


Kürzlich löste ein Tweet von Matthias Plappert eine breite Diskussion im LLMs-Kreis aus.
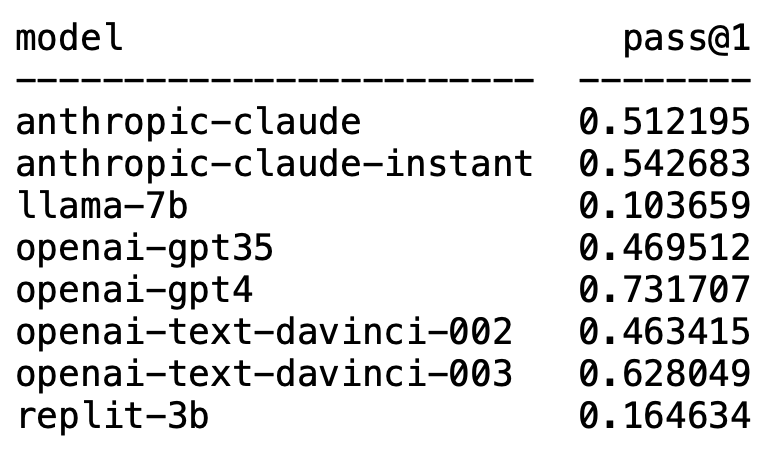
Plappert ist ein bekannter Informatiker. Er hat seine Benchmark-Testergebnisse zum Mainstream-LLM im AI-Circle auf HumanEval veröffentlicht.
Seine Tests sind auf die Codegenerierung ausgerichtet.
Die Ergebnisse sind schockierend und schockierend zugleich.

Unerwartet dominiert GPT-4 zweifellos die Liste und belegt den ersten Platz.
Unerwartet tauchte plötzlich text-davinci-003 von OpenAI auf und belegte den zweiten Platz.
Plappert sagte, dass text-davinci-003 als „Schatz“-Modell bezeichnet werden kann.
Das bekannte LLaMA ist nicht gut in der Codegenerierung.
Plappert sagte, dass die Leistung von GPT-4 sogar besser ist als die Daten in der Literatur.
Die Ein-Runden-Testdaten von GPT-4 in der Arbeit besagen eine Erfolgsquote von 67 %, während Plapperts Test 73 % erreichte.

Bei der Analyse der Ursachen sagte er, dass es viele Möglichkeiten für Unterschiede in den Daten gebe. Einer davon ist, dass die Eingabeaufforderung, die er GPT-4 gab, etwas besser war als zu dem Zeitpunkt, als der Autor des Artikels es testete.
Ein weiterer Grund ist, dass er vermutete, dass die Temperatur des Modells nicht 0 war, als das Papier GPT-4 testete.
„Temperatur“ ist ein Parameter, der verwendet wird, um die Kreativität und Vielfalt des Modells bei der Textgenerierung anzupassen. „Temperatur“ ist ein Wert größer als 0, normalerweise zwischen 0 und 1. Es beeinflusst die Wahrscheinlichkeitsverteilung der abgetasteten vorhergesagten Wörter, wenn das Modell Text generiert.
Wenn die „Temperatur“ des Modells höher ist (z. B. 0,8, 1 oder höher), ist das Modell eher geneigt, aus vielfältigeren und unterschiedlicheren Wörtern auszuwählen, was den generierten Text riskanter und kreativer macht , sondern führt wahrscheinlich auch zu mehr Fehlern und Inkonsistenzen.
Und wenn die „Temperatur“ niedrig ist (z. B. 0,2, 0,3 usw.), wählt das Modell hauptsächlich Wörter mit höherer Wahrscheinlichkeit aus, was zu einem glatteren und kohärenteren Text führt.
Aber an dieser Stelle erscheint der generierte Text möglicherweise zu konservativ und eintönig.
Bei tatsächlichen Anwendungen ist es also notwendig, den geeigneten „Temperatur“-Wert entsprechend den spezifischen Anforderungen abzuwägen und auszuwählen.
Als nächstes sagte Plappert in seinem Kommentar zu text-davinci-003, dass dies auch ein sehr leistungsfähiges Modell unter OpenAI sei.
Obwohl es nicht so gut ist wie GPT-4, belegt es mit einer Erfolgsquote von 62 % in einer Testrunde immer noch den klaren zweiten Platz.
Plappert betonte, dass das Beste an text-davinci-003 darin besteht, dass Benutzer nicht die API von ChatGPT verwenden müssen. Das bedeutet, dass es einfacher sein kann, Eingabeaufforderungen zu geben.
Darüber hinaus gab Plappert auch dem Claude-Instant-Modell von Anthropic AI eine relativ hohe Bewertung.
Er findet die Leistung dieses Modells gut und kann GPT-3.5 schlagen. Die Erfolgsquote von GPT-3.5 beträgt 46 %, während die Erfolgsquote von Claude-Instant 54 % beträgt.
Natürlich kann der andere LLM von Anthropic AI, Claude, nicht von Claude-Instant gespielt werden, und die Erfolgsquote beträgt nur 51 %.
Plappert sagte, dass die Eingabeaufforderungen zum Testen der beiden Modelle gleich seien: Wenn es nicht funktioniert, funktioniert es nicht.
Zusätzlich zu diesen bekannten Modellen hat Plappert auch viele kleine Open-Source-Modelle getestet.
Plappert sagte, dass es gut sei, dass er diese Modelle vor Ort betreiben kann.
Vom Maßstab her sind diese Modelle jedoch offensichtlich nicht so groß wie die von OpenAI und Anthropic AI, sodass ein Vergleich etwas überwältigend ist.

Den Testergebnissen nach zu urteilen, schneidet LLaMA bei der Codegenerierung sehr schlecht ab. Wahrscheinlich, weil sie beim Sammeln von Daten von GitHub eine Unterabtastung verwendet haben.
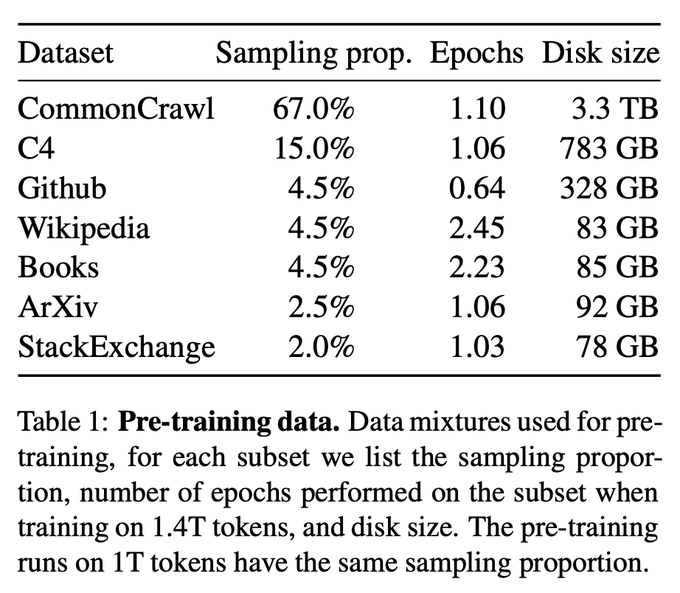 Selbst im Vergleich zu Codex 2.5B ist die Leistung von LLaMA nicht die gleiche. (Erfolgsquote 10 % vs. 22 %)
Selbst im Vergleich zu Codex 2.5B ist die Leistung von LLaMA nicht die gleiche. (Erfolgsquote 10 % vs. 22 %)
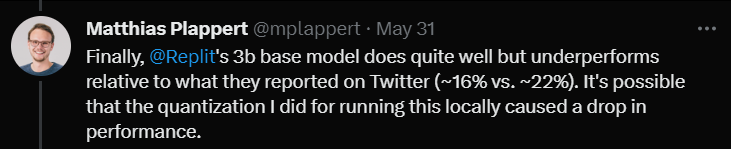
 Schließlich testete er das 3B-Modell von Replit.
Schließlich testete er das 3B-Modell von Replit.
Er sagte, dass die Leistung nicht schlecht sei, aber im Vergleich zu den auf Twitter beworbenen Daten (Erfolgsquote 16 % gegenüber 22 %)
Plappert glaubt, dass dies daran liegen könnte, dass er dieses Modell getestet hat. Die Quantifizierungsmethode Die Erfolgsquote sank um mehrere Prozentpunkte.
 Am Ende der Rezension erwähnte Plappert einen interessanten Punkt.
Am Ende der Rezension erwähnte Plappert einen interessanten Punkt.
Ein Benutzer hat auf Twitter entdeckt, dass GPT-3.5-turbo eine bessere Leistung erbringt, wenn die Completion API der Azure-Plattform (anstelle der Chat API) verwendet wird.
Plappert glaubt, dass dieses Phänomen durchaus legitim ist, da die Eingabe von Eingabeaufforderungen über die Chat-API recht kompliziert sein kann.
Das obige ist der detaillierte Inhalt vonOpenAI dominiert die Top 2! Die Rangliste der großen Modellcode-Generierung wird veröffentlicht, wobei 7 Milliarden LLaMA diese übertreffen und von 250 Millionen Codex übertroffen werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Computersprachen
Computersprachen
 Computer-Anwendungsbereiche
Computer-Anwendungsbereiche
 Welche Kodierung wird in einem Computer zur Verarbeitung von Daten und Anweisungen verwendet?
Welche Kodierung wird in einem Computer zur Verarbeitung von Daten und Anweisungen verwendet?
 Der Hauptgrund, warum Computer Binärdateien verwenden
Der Hauptgrund, warum Computer Binärdateien verwenden
 Was sind die Hauptmerkmale von Computern?
Was sind die Hauptmerkmale von Computern?
 Einführung in die Verwendung des gesamten VBS-Codes
Einführung in die Verwendung des gesamten VBS-Codes
 Was sind die Grundkomponenten eines Computers?
Was sind die Grundkomponenten eines Computers?
 Auf welche Tasten beziehen sich Pfeile in Computern?
Auf welche Tasten beziehen sich Pfeile in Computern?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



