


In den letzten zwei Jahren gab es in der KI-Branche einen Anstieg bei der Veröffentlichung groß angelegter generativer Modelle, insbesondere nach der Open Source von Stable Diffusion und der offenen Schnittstelle von ChatGPT, was die Begeisterung der Branche weiter angeregt hat für generative Modelle.
Allerdings gibt es viele Arten von generativen Modellen und die Veröffentlichungsgeschwindigkeit ist sehr hoch. Wenn Sie nicht aufpassen, könnten Sie Sota übersehen. Kürzlich haben Forscher der Päpstlichen Universität Comillas in Spanien eine umfassende Überprüfung durchgeführt KI in verschiedenen Bereichen Der neueste Fortschritt hat generative Modelle nach Aufgabenmodi und -feldern in neun Kategorien unterteilt und 21 im Jahr 2022 veröffentlichte generative Modelle zusammengefasst, sodass Sie den Entwicklungskontext generativer Modelle sofort verstehen können!
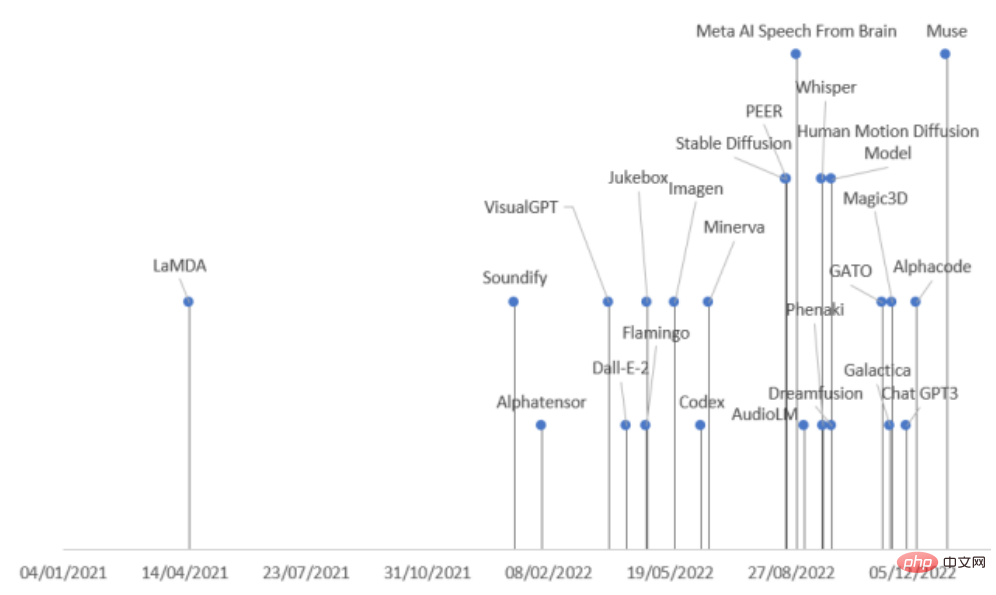
Papierlink: https://arxiv.org/abs/2301.04655
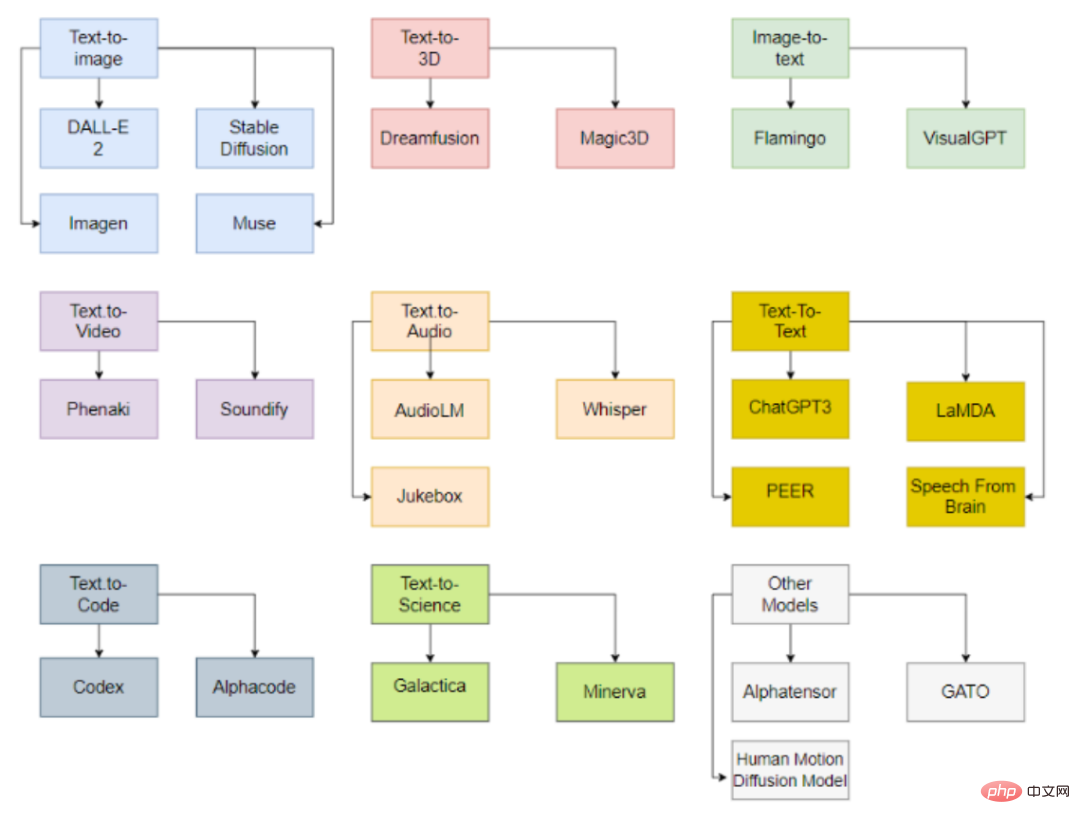
Generative KI-Klassifizierung
Interessanterweise sind hinter diesen großen veröffentlichten Modellen nur sechs Organisationen (OpenAI, Google, DeepMind, Meta, Runway, Nvidia) an der Bereitstellung dieser hochmodernen Modelle beteiligt.
Der Hauptgrund ist, dass man, um die Parameter dieser Modelle abschätzen zu können, über eine extrem große Rechenleistung sowie ein Team verfügen muss, das hochqualifiziert und erfahren in den Bereichen Datenwissenschaft und Datentechnik ist.
Daher können nur diese Unternehmen mit Hilfe übernommener Startups und Kooperationen mit der Wissenschaft erfolgreich generative KI-Modelle einsetzen. 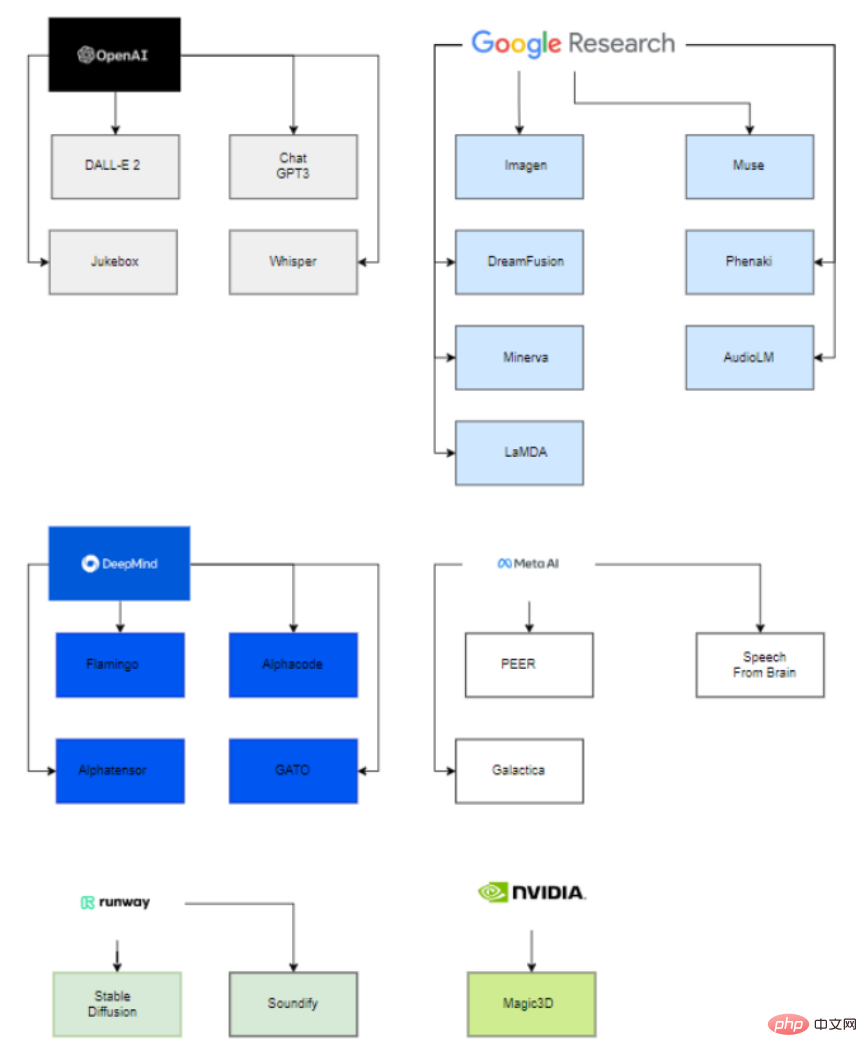
Insbesondere verfügt die CLIP-Einbettung über mehrere wünschenswerte Eigenschaften: Sie ist in der Lage, die Bildverteilung stabil zu transformieren, und sie erzielt nach der Feinabstimmung hochmoderne Ergebnisse.
Um ein vollständiges Bildgenerierungsmodell zu erhalten, wird das CLIP-Bildeinbettungs-Decodermodul mit einem Vorgängermodell kombiniert, um relevante CLIP-Bildeinbettungen aus einer bestimmten Textbeschriftung zu generieren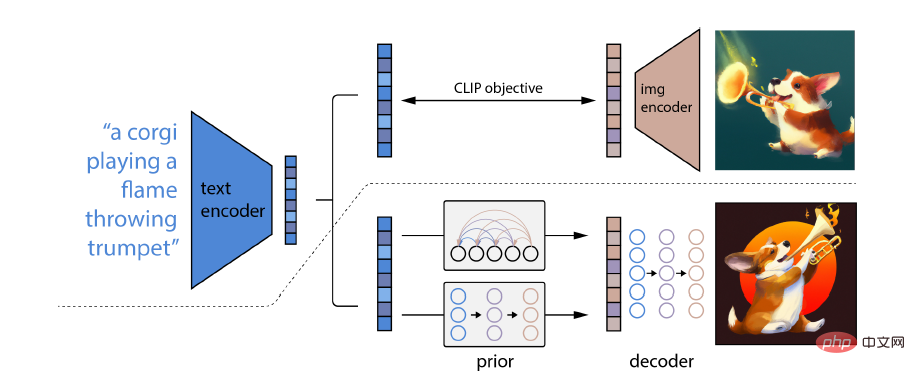
Andere Modelle umfassen Imagen, Stable Diffusion, Muse
Text -zu-3D-Modell
Dreamfusion ersetzt die CLIP-Technik durch einen Verlust, der aus der Destillation eines zweidimensionalen Diffusionsmodells erhalten wird. Das heißt, das Diffusionsmodell kann als Verlust in einem allgemeinen kontinuierlichen Optimierungsproblem zum Generieren von Proben verwendet werden.
Im Vergleich zu anderen Methoden, die hauptsächlich Pixel abtasten, ist die Abtastung im Pixelraum viel schwieriger. Der Schwerpunkt liegt auf der Erstellung von Bildern, die aus zufälligen Winkeln gerendert werden.

Andere Modelle wie Magic3D werden von NVIDIA entwickelt.
Es ist auch nützlich, einen Text zu erhalten, der das Bild beschreibt, was der umgekehrten Version der Bildgenerierung entspricht.
Flamingo
Dieses von Deepmind entwickelte Modell kann mit nur wenigen Eingabeaufforderungen aus Eingabe-/Ausgabebeispielen das Lernen in wenigen Schritten für offene visuelle Sprachaufgaben durchführen.
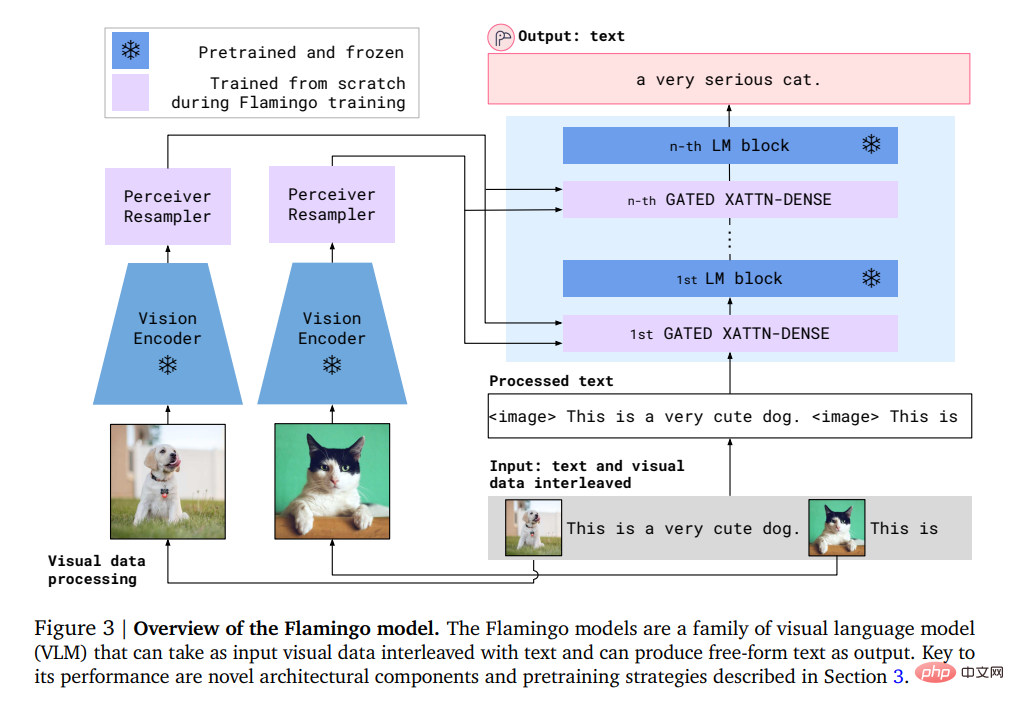
Konkret umfasst die Eingabe von Flamingo ein autoregressives Textgenerierungsmodell unter visuellen Bedingungen, das eine mit Bildern oder Videos verschachtelte Folge von Text-Tokens empfangen und Text als Ausgabe generieren kann.
Benutzer können eine Anfrage in das Modell eingeben und ein Foto oder Video anhängen, und das Modell antwortet mit einer Textantwort.

Das Flamingo-Modell nutzt zwei komplementäre Modelle: ein visuelles Modell, das visuelle Szenen analysiert, und ein großes Sprachmodell, das grundlegende Formen des Denkens durchführt.
VisualGPT
VisualGPT ist ein von OpenAI entwickeltes Bildbeschreibungsmodell, das das Wissen im vorab trainierten Sprachmodell GPT-2 nutzen kann.
Um die semantische Lücke zwischen verschiedenen Modalitäten zu schließen, haben die Forscher einen neuen Encoder-Decoder-Aufmerksamkeitsmechanismus mit Gleichrichtungs-Gating-Funktion entwickelt.

Der größte Vorteil von VisualGPT besteht darin, dass es nicht so viele Daten erfordert wie andere Bild-zu-Text-Modelle, die Dateneffizienz von Bildbeschreibungsmodellen verbessern und in Nischenbereichen oder zur Beschreibung seltener Objekte angewendet werden kann.
Phenaki
Dieses Modell wurde von Google Research entwickelt und produziert und kann anhand einer Reihe von Textaufforderungen eine echte Videosynthese durchführen.
Phenaki ist das erste Modell, das Videos aus zeitvariablen Hinweisen mit offener Domäne generieren kann.
Um das Datenproblem zu lösen, trainierten die Forscher gemeinsam an einem großen Bild-Text-Paar-Datensatz und einer kleineren Anzahl von Video-Text-Beispielen und erreichten schließlich Generalisierungsfähigkeiten über den Videodatensatz hinaus.
Hauptsächlich Bild-Text-Datensätze enthalten in der Regel Milliarden von Eingabedaten, während Text-Video-Datensätze viel kleiner sind und die Berechnung von Videos unterschiedlicher Länge ebenfalls ein schwieriges Problem darstellt.

Das Phenaki-Modell besteht aus drei Teilen: C-ViViT-Encoder, Trainingstransformator und Videogenerator.
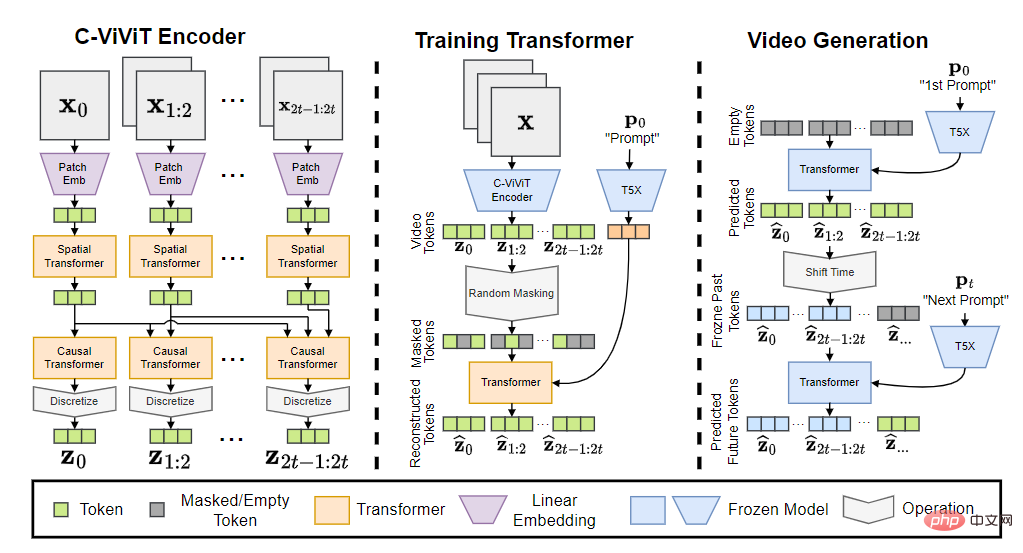
Nachdem das Eingabe-Token in Einbettung umgewandelt wurde, durchläuft es den zeitlichen Transformator und den räumlichen Transformator und verwendet dann eine einzelne lineare Projektion ohne Aktivierung, um das Token wieder dem Pixelraum zuzuordnen.
Das endgültige Modell kann Videos mit zeitlicher Kohärenz und Diversität generieren, die auf offenen Domänenhinweisen basieren, und ist sogar in der Lage, einige neue Konzepte zu verarbeiten, die im Datensatz nicht vorhanden sind.
Zu den verwandten Modellen gehört Soundify.
Für die Videoerzeugung ist Ton ebenfalls ein unverzichtbarer Bestandteil.
AudioLM
Dieses Modell wurde von Google entwickelt und kann verwendet werden, um hochwertiges Audio mit Konsistenz über große Entfernungen zu erzeugen.
Das Besondere an AudioLM ist, dass es Eingabeaudio in eine diskrete Tokensequenz umwandelt und die Audiogenerierung als Sprachmodellierungsaufgabe in diesem Darstellungsraum verwendet.
Durch das Training an einem großen Korpus roher Audiowellenformen hat AudioLM erfolgreich gelernt, unter kurzen Eingabeaufforderungen natürliche und kohärente kontinuierliche Sprache zu erzeugen. Diese Methode kann sogar auf andere Sprache als menschliche Stimmen ausgeweitet werden, z. B. auf kontinuierliche Klaviermusik usw., ohne während des Trainings eine symbolische Darstellung hinzuzufügen.
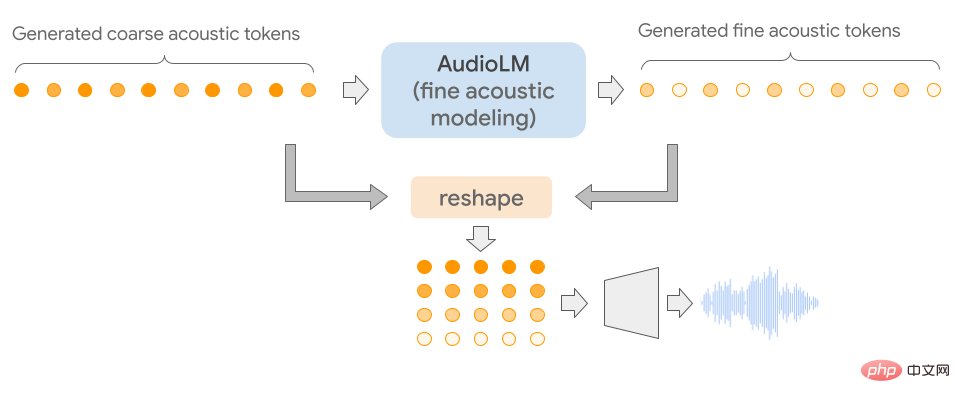
Da Audiosignale die Abstraktion mehrerer Skalen beinhalten, ist es eine große Herausforderung, eine hohe Audioqualität auf mehreren Skalen zu erreichen und gleichzeitig bei der Audiosynthese Konsistenz zu zeigen. Das AudioLM-Modell wird durch die Kombination aktueller Fortschritte in der neuronalen Audiokomprimierung, selbstüberwachtem Repräsentationslernen und Sprachmodellierung implementiert.
Zur subjektiven Bewertung werden die Prüfer gebeten, sich eine 10-sekündige Probe anzuhören und zu entscheiden, ob es sich um menschliche Sprache oder synthetisierte Sprache handelt. Basierend auf 1000 gesammelten Bewertungen liegt die Quote bei 51,2 %, was sich statistisch nicht von zufällig vergebenen Labels unterscheidet, d. h. Menschen können nicht zwischen synthetischen und echten Proben unterscheiden.
Andere verwandte Modelle umfassen Jukebox und Whisper
Wird häufig bei Frage- und Antwortaufgaben verwendet.
ChatGPT
Das beliebte ChatGPT wurde von OpenAI entwickelt und interagiert auf konversationelle Weise mit Benutzern.
Der Benutzer stellt eine Frage oder die erste Hälfte des Eingabeaufforderungstextes, und das Modell vervollständigt die folgenden Teile und kann falsche Eingabevoraussetzungen erkennen und unangemessene Anfragen ablehnen.
Konkret handelt es sich bei dem Algorithmus hinter ChatGPT um Transformer, und der Trainingsprozess besteht hauptsächlich aus verstärkendem Lernen basierend auf menschlichem Feedback.
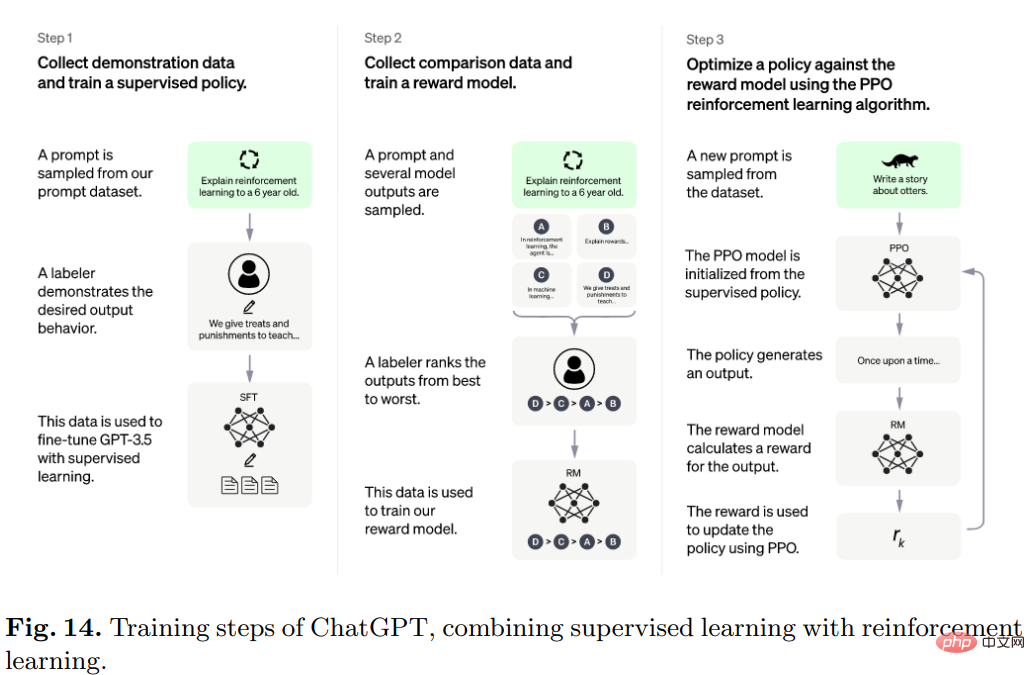
Das ursprüngliche Modell wird durch Feinabstimmung im Rahmen des überwachten Lernens trainiert, und dann führen Menschen Gespräche, in denen sie die Rolle des Benutzers und des KI-Assistenten füreinander übernehmen. Die Menschen modifizieren dann die vom Modell zurückgegebenen Antworten und verwenden sie Die richtigen Antworten helfen dem Modell, sich zu verbessern.
Mischen Sie den erstellten Datensatz mit dem Datensatz von InstructGPT und konvertieren Sie ihn in ein Konversationsformat.
Andere verwandte Modelle sind LaMDA und PEER.
ähnelt Text-to-Text, außer dass es eine spezielle Art von Text, nämlich Code, generiert.
Codex
Dieses von OpenAI entwickelte Modell kann Text in Code übersetzen.
Codex ist ein allgemeines Programmiermodell, das auf grundsätzlich jede Programmieraufgabe angewendet werden kann.
Menschliche Aktivitäten beim Programmieren können in zwei Teile unterteilt werden: 1) Zerlegen eines Problems in einfachere Probleme; 2) Zuordnen dieser Probleme in vorhandenen vorhandenen Code (Bibliothek, API oder Funktion).
Der zweite Teil ist für Programmierer der zeitraubendste Teil und darin ist Codex auch am besten.
Trainingsdaten wurden aus öffentlichen Software-Repositories gesammelt, die im Mai 2020 auf GitHub gehostet wurden, 179 GB Python-Dateien enthalten und auf GPT-3 optimiert wurden, das bereits leistungsstarke Darstellungen in natürlicher Sprache enthält.
Zu den verwandten Modellen gehört auch Alphacode
Wissenschaftlicher Forschungstext ist ebenfalls eines der Ziele der KI-Textgenerierung, aber es ist noch ein langer Weg, bis Ergebnisse erzielt werden.
Galactica
Dieses Modell wurde gemeinsam von Meta AI und Papers with Code entwickelt und kann zur automatischen Organisation groß angelegter Modelle wissenschaftlicher Texte verwendet werden.
Der Hauptvorteil von Galactica besteht darin, dass das Modell auch nach dem Training mehrerer Episoden immer noch nicht überangepasst ist und sich die Upstream- und Downstream-Leistung durch die wiederholte Verwendung von Token verbessert.
Und das Design des Datensatzes ist für diesen Ansatz von entscheidender Bedeutung, da alle Daten in einem gemeinsamen Markdown-Format verarbeitet werden, was die Mischung von Wissen aus verschiedenen Quellen ermöglicht.
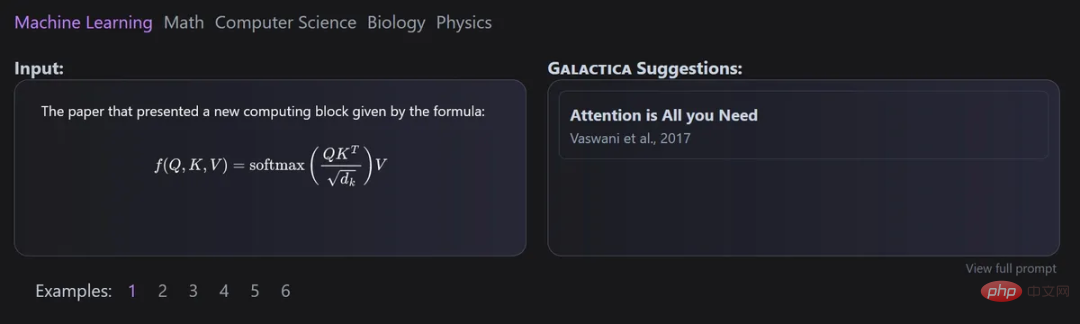
Zitate werden über ein bestimmtes Token verarbeitet, sodass Forscher ein Zitat in jedem Eingabekontext vorhersagen können. Die Fähigkeit von Galactica-Modellen, Zitate vorherzusagen, nimmt mit zunehmendem Maßstab zu.
Darüber hinaus verwendet das Modell eine Transformer-Architektur in einer reinen Decoder-Umgebung mit GeLU-Aktivierung für alle Größen des Modells und ermöglicht die Ausführung multimodaler Aufgaben mit SMILES-chemischen Formeln und Proteinsequenzen,
Minerva
The main Der Zweck von Minerva besteht darin, mathematische und wissenschaftliche Probleme zu lösen. Zu diesem Zweck hat es eine große Menge an Trainingsdaten gesammelt, Probleme beim quantitativen Denken und bei der Entwicklung umfangreicher Modelle gelöst und auch erstklassige Argumentationstechnologie übernommen.
Die Modellarchitektur der Minerva-Sampling-Sprache löst das Problem der Eingabe durch schrittweises Denken, d. h. die Eingabe muss Berechnungen und symbolische Operationen umfassen, ohne dass externe Tools eingeführt werden müssen.
Es gibt auch einige Modelle, die nicht in die zuvor genannten Kategorien fallen.
AlphaTensor
Es wurde von Deepmind entwickelt und ist aufgrund seiner Fähigkeit, neue Algorithmen zu entdecken, ein völlig revolutionäres Modell in der Branche.
Im veröffentlichten Beispiel hat AlphaTensor einen effizienteren Matrixmultiplikationsalgorithmus erstellt. Dieser Algorithmus ist so wichtig, dass alles, von neuronalen Netzen bis hin zu wissenschaftlichen Computerprogrammen, von dieser effizienten Multiplikationsberechnung profitieren kann.
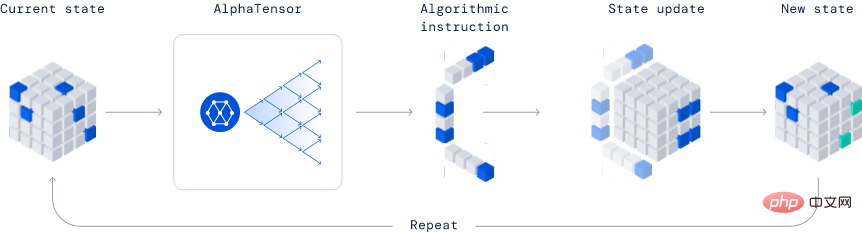
Diese Methode basiert auf der Deep-Reinforcement-Learning-Methode, bei der der Trainingsprozess des Agenten AlphaTensor darin besteht, ein Einzelspielerspiel zu spielen, und das Ziel darin besteht, die Tensorzerlegung in einem begrenzten Faktorraum zu finden.
Bei jedem Schritt von TensorGame müssen die Spieler entscheiden, wie sie verschiedene Einträge der Matrix kombinieren, um eine Multiplikation durchzuführen, und Bonuspunkte basierend auf der Anzahl der Operationen verdienen, die erforderlich sind, um das richtige Multiplikationsergebnis zu erzielen. AlphaTensor nutzt eine spezielle neuronale Netzwerkarchitektur, um die Symmetrie des synthetischen Trainingsspiels auszunutzen.
GATO
Dieses Modell ist ein von Deepmind entwickelter Generalagent. Es kann als multimodale, Multi-Task- oder Multi-Embodiment-Generalisierungsstrategie verwendet werden.
Das gleiche Netzwerk mit der gleichen Gewichtung kann sehr unterschiedliche Funktionen beherbergen, vom Spielen von Atari-Spielen über das Beschreiben von Bildern, Chatten, Stapeln von Blöcken und mehr.
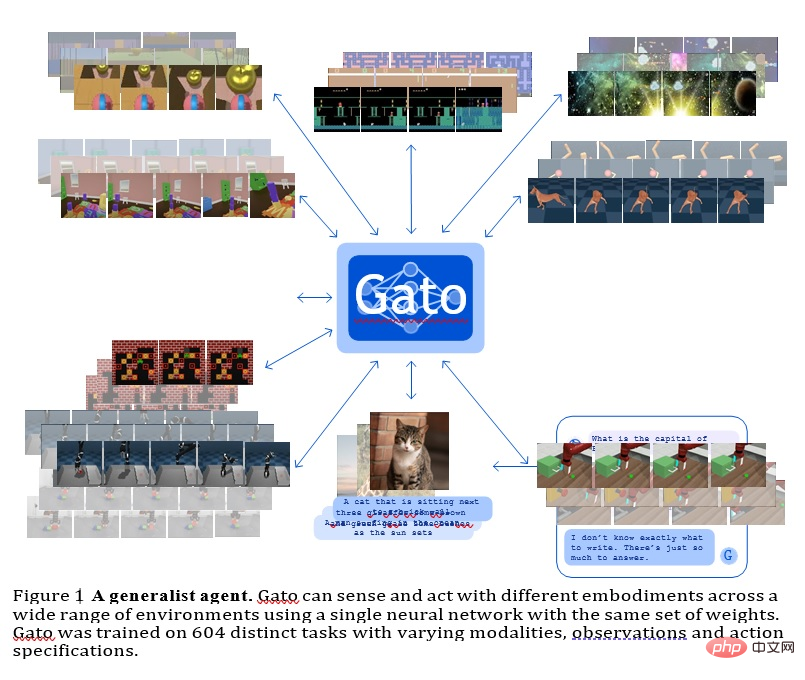
Die Verwendung eines einzigen neuronalen Sequenzmodells für alle Aufgaben bietet viele Vorteile: Sie verringert die Notwendigkeit, strategische Modelle mit ihren eigenen induktiven Tendenzen manuell zu erstellen, und erhöht die Menge und Vielfalt der Trainingsdaten.
Dieser Allzweckagent ist bei einer Vielzahl von Aufgaben erfolgreich und kann mit wenigen zusätzlichen Daten so abgestimmt werden, dass er noch mehr Aufgaben erfolgreich bewältigt.
Derzeit verfügt GATO über etwa 1,2 Milliarden Parameter, mit denen der Modellmaßstab realer Roboter in Echtzeit gesteuert werden kann.
Andere veröffentlichte generative künstliche Intelligenzmodelle umfassen die Erzeugung menschlicher Bewegungen usw.
Referenz: https://arxiv.org/abs/2301.04655
Das obige ist der detaillierte Inhalt vonLesen Sie alle generativen SOTA-Modelle in einem Artikel: eine vollständige Übersicht über 21 Modelle in neun Kategorien!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































