


Transformer ist heute die leistungsstärkste seq2seq-Architektur. Vortrainierte Transformatoren verfügen typischerweise über Kontextfenster von 512 (z. B. BERT) oder 1024 (z. B. BART) Token, was für viele aktuelle Textzusammenfassungsdatensätze (XSum, CNN/DM) lang genug ist.
Aber 16384 ist keine Obergrenze für die Länge des Kontexts, der zur Generierung erforderlich ist: Aufgaben mit langen Erzählungen, wie Buchzusammenfassungen (Krys-´cinski et al., 2021) oder narrative Fragen und Antworten (Kociský et al. , 2018), erfordern häufig Eingaben von mehr als 100.000 Token. Das aus Wikipedia-Artikeln generierte Challenge-Set (Liu* et al., 2018) enthält Eingaben von mehr als 500.000 Token. Open-Domain-Aufgaben bei der generativen Fragebeantwortung können Informationen aus größeren Eingaben synthetisieren, beispielsweise die Beantwortung von Fragen zu den aggregierten Eigenschaften von Artikeln aller lebenden Autoren auf Wikipedia. In Abbildung 1 sind die Größen mehrerer beliebter Zusammenfassungs- und Frage-und-Antwort-Datensätze im Vergleich zu den üblichen Kontextfensterlängen dargestellt. Die längste Eingabe ist mehr als 34-mal länger als das Kontextfenster von Longformer.
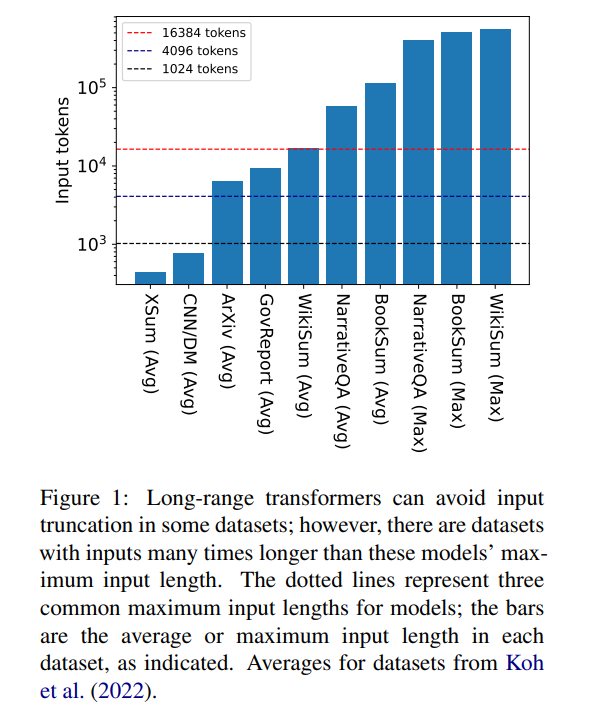
Bei diesen sehr langen Eingaben kann der Vanilla-Transformer nicht skalieren, da der native Aufmerksamkeitsmechanismus quadratische Komplexität aufweist. Lange Eingangstransformatoren sind zwar effizienter als Standardtransformatoren, erfordern jedoch dennoch erhebliche Rechenressourcen, die mit zunehmender Kontextfenstergröße zunehmen. Darüber hinaus erfordert die Vergrößerung des Kontextfensters eine Neuschulung des Modells mit der neuen Kontextfenstergröße, was rechen- und umweltintensiv ist.
In dem Artikel „Unlimiformer: Long-Range Transformers with Unlimited Length Input“ stellten Forscher der Carnegie Mellon University Unlimiformer vor. Hierbei handelt es sich um einen auf Abruf basierenden Ansatz, der ein vorab trainiertes Sprachmodell erweitert, um zum Testzeitpunkt Eingaben mit unendlicher Länge zu akzeptieren.

Link zum Papier: https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer kann in jeden vorhandenen Encoder-Decoder-Transformator injiziert werden, der Eingaben mit unbegrenzter Länge verarbeiten kann . Bei einer langen Eingabesequenz kann Unlimiformer einen Datenspeicher auf den verborgenen Zuständen aller Eingabetoken aufbauen. Der Standard-Cross-Attention-Mechanismus des Decoders ist dann in der Lage, den Datenspeicher abzufragen und sich auf die obersten k Eingabetokens zu konzentrieren. Der Datenspeicher kann im GPU- oder CPU-Speicher gespeichert und sublinear abgefragt werden.
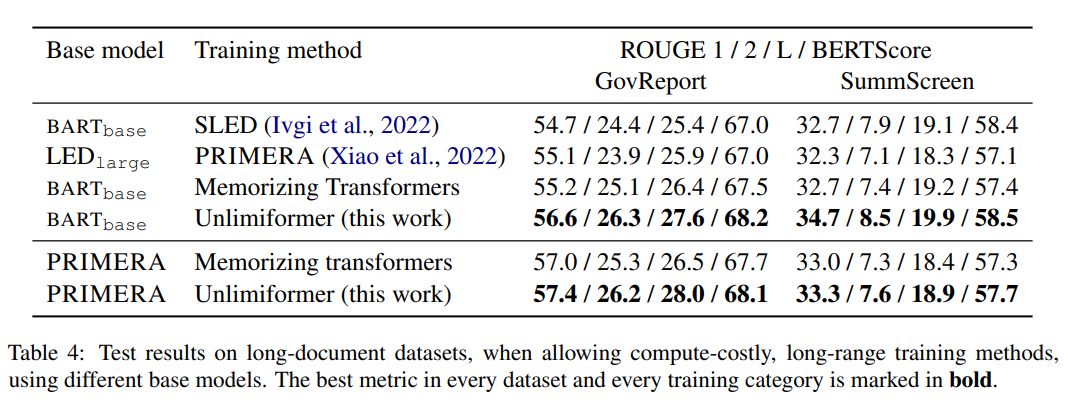
Unlimiformer kann direkt auf ein trainiertes Modell angewendet werden und kann bestehende Kontrollpunkte ohne weitere Schulung verbessern. Die Leistung von Unlimiformer wird nach der Feinabstimmung weiter verbessert. Dieses Papier zeigt, dass Unlimiformer auf mehrere Basismodelle wie BART (Lewis et al., 2020a) oder PRIMERA (Xiao et al., 2022) angewendet werden kann, ohne Gewichte hinzuzufügen und erneut zu trainieren. In verschiedenen seq2seq-Datensätzen mit großer Reichweite ist Unlimiformer nicht nur stärker als Transformer mit großer Reichweite wie Longformer (Beltagy et al., 2020b), SLED (Ivgi et al., 2022) und Memorizing Transformers (Wu et al., 2021). ) auf diesen Datensätzen Die Leistung ist besser, und in diesem Artikel wurde auch festgestellt, dass Unlimiform zusätzlich zum Longformer-Encodermodell angewendet werden kann, um weitere Verbesserungen zu erzielen.
Da die Größe des Encoder-Kontextfensters fest ist, ist die maximale Eingabelänge des Transformers begrenzt. Bei der Dekodierung können jedoch unterschiedliche Informationen relevant sein; außerdem können sich unterschiedliche Aufmerksamkeitsköpfe auf unterschiedliche Arten von Informationen konzentrieren (Clark et al., 2019). Daher verschwendet ein festes Kontextfenster möglicherweise Aufwand für Token, auf die die Aufmerksamkeit weniger gerichtet ist.
Bei jedem Dekodierungsschritt wählt jeder Aufmerksamkeitskopf in Unlimiformer aus allen Eingaben ein separates Kontextfenster aus. Dies wird erreicht, indem die Unlimiformer-Suche in den Decoder eingefügt wird: Bevor das Modell in das Cross-Attention-Modul eintritt, führt es eine k-Nearest-Neighbor-Suche (kNN) im externen Datenspeicher durch und wählt einen Satz jedes Aufmerksamkeitskopfes in jeder Decoderschicht aus. Token zur Teilnahme.
Kodierung
Um die Eingabesequenz länger als die Kontextfensterlänge des Modells zu kodieren, kodiert dieser Artikel die überlappenden Eingabeblöcke gemäß der Methode von Ivgi et al. (2022) (Ivgi et al., 2022), wobei jeder einzelne beibehalten wird Teilen Sie die mittlere Hälfte der Ausgabe auf, um vor und nach dem Kodierungsprozess ausreichend Kontext sicherzustellen. Schließlich verwendet dieser Artikel Bibliotheken wie Faiss (Johnson et al., 2019), um codierte Eingaben in Datenspeichern zu indizieren (Johnson et al., 2019).
Erweiterten Queraufmerksamkeitsmechanismus abrufen
Beim Standard-Queraufmerksamkeitsmechanismus konzentriert sich der Decoder des Transformators auf den endgültigen verborgenen Zustand des Encoders, und der Encoder schneidet normalerweise die Eingabe ab und nur den ersten k Token sind kodiert.
Dieser Artikel konzentriert sich nicht nur auf die ersten k Token der Eingabe, sondern ruft auch die ersten k verborgenen Zustände der längeren Eingabereihe ab und konzentriert sich nur auf die ersten k. Dadurch kann das Schlüsselwort aus der gesamten Eingabesequenz abgerufen werden, anstatt das Schlüsselwort abzuschneiden. Unser Ansatz ist außerdem hinsichtlich der Rechenleistung und des GPU-Speichers kostengünstiger als die Verarbeitung aller Eingabetokens und behält in der Regel über 99 % der Aufmerksamkeitsleistung bei.
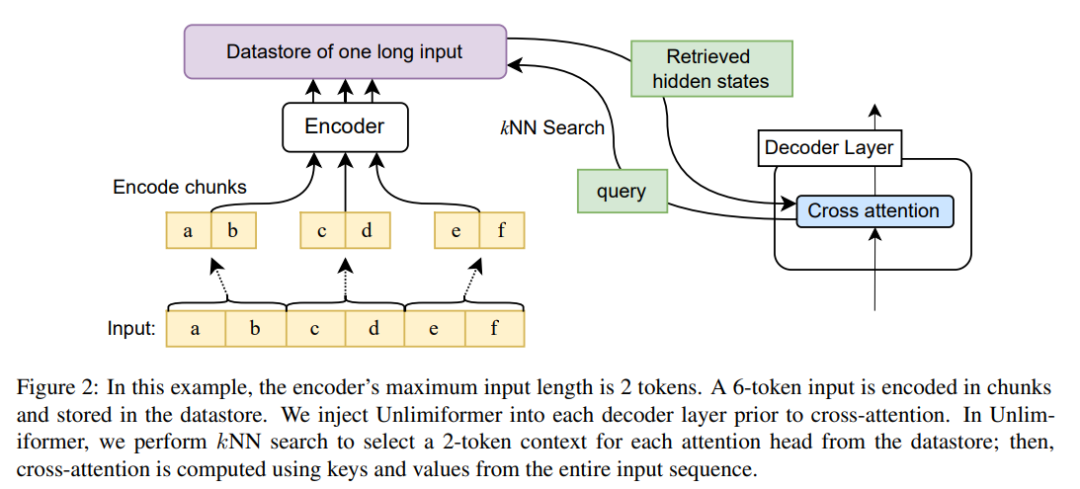
Abbildung 2 zeigt die Änderungen dieses Artikels an der seq2seq-Transformator-Architektur. Die vollständige Eingabe wird mithilfe des Encoders blockcodiert und in einem Datenspeicher gespeichert; der codierte Latentzustandsdatenspeicher wird dann beim Decodieren abgefragt. Die kNN-Suche ist nicht parametrisch und kann in jeden vorab trainierten seq2seq-Transformator eingefügt werden, wie unten beschrieben. Experimentelle Ergebnisse
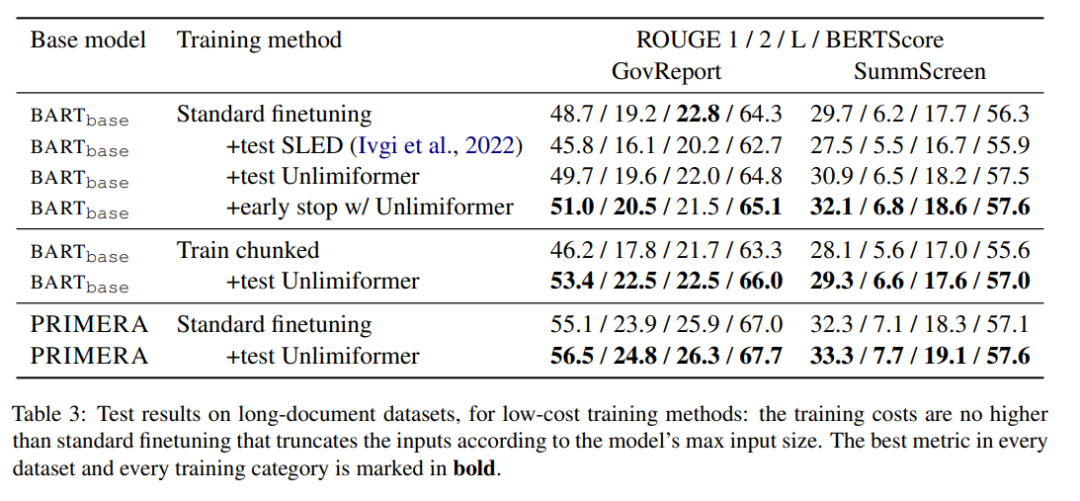
Buchzusammenfassung
Das obige ist der detaillierte Inhalt vonDas 32k-Eingabefeld von GPT-4 reicht immer noch nicht aus? Unlimiformer erweitert die Kontextlänge auf unendliche Länge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie den Atom-Editor
So verwenden Sie den Atom-Editor
 Verwendung der Resample-Funktion
Verwendung der Resample-Funktion
 So verwenden Sie die Auswahlfunktion
So verwenden Sie die Auswahlfunktion
 So erstellen Sie virtuelles WLAN in Win7
So erstellen Sie virtuelles WLAN in Win7
 So lösen Sie das Problem, dass der Geräte-Manager nicht geöffnet werden kann
So lösen Sie das Problem, dass der Geräte-Manager nicht geöffnet werden kann
 So verwenden Sie die Längenfunktion in Matlab
So verwenden Sie die Längenfunktion in Matlab
 Was bedeutet Bildrate?
Was bedeutet Bildrate?
 Der Unterschied zwischen Konsolenkabel und Netzwerkkabel
Der Unterschied zwischen Konsolenkabel und Netzwerkkabel








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



