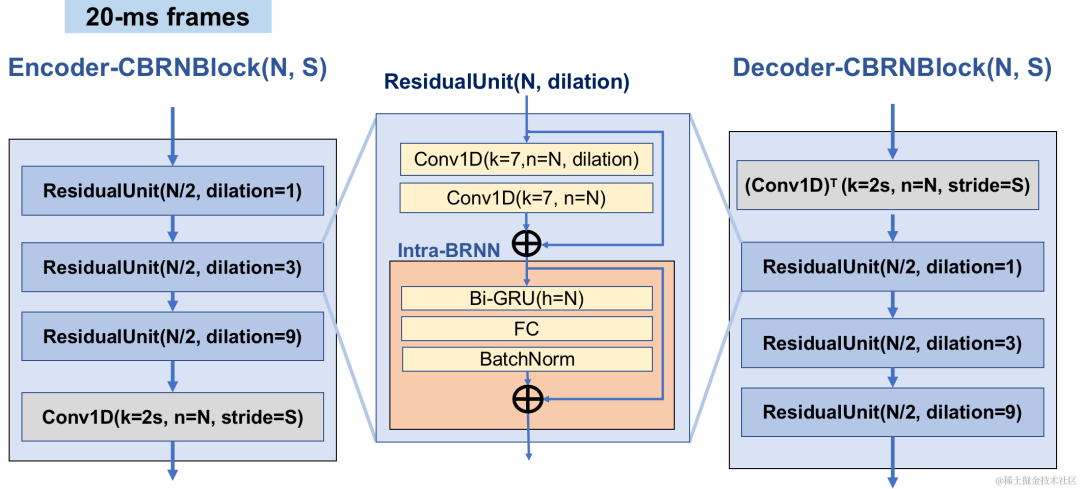
Gruppenweiser RVQ
|
|
||||||||
|
Gruppenweise RVQ gruppiert die Encoder-Ausgabe und verwendet die gruppierte RVQ, um die gruppierten Merkmale unabhängig zu quantifizieren, und dann wird die gruppierte quantisierte Ausgabe in den Eingabe-Decoder gespleißt. Gruppenweises RVQ nutzt die Gruppenquantisierung, um die Codebuchparameter und die Rechenkomplexität des Quantisierers zu reduzieren und gleichzeitig die Schwierigkeit des CBRC-End-to-End-Trainings zu verringern und dadurch die Qualität von CBRC-codiertem Audio zu verbessern. Das Team führte Beam-Search RVQ in das End-to-End-Training des neuronalen Audio-Encoders ein und nutzte den Beam-Search-Algorithmus, um die Codebuchkombination mit dem kleinsten Quantisierungspfadfehler in RVQ auszuwählen, um den Quantisierungsfehler des zu reduzieren Quantisierer. Der ursprüngliche RVQ-Algorithmus wählt das Codebuch mit dem kleinsten Fehler in jeder Schicht der VQ-Quantisierung als Ausgabe aus, aber die Kombination der optimalen Codebücher für jede Schicht der VQ-Quantisierung muss nicht unbedingt die global optimale Codebuchkombination sein. Das Team verwendet Beam-Search RVQ, um k optimale Quantisierungspfade in jeder VQ-Schicht basierend auf dem Kriterium des minimalen Quantisierungspfadfehlers beizubehalten, was die Auswahl besserer Codebuchkombinationen in einem größeren Quantisierungssuchraum ermöglicht und Quantisierungsfehler reduziert.
ModelltrainingIm Experiment wurden 245 Stunden 16-kHz-Sprache im LibriTTS-Datensatz zum Training verwendet, die Sprachamplitude mit einer zufälligen Verstärkung multipliziert und dann in das Modell eingegeben. Die Verlustfunktion im Training besteht aus einem Multiskalenverlust der Spektrumrekonstruktion, einem Diskriminator-Gegnerverlust und einem Merkmalsverlust, einem VQ-Quantisierungsverlust und einem Wahrnehmungsverlust.
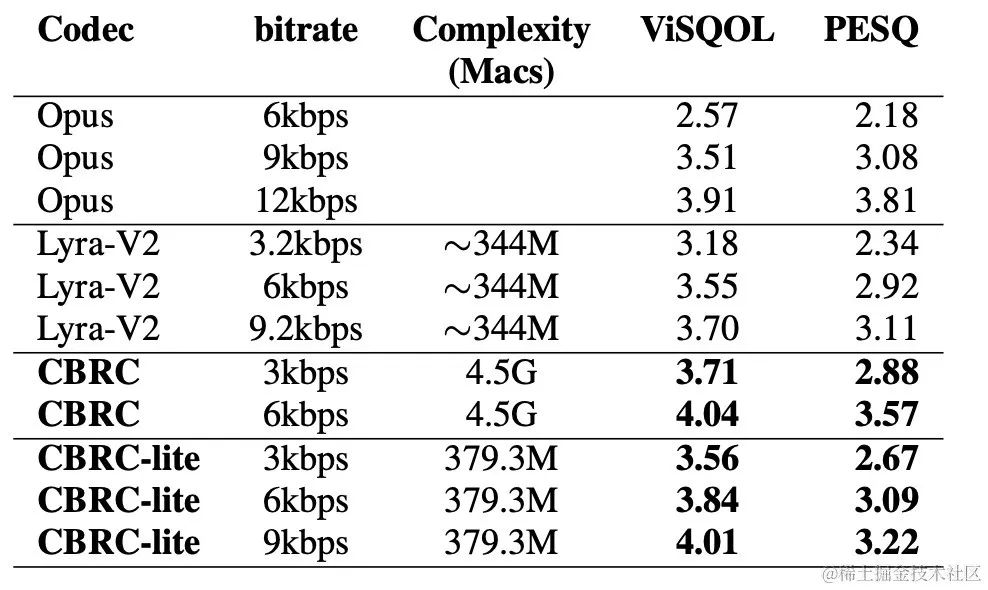
Experimentelle ErgebnisseSubjektive und objektive BewertungenUm die CBRC-codierte Sprachqualität zu bewerten, wurden 10 mehrsprachige Audio-Vergleichssätze erstellt und mit anderen Audio-Codecs in diesem Vergleichssatz verglichen. Um die Auswirkungen der Rechenkomplexität zu reduzieren, entwickelte das Team das leichte CBRC-Lite, dessen Rechenkomplexität etwas höher ist als die von Lyra-V2. Aus den Ergebnissen des subjektiven Hörvergleichs geht hervor, dass die Sprachqualität von CBRC bei 3 kbps die von Opus bei 12 kbps übertrifft und auch die von Lyra-V2 bei 3,2 kbps übertrifft, was die Wirksamkeit der vorgeschlagenen Methode zeigt. CBRC-kodierte Audiobeispiele finden Sie unter https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb.
AblationsexperimentDas Team entwarf Ablationsexperimente für Intra-BRNN, gruppenweises RVQ und Beam-Search-RVQ. Experimentelle Ergebnisse zeigen, dass die Verwendung von Intra-BRNN sowohl im Encoder als auch im Decoder die Sprachqualität erheblich verbessern kann. Darüber hinaus zählte das Team die Häufigkeit der Codebuch-Nutzung in RVQ und berechnete die Entropiedekodierung, um die Codebuch-Nutzungsraten unter verschiedenen Netzwerkstrukturen zu vergleichen. Im Vergleich zur vollständig Faltungsstruktur erhöht CBRC mit Intra-BRNN die potenzielle Codierungsbitrate von 4,94 KBit/s auf 5,13 KBit/s. In ähnlicher Weise kann die Verwendung von gruppenweisem RVQ und Beam-Search-RVQ in CBRC die Qualität codierter Sprache erheblich verbessern, und im Vergleich zur Rechenkomplexität des neuronalen Netzwerks selbst ist der durch GB-RVQ verursachte Komplexitätszuwachs nahezu vernachlässigbar. ?? _1 6k , technisches Team von ByteDance, 10 Sekunden
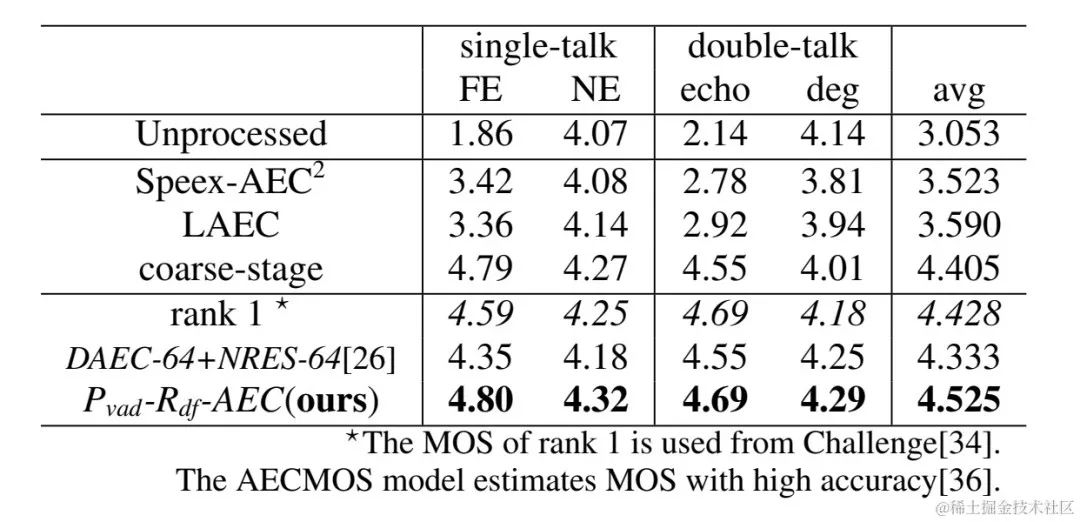
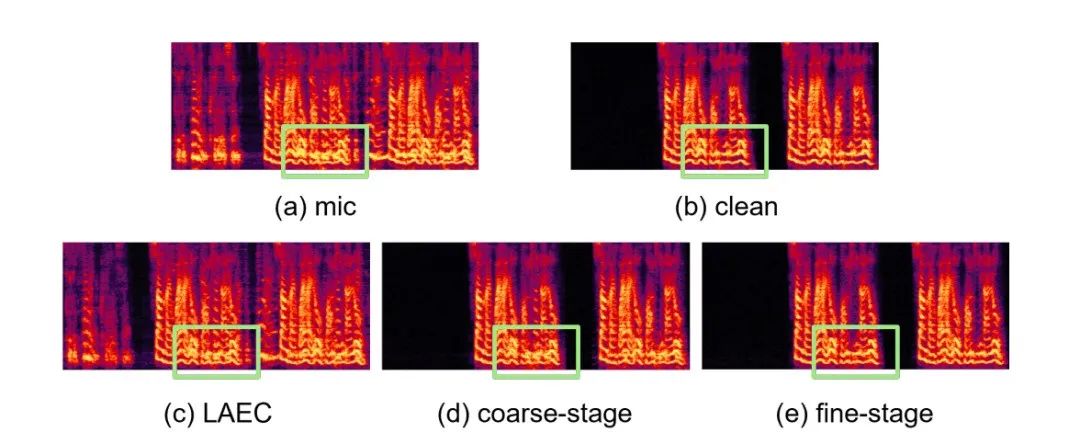
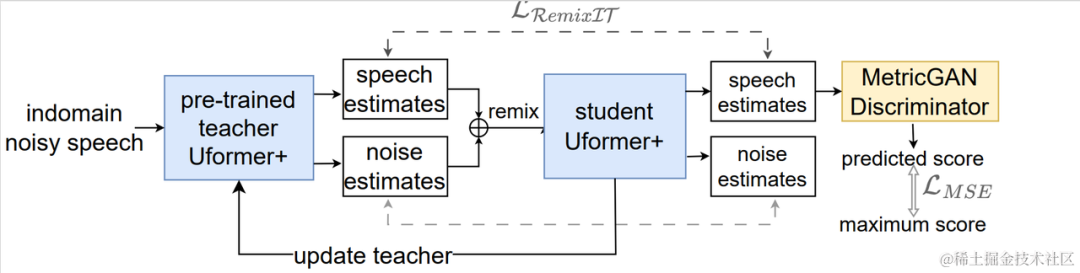
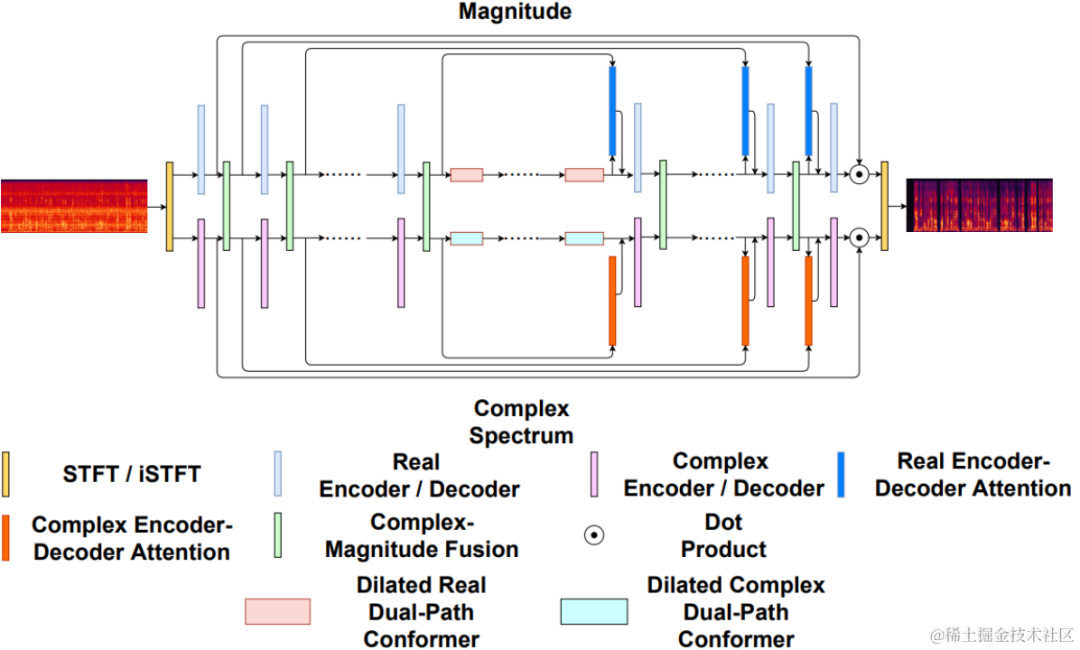
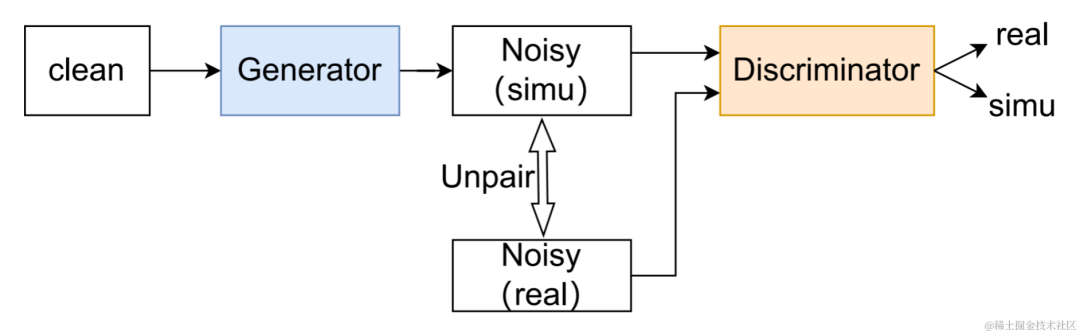
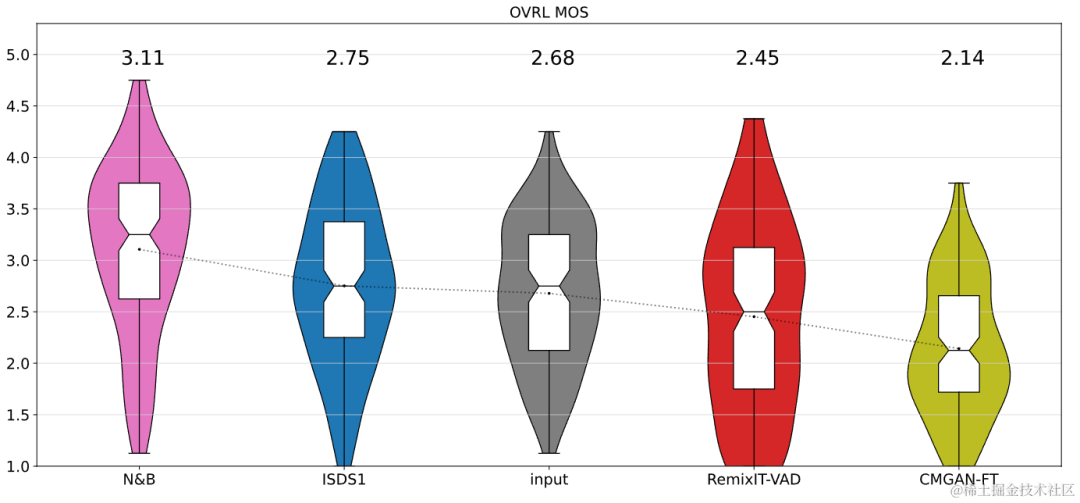
CBRC 3kbpsarctic_a0023_16k_CBRC_3kbps , technisches Team von Bytedance, 5 Sekundenes01_l_16k_CBRC_3kbps , technisches Team von Bytedance, 10 SekundenCBRC-lite 3kbps arctic_a0023_16k_CBRC_lite_3kbps , Bytedance technisch Team, 5 Sekundenes01_l_16k_CBRC_lite_3kbps , technisches Team von Bytedance, 10 SekundenEchounterdrückungsmethode basierend auf einem zweistufigen progressiven neuronalen Netzwerk Papieradresse: https://www.isca-speech.org/archive /pdfs/interspeech_2023/chen23e_interspeech.pdf HintergrundIn Freisprech-Kommunikationssystemen ist akustisches Echo eine störende Hintergrundstörung. Echo entsteht, wenn ein Signal der Gegenseite über einen Lautsprecher wiedergegeben und dann von einem Mikrofon der Gegenseite aufgezeichnet wird. Die akustische Echounterdrückung (AEC) soll unerwünschte Echos unterdrücken, die von Mikrofonen aufgenommen werden. In der realen Welt gibt es viele Anwendungen, die eine Echounterdrückung erfordern, z. B. Echtzeitkommunikation, intelligente Klassenzimmer, Freisprechsysteme in Fahrzeugen usw. In letzter Zeit haben sich datengesteuerte AEC-Modelle, die Deep-Learning-Methoden (DL) nutzen, als robuster und leistungsfähiger erwiesen. Diese Methoden formulieren AEC als überwachtes Lernproblem, bei dem die Zuordnungsfunktion zwischen dem Eingangssignal und dem proximalen Zielsignal über ein tiefes neuronales Netzwerk (DNN) gelernt wird. Allerdings ist der reale Echopfad äußerst komplex, was höhere Anforderungen an die Modellierungsfähigkeiten von DNN stellt. Um den Modellierungsaufwand des Netzwerks zu reduzieren, verwenden die meisten vorhandenen DL-basierten AEC-Methoden ein LAEC-Modul (Front-End Linear Echo Cancellation), um die meisten linearen Komponenten des Echos zu unterdrücken. Allerdings haben LAEC-Module zwei Nachteile: 1) ungeeignetes LAEC kann zu einer gewissen Verzerrung der Nahsprache führen und 2) der LAEC-Konvergenzprozess macht die Leistung der linearen Echounterdrückung instabil. Da LAEC selbstoptimierend ist, werden die Mängel von LAEC eine zusätzliche Lernbelastung für nachfolgende neuronale Netze mit sich bringen. Um die Auswirkungen von LAEC zu vermeiden und eine bessere Sprachqualität im Nahbereich aufrechtzuerhalten, untersucht dieser Artikel ein neues zweistufiges Verarbeitungsmodell basierend auf End-to-End-DL und schlägt eine grobkörnige (grobe Stufe) und eine feine vor -körniges Ein feinstufiges zweistufiges kaskadiertes neuronales Netzwerk (TSPNN) wird für Echokompensationsaufgaben verwendet. Eine große Anzahl experimenteller Ergebnisse zeigt, dass die vorgeschlagene zweistufige Echokompensationsmethode eine bessere Leistung als andere gängige Methoden erzielen kann. ModellrahmenstrukturWie in der folgenden Abbildung dargestellt, besteht TSPNN hauptsächlich aus drei Teilen: Zeitverzögerungskompensationsmodul (TDC), grobkörnigem Verarbeitungsmodul (Grobstufe) und feinkörnigem Verarbeitungsmodul (Feinstufe). . TDC ist für die Ausrichtung des Eingangs-Referenzsignals am fernen Ende (ref) und des Mikrofonsignals am nahen Ende (mic) verantwortlich, was für die nachfolgende Modellkonvergenz von Vorteil ist. Die Grobstufe ist dafür verantwortlich, den größten Teil des Echos und Rauschens aus dem Mikrofon zu entfernen, wodurch der Lernaufwand für das Modell in der anschließenden Feinstufe erheblich reduziert wird. Gleichzeitig kombiniert die Grobstufe die VAD-Aufgabe (Voice Activity Detection) für das Multitasking-Lernen, um die Wahrnehmung von Sprache am nahen Ende durch das Modell zu stärken und Schäden an Sprache am nahen Ende zu reduzieren. Die Feinstufe ist für die weitere Eliminierung von Restecho und Rauschen verantwortlich und kombiniert Informationen zu benachbarten Frequenzpunkten, um das Zielsignal am nahen Ende besser zu rekonstruieren. Um suboptimale Lösungen zu vermeiden, die durch die unabhängige Optimierung des Modells jeder Stufe verursacht werden, verwendet dieser Artikel die Form der Kaskadenoptimierung, um gleichzeitig die Grobstufe und die Feinstufe zu optimieren und gleichzeitig die Einschränkungen auf der Grobstufe zu lockern, um Probleme zu vermeiden zum baldigen Sprachschaden. Um dem Modell außerdem die Fähigkeit zu ermöglichen, Nahsprache wahrzunehmen, führt die vorliegende Erfindung die VAD-Aufgabe für das Lernen mit mehreren Aufgaben ein und fügt der Verlustfunktion den VAD-Verlust hinzu. Die endgültige Verlustfunktion ist: wobei das komplexe Zielspektrum des Nahsignals darstellt, das grobstufige und feinstufige geschätzte komplexe Spektrum des Nahsignals den durch die Grobstufe geschätzten aktiven Sprachzustand am nahen Ende darstellt , Near-End-Sprache bzw. Aktivitätserkennungsetikett; ist ein Kontrollskalar, der hauptsächlich zur Anpassung des Aufmerksamkeitsgrads an verschiedene Phasen in der Trainingsphase verwendet wird. Die vorliegende Erfindung beschränkt darauf, die Beschränkungen auf der Grobstufe zu lockern und eine Beschädigung des proximalen Endes der Grobstufe wirksam zu vermeiden. Das vom Volcano Engine-Streaming-Audio-Team vorgeschlagene zweistufige Echounterdrückungssystem wurde auch mit anderen Methoden verglichen. Die experimentellen Ergebnisse zeigen, dass das vorgeschlagene System bessere Ergebnisse erzielen kann als andere gängige Methoden. Papieradresse: https://www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf In den letzten Jahren mit der Entwicklung neuronaler Netze und datengesteuertem Deep Learning Mit der Entwicklung der Technologie hat sich die Forschung zur Sprachverbesserungstechnologie nach und nach Methoden zugewandt, die auf tiefem Lernen basieren, und es wurden immer mehr Sprachverbesserungsmodelle vorgeschlagen, die auf tiefen neuronalen Netzen basieren. Die meisten dieser Modelle basieren jedoch auf überwachtem Lernen und erfordern für das Training eine große Menge gepaarter Daten. In tatsächlichen Szenarien ist es jedoch unmöglich, die Sprache in lauten Szenen und die gepaarten sauberen Sprachmarkierungen gleichzeitig ohne Interferenzen zu erfassen. Die Datensimulation wird normalerweise verwendet, um saubere Sprache und verschiedene Geräusche getrennt zu erfassen und sie dann entsprechend einem bestimmten Signal zu kombinieren -Rauschverhältnismischungen, um verrauschte Frequenzen zu erzeugen. Dies führt zu einer Diskrepanz zwischen Trainingsszenarien und tatsächlichen Anwendungsszenarien und führt zu einem Leistungsabfall des Modells in tatsächlichen Anwendungen. Um das oben genannte Problem der Domäneninkongruenz besser zu lösen, wurde eine unbeaufsichtigte und selbstüberwachte Sprachverbesserungstechnologie vorgeschlagen, die eine große Menge unbeschrifteter Daten in realen Szenen verwendet. CHiME Challenge Track 2 zielt darauf ab, unbeschriftete Daten zu verwenden, um das Problem der Leistungsverschlechterung von Sprachverbesserungsmodellen zu überwinden, die auf künstlich generierten beschrifteten Daten trainiert werden, aufgrund der Nichtübereinstimmung zwischen Trainingsdaten und tatsächlichen Anwendungsszenarien. Der Schwerpunkt der Forschung liegt auf der Verwendung der unbeschrifteten Zielgruppe Daten der Domäne und die gekennzeichneten Daten außerhalb des Satzes werden verwendet, um die Verbesserungsergebnisse der Zieldomäne zu verbessern. Flussdiagramm des unbeaufsichtigten domänenadaptiven Sprachverbesserungssystems Wie in der Abbildung oben dargestellt, handelt es sich bei dem vorgeschlagenen Rahmen um ein Lehrer-Schüler-Netzwerk. Verwenden Sie zunächst Sprachaktivitätserkennung, UNA-GAN, simulierte Raumimpulsantwort, dynamisches Rauschen und andere Technologien für die Daten in der Domäne, um einen markierten Datensatz zu generieren, der der Zieldomäne am nächsten liegt, und trainieren Sie das Lehrer-Lärmreduzierungsnetzwerk Uformer+ vorab Der markierte Datensatz außerhalb der Domäne. Anschließend wird das Schülernetzwerk mit Hilfe dieses Frameworks auf unbeschriftete Daten in der Domäne aktualisiert, d. h. das vorab trainierte Lehrernetzwerk wird verwendet, um saubere Sprache und Rauschen als Pseudobezeichnungen aus dem verrauschten Audio abzuschätzen, und diese werden neu gemischt Zufällige Reihenfolge als Trainingsdateneingabe in das Studentennetzwerk. Überwachtes Training von Studentennetzwerken unter Verwendung von Pseudo-Labels. Der vom Studentennetzwerk generierte Qualitätswert für saubere Sprache wird mithilfe des vorab trainierten MetricGAN-Diskriminators geschätzt und der Verlust wird mit dem höchsten Wert berechnet, um das Studentennetzwerk bei der Erzeugung sauberer Audioqualität in höherer Qualität anzuleiten. Nach jedem Trainingsschritt werden die Parameter des Schülernetzwerks mit einem bestimmten Gewicht auf das Lehrernetzwerk aktualisiert, um Pseudoetiketten für überwachtes Lernen höherer Qualität usw. zu erhalten. Uformer+ wird durch die Hinzufügung von MetricGAN basierend auf dem Uformer-Netzwerk verbessert. Uformer ist ein komplexes Zweipfad-Konverternetzwerk für reelle Zahlen, das auf der Unet-Struktur basiert. Es verfügt über zwei parallele Zweige, den Amplitudenspektrumzweig und den komplexen Spektrumzweig. Die Netzwerkstruktur ist in der folgenden Abbildung dargestellt. Der Amplitudenzweig wird für die Hauptgeräuschunterdrückungsfunktion verwendet und kann die meisten Geräusche effektiv unterdrücken. Der komplexe Zweig dient als Hilfsmittel zur Kompensation von Verlusten wie spektraler Detailliertheit und Phasenabweichung. Die Hauptidee von MetricGAN besteht darin, mithilfe neuronaler Netze nicht differenzierbare Bewertungsindikatoren für die Sprachqualität zu simulieren, sodass sie beim Netzwerktraining verwendet werden können, um Fehler zu reduzieren, die durch inkonsistente Bewertungsindikatoren während des Trainings und der tatsächlichen Anwendung verursacht werden. Hier verwendet das Team die Perceptual Speech Quality Evaluation (PESQ) als Ziel für die MetricGAN-Netzwerkschätzung. Uformer-Netzwerkstrukturdiagramm RemixIT-G ist ein Lehrer-Schüler-Netzwerk. Es trainiert zunächst das Lehrer-Uformer+-Modell anhand gekennzeichneter Daten außerhalb der Domäne und verwendet das vorab trainierte Lehrermodell um verrauschtes Audio in der Domäne zu dekodieren. Als nächstes wird die Reihenfolge der geschätzten Geräusche und Sprache innerhalb desselben Stapels verwürfelt, und die Geräusche und Sprache werden in der verwürfelten Reihenfolge zu verrauschtem Audio neu gemischt, das als Eingabe für das Training des Studentennetzwerks verwendet wird. Lärm und Sprache werden vom Lehrernetzwerk als Pseudobezeichnungen geschätzt. Das Studentennetzwerk dekodiert die neu gemischten verrauschten Audiodaten, schätzt den Lärm und die Sprache, berechnet Verluste mit Pseudoetiketten und aktualisiert die Parameter des Studentennetzwerks. Die vom Studentennetzwerk geschätzte Sprache wird in den vorab trainierten MetricGAN-Diskriminator eingespeist, um PESQ vorherzusagen, und der Verlust wird mit dem Maximalwert von PESQ berechnet, um die Parameter des Studentennetzwerks zu aktualisieren. Nachdem alle Trainingsdaten eine Iteration abgeschlossen haben, werden die Parameter des Lehrernetzwerks gemäß der folgenden Formel aktualisiert: Wo sind die Parameter der K-ten Trainingsrunde des Lehrernetzwerks? Sind die Parameter des K- Runde des Studierendennetzwerks. Das heißt, die Parameter des Schülernetzwerks werden mit einem bestimmten Gewicht zum Lehrernetzwerk hinzugefügt. UNA-GAN-Strukturdiagramm Unüberwachtes rauschadaptives Datenerweiterungsnetzwerk UNA-GAN ist ein verrauschtes Audiogenerierungsmodell, das auf einem generativen gegnerischen Netzwerk basiert. Der Zweck besteht darin, saubere Sprache direkt in verrauschtes Audio mit domäneninternem Rauschen umzuwandeln, indem nur das verrauschte Audio in der Domäne verwendet wird, wenn keine unabhängigen Rauschdaten erhalten werden können. Der Generator gibt saubere Sprache ein und gibt simuliertes verrauschtes Audio aus. Der Diskriminator gibt das erzeugte verrauschte Audio oder das tatsächlich verrauschte Audio in die Domäne ein und bestimmt, ob das eingegebene Audio aus einer realen Szene stammt oder durch Simulation generiert wird. Der Diskriminator unterscheidet Quellen hauptsächlich anhand der Verteilung von Hintergrundgeräuschen. Dabei wird menschliche Sprache als ungültige Information behandelt. Durch die Durchführung des oben beschriebenen gegnerischen Trainingsprozesses versucht der Generator, domäneninternes Rauschen direkt zum sauberen Eingangsaudio hinzuzufügen, um den Diskriminator zu verwirren, der versucht, die Quelle des verrauschten Audios zu unterscheiden. Um zu vermeiden, dass der Generator zu viel Rauschen hinzufügt und menschliche Sprache im Eingabeaudio überdeckt, wird kontrastives Lernen eingesetzt. Probieren Sie 256 Blöcke an Positionen aus, die dem erzeugten verrauschten Audio und der eingegebenen sauberen Sprache entsprechen. Blockpaare an derselben Position gelten als positive Beispiele, Blockpaare an unterschiedlichen Positionen als negative Beispiele. Berechnen Sie den Kreuzentropieverlust anhand positiver und negativer Beispiele. Die Ergebnisse zeigen, dass der vorgeschlagene Uformer+ eine stärkere Leistung aufweist als der Basis-Sudo rm-rf und die Datenerweiterungsmethode UNA-GAN auch in der Lage ist, verrauschtes Audio in der Domäne zu erzeugen. Das Domänenanpassungs-Framework RemixIT Baseline hat große Verbesserungen bei SI-SDR erzielt, weist jedoch eine schlechte Leistung bei DNS-MOS auf. Die vom Team vorgeschlagene Verbesserung RemixIT-G hat bei beiden Indikatoren gleichzeitig wirksame Verbesserungen erzielt und den höchsten subjektiven Hör-MOS-Wert im Blindtestsatz des Wettbewerbs erzielt. Die endgültigen Ergebnisse des Hörtests sind in der folgenden Abbildung dargestellt. Das Obige stellt einige Lösungen und Effekte vor, die vom Volcano Engine Streaming Audio Team entwickelt wurden und auf Deep Learning in Richtung sprecherspezifischer Geräuschreduzierung, KI-Encoder, Echounterdrückung und unbeaufsichtigter adaptiver Sprachverbesserung basieren. Zukünftige Szenarien stehen immer noch vor Herausforderungen in vielerlei Hinsicht, beispielsweise bei der Bereitstellung und Ausführung von leichten und wenig komplexen Modellen auf verschiedenen Endgeräten und der Robustheit von Multi-Device-Effekten. Diese Herausforderungen werden auch in Zukunft im Fokus des Streaming-Audio-Teams stehen . Forschungsrichtung. |
Das obige ist der detaillierte Inhalt vonInterspeech 2023 |. Volcano Engine Streaming Audio-Technologie Sprachverbesserung und KI-Audiokodierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist ein Servomotor?
Was ist ein Servomotor?
 Einführung in SEO-Diagnosemethoden
Einführung in SEO-Diagnosemethoden
 Was beinhaltet die Datenverschlüsselungsspeicherung?
Was beinhaltet die Datenverschlüsselungsspeicherung?
 Was sind die Hauptunterschiede zwischen Linux und Windows?
Was sind die Hauptunterschiede zwischen Linux und Windows?
 Ein Speicher, der Informationen direkt mit der CPU austauschen kann, ist ein
Ein Speicher, der Informationen direkt mit der CPU austauschen kann, ist ein
 So öffnen Sie eine MDS-Datei
So öffnen Sie eine MDS-Datei
 Ändern Sie die Hintergrundfarbe des Wortes in Weiß
Ändern Sie die Hintergrundfarbe des Wortes in Weiß
 Welche Entwicklungstools gibt es?
Welche Entwicklungstools gibt es?







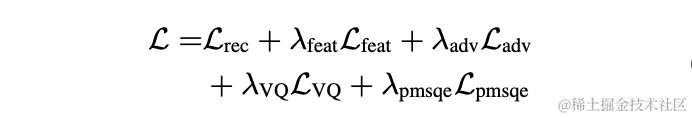
 .
. 



![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



