



#🎜 🎜#Einführung: Stable Diffusion zeigt leistungsstarke visuelle Generierungsfähigkeiten. Es gelingt ihnen jedoch oft nicht, Bilder mit räumlicher, struktureller oder geometrischer Kontrolle zu erzeugen. Arbeiten wie ControlNet [1] und T2I-Adpater [2] ermöglichen eine kontrollierbare Bilderzeugung für verschiedene Modalitäten, aber die Anpassung an verschiedene visuelle Bedingungen in einem einzigen einheitlichen Modell bleibt eine ungelöste Herausforderung. UniControl umfasst eine Vielzahl steuerbarer Condition-to-Image-Aufgaben (C2I) in einem einzigen Framework. Um UniControl in die Lage zu versetzen, verschiedene visuelle Bedingungen zu bewältigen, führten die Autoren ein aufgabenbewusstes HyperNet ein, um das nachgeschaltete bedingte Diffusionsmodell so anzupassen, dass es sich gleichzeitig an verschiedene C2I-Aufgaben anpassen kann. UniControl ist für neun verschiedene C2I-Aufgaben geschult und demonstriert starke visuelle Generierungsfähigkeiten und Zero-Shot-Generalisierungsfähigkeiten. Der Autor hat die Modellparameter und den Inferenzcode als Open Source bereitgestellt. Der Datensatz und der Trainingscode werden ebenfalls so schnell wie möglich als Open Source bereitgestellt. Abbildung 1: UniControl-Modell von Bestehend aus mehreren Pre-Training-Aufgaben und Zero-Shot-Aufgaben Alle Modelle sind für eine einzige Modalität konzipiert. Arbeiten wie Taskonomy [3] beweisen jedoch, dass verschiedene visuelle Modalitäten gemeinsame Merkmale und Informationen haben. Daher geht dieser Artikel davon aus, dass ein einheitliches multimodales Modell großes Potenzial hat.
Lösung:  In diesem Artikel werden MOE-ähnliche Adapter und aufgabenorientiertes HyperNet vorgeschlagen, um Funktionen zur multimodalen Bedingungsgenerierung in UniControl zu implementieren. Und der Autor hat einen neuen Datensatz MultiGen-20M erstellt, der 9 Hauptaufgaben, mehr als 20 Millionen Bildbedingungs-Prompt-Tripel und eine Bildgröße ≥512 enthält.
In diesem Artikel werden MOE-ähnliche Adapter und aufgabenorientiertes HyperNet vorgeschlagen, um Funktionen zur multimodalen Bedingungsgenerierung in UniControl zu implementieren. Und der Autor hat einen neuen Datensatz MultiGen-20M erstellt, der 9 Hauptaufgaben, mehr als 20 Millionen Bildbedingungs-Prompt-Tripel und eine Bildgröße ≥512 enthält.
Vorteile: 1) Kompakteres Modell (1,4B #params, 5,78GB Prüfpunkt), Implementieren Sie mehrere Aufgaben mit weniger Parametern. 2) Leistungsstärkere visuelle Generierungsfunktionen und Steuerungsgenauigkeit. 3) Zero-Shot-Generalisierungsfähigkeit auf noch nie gesehene Modalitäten.
1. Einführung Generative Basismodelle verändern die Bereiche der künstlichen Intelligenz in der Verarbeitung natürlicher Sprache, Computer Vision, Audioverarbeitung und Robotersteuerung . Art der Interaktion. Bei der Verarbeitung natürlicher Sprache leisten generative Basismodelle wie InstructGPT oder GPT-4 bei einer Vielzahl von Aufgaben gute Dienste, und diese Multitasking-Fähigkeit ist eine der attraktivsten Funktionen. Darüber hinaus können sie Zero-Shot- oder Fence-Shot-Lernen durchführen, um unbekannte Aufgaben zu bewältigen.
Allerdings ist diese Multitasking-Fähigkeit in generativen Modellen im visuellen Bereich nicht ausgeprägt. Während Textbeschreibungen eine flexible Möglichkeit bieten, den Inhalt generierter Bilder zu steuern, mangelt es ihnen oft an räumlicher, struktureller oder geometrischer Kontrolle auf Pixelebene. Aktuelle populäre Forschungsergebnisse wie ControlNet und der T2I-Adapter können das Stable Diffusion Model (SDM) verbessern, um eine präzise Steuerung zu erreichen. Im Gegensatz zu Sprachhinweisen, die von einem einheitlichen Modul wie CLIP verarbeitet werden können, kann jedes ControlNet-Modell jedoch nur die spezifische Modalität verarbeiten, auf die es trainiert wurde.
Um die Einschränkungen früherer Arbeiten zu überwinden, schlägt dieses Papier UniControl vor, ein einheitliches Diffusionsmodell, das sowohl Sprache als auch verschiedene visuelle Bedingungen verarbeiten kann. Das einheitliche Design von UniControl ermöglicht eine verbesserte Trainings- und Inferenzeffizienz sowie eine verbesserte steuerbare Erzeugung. UniControl hingegen profitiert von den inhärenten Verbindungen zwischen verschiedenen Sehbedingungen, um die generativen Effekte jeder Bedingung zu verstärken.Die einheitliche steuerbare Generierungsfunktion von UniControl basiert auf zwei Teilen: dem „MOE-Style-Adapter“ und dem „Task-aware HyperNet“. Der MOE-Adapter verfügt über etwa 70.000 Parameter und kann Low-Level-Feature-Maps aus verschiedenen Modalitäten erlernen. Das aufgabenbewusste HyperNet kann Aufgabenanweisungen als Eingabeaufforderungen in natürlicher Sprache eingeben und Aufgabeneinbettungen ausgeben, die in das Downstream-Netzwerk eingebettet werden, um die Downstream-Parameter zu modulieren zur Anpassung an verschiedene modale Eingaben. In dieser Studie wurde UniControl vorab trainiert, um die Fähigkeit zum Multitasking- und Zero-Shot-Lernen zu erlangen, einschließlich neun verschiedener Aufgaben in fünf Kategorien: Edge (Canny, HED, Skizze), Flächenkartierung (Segmentierung, Object Bound Box), Skelett (Menschliches Skelett), Geometrie (Tiefe, normale Oberfläche) und Bildbearbeitung (Image Outpainting). Anschließend trainierte die Studie UniControl über 5.000 GPU-Stunden lang auf NVIDIA A100-Hardware (neue Modelle werden auch heute noch trainiert). Und UniControl demonstriert die sofortige Anpassungsfähigkeit an neue Aufgaben. Der Beitrag dieser Studie lässt sich wie folgt zusammenfassen:
2. Modelldesign
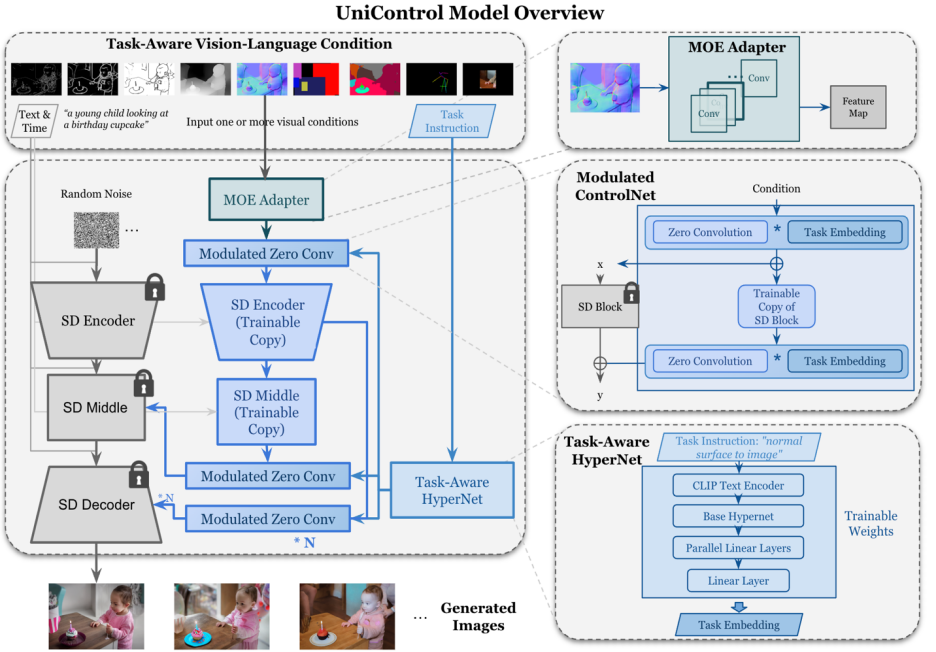
#🎜 🎜#Abbildung 2: Modellstruktur. Um mehrere Aufgaben zu bewältigen, wurde in der Studie ein MOE-Adapter mit etwa 70.000 Parametern pro Aufgabe und einem aufgabenbewussten HyperNet (~12 Millionen Parameter) zur Modulation von 7 Schichten ohne Faltung entwickelt. Diese Struktur ermöglicht die Implementierung von Multitask-Funktionen in einem einzigen Modell, wodurch nicht nur die Vielfalt von Multitasks sichergestellt wird, sondern auch die zugrunde liegende Parameterfreigabe erhalten bleibt. Erhebliche Reduzierung der Modellgröße im Vergleich zu äquivalenten gestapelten Einzelaufgabenmodellen (ca. 1,4 Milliarden Parameter pro Modell).
UniControl-Modelldesign gewährleistet zwei Eigenschaften:
1 ) zu Überwinden Sie die Fehlausrichtung zwischen Low-Level-Features verschiedener Modalitäten. Dies hilft UniControl, notwendige und einzigartige Informationen aus allen Aufgaben zu lernen. Wenn ein Modell beispielsweise auf Segmentierungskarten als visuelle Bedingung basiert, werden 3D-Informationen möglicherweise ignoriert.
2) Kann Metawissen aufgabenübergreifend erlernen. Dadurch kann das Modell das gemeinsame Wissen zwischen Aufgaben und die Unterschiede zwischen ihnen verstehen.
Um diese Eigenschaften bereitzustellen, führt das Modell zwei neuartige Module ein: MOE-Style-Adapter und Task-aware HyperNet.
Der Adapter im MOE-Stil besteht aus einer Reihe von Faltungsmodulen. Jeder Adapter entspricht einer separaten Modalität, inspiriert vom Mischungsmodell der Experten (MOE), das als UniControl-Erfassung verwendet wird Charakterisierung verschiedener Sehstörungen auf niedriger Ebene. Dieses Adaptermodul verfügt über ca. 70.000 Parameter und ist äußerst recheneffizient. Die visuellen Merkmale werden dann zur Verarbeitung in ein einheitliches Netzwerk eingespeist.
Aufgabenbewusstes HyperNet passt das Nullfaltungsmodul von ControlNet durch Aufgabenanweisungsbedingungen an. HyperNet projiziert zunächst die Aufgabenanweisungen in die Aufgabeneinbettung, und dann injizieren die Forscher die Aufgabeneinbettung in die Null-Faltungsschicht von ControlNet. Hier entspricht die Aufgabeneinbettung der Faltungskernmatrixgröße der Null-Faltungsschicht. Ähnlich wie bei StyleGAN [4] multipliziert diese Studie die beiden direkt, um die Faltungsparameter zu modulieren, und die modulierten Faltungsparameter werden als endgültige Faltungsparameter verwendet. Daher sind die modulierten Nullfaltungsparameter jeder Aufgabe unterschiedlich. Dies stellt die Anpassungsfähigkeit des Modells an jede Modalität sicher. Darüber hinaus werden alle Gewichte geteilt.
Anders als bei SDM oder ControlNet ist die Bilderzeugungsbedingung dieser Modelle ein einzelner Sprachhinweis oder eine einzelne Art von visueller Bedingung wie „canny“. UniControl muss eine Vielzahl visueller Bedingungen aus verschiedenen Aufgaben sowie verbale Hinweise bewältigen. Daher besteht die Eingabe von UniControl aus vier Teilen: Geräusch, Textaufforderung, visueller Zustand und Aufgabenanweisung. Unter anderem können Aufgabenanweisungen auf natürliche Weise entsprechend der Modalität des Sehzustands erhalten werden.

Mit solchen generierten Trainingspaaren wurde in dieser Studie DDPM [5] zum Trainieren des Modells übernommen.

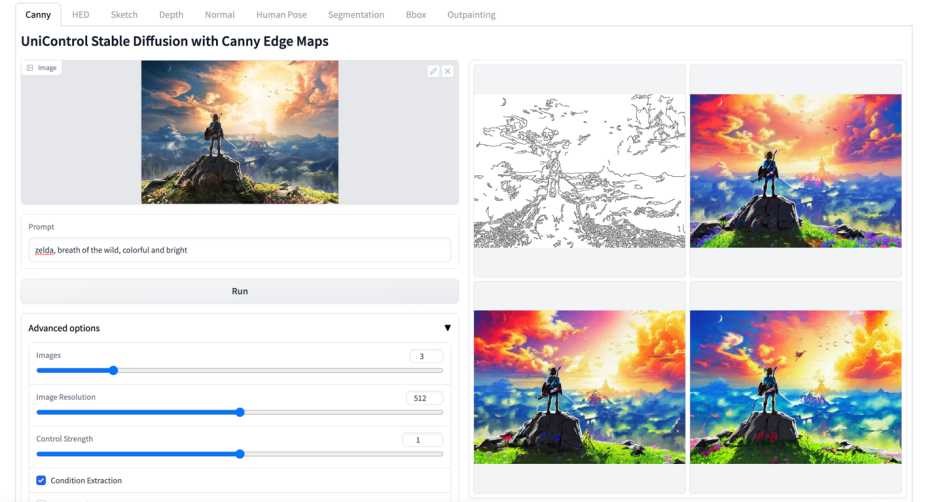
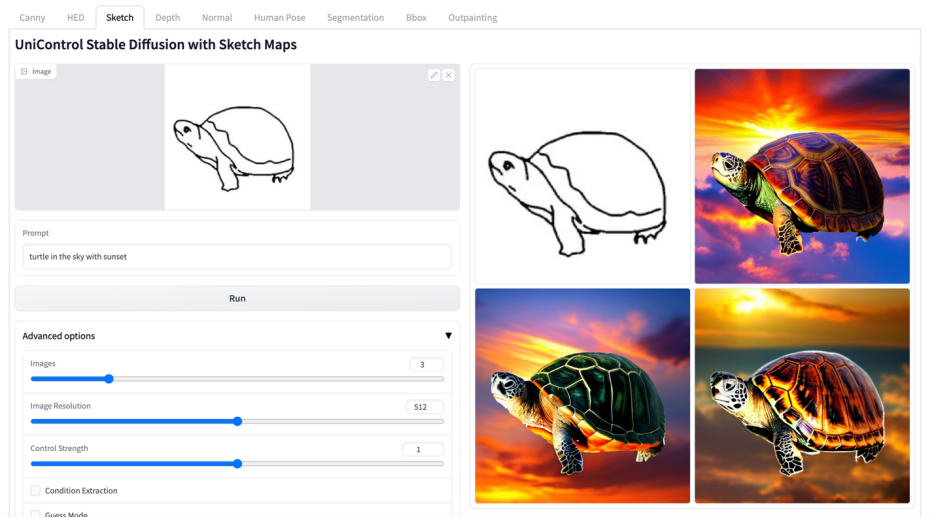
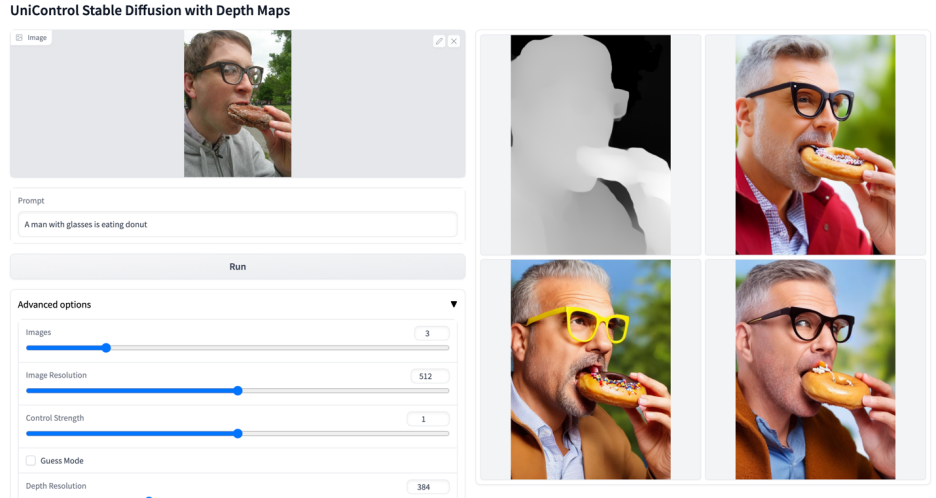
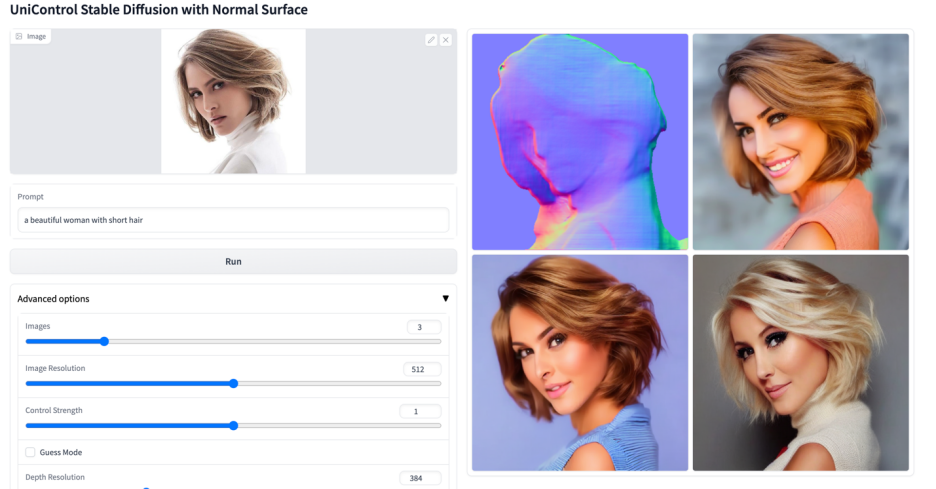
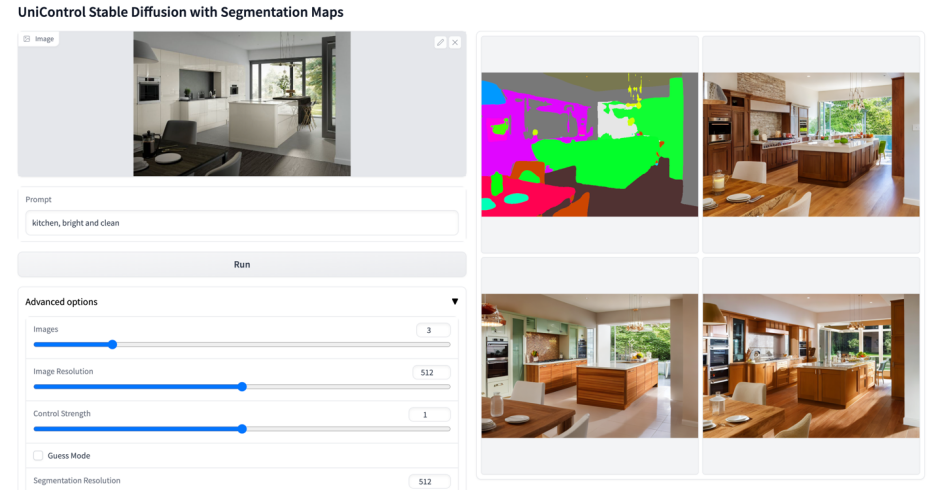
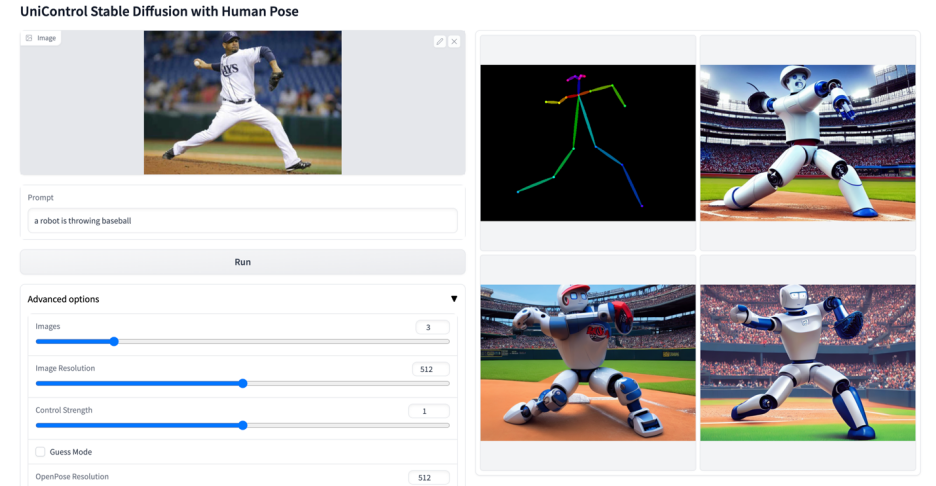
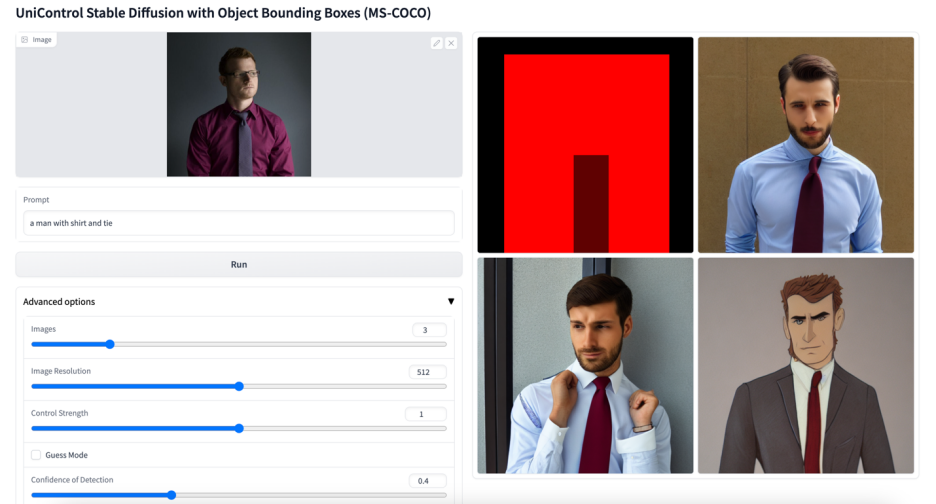
#🎜 🎜#Abbildung 6: Visuelle Vergleichsergebnisse des Testsatzes. Die Testdaten stammen von MSCOCO [6] und Laion [7]
Die hier wiedergegebenen Vergleichsergebnisse mit dem offiziellen oder ControlNet Die Ergebnisse der Studie sind in Abbildung 6 dargestellt. Weitere Ergebnisse finden Sie im Dokument.
5.Zero-Shot-Aufgaben-VerallgemeinerungDas Modell testet die Zero-Shot-Fähigkeit in den folgenden zwei Szenarien: # 🎜🎜#
Verallgemeinerung gemischter Aufgaben: Diese Studie berücksichtigt zwei verschiedene visuelle Bedingungen als Eingabe für UniControl, eine davon ist eine Mischung aus Segmentierungskarten und menschlichen Skeletten, und fügt spezifische Schlüsselwörter in den Textaufforderungen hinzu. „Hintergrund“ und „Vordergrund“. Darüber hinaus schreibt die Studie die Hybridaufgabenanweisungen als Hybridanweisungen zur Kombination zweier Aufgaben um, beispielsweise „Segmentierungskarte und menschliches Skelett zum Bild“.Neue Aufgabenverallgemeinerung: UniControl muss kontrollierbare Bilder unter neuen, noch nie dagewesenen visuellen Bedingungen generieren. Um dies zu erreichen, ist es wichtig, die Aufgabengewichte auf der Grundlage der Beziehung zwischen unsichtbaren und sichtbaren vorab trainierten Aufgaben abzuschätzen. Aufgabengewichte können durch manuelles Zuweisen oder Berechnen von Ähnlichkeitswerten von Aufgabenanweisungen im Einbettungsraum geschätzt werden. Adapter im MOE-Stil können linear mit geschätzten Aufgabengewichten zusammengesetzt werden, um flache Merkmale aus neuen, unsichtbaren visuellen Bedingungen zu extrahieren.
Die visualisierten Ergebnisse sind in Abbildung 7 dargestellt. Weitere Ergebnisse finden Sie im Dokument.

Abbildung 7: UniControl im Nullpunkt Visuelle Ergebnisse bei -Shot-Aufgaben6. Zusammenfassung
Im Allgemeinen hat das UniControl-Modell seine Kontrolle bestanden Diversität bietet ein neues Grundmodell für die kontrollierbare visuelle Generierung. Ein solches Modell könnte die Möglichkeit bieten, ein höheres Maß an Autonomie und menschlicher Kontrolle bei Bilderzeugungsaufgaben zu erreichen. Diese Studie freut sich auf die Diskussion und Zusammenarbeit mit weiteren Forschern, um die Entwicklung dieses Fachgebiets weiter voranzutreiben. Weitere Bilder 🎜#
# 🎜 🎜#
Das obige ist der detaillierte Inhalt vonEs gibt ein einheitliches Modell für die multimodale, steuerbare Bilderzeugung, und alle Modellparameter und Inferenzcodes sind Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 OuYi Exchange USDT-Preis
OuYi Exchange USDT-Preis
 Was ist der Unterschied zwischen dem TCP-Protokoll und dem UDP-Protokoll?
Was ist der Unterschied zwischen dem TCP-Protokoll und dem UDP-Protokoll?
 Localstorage-Nutzung
Localstorage-Nutzung
 So fügen Sie Audio in ppt ein
So fügen Sie Audio in ppt ein
 Welche Software ist Twitter?
Welche Software ist Twitter?
 So konfigurieren Sie die Pfadumgebungsvariable in Java
So konfigurieren Sie die Pfadumgebungsvariable in Java
 Der Unterschied zwischen vivox100s und x100
Der Unterschied zwischen vivox100s und x100
 Java-Multithread-Programmierung
Java-Multithread-Programmierung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



