


Am 30. November startete OpenAI einen KI-Chatbot namens ChatGPT, der von der Öffentlichkeit kostenlos getestet werden kann. Er wurde innerhalb weniger Tage im gesamten Netzwerk populär.
Nach mehreren Werbeaktionen in Schlagzeilen und öffentlichen Accounts zu urteilen, kann es nicht nur Code schreiben und Fehler prüfen, sondern auch Romane und Spielplanung schreiben, einschließlich Bewerbungen für Schulen usw. schreiben. Es scheint zu allem fähig zu sein.
Im Geiste des wissenschaftlichen (guten) Lernens (seltsam) habe ich mir etwas Zeit genommen, ChatGPT zu testen und zu verifizieren und **herausgefunden, warum ChatGPT so „stark“ ist**.
Da der Autor KI nicht professionell studiert hat und nur über begrenzte Energie verfügt, wird es in kurzer Zeit keine ausführlicheren technischen Kapitel wie AI-003 geben.
In diesem Artikel werden viele Fachbegriffe vorkommen, und ich werde versuchen, die Schwierigkeit, sie zu verstehen, zu verringern.
Da ich kein KI-Experte bin, weisen Sie bitte gleichzeitig auf etwaige Fehler oder Auslassungen hin.
Danksagungen: Ich bin den beiden Experten X und Z für die Durchsicht des Manuskripts sehr dankbar, insbesondere X für seine Professionalität
Chat Es gibt zwei Wörter in GPT, eines ist Chat Sie können ein Gespräch führen. Ein anderes Wort ist GPT. Der vollständige Name von
GPT lautet Generative Pre-Trained Transformer (generatives Pre-Training-Transformer-Modell).
Sie können darin insgesamt 3 Wörter sehen: Generativ, Vortrainiert und Transformator.
Einige Leser bemerken möglicherweise, dass ich den Transformer oben nicht ins Chinesische übersetzt habe.
Da es sich bei „Transformer“ um einen technischen Begriff handelt, handelt es sich, wenn man ihn genau übersetzt, um einen Transformator. Aber es ist leicht, die ursprüngliche Bedeutung zu verlieren, daher ist es besser, sie nicht zu übersetzen.
Ich werde in Kapitel 3 unten mehr über Transformer erklären.
Die Entwicklungsgeschichte von GPT von der Gründung bis zur Gegenwart ist wie folgt:
Im Juni 2017 veröffentlichte Google das Papier „Attention is all you need“ und schlug damit erstmals das Transformer-Modell vor , die zur Grundlage für die Entwicklung von GPT Base wurde. Papieradresse: https://arxiv.org/abs/1706.03762
Im Juni 2018 veröffentlichte OpenAI das Papier „Improving Language Understanding by Generative Pre-Training“ (Verbesserung des Sprachverständnisses durch generatives Pre-Training) und schlug erstmals GPT vor Zeitmodell (generatives Vortraining). Papieradresse: https://paperswithcode.com/method/gpt.
Im Februar 2019 veröffentlichte OpenAI das Papier „Language Models are Unsupervised Multitask Learners“ (das Sprachmodell sollte ein unbeaufsichtigter Multitask-Lerner sein) und schlug das GPT-2-Modell vor. Papieradresse: https://paperswithcode.com/method/gpt-2
Im Mai 2020 veröffentlichte OpenAI das Papier „Language Models are Few-Shot Learners“ (Sprachmodell sollte ein Few-Shot-Lerner sein) und schlug GPT vor -3-Modell. Papieradresse: https://paperswithcode.com/method/gpt-3
Ende Februar 2022 veröffentlichte OpenAI das Papier „Trainieren Sie Sprachmodelle, um Anweisungen mit menschlichem Feedback zu befolgen“ (unter Verwendung des Anweisungsflusses mit menschlichem Feedback). ) (zum Trainieren von Sprachmodellen) kündigte das Instruction GPT-Modell an: https://arxiv.org/abs/2203.02155
Am 30. November 2022 stellte OpenAI das ChatGPT-Modell zur Verfügung, siehe: AI -001-Was kann ChatGPT, der beliebte Chatbot im Internet? 3. GPTs T-Transformer (2017)
Aber es gibt eine das wichtigste und grundlegendste Schlüsselwort in GPT (Generative Pre-Training Transformer)
(Hinweis: Der Transformer von GPT ist im Vergleich zum ursprünglichen Transformer in Googles Artikel vereinfacht, nur der Decoder-Teil bleibt erhalten, siehe Abschnitt 4.3 dieses Artikels)
3.1 . Ist es wichtiger, gut zu sein oder ein guter Mensch zu sein?
3.2. Entschuldigung, du bist ein guter Mensch
Erweiterung, was ist mit „Es tut mir leid, du bist ein guter Mensch“
Der Fokus der Semantik ist. Aber die Prämisse der Semantik ist immer noch menschlich
3.3 Zurück zum Thema „Transfomer in zehn Minuten verstehen“ (https://zhuanlan.zhihu.com/p/82312421) Sie können es lesen.
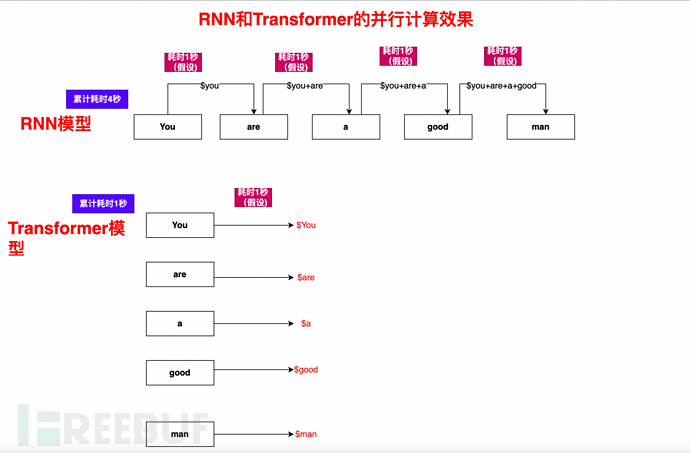
Das Grundprinzip von RNN besteht darin, jeden Wortvektor von links nach rechts zu durchsuchen (z. B. ist dies ein Hund), die Daten jedes Wortes beizubehalten und jedes nachfolgende Wort hängt vom vorherigen Wort ab.
Das Hauptproblem von RNN: Es muss sequentiell und sequentiell berechnet werden. Sie können sich vorstellen, dass ein Buch oder ein Artikel eine große Anzahl von Wörtern enthält, diese jedoch aufgrund der Sequenzabhängigkeit nicht parallelisiert werden können, sodass die Effizienz sehr gering ist.
Es ist möglicherweise nicht für jeden leicht zu verstehen (vereinfachtes Verständnis, das möglicherweise geringfügig von der tatsächlichen Situation abweicht):
In der RNN-Schleife der Satz Du bist ein guter Mann. Wie berechnet man das?
1), You und You are a good man, berechnen Sie und erhalten Sie die Ergebnismenge $You
2), basierend auf $You, und verwenden Sie dann Are und You sind ein guter Mann, berechnen $Are
3), basierend auf $You, $Are, berechnen Sie weiterhin $a
4) und so weiter, berechnen Sie $ ist, $gut, $mann, und schließen Sie schließlich die vollständige Berechnung aller Elemente von „Du bist ein guter Mann“ ab
Wie Sie sehen können, ist der Berechnungsprozess eine nach der anderen, eine sequentielle Berechnung, eine einzige Pipeline und der folgende Prozess hängen vom vorherigen Prozess ab und sind daher sehr langsam. Im Juni veröffentlichte Google das Papier „Aufmerksamkeit ist alles, was Sie brauchen“ und schlug erstmals das Transformer-Modell vor, das zur Grundlage für die Entwicklung wurde von GPT. Adresse des Papiers: https://arxiv.org/abs/1706.03762
Sie können anhand des Titels „Attention is all you need“ erkennen, dass Transfomer tatsächlich „All in Attention“ befürwortet. Was ist also Aufmerksamkeit?
Im Papier „Aufmerksamkeit ist alles, was Sie brauchen“ können Sie die Definition wie folgt sehen:
Selbstaufmerksamkeit, manchmal auch interne Aufmerksamkeit genannt, ist eine Aufmerksamkeit Mechanismus, der verschiedene Positionen einer einzelnen Sequenz zuordnet, um eine Darstellung der Sequenz zu berechnen. Selbstaufmerksamkeit wurde bei einer Vielzahl von Aufgaben erfolgreich eingesetzt, beispielsweise beim Leseverständnis, bei der Zusammenfassung von Zusammenfassungen, beim Einbeziehen von Diskursen und beim Erlernen der aufgabenunabhängigen Satzdarstellung. 🎜#Einfaches Verständnis besteht darin, dass die Korrelation zwischen Wörtern durch den Vektor der Aufmerksamkeit beschrieben wird. Zum Beispiel: „Du bist ein guter Mensch“ (Du bist ein guter Mensch) a Im Satz „guter Mann“, berechnet durch den Aufmerksamkeitsmechanismus, ist die Aufmerksamkeitskorrelationswahrscheinlichkeit zwischen Ihnen und Ihnen (Selbst) am höchsten (0,7, 70 %). Schließlich sind Sie (Sie) zuerst Sie (Sie). Also Du, Dein Aufmerksamkeitsvektor beträgt 0,7Der Aufmerksamkeitsvektor von Dir und dem Menschen (Person) hängt zweitens zusammen (0,5, 50 %), Du (Du) bist eine Person (Mann), also Du ,Mannes Der Aufmerksamkeitsvektor beträgt 0,5Die Aufmerksamkeitskorrelation zwischen Ihnen und dem Guten (Gut) beträgt wiederum (0,4, 40 %). Auf der Grundlage des Menschen sind Sie immer noch ein guter (guter) Mensch . Der Aufmerksamkeitsvektorwert von You,good beträgt also 0,4
You,areDer Vektorwert beträgt 0,3; der Vektorwert von You,a beträgt 0,2. Die endgültige Liste der Aufmerksamkeitsvektoren für Sie lautet also [0,7, 0,3, 0,2, 0,4, 0,5] (nur Beispiele in diesem Artikel).
Die endgültige Liste der Aufmerksamkeitsvektoren für Sie lautet also [0,7, 0,3, 0,2, 0,4, 0,5] (nur Beispiele in diesem Artikel).
#🎜🎜 #Nach dem Aufkommen von Transformer ersetzte es schnell eine Reihe von Varianten des rekurrenten neuronalen Netzwerks RNN und wurde zur Grundlage der Mainstream-Modellarchitektur. 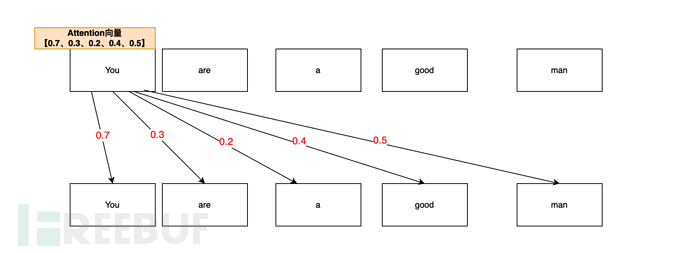
 Dieses Haupthindernis ist: in der Vergangenheit Schulung, wenn wir wollen Um ein Deep-Learning-Modell zu trainieren, müssen wir große beschriftete Datensätze für das Training verwenden. Diese Datensätze erfordern eine manuelle Beschriftung, was äußerst kostspielig ist.
Dieses Haupthindernis ist: in der Vergangenheit Schulung, wenn wir wollen Um ein Deep-Learning-Modell zu trainieren, müssen wir große beschriftete Datensätze für das Training verwenden. Diese Datensätze erfordern eine manuelle Beschriftung, was äußerst kostspielig ist.
Zum Beispiel erfordert maschinelles Lernen eine große Menge an Lehrmaterialien und eine große Anzahl von Eingabe- und Ausgabebeispielen, damit die Maschine lernen und trainieren kann. Dieses Lehrmaterial muss maßgeschneidert sein und die Nachfrage ist riesig. 


Auf diese Weise sind viele vorgefertigte Artikel, Webseiten, Zhihu Q&A, Baidu Zhizhi usw. natürliche annotierte Datensätze (ein Wort, super sparsam).
3.5.2. Wandeln Sie sequentielle Berechnungen in parallele Berechnungen um, wodurch die Trainingszeit erheblich verkürzt wird.
Neben der manuellen Annotation besteht der in Abschnitt 3.3.1 erwähnte Hauptfehler von RNN im Problem sequentieller Berechnungen und einer einzelnen Pipeline.
Der Selbstaufmerksamkeitsmechanismus ermöglicht in Kombination mit dem Maskenmechanismus und der Algorithmusoptimierung die parallele Berechnung eines Artikels, Satzes und Absatzes.
Nehmen wir „Sie sind ein guter Mann“ als Beispiel. Sie können sehen, wie schnell der Transformer sein kann:


Als nächstes ist es Zeit für den Vorgänger von ChatGPT – GPT(1).
Im Juni 2018 veröffentlichte OpenAI das Papier „Improving Language Understanding by Generative Pre-Training“ (Verbesserung des Sprachverständnisses durch generatives Pre-Training), in dem erstmals das GPT-Modell (Generative Pre-Training) vorgeschlagen wurde. Papieradresse: https://paperswithcode.com/method/gpt.
Das GPT-Modell basiert auf der Prämisse, dass Transformer sequentielle Korrelationen und Abhängigkeiten eliminiert und einen konstruktiven Vorschlag vorschlägt.
Bestehen Sie zunächst eine große Menge unbeaufsichtigter Vorschulungen.
Hinweis: Unbeaufsichtigt bezieht sich auf Vorschulungen, die kein menschliches Eingreifen oder gekennzeichnete Datensätze erfordern (es sind keine Lehrmaterialien und Lehrer erforderlich).
Verwenden Sie dann eine kleine überwachte Feinabstimmung, um sein Verständnisvermögen zu korrigieren.

4.1.1. Zum Beispiel
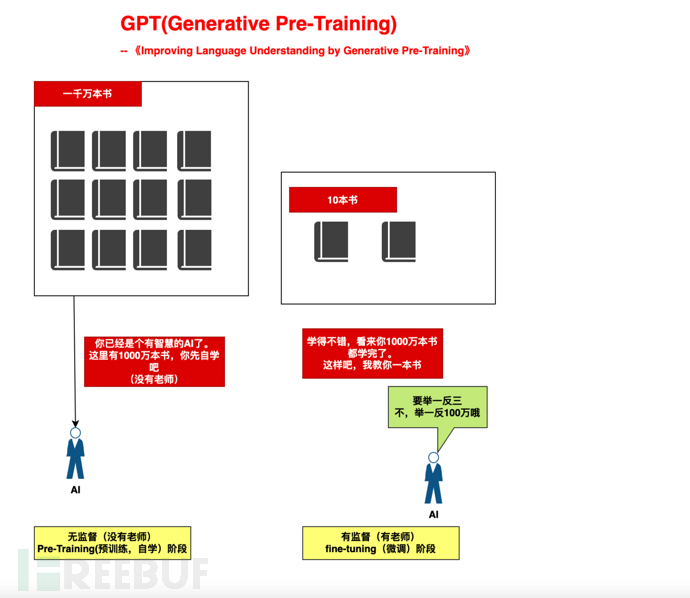
Zum Beispiel trainieren wir ein Kind in zwei Phasen:
1), groß angelegte Selbstlernphase (Selbststudium von 10 Millionen Büchern, Nr Lehrer): Stellen Sie der KI ausreichend Rechenleistung zur Verfügung und lassen Sie sie basierend auf dem Aufmerksamkeitsmechanismus selbst lernen.
2), Kleine Anleitungsphase (Unterricht von 10 Büchern): Ziehen Sie auf der Grundlage von 10 Büchern Schlussfolgerungen zu „drei“

4.1.2. Beschreibung der Eröffnung des Papiers
Die sogenannte klare Bedeutung. In der ersten Einführung können Sie auch die Beschreibung des überwachten Lernens und der manuellen Annotation von Daten im GPT-Modell sehen.

Beim maschinellen Lernen gibt es zwei Unterschiede: diskriminatives Modell und generatives Modell.
GPT (Generative Pre-Training) verwendet, wie der Name schon sagt, ein generatives Modell.
Generative Modelle eignen sich besser für das Big-Data-Lernen als diskriminierende Modelle, die sich besser für genaue Stichproben (manuell gekennzeichnete gültige Datensätze) eignen. Um das Pre-Training besser umzusetzen, wäre das generative Modell geeigneter.
Hinweis: Der Schwerpunkt dieses Abschnitts liegt auf dem obigen Satz (besser geeignet für das Big-Data-Lernen). Wenn Sie das Verständnis für kompliziert halten, lesen Sie den Rest dieses Abschnitts nicht.
Im Wiki-Material zum generativen Modell (https://en.wikisensitivity.org/wiki/Generative_model) wird das folgende Beispiel gegeben, um den Unterschied zwischen den beiden zu veranschaulichen:

Es ist möglicherweise nicht einfach, nur hinzusehen Zum obigen Verständnis finden Sie hier eine ergänzende Erklärung.
Das Obige bedeutet, vorausgesetzt, es gibt 4 Proben:
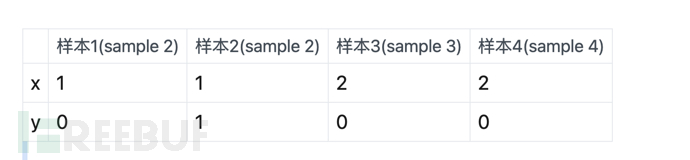
Dann besteht das Merkmal des generativen Modells darin, dass die Wahrscheinlichkeit nicht gruppiert ist (berechnet die Wahrscheinlichkeit innerhalb der Stichprobe und dividiert sie durch die Summe der Stichproben). In der obigen Tabelle wird beispielsweise festgestellt, dass es insgesamt gibt 1 x = 1 und y = 0, daher wird davon ausgegangen, dass x = 1 ist und die Wahrscheinlichkeit von y = 0 1/4 beträgt (die Gesamtzahl der Stichproben beträgt 4).
In ähnlicher Weise gibt es insgesamt 2 x=2, y=0, dann beträgt die Wahrscheinlichkeit von x=2, y=0 2/4.

Die Merkmale des diskriminierenden Modells sind* *Wahrscheinlichkeitsgruppierung Berechnung (Wahrscheinlichkeit innerhalb der Gruppe berechnen und durch die Summe innerhalb der Gruppe dividieren)**. Nehmen wir die obige Tabelle als Beispiel: Es gibt insgesamt 1 Stichprobe für x = 1 und y = 0 und insgesamt 2 Stichproben für die Gruppe von x = 1, sodass die Wahrscheinlichkeit 1/2 beträgt.
Ebenso gibt es insgesamt 2 x=2, y=0. Und gleichzeitig gibt es 2 Stichproben in der Gruppe mit x = 2, dann ist die Wahrscheinlichkeit von x = 2, y = 0 2/2 = 1 (dh 100 %).

Das Folgende ist die Modellbeschreibung eines GPT-trainierten 12-Schicht-Decoder-Only-Decoders (nur Decoder, kein Encoder), wodurch das Modell einfacher wird.
Hinweis 1: Der ursprüngliche Transformer des Google-Artikels „Attention is all you need“ enthält zwei Teile: Encoder und Decoder. Der erstere (Encoder) entspricht der Übersetzung und der letztere (Decoder) entspricht der Generierung.
Hinweis 2: Google hat ein BERT-Modell (Bidirektionale Encoder-Repräsentationen von Transformatoren, Bidirektionale Encoder-Repräsentationen von Transformatoren) mit Encoder als Kern erstellt. Das bidirektionale Innere bedeutet, dass BERT sowohl den oberen als auch den unteren Kontext verwendet, um Wörter vorherzusagen, sodass BERT besser in der Lage ist, Aufgaben zum Verstehen natürlicher Sprache (NLU) zu bewältigen.
Hinweis 3: Der Hauptpunkt dieses Abschnitts ist, dass GPT auf Transformer basiert, aber im Vergleich zu Transformer ist das Modell vereinfacht, der Encoder wurde entfernt und nur der Decoder bleibt erhalten. Gleichzeitig befürwortet GPT im Vergleich zur Kontextvorhersage von BERT (zweiseitig) die Verwendung nur des Kontexts des Wortes zur Vorhersage des Wortes (einseitig), wodurch das Modell einfacher, schneller zu berechnen und besser für die extreme Generierung geeignet ist. und deshalb ist GPT besser in der Verarbeitung Der Natural Language Generation Task (NLG) ist das, was wir in AI-001 entdeckt haben – was ChatGPT, der beliebte Chatbot im Internet, kann. ChatGPT ist sehr gut darin, „Aufsätze“ zu schreiben und Lügen zu erfinden . Nachdem Sie diesen Absatz verstanden haben, müssen Sie den Rest dieses Abschnitts nicht mehr lesen.
Anmerkung 4: Aus der Perspektive der Simulation von Menschen ähnelt der Mechanismus von GPT eher dem von echten Menschen. Weil der Mensch auch das Folgende (das heißt das Folgende) auf der Grundlage des oben Gesagten (was zuvor gesagt wurde) ableitet. Der Mensch kann die vorherigen Worte nicht auf der Grundlage dessen, was später gesagt wurde, anpassen Auch wenn sie „Falsch“ sagen, verletzen schlechte Worte die Herzen der Menschen und können nur auf der Grundlage der gesprochenen Worte (oben) behoben und erklärt werden.

4.3.1. Vergleich von Architekturdiagrammen
Die folgende Abbildung zeigt den Vergleich zwischen der Transformer-Modellarchitektur und der GPT-Modellarchitektur (aus den Artikeln „Attention is all you need“ und „Improving Language Understanding by“) Generatives Pre-Training" bzw. )
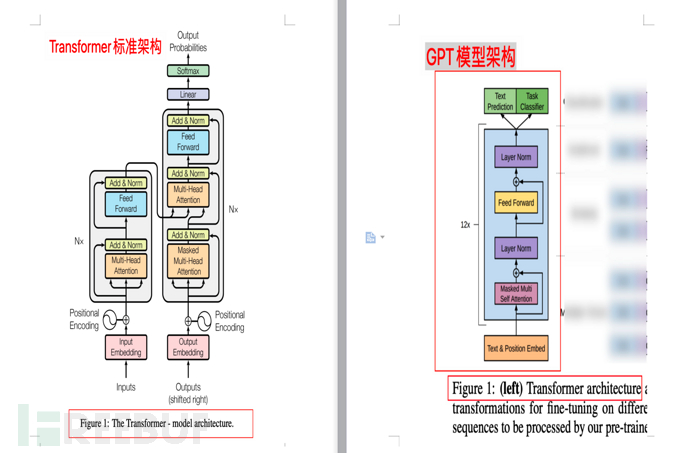
Wie bereits erwähnt, eignet sich das generative Modell besser für das Pre-Training großer Datensätze. Wie groß ist also der Datensatz, den GPT verwendet?
Wie in dem Artikel erwähnt, wird ein Datensatz namens BooksCorpus verwendet, der mehr als 7.000 unveröffentlichte Bücher enthält. 5, GPT-2 (Februar 2019) Papieradresse: https://paperswithcode.com/method/gpt-2
5.1. Kernänderungen des GPT-2-Modells im Vergleich zu GPT-1

Warum ist GPT-2 so angepasst? Der Beschreibung des Papiers nach zu urteilen, soll versucht werden, das Nullschuss-Lernproblem (Zero-Shot-Lernproblem)** zu lösen.
Was ist das Problem mit Zero-Shot (Zero-Shot-Lernen)? Es kann einfach als Denkfähigkeit verstanden werden. Dies bedeutet, dass die KI, wenn sie mit unbekannten Dingen konfrontiert wird, diese automatisch erkennen kann, das heißt, sie verfügt über die Fähigkeit, zu argumentieren.
Zum Beispiel haben wir den Kindern vor dem Zoobesuch erklärt, dass ein pferdeähnliches Tier, das wie ein Panda schwarz und weiß ist und schwarz-weiße Streifen hat, ein Zebra ist. Anhand dieses Tipps können die Kinder das richtig finden Zebra.
Wenn Sie im traditionellen ML ein Modell trainieren möchten, benötigen Sie einen speziellen annotierten Datensatz, um eine spezielle KI zu trainieren.
Um beispielsweise einen Roboter zu trainieren, der Hundebilder erkennen kann, benötigen Sie 1 Million Bilder mit der Beschriftung „Hunde“. Nach dem Training kann die KI Hunde erkennen. Bei dieser KI handelt es sich um eine dedizierte KI, auch Einzelaufgabe genannt.
Multitasking Multitasking bedeutet nicht, eine dedizierte KI zu trainieren, sondern jede Aufgabe zu erledigen, nachdem riesige Datenmengen zugeführt wurden.
Der Datensatz ist auf 8 Millionen Webseiten und eine Größe von 40 GB angewachsen.

Das Modell selbst erreicht ebenfalls maximal 1,5 Milliarden Parameter und der Transformer-Stack erreicht 48 Schichten. Eine einfache Analogie ist wie die Simulation von 1,5 Milliarden menschlichen Neuronen (nur ein Beispiel, nicht völlig gleichwertig).

Im Mai 2020 veröffentlichte OpenAI das Papier „Language Models are Few-Shot Learners“ (Sprachmodell sollte ein Few-Shot-Lerner sein) und schlug GPT-3 vor Modell. Papieradresse: https://paperswithcode.com/method/gpt-3
1 Die Übersetzung und die Probleme von GPT-3 zeigen sich stark Leistung beim Antworten und Lückentext, während Sie gleichzeitig in der Lage sind, Wörter zu entziffern, neue Wörter in Sätzen zu verwenden oder dreistellige Berechnungen durchzuführen.
2. GPT-3 kann Muster von Nachrichtenartikeln generieren, die Menschen nicht mehr unterscheiden können.
Wie unten gezeigt:
 6.2. Die Kernänderungen von GPT-3 im Vergleich zu GPT-2
6.2. Die Kernänderungen von GPT-3 im Vergleich zu GPT-2
Um es ganz klar auszudrücken: Zero-Shot (Zero-Shot-Lernen) ist unzuverlässig.
 Darüber hinaus werden während des Trainingsprozesses One-Shot-Lernen (Einzelproben-Lernen), Few-Shot-Lernen (eine kleine Anzahl von Proben-Lernen) und künstliche Feinabstimmungsmethoden verglichen .
Darüber hinaus werden während des Trainingsprozesses One-Shot-Lernen (Einzelproben-Lernen), Few-Shot-Lernen (eine kleine Anzahl von Proben-Lernen) und künstliche Feinabstimmungsmethoden verglichen .
Schließlich ist in den meisten Fällen die Gesamtleistung von Wenigen Aufnahmen (einer kleinen Anzahl von Proben) im unbeaufsichtigten Modus optimal, aber etwas schwächer als im Feinabstimmungsmodus.
Aus den Tabellen und Grafiken des folgenden Artikels ist auch ersichtlich, dass die Gesamtleistung von Wenigschüssen nur schwächer ist als die Feinabstimmung.
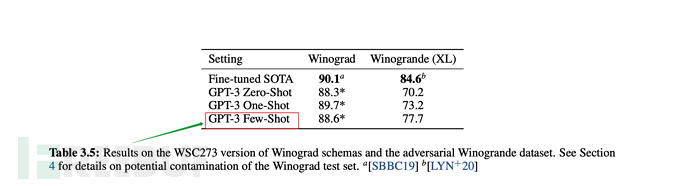
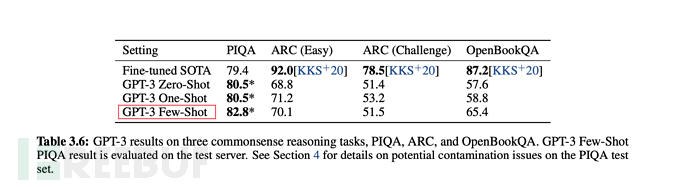
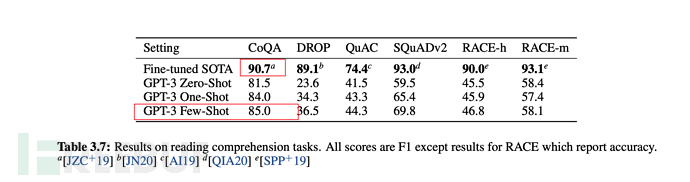
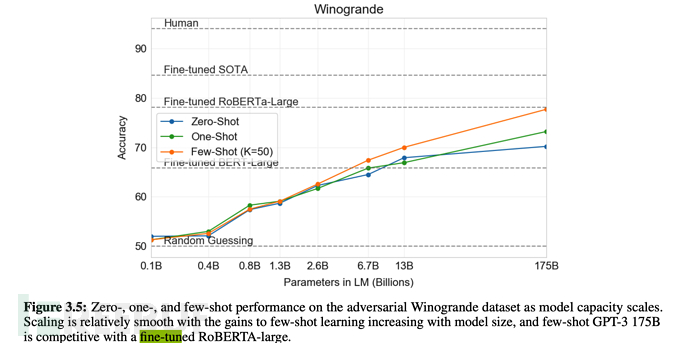 6.3, GPT-3-Trainingsskala
6.3, GPT-3-Trainingsskala
 In Bezug auf die Modellparameter ist sie von 1,5 Milliarden in GPT-2 auf 175 Milliarden gestiegen, was einer Steigerung um mehr als das 110-fache entspricht; auch die Transformer-Schicht ist von 48 auf 96 gestiegen.
In Bezug auf die Modellparameter ist sie von 1,5 Milliarden in GPT-2 auf 175 Milliarden gestiegen, was einer Steigerung um mehr als das 110-fache entspricht; auch die Transformer-Schicht ist von 48 auf 96 gestiegen.
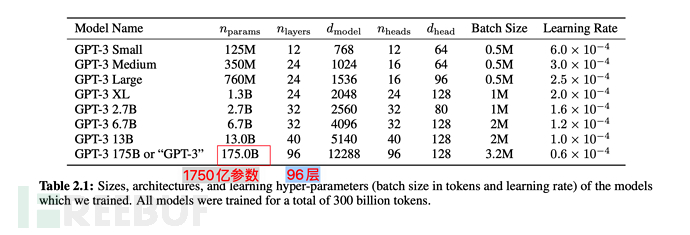 7.1. Kernänderungen von Instruction GPT im Vergleich zu GPT-3
7.1. Kernänderungen von Instruction GPT im Vergleich zu GPT-3
Wie bereits erwähnt, befürwortet GPT-3 das Lernen mit wenigen Schüssen und besteht gleichzeitig auf unbeaufsichtigtem Lernen.
Was sollen wir also tun? Zur Feinabstimmung zurückkehren, um die Feinabstimmung zu überwachen? Anscheinend nicht.
OpenAI gibt eine neue Antwort: Trainieren Sie basierend auf GPT-3 ein Belohnungsmodell (Belohnungsmodell) basierend auf manuellem Feedback (RHLF) und verwenden Sie dann das Belohnungsmodell (Belohnungsmodell, RM), um das Lernmodell zu trainieren.
Oh mein Gott, ich bin so jung. . Es ist an der Zeit, Maschinen (KI) zu nutzen, um Maschinen (KI) zu trainieren. .
7.2. Die Kernschulungsschritte der GPT-Anleitung Die GPT-Anleitung besteht insgesamt aus 3 Schritten:
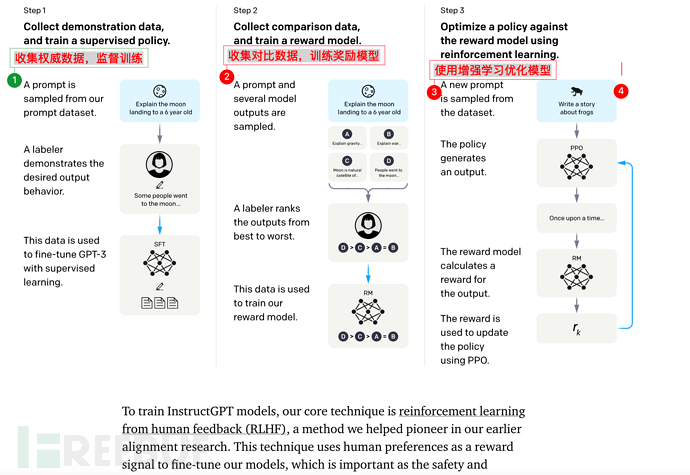 3) und schließlich SFT durch verstärkendes Lernen optimieren
3) und schließlich SFT durch verstärkendes Lernen optimieren
Es ist erwähnenswert, dass die Schritte 2 und 3 durchaus möglich sind. Iteration und Schleife werden durchgeführt mehrfach. 
 Die grundlegende Datenskala ist die gleiche wie bei GPT-3 (siehe Abschnitt 6.3), es wurden jedoch 3 Schritte hinzugefügt (überwachte Feinabstimmung von SFT, Belohnungsmodelltraining, Belohnungsmodell usw.). verbesserte Lernoptimierung (RPO).
Die grundlegende Datenskala ist die gleiche wie bei GPT-3 (siehe Abschnitt 6.3), es wurden jedoch 3 Schritte hinzugefügt (überwachte Feinabstimmung von SFT, Belohnungsmodelltraining, Belohnungsmodell usw.). verbesserte Lernoptimierung (RPO).
Der Labeler im Bild unten bezieht sich auf den **Labeler**, der von OpenAI verwendet wird oder mit OpenAI zusammenhängt.
Nach dem Start von ChatGPT soll es dieses Mal mehr als eine Million Benutzer geben, und jeder von uns ist sein Kunde. Daher ist es absehbar, dass die Kundengröße bei der Veröffentlichung von GPT-4 in der Zukunft steigen wird mindestens eine Million betragen.
8. ChatGPT (November 2022) Am 30. November 2022 führte OpenAI das ChatGPT-Modell ein und stellte Testversionen bereit, die im gesamten Netzwerk beliebt wurden.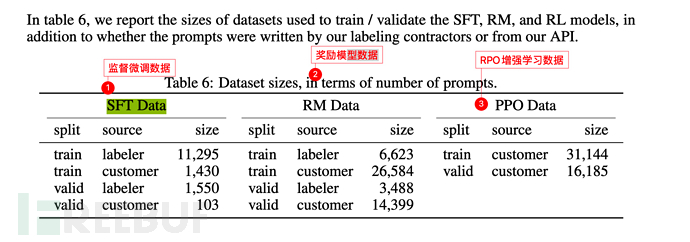 Siehe: AI-001 – Was der beliebte Chatbot ChatGPT kann
Siehe: AI-001 – Was der beliebte Chatbot ChatGPT kann
ChatGPT und InstructionGPT sind im Wesentlichen von derselben Generation. Sie fügen lediglich Chat auf Basis von InstructionGPT hinzu der Öffentlichkeit zu Test- und Schulungszwecken zur Verfügung gestellt, um effektivere Annotationsdaten zu generieren.
8.2 [Wichtig, es wird empfohlen, das empfohlene Video unten zu durchsuchen] Aus der Perspektive des menschlichen intuitiven Verständnisses werden wir die Grundprinzipien von ChatGPT ergänzenSie können sich auf das Video „Wie wird ChatGPT erstellt?“ beziehen. " von Li Hongyi, Professor an der National Taiwan University. „GPT Socialization Process“ ist ein sehr guter Vortrag.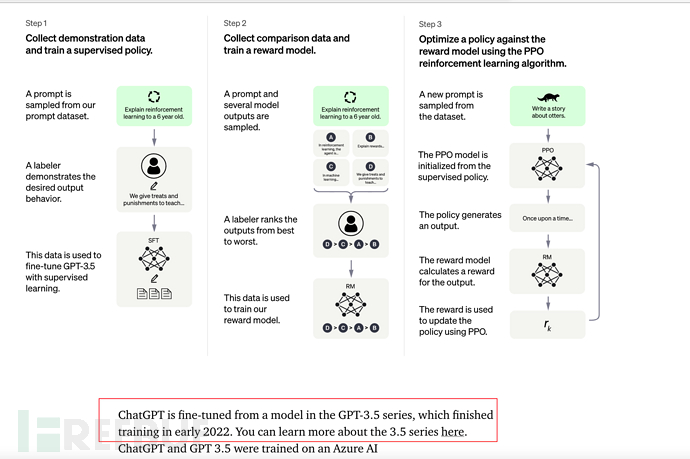 https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
Zum Beispiel gibt es einen Satz:
Geben Sie Eingaben für das GPT-Modell. Hallo, das nächste Wort ist, Sie abzuholen, okay? Du bist attraktiv? Bist du so groß? Wie schön bist du? Warten Sie, GPT berechnet eine Wahrscheinlichkeit und gibt die höchste Wahrscheinlichkeit als Antwort an.
Und so weiter: Wenn ein Befehl (oder eine Eingabeaufforderung) gegeben wird, berechnet ChatGPT auch die folgende (Antwort) basierend auf der oben genannten (Eingabeaufforderung) und wählt gleichzeitig die höchste Wahrscheinlichkeit für die Antwort aus.
Wie unten gezeigt:
9. Zusammenfassung:
1) Im Jahr 2017 veröffentlichte Google das Papier „Attention is all you need“ und schlug das Transformer-Modell vor, das den Weg für GPT ebnete.
2) Im Juni 2018 veröffentlichte OpenAI das generative GPT-Vortrainingsmodell, das mithilfe des großen Datensatzes BooksCorpus (7000 Bücher) trainiert wurde, und befürwortete ein groß angelegtes, unbeaufsichtigtes Vortraining (Vortraining) + Supervised Fine -Tuning für den Modellbau.
3) Im Februar 2019 veröffentlichte OpenAI das GPT-2-Modell und erweiterte damit den Trainingsumfang weiter (unter Verwendung eines 40-GB-Datensatzes mit maximal 1,5 Milliarden Parametern). Gleichzeitig wird in Bezug auf Ideen der Feinabstimmungsprozess entfernt und Zero-Shot (Zero-Shot-Lernen) und Multitasking (Multitasking) betont. Aber am Ende ist der Zero-Shot-Effekt der Feinabstimmung deutlich unterlegen.
4) Im Mai 2020 veröffentlichte OpenAI das GPT-3-Modell und erweiterte damit den **Trainingsumfang (unter Verwendung eines 570-GB-Datensatzes und 175 Milliarden Parametern)** weiter. Gleichzeitig wurde ein Lernmodell mit wenigen Schüssen (kleine Anzahl von Proben) übernommen und erzielte hervorragende Ergebnisse. Natürlich wurde im Experiment gleichzeitig die Feinabstimmung verglichen, und der Effekt war etwas schlechter als die Feinabstimmung.
5) Im Februar 2022 veröffentlichte OpenAI das Instruction GPT-Modell. Diesmal fügte es hauptsächlich einen Supervised Fine-Tuning-Link basierend auf GPT-3 und darauf basierend ein weiteres Belohnungsmodell, das RM-Trainingsmodell, hinzu wird verwendet, um eine RPO-erweiterte Lernoptimierung für das Lernmodell durchzuführen.
6), Am 30. November 2022 veröffentlichte OpenAI das ChatGPT-Modell, das nach mehreren Runden iterativen Trainings als InstructionGPT verstanden werden kann, und darauf basierend wurde eine Chat-Dialogfunktion hinzugefügt.
Aus verschiedenen Gründen könnte GPT-4 im Jahr 2023 vorgestellt werden? Wie mächtig wird es sein?
Gleichzeitig hat die Wirkung von ChatGPT in der Branche große Aufmerksamkeit erregt. Ich glaube, dass in Zukunft weitere GPT-basierte Trainingsmodelle und ihre Anwendungen florieren werden.
Lasst uns abwarten, was die Zukunft bringt.
ai.googleblog.com/2017/08/transformer-novel-neural-network.html
https://arxiv.org/abs/1706.03762
https://paperswithcode.com/method / gpt
https://paperswithcode.com/method/gpt-2
https://paperswithcode.com/method/gpt-3
https://arxiv.org/abs/2203.02155
https:// /zhuanlan.zhihu.com/p/464520503
https://zhuanlan.zhihu.com/p/82312421
https://cloud.tencent.com/developer/article/1656975
https://cloud. tencent.com/developer/article/1848106
https://zhuanlan.zhihu.com/p/353423931
https://zhuanlan.zhihu.com/p/353350370
https://juejin.cn/post /6969394206414471175
https://zhuanlan.zhihu.com/p/266202548
https://en.wikisensitivity.org/wiki/Generative_model
https://zhuanlan.zhihu.com/p/67119176
https ://zhuanlan.zhihu.com/p/365554706
https://cloud.tencent.com/developer/article/1877406
https://zhuanlan.zhihu.com/p/34656727
https :// zhuanlan.zhihu.com/p/590311003
Das obige ist der detaillierte Inhalt vonZehn Minuten, um die technische Logik und Entwicklung von ChatGPT (vergangenes Leben, gegenwärtiges Leben) zu verstehen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 ChatGPT-Registrierung
ChatGPT-Registrierung
 Inländische kostenlose ChatGPT-Enzyklopädie
Inländische kostenlose ChatGPT-Enzyklopädie
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 So installieren Sie ChatGPT auf einem Mobiltelefon
So installieren Sie ChatGPT auf einem Mobiltelefon
 Kann Chatgpt in China verwendet werden?
Kann Chatgpt in China verwendet werden?
 vcruntime140.dll kann nicht gefunden werden und die Codeausführung kann nicht fortgesetzt werden
vcruntime140.dll kann nicht gefunden werden und die Codeausführung kann nicht fortgesetzt werden
 Verwendung der SetTimer-Funktion
Verwendung der SetTimer-Funktion
 iexplore.exe
iexplore.exe








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



