


Andererseits speichert der Blattknoten in einem nicht gruppierten Index den Primärschlüsselwert. Wenn der Primärschlüssel eine lange UUID-Zeichenfolge ist, belegt er einen größeren Speicherplatz (im Vergleich zu int). Die Primärschlüsselwerte, die vom selben Blattknoten gespeichert werden können, werden reduziert, was dazu führen kann, dass der Baum höher wird, was bedeutet, dass die Anzahl der E/As während der Abfrage zunimmt und die Abfrageeffizienz abnimmt. Basierend auf der obigen Analyse versuchen wir, UUID nicht als Primärschlüssel in MySQL zu verwenden. Ohne UUID denken einige Freunde vielleicht: Kann ich den Primärschlüssel zum automatischen Inkrementieren verwenden?
Die automatische Inkrementierung des Primärschlüssels kann offensichtlich die beiden Probleme lösen, die bei der Verwendung der UUID als Primärschlüssel auftreten. Der Primärschlüssel wird automatisch erhöht. Sie müssen ihn nur jedes Mal am Ende des Baums hinzufügen. Das Problem der Seitenaufteilung besteht grundsätzlich nicht Der belegte Speicherplatz ist relativ gering. Für Nicht-Cluster ist die Auswirkung der Indizierung ebenfalls geringer.
Ist die automatische Inkrementierung des Primärschlüssels also die beste Lösung? Gibt es Probleme, die bei der automatischen Erhöhung des Primärschlüssels beachtet werden müssen?
2. Das Problem der automatischen Inkrementierung des Primärschlüssels
Der folgende Inhalt hat eine gemeinsame Prämisse, das heißt, unsere Tabelle verfügt über eine automatische Inkrementierung des Primärschlüssels.Im Allgemeinen gibt es kein Problem mit der automatischen Inkrementierung des Primärschlüssels. Wenn Sie sich jedoch in einer Umgebung mit hoher Parallelität befinden, treten Probleme auf. Am einfachsten ist es, sich das Tail-Hotspot-Problem vorzustellen, das beim gleichzeitigen Einfügen auftritt. Jeder muss diesen Wert abfragen und dann seinen eigenen Primärschlüsselwert berechnen Der Schlüssel wird zu den Hotspot-Daten. Beim gleichzeitigen Einfügen kommt es hier zu einem Sperrwettbewerb.
Um dieses Problem zu lösen, müssen wir den innodb_autoinc_lock_mode auswählen, der zu uns passt.
Wenn wir Daten in die Datentabelle einfügen, gibt es zunächst im Allgemeinen drei verschiedene Formen, die wie folgt lauten:
innodb_autoinc_lock_mode。
首先,我们在向数据表中插入数据的时候,一般来说有三种不同的形式,分别如下:
insert into user(name) values('javaboy') 或者 replace into user(name) values('javaboy') ,这种没有嵌套子查询并且能够确定具体插入多少行的插入叫做 simple insert,不过需要注意的是 INSERT ... ON DUPLICATE KEY UPDATE 不算是 simple insert。
load data 或者 insert into user select ... from ....,这种都是批量插入,叫做 bulk insert,这种批量插入有一个特点就是插入多少条数据在一开始是未知的。
insert into user(id,name) values(null,'javaboy'),(null,'江南一点雨'),这种也是批量插入,但是跟第二种又不太一样,这种里边包含了一些自动生成的值(本案例中的主键自增),并且能够确定一共插入多少行,这种称之为 mixed insert,对于前面第一点提到的 INSERT ... ON DUPLICATE KEY UPDATE 也算是一种 mixed insert。
将数据插入分为这三类,主要是因为在主键自增的时候,锁的处理方案不同,我们继续往下看。
我们可以通过控制 innodb_autoinc_lock_mode 变量的值,来控制在主键自增的时候,MySQL 锁的处理思路。
innodb_autoinc_lock_mode 变量一共有三个不同的取值:
0: 这个表示 traditional,在这种模式下,我们上面提到的三种不同的插入 SQL,对于自增锁的处理方案是一致的,都是在插入 SQL 语句开始的时候,获取到一个表级的 AUTO-INC 锁,然后当插入 SQL 执行完毕之后,再释放掉这把锁,这样做的好处是可以确保在批量插入的时候,自增主键是连续的。
1: 这个表示 consecutive,在这种模式下,对 simple insert(能够确定具体插入行数的,对应上面 1、3 两种情况)做了一些优化,由于 simple insertin Benutzer(name)-Werte('javaboy') einfügen oder in Benutzer(name)-Werte('javaboy') ersetzen, dies ist nicht eingebettet. An Einfügung, die eine verschachtelte Abfrage verwendet und bestimmen kann, wie viele Zeilen eingefügt werden sollen, wird als einfache Einfügung bezeichnet. Es ist jedoch zu beachten, dass INSERT ... ON DUPLICATE KEY UPDATE nicht berücksichtigt wird einfache Einfügung.
Daten laden oder insert into user select ... from ...., das sind Masseneinfügungen, genannt bulk insert, Ein Merkmal dieser Stapeleinfügung besteht darin, dass die Anzahl der einzufügenden Daten zu Beginn unbekannt ist.
insert into user(id,name) Values(null,'javaboy'),(null,'Jiangnan Yidianyu'), dies ist ebenfalls eine Batch-Einfügung, unterscheidet sich jedoch von der Das zweite ist nicht dasselbe. Es enthält einige automatisch generierte Werte (in diesem Fall wird der Primärschlüssel automatisch erhöht) und kann bestimmen, wie viele Zeilen insgesamt eingefügt werden. code>. Für den vorherigen Teil wird der zuvor erwähnte INSERT ... ON DUPLICATE KEY UPDATE auch als gemischte Einfügung betrachtet. 🎜🎜einfaches Einfügen vorgenommen (wodurch die spezifische Anzahl der eingefügten Zeilen bestimmt werden kann, entsprechend den beiden oben genannten Situationen 1 und 3). , weil simple insert Es ist einfach zu berechnen, wie viele Zeilen eingefügt werden müssen, sodass mehrere aufeinanderfolgende Werte gleichzeitig generiert und in den entsprechenden Einfügungs-SQL-Anweisungen verwendet werden können. Die INC-Sperre kann im Voraus freigegeben und die Anzahl der Sperren reduziert werden, um die Effizienz des gleichzeitigen Einfügens zu verbessern. 🎜🎜🎜🎜2: Dies bedeutet, dass es in diesem Fall keine AUTO-INC-Sperre gibt. Beim Einfügen in Stapeln kann es zu dem Problem kommen, dass der Primärschlüssel inkrementiert wird. 🎜Wie Sie der obigen Einführung entnehmen können, handelt es sich tatsächlich um den dritten Typ, dh wenn der Wert von innodb_autoinc_lock_mode 2 ist, ist die Parallelitätseffizienz am stärksten. Sollten wir also innodb_autoinc_lock_mode = 2 festlegen?
Es kommt auf die Situation an.
Bruder Song hat zuvor einen Artikel geschrieben, um seinen Freunden die drei Formate von MySQL-Binlog-Protokolldateien vorzustellen:
Zeile: Was im Binlog aufgezeichnet wird, ist der spezifische Wert und nicht das ursprüngliche SQL. Um ein einfaches Beispiel zu nennen Angenommen, ein Feld in der Tabelle ist UUID und die vom Benutzer ausgeführte SQL wird insert into user(username,uuid) Values('javaboy',uuid()), dann wird die SQL schließlich aufgezeichnet Das Binlog ist insert into user(username,uuid) Values('javaboy',‘0212cfa0-de06-11ed-a026-0242ac110004’). insert into user(username,uuid) values('javaboy',uuid()),那么最终记录到 binlog 中的 SQL 是 insert into user(username,uuid) values('javaboy',‘0212cfa0-de06-11ed-a026-0242ac110004’)。
statement:binlog 中记录的就是原始的 SQL 了,以 row 中的为例,最终 binlog 中记录的就是 insert into user(username,uuid) values('javaboy',uuid())。
mixed:在这种模式下,MySQL 会根据具体的 SQL 语句来决定日志的形式,也就是在 statement 和 row 之间选择一种。
对于这三种不同的模式,很明显,在主从复制的时候,statement 模式可能会导致主从数据不一致,所以现在 MySQL 默认的 binlog 格式都是 row。
回到我们的问题:
如果 binlog 格式是 row,那么我们就可以设置 innodb_autoinc_lock_mode 的值为 2,这样就能尽最大程度保证数据并发插入的能力,同时不会发生主从数据不一致的问题。
如果 binlog 格式是 statement,那么我们最好设置 innodb_autoinc_lock_mode 的值为 1,这样对于 simple insert 的并发插入能力进行了提高,批量插入还是先获取 AUTO-INC 锁,等插入成功之后再释放,这样也能避免主从数据不一致,保证数据复制的安全性。
以上两点主要是针对 InnoDB 存储引擎,如果是 MyISAM 存储引擎,都是先获取 AUTO-INC 锁,插入完成再释放,相当于 innodb_autoinc_lock_mode 变量的取值对 MyISAM 不生效。
接下来我们来通过一个简单的 SQL 来和小伙伴们演示一下 innodb_autoinc_lock_mode 不同取值对应不同结果的情况。
我们可以使用以下 SQL 查询来查看当前 innodb_autoinc_lock_mode 的设置:

可以看到,我使用的 8.0.32 这个版本目前默认值是 2。
我先把它改成 0,修改方式就是在 /etc/my.cnf 文件中添加一行 innodb_autoinc_lock_mode=0:
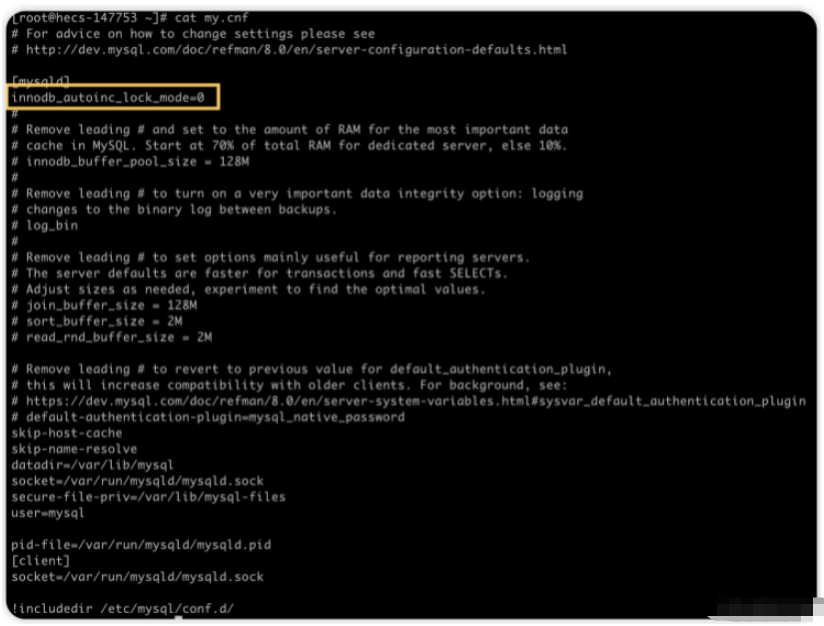
改完之后再重启查看,如下:

可以看到,现在就已经改过来了。
现在假设我有如下表:
CREATE TABLE `user` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
这个自增是从 100 开始计的,现在假设我有如下插入 SQL:
insert into user(id,username) values(1,'javaboy'),(null,'江南一点雨'),(3,'www.javaboy.org'),(null,'lisi');
插入完成之后,我们来看查询结果:

按照我们前文的介绍,这个情况应该是可以解释的通的,我这里不再赘述。
接下来,我把 innodb_autoinc_lock_mode 取值改为 1,如下:

还是上面相同的 SQL,我们再执行一遍。执行完成之后结果也和上文相同。
但是!!!**当上面的 SQL 执行完毕之后,如果我们还想再插入数据,并且新插入的 ID 不指定值,则我们发现自动生成的 ID 值为 104。**这就是因为我们设置了 innodb_autoinc_lock_mode=1,此时,执行 simple insert
insert into user(username,uuid) Values('javaboy'). ,uuid()) . 🎜🎜🎜🎜gemischt: In diesem Modus bestimmt MySQL das Protokollformat basierend auf der spezifischen SQL-Anweisung, das heißt, es wählt eines zwischen Anweisung und Zeile. 🎜🎜🎜🎜Bei diesen drei verschiedenen Modi ist es offensichtlich, dass der Anweisungsmodus zu Inkonsistenzen in den Master-Slave-Daten während der Master-Slave-Replikation führen kann. Daher ist MySQLs Standard-Binlog-Format jetzt Zeile. 🎜🎜Zurück zu unserer Frage: 🎜🎜🎜🎜Wenn das Binlog-Format eine Zeile ist, können wir den Wert von innodb_autoinc_lock_mode auf 2 setzen, um die Fähigkeit zum gleichzeitigen Einfügen von Daten weitestgehend sicherzustellen und gleichzeitig Es tritt kein Problem mit der Master-Slave-Dateninkonsistenz auf. 🎜🎜🎜🎜Wenn das Binlog-Format eine Anweisung ist, sollten wir den Wert von innodb_autoinc_lock_mode besser auf 1 setzen, damit die gleichzeitige Einfügungsfähigkeit von simple insert verbessert wird. Für die Stapeleinfügung ist es besser Um zuerst die AUTO-INC-Sperre zu erhalten, warten Sie, bis die Einfügung erfolgreich ist, bevor Sie sie freigeben. Dies kann auch Inkonsistenzen zwischen Master und Slave vermeiden und die Sicherheit der Datenreplikation gewährleisten. 🎜🎜🎜🎜Die beiden oben genannten Punkte gelten hauptsächlich für die InnoDB-Speicher-Engine. Wenn es sich um eine MyISAM-Speicher-Engine handelt, wird die AUTO-INC-Sperre zuerst abgerufen und nach Abschluss des Einfügens freigegeben Die Variable innodb_autoinc_lock_mode hat auf MyISAM keine Wirkung. 🎜🎜🎜🎜🎜Nach Abschluss der Änderungen starten Sie neu Ansicht wie folgt: 🎜🎜🎜🎜Gemäß unserem vorherigen Einführung, dies Die Situation sollte erklärbar sein, daher werde ich hier nicht auf Details eingehen. 🎜🎜Als nächstes habe ich den Wert von innodb_autoinc_lock_mode wie folgt auf 1 geändert: 🎜🎜
Das obige ist der detaillierte Inhalt vonSo lösen Sie die Fallstricke, die bei der automatischen Inkrementierung des MySQL-Primärschlüssels auftreten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



