


Die Daten in der MySQL-Datenbank werden in Form von Dateien auf der Festplatte gespeichert. Standardmäßig werden sie unter /mysql/data abgelegt (kann über das Datenverzeichnis in my.cnf angezeigt werden). Tabelle entspricht hauptsächlich Es gibt drei Dateien, eine ist frm zum Speichern der Tabellenstruktur, eine ist myd zum Speichern der Tabellendaten und eine ist myi zum Speichern des Tabellenindex. Wenn die Datenmenge in einer Tabelle zu groß ist, werden myd und myi sehr groß und die Suche nach Daten wird sehr langsam. Zu diesem Zeitpunkt können wir die Partitionsfunktion von MySQL verwenden, um dieser Tabelle zu entsprechen Drei Dateien sind in viele kleine Blöcke unterteilt. Wenn wir nach Daten suchen, müssen wir nicht alle durchsuchen. Wir müssen nur wissen, in welchem Block sich die Daten befinden, und dann darin suchen Block. Wenn eine Tabelle eine große Datenmenge enthält, kann es erforderlich sein, die Daten auf mehrere Festplatten zu verteilen, um zu verhindern, dass eine Festplatte alle Daten speichern kann.
Tabellenpartitionierung ist der Prozess der Aufteilung einer Tabelle in einer Datenbank in kleinere und besser verwaltbare Teile basierend auf bestimmten Regeln. Logischerweise gibt es nur eine Tabelle, aber die unterste Ebene besteht aus mehreren physischen Partitionen.
Untertabelle: bezieht sich auf die Zerlegung einer Tabelle in mehrere verschiedene Tabellen durch bestimmte Regeln. Beispielsweise werden Benutzerbestellungsdatensätze zeitabhängig in mehrere Tabellen unterteilt. Der Unterschied zwischen Partitionierung und Tabellenunterteilung besteht darin, dass die Partitionierung logischerweise nur eine Tabelle umfasst, während die Tabellenunterteilung eine Tabelle in mehrere Tabellen aufteilt.
(1) Im Vergleich zu einer einzelnen Festplatte oder Dateisystempartition können mehr Daten gespeichert werden.
Im Allgemeinen können Daten, die keinen Aufbewahrungswert haben, einfach gelöscht werden, indem die damit verbundenen Partitionen gelöscht werden. Um neue Daten einfach hinzuzufügen, können Sie manchmal eine neue Partition erstellen, um diese neuen Daten speziell zu speichern.
(3) Einige Abfragen können erheblich optimiert werden. Dies liegt hauptsächlich daran, dass die Daten, die eine bestimmte WHERE-Anweisung erfüllen, nur in einer oder mehreren Partitionen gespeichert werden können für andere verbleibende Partitionen. Da die Partitionierung nach der Erstellung der partitionierten Tabelle geändert werden kann, können Sie die Daten neu organisieren, um die Effizienz häufig verwendeter Abfragen zu verbessern, sofern Sie dies nicht bereits bei der ersten Konfiguration des Partitionierungsschemas getan haben.
Wenn Abfragen Aggregatfunktionen wie SUM() und COUNT() beinhalten, können sie problemlos parallel verarbeitet werden. Ein einfaches Beispiel für eine solche Abfrage ist „SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;“. Eine „parallele“ Abfrage bedeutet, dass die Abfrage auf jeder Partition gleichzeitig ausgeführt werden kann und das Endergebnis einfach die Ergebnisse aller Partitionen aggregiert.
(5). Erzielen Sie einen höheren Abfragedurchsatz, indem Sie Datenabfragen auf mehrere Festplatten verteilen.
(1) Eine Tabelle kann nur maximal 1024 Partitionen haben.
In MySQL 5.1 können Partitionsausdrücke nur Ganzzahlen oder Ausdrücke sein, die Ganzzahlen zurückgeben können. Unterstützung für die Partitionierung nicht-ganzzahliger Ausdrücke wird in MySQL 5.5 bereitgestellt.
Wenn Spalten mit Primärschlüssel oder eindeutigem Index im Partitionsfeld enthalten sind, müssen alle Primärschlüsselspalten und eindeutigen Indexspalten enthalten sein. Entweder enthält das Partitionsfeld nicht die Primärschlüssel- und Indexspalten oder es enthält alle Primärschlüssel- und Indexspalten.
(4). Fremdschlüsseleinschränkungen können in partitionierten Tabellen nicht verwendet werden.
(5) Die MySQL-Partitionierung gilt für alle Daten und Indizes in einer Tabelle. Sie können nicht nur die Tabellendaten, aber nicht den Index partitionieren. Sie können auch nicht nur den Index, aber nicht die Tabelle partitionieren Partitionieren Sie die Tabellendaten, nicht jedoch den Index.
mysql> show variables like '%partition%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | have_partitioning | YES | +-------------------+-------+ 1 row in set (0.00 sec)
Der Wert von have_partintioning ist YES, was darauf hinweist, dass Partitionierung unterstützt wird.
(1), RANGE-Partitionierung: Ordnen Sie mehrere Zeilen einer Partition zu, basierend auf Spaltenwerten, die zu einem bestimmten kontinuierlichen Bereich gehören.
(2), LIST-Partitionierung: Ähnlich wie die Partitionierung nach RANGE, der Unterschied besteht darin, dass die LIST-Partitionierung basierend auf dem Spaltenwert ausgewählt wird, der mit einem bestimmten Wert in einem diskreten Wertesatz übereinstimmt.
(3), HASH-Partition: Die Partition, die basierend auf dem Rückgabewert eines benutzerdefinierten Ausdrucks ausgewählt wird, der anhand der Spaltenwerte der in die Tabelle einzufügenden Zeilen berechnet wird. In diese Funktion kann jeder gültige MySQL-Ausdruck einbezogen werden, der einen nicht negativen Ganzzahlwert erzeugt.
(4), KEY-Partitionierung: Ähnlich wie bei der HASH-Partitionierung besteht der Unterschied darin, dass die KEY-Partitionierung nur die Berechnung einer oder mehrerer Spalten unterstützt und der MySQL-Server eine eigene Hash-Funktion bereitstellt. Es müssen eine oder mehrere Spalten mit ganzzahligen Werten vorhanden sein.
Hinweis: In Version MySQL 5.1 erfordern RANGE-, LIST- und HASH-Partitionen, dass der Partitionsschlüssel vom Typ INT sein muss oder den Typ INT über einen Ausdruck zurückgeben muss. Bei der KEY-Partitionierung können neben den Spalten vom Typ BLOB und TEXT auch andere Spaltentypen als Partitionsschlüssel verwendet werden.
Partition basierend auf dem Bereich, der Bereich sollte kontinuierlich, aber nicht überlappend sein, verwenden Sie die Schlüsselwörter PARTITION BY RANGE, VALUES LESS THAN. Wenn Sie das Schlüsselwort COLUMNS nicht verwenden, müssen die RANGE-Klammern ein ganzzahliger Feldname oder eine Funktion sein, die eine bestimmte ganze Zahl zurückgibt.
drop table if exists employees;
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21)
);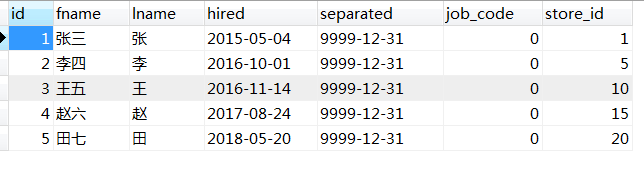
按照这种分区方案,在商店1到5工作的雇员相对应的所有行被保存在分区P0中,商店6到10的雇员保存在P1中,依次类推。注意,每个分区都是按顺序进行定义,从最低到最高。这是PARTITION BY RANGE 语法的要求。
对于包含数据(6,'亢八','亢','2018-06-24',13)的一个新行,可以很容易地确定它将插入到p2分区中。
insert into employees (id,fname,lname,hired,store_id) values(6,'亢八','亢','2018-06-24',13);
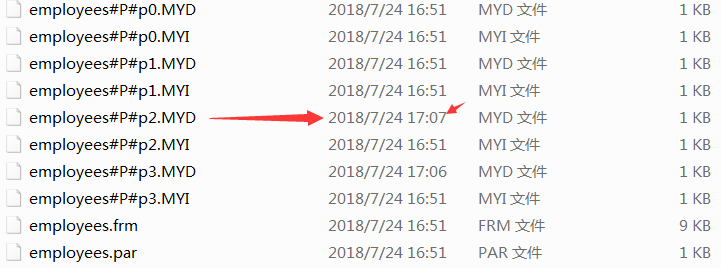
但是如果增加了一个编号为第21的商店(7,'周九','周','2018-07-24',21),将会发生什么呢?在这种方案下,由于没有规则把store_id大于20的商店包含在内,服务器将不知道把该行保存在何处,将会导致错误。
insert into employees (id,fname,lname,hired,store_id) values(7,'周九','周','2018-07-24',21); ERROR 1526 (HY000): Table has no partition for value 21
要避免这种错误,可以通过在CREATE TABLE语句中使用一个“catchall” VALUES LESS THAN子句,该子句提供给所有大于明确指定的最高值的值:
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21),
partition p4 values less than MAXVALUE
);drop table if exists quarterly_report_status; create table quarterly_report_status( report_id int not null, report_status varchar(20) not null, report_updated timestamp not null default current_timestamp on update current_timestamp ) partition by range(unix_timestamp(report_updated))( partition p0 values less than (unix_timestamp('2008-01-01 00:00:00')), partition p1 values less than (unix_timestamp('2008-04-01 00:00:00')), partition p2 values less than (unix_timestamp('2008-07-01 00:00:00')), partition p3 values less than (unix_timestamp('2008-10-01 00:00:00')), partition p4 values less than (unix_timestamp('2009-01-01 00:00:00')), partition p5 values less than (unix_timestamp('2009-04-01 00:00:00')), partition p6 values less than (unix_timestamp('2009-07-01 00:00:00')), partition p7 values less than (unix_timestamp('2009-10-01 00:00:00')), partition p8 values less than (unix_timestamp('2010-01-01 00:00:00')), partition p9 values less than maxvalue );
添加COLUMNS关键字可定义非integer范围及多列范围,不过需要注意COLUMNS括号内只能是列名,不支持函数;多列范围时,多列范围必须呈递增趋势:
drop table if exists member; create table member( firstname varchar(25) not null, lastname varchar(25) not null, username varchar(16) not null, email varchar(35), joined date not null ) partition by range columns(joined)( partition p0 values less than ('1960-01-01'), partition p1 values less than ('1970-01-01'), partition p2 values less than ('1980-01-01'), partition p3 values less than ('1990-01-01'), partition p4 values less than maxvalue )
drop table if exists rc3; create table rc3( a int, b int ) partition by range columns(a,b)( partition p0 values less than (0,10), partition p1 values less than (10,20), partition p2 values less than (20,30), partition p3 values less than (30,40), partition p4 values less than (40,50), partition p5 values less than (maxvalue,maxvalue) )
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 )engine=myisam default charset=utf8 partition by range(year(separated))( partition p0 values less than (1991), partition p1 values less than (1996), partition p2 values less than (2001), partition p4 values less than MAXVALUE );
只需删除分区,就能清除“旧的”数据。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用”alter table staff drop partition p0;”来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如”delete from staff WHERE year(separated) <= 1990;”这样的一个DELETE查询要有效得多。
(2)、想要使用一个包含有日期或时间值,或包含有从一些其他级数开始增长的值的列。
(3)、经常运行直接依赖于用于分割表的列的查询。例如,当执行一个如”select count(*) from staff where year(separated) = 200 group by store_id;”这样的查询时,MySQL可以很迅速地确定只有分区p2需要扫描,这是因为余下的分区不可能包含有符合该WHERE子句的任何记录。
根据具体数值分区,每个分区数值不重叠,使用PARTITION BY LIST、VALUES IN关键字。在不使用COLUMNS关键字的情况下,与Range分区类似,List括号内必须是整数字段名或返回确定整数的函数。
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr”是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。
假定有20个音像店,分布在4个有经销权的地区,如下表所示:
====================
地区 商店ID 号
北区 3, 5, 6, 9, 17
东区 1, 2, 10, 11, 19, 20
4, 12, 13, 14, 18是西区的编号
中心区 7, 8, 15, 16
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by list(store_id)( partition pNorth values in (3,5,6,9,17), partition pEast values in (1,2,10,11,19,20), partition pWest values in (4,12,13,14,18), partition pCentral values in (7,8,15,16) );
这使得在表中增加或删除指定地区的雇员记录变得容易起来。例如,假定西区的所有音像店都卖给了其他公司。那么与在西区音像店工作雇员相关的所有记录(行)可以使用查询“ALTER TABLE staff DROP PARTITION pWest;”来进行删除,它与具有同样作用的DELETE(删除)“DELETE FROM staff WHERE store_id IN (4,12,13,14,18);”比起来,要有效得多。
如果试图插入列值(或分区表达式的返回值)不在分区值列表中的一行时,那么“INSERT”查询将失败并报错。
当插入多条数据出错时,如果表的引擎支持事务(Innodb),则不会插入任何数据;如果不支持事务,则出错前的数据会插入,后面的不会执行。
与Range分区相同,添加COLUMNS关键字可支持非整数和多列。
Hash分区主要用来确保数据在预先确定数目的分区中平均分布,Hash括号内只能是整数列或返回确定整数的函数,实际上就是使用返回的整数对分区数取模。
要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num是一个非负的整数,它表示表将要被分割成分区的数量。
如果没有包括一个PARTITIONS子句,那么分区的数量将默认为1
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by hash(store_id) partitions 4;
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by hash(year(hired)) partitions 4;
Hash分区也存在与传统Hash分表一样的问题,可扩展性差。MySQL也提供了一个类似于一致Hash的分区方法-线性Hash分区,只需要在定义分区时添加LINEAR关键字。
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by linear hash(year(hired)) partitions 4;
线性哈希功能,它与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则,而常规哈希使用的是求哈希函数值的模数。
Key分区与Hash分区很相似,只是Hash函数不同,定义时把Hash关键字替换成Key即可,同样Key分区也有对应与线性Hash的线性Key分区方法。
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by key(store_id) partitions 4;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
另外,当表存在主键或唯一索引时可省略Key括号内的列名,Mysql将按照主键-唯一索引的顺序选择,当找不到唯一索引时报错。
Das obige ist der detaillierte Inhalt vonWas sind die vier Partitionierungsmethoden der MySQL-Tabelle?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen

























