


Transformer ist zweifellos das beliebteste Modell im Bereich maschinelles Lernen der letzten Jahre.
Seit sie 2017 in der Veröffentlichung „Aufmerksamkeit ist alles, was Sie brauchen“ vorgeschlagen wurde, hat diese neue Netzwerkstruktur große Übersetzungsaufgaben überwältigt und viele neue Datensätze erstellt.
Aber Transformer hat einen Fehler beim Umgang mit langen Bytesequenzen ein gravierender Verlust an Rechenleistung, und die neuesten Ergebnisse der Meta-Forscher können diesen Fehler gut beheben.
Sie haben eine neue Modellarchitektur eingeführt, die mehr als 1 Million Token in mehreren Formaten generieren kann und den bestehenden Transformer hinter Modellen wie GPT-4 Architectural-Funktionen übertrifft.
Dieses Modell heißt „Megabyte“ und ist eine Multiskalen-Decoder-Architektur, die mehr als eine End-to-End-differenzierbare Modellierung von Megabyte-Sequenzen verarbeiten kann.

Papierlink: https://arxiv.org/abs/2305.07185
Warum Megabyte besser ist als Transformer, müssen Sie sich zunächst die Mängel von Transformer ansehen.
Bisher gibt es mehrere Arten von leistungsstarken generativen KI-Modellen, wie GPT-4 von OpenAI und Bard, They sind alle Modelle, die auf der Transformer-Architektur basieren.
Aber Metas Forschungsteam glaubt, dass die beliebte Transformer-Architektur möglicherweise an ihre Grenzen stößt, wobei die Hauptgründe zwei wichtige Mängel im Transformer-Design sind: #🎜🎜 #
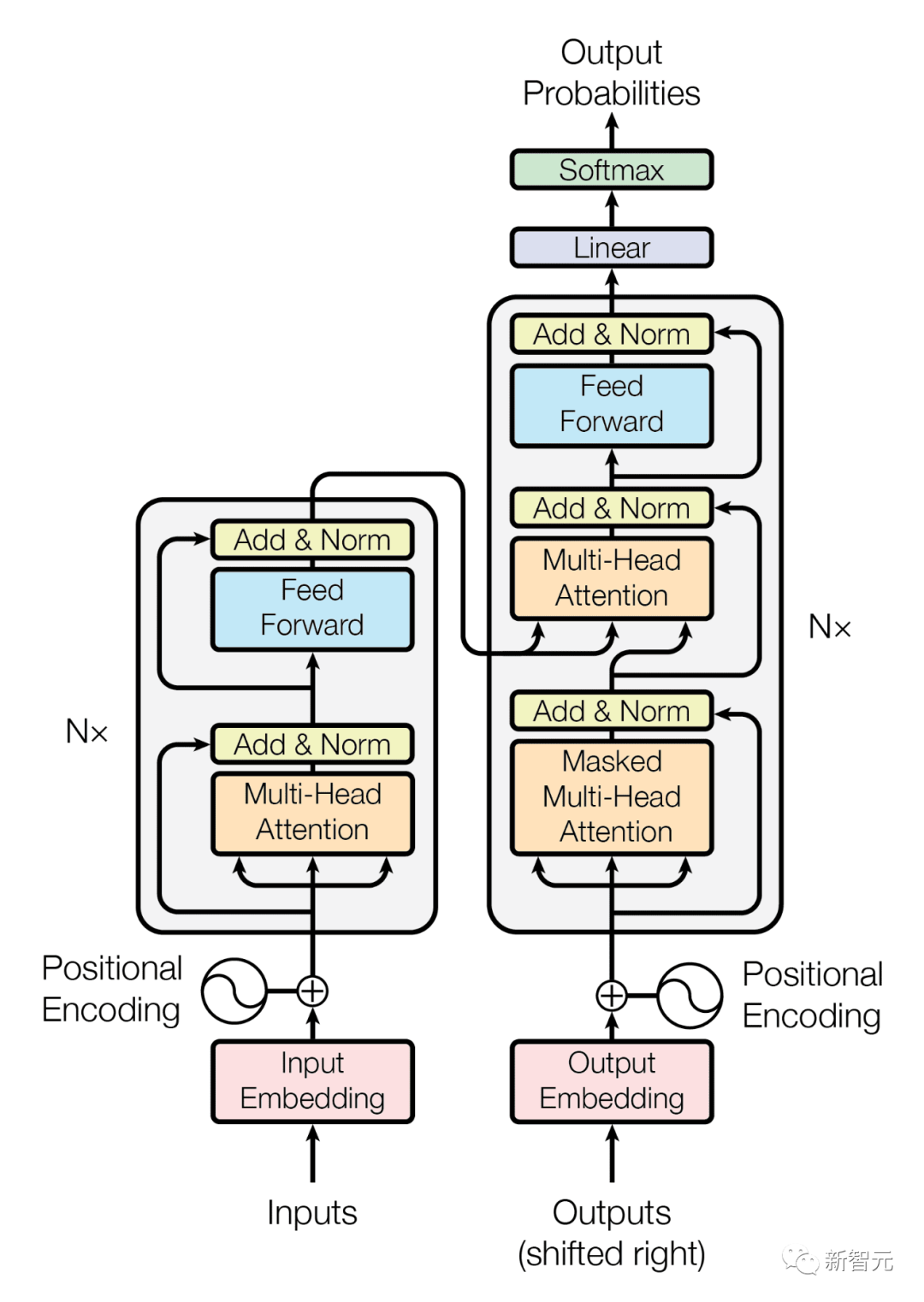
- Mit zunehmender Länge der Eingabe- und Ausgabebytes steigen auch die Kosten für die Selbstaufmerksamkeit rapide an, da eingegebene Musik-, Bild- oder Videodateien normalerweise mehrere Megabyte enthalten. Große- Scale-Decoder (LLMs) verwenden typischerweise nur ein paar tausend kontextbezogene Token – Feedforward-Netzwerke helfen Sprachmodellen, Wörter durch eine Reihe mathematischer Operationen und Transformationen zu verstehen und zu verarbeiten. Skalierbarkeit ist jedoch auf Positionsbasis schwer zu erreichen. Diese Netzwerke arbeiten auf Zeichenbasis Gruppen oder Positionen unabhängig voneinander, was zu einem erheblichen Rechenaufwand führt 🎜#Im Vergleich zu Transformer weist das Megabyte-Modell eine einzigartige und andere Architektur auf, bei der die Eingabe- und Ausgabesequenzen in Patches statt in einzelne Token unterteilt werden.
Wie unten gezeigt, generiert das lokale KI-Modell in jedem Patch Ergebnisse, während das globale Modell die endgültige Ausgabe aller Patches verwaltet und koordiniert.
Zuerst wird die Bytesequenz grob in Patches fester Größe aufgeteilt Ähnlich wie Token besteht dieses Modell aus drei Teilen:
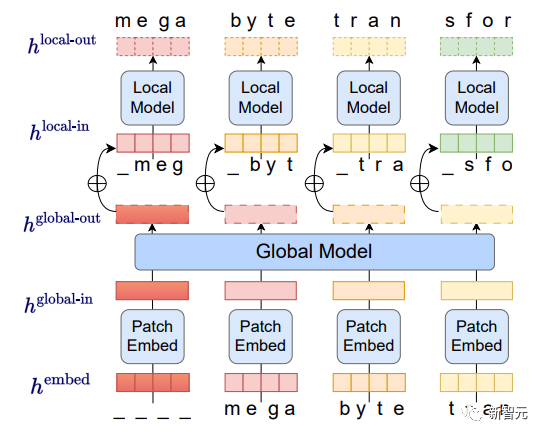 (1) Patch-Embedder: Einfach durch verlustfreie Verkettung der Einbettungen jedes Bytes Lokal codierter Patch# 🎜🎜#
(1) Patch-Embedder: Einfach durch verlustfreie Verkettung der Einbettungen jedes Bytes Lokal codierter Patch# 🎜🎜#
(2) Ein globales Modell: ein großer autoregressiver Transformator, dargestellt durch Eingabe- und Ausgabepatches (3) Ein lokales Modell: ein kleines autoregressives Modell, das Bytes vorhersagt im Patch
Forscher haben festgestellt, dass Bytevorhersagen für die meisten Aufgaben relativ einfach sind (z. B. das Vervollständigen eines Wortes anhand der ersten Zeichen), was bedeutet dass große Netzwerke pro Byte unnötig sind und kleinere Modelle für interne Vorhersagen verwendet werden können.
Dieser Ansatz löst die Skalierbarkeitsherausforderungen, die in heutigen KI-Modellen vorherrschen. Das Patch-System des Megabyte-Modells ermöglicht die Ausführung eines einzelnen Feed-Forward-Netzwerks auf einem Patch, der mehrere Token enthält, und löst so effektiv das Problem des Selbst - Problem der Aufmerksamkeitsskalierung.
Unter anderem hat die Megabyte-Architektur drei wesentliche Verbesserungen am Transformer für die Modellierung langer Sequenzen vorgenommen:
#🎜🎜 # – Subquadratische Selbstaufmerksamkeit, während Megabyte eine lange Sequenz in zwei kürzere Sequenzen aufteilt, was auch bei langen Sequenzen immer noch einfach zu handhaben ist.
- Patch-Feedforward-Ebenen (Per-Patch-Feedforward-Ebenen)
in GPT-3-Größe In der Modell werden mehr als 98 % der FLOPS zur Berechnung der Positions-Feedforward-Schicht verwendet. Megabyte verwendet für jeden Patch eine große Feedforward-Schicht, um bei gleichen Kosten ein größeres und leistungsfähigeres Modell zu erreichen. Bei einer Patchgröße von P verwendet der Basiskonverter dieselbe Feedforward-Schicht mit m Parametern P-mal, und Megabyte kann eine Schicht mit mP-Parametern einmal zum gleichen Preis verwenden.
- Parallelität bei der Dekodierung
Transformatoren müssen während der Generierung serialisiert werden. Alle Berechnungen werden aufgrund der Eingabe von durchgeführt Jeder Zeitschritt ist die Ausgabe des vorherigen Zeitschritts. Durch die parallele Generierung der Patch-Darstellung ermöglicht Megabyte eine größere Parallelität im Generierungsprozess.
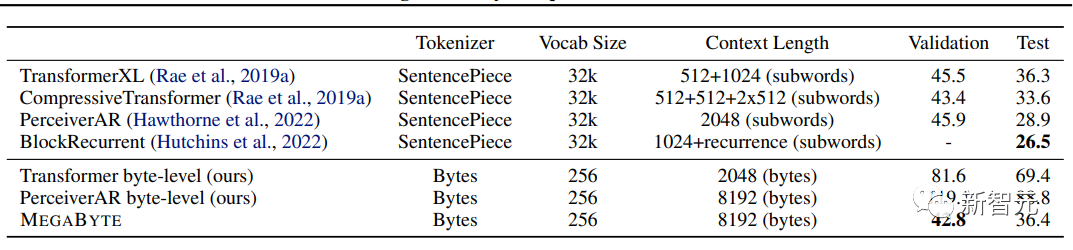
Zum Beispiel generiert ein Megabyte-Modell mit 1,5-B-Parametern Sequenzen, die 40 % schneller sind als ein standardmäßiger 350MTransformer, und verbessert sich dennoch beim Training mit dem gleichen Rechenaufwand. Verwirrung.
Megabyte übertrifft andere Modelle bei weitem und liefert Ergebnisse, die mit auf Unterwörtern trainierten Sota-Modellen konkurrenzfähig sind
#🎜🎜 #
Im Vergleich dazu hat GPT-4 von OpenAI ein Limit von 32.000 Token, während Claude von Anthropic ein Limit von 100.000 Token hat.Darüber hinaus verwendet Megabyte im Hinblick auf die Recheneffizienz innerhalb eines festen Modellgrößen- und Sequenzlängenbereichs weniger Token als Transformers und Linear Transformers derselben Größe, was dies ermöglicht Gleicher Rechenaufwand bei Verwendung eines größeren Modells. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#kurz , Diese Verbesserungen ermöglichen es uns, größere, leistungsstärkere Modelle mit demselben Rechenbudget zu trainieren, auf sehr lange Sequenzen zu skalieren und die Build-Geschwindigkeit während der Bereitstellung zu erhöhen.
Wie wird die Zukunft aussehen? Die Parameter werden immer höher.
Während GPT-3.5 auf 175B-Parameter trainiert wurde, spekulieren einige, dass das leistungsfähigere GPT-4 auf 1 Billion Parameter trainiert wurde.
Auch OpenAI-CEO Sam Altman schlug kürzlich einen Strategiewechsel vor. Er sagte, das Unternehmen erwäge, das Training großer Modelle aufzugeben und sich auf andere Leistungsoptimierungen zu konzentrieren.
Er setzt die Zukunft von KI-Modellen mit iPhone-Chips gleich, während die meisten Verbraucher keine Ahnung von den reinen technischen Spezifikationen haben. Die Forscher von Meta glauben, dass ihre innovative Architektur zum richtigen Zeitpunkt kommt, geben jedoch zu, dass es auch andere Möglichkeiten zur Optimierung gibt.Zum Beispiel ein effizienteres Encodermodell mit Patching-Technologie, ein Decodierungsmodell, das die Sequenz in kleinere Blöcke aufteilt und die Sequenz in ein komprimiertes Token vorverarbeitet usw. und kann die Fähigkeiten vorhandener Transformer-Architekturen erweitern, um Modelle der nächsten Generation zu erstellen.
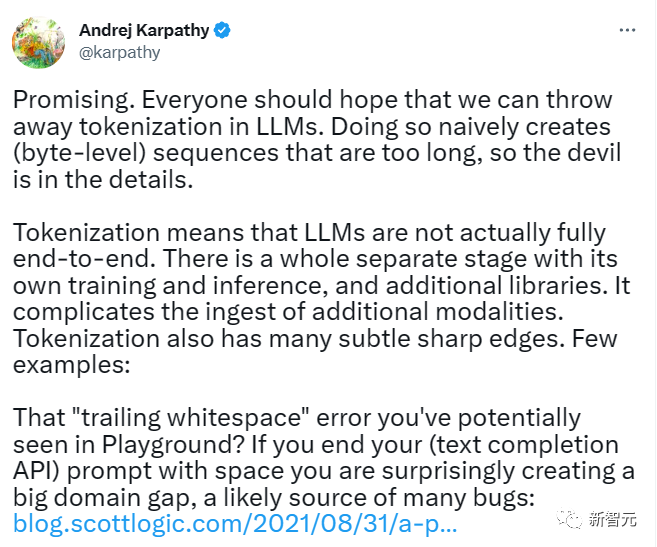
Der ehemalige Tesla AI-Direktor Andrej Karpathy äußerte auch seine Ansichten zu diesem Papier. Er schrieb auf Twitter:
Das ist sehr vielversprechend und jeder sollte hoffen, dass wir die Tokenisierung in großen Modellen abschaffen und die Notwendigkeit dieser langen Bytesequenzen beseitigen können.
Das obige ist der detaillierte Inhalt von40 % schneller als Transformer! Meta veröffentlicht neues Megabyte-Modell, um das Problem des Rechenleistungsverlusts zu lösen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Ist die Geschwindigkeit von PHP8.0 verbessert?
Ist die Geschwindigkeit von PHP8.0 verbessert?
 Was sind private Clouds?
Was sind private Clouds?
 Formelle Handelsplattform für digitale Währungen
Formelle Handelsplattform für digitale Währungen
 So registrieren Sie einen dauerhaften Website-Domainnamen
So registrieren Sie einen dauerhaften Website-Domainnamen
 Was bedeutet Bildrate?
Was bedeutet Bildrate?
 So stellen Sie Freunde wieder her, nachdem Sie auf TikTok blockiert wurden
So stellen Sie Freunde wieder her, nachdem Sie auf TikTok blockiert wurden
 So registrieren Sie eine geschäftliche E-Mail-Adresse
So registrieren Sie eine geschäftliche E-Mail-Adresse
 C#-Task-Nutzung
C#-Task-Nutzung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



