


Aufgrund ihrer Komplexität werden neuronale Netze oft als „heiliger Gral“ zur Lösung aller Probleme des maschinellen Lernens angesehen. Baumbasierte Methoden hingegen haben nicht die gleiche Aufmerksamkeit erhalten, was vor allem auf die scheinbare Einfachheit solcher Algorithmen zurückzuführen ist. Diese beiden Algorithmen mögen zwar unterschiedlich erscheinen, aber sie sind wie zwei Seiten derselben Medaille, beide sind wichtig.

basiert On-Tree-Methoden sind oft besser als neuronale Netze. Im Wesentlichen werden baumbasierte Methoden und auf neuronalen Netzwerken basierende Methoden in dieselbe Kategorie eingeordnet, da beide das Problem durch schrittweise Dekonstruktion angehen, anstatt den gesamten Datensatz durch komplexe Grenzen wie Support-Vektor-Maschinen oder logistische Regression aufzuteilen. .
Offensichtlich teilt die baumbasierte Methode den Feature-Raum schrittweise entlang verschiedener Features auf, um den Informationsgewinn zu optimieren. Weniger offensichtlich ist, dass auch neuronale Netze Aufgaben auf ähnliche Weise angehen. Jedes Neuron überwacht einen bestimmten Teil des Merkmalsraums (mit mehreren Überlappungen). Wenn Eingaben in diesen Raum gelangen, werden bestimmte Neuronen aktiviert.
Neuronale Netze betrachten diese Stück-für-Stück-Modellanpassung aus einer probabilistischen Perspektive, während baumbasierte Methoden eine deterministische Perspektive verwenden. Unabhängig davon hängt die Leistung beider von der Tiefe des Modells ab, da ihre Komponenten verschiedenen Teilen des Merkmalsraums zugeordnet sind.
Ein Modell, das zu viele Komponenten enthält (Knoten für Baummodelle, Neuronen für neuronale Netze), wird überpassen, während ein Modell mit zu wenigen Komponenten überpasst überhaupt gemacht werden kann. (Beide beginnen mit dem Auswendiglernen von Datenpunkten, anstatt die Verallgemeinerung zu lernen.)
Um intuitiver zu verstehen, wie neuronale Netze den Merkmalsraum aufteilen, können Sie diesen Artikel lesen, in dem die universelle Näherung vorgestellt wird Satz: https://medium.com/analytics-vidhya/you-dont-understand-neural-networks-until-you-understand-the-universal- approximation-theory-85b3e7677126.
Während es viele leistungsstarke Varianten von Entscheidungsbäumen wie Random Forest, Gradient Boosting, AdaBoost und Deep Forest gibt, sind baumbasierte Methoden im Wesentlichen eine vereinfachte Version von neuronales Netzwerk.
Baumbasierte Methoden lösen das Problem Stück für Stück durch vertikale und horizontale Linien, um die Entropie zu minimieren (Optimierer und Verlust). Neuronale Netze nutzen Aktivierungsfunktionen, um Probleme Stück für Stück zu lösen.
Baumbasierte Methoden sind eher deterministisch als probabilistisch. Dies bringt einige nette Vereinfachungen mit sich, wie z. B. die automatische Funktionsauswahl.
Die aktivierten Bedingungsknoten im Entscheidungsbaum ähneln den aktivierten Neuronen (Informationsfluss) im neuronalen Netzwerk.
Das neuronale Netzwerk wandelt die Eingabe durch Anpassungsparameter um und steuert indirekt die Aktivierung nachfolgender Neuronen. Entscheidungsbäume passen explizit Parameter an, um den Informationsfluss zu steuern. (Dies ist das Ergebnis, das der Gewissheit und der Wahrscheinlichkeit entspricht.) außer dass der Ablauf im Baummodell einfacher ist.
1 und 0 Auswahl des Baummodells VS Wahrscheinlichkeitsauswahl des neuronalen Netzwerks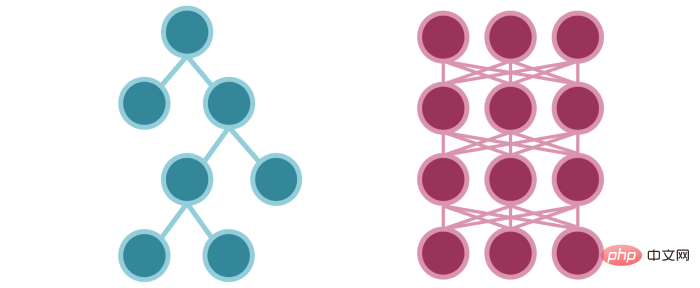
Es gibt nur sehr wenige Bilder, die mit Einsen und Nullen modelliert werden können. Entscheidungsbaumwerte können Datensätze mit vielen Zwischenwerten (z. B. 0,5) nicht verarbeiten, weshalb sie bei MNIST-Datensätzen gut funktionieren, bei denen die Pixelwerte fast alle schwarz oder weiß sind, die Pixel anderer Datensätze jedoch nicht (z. B. ImageNet). . Ebenso enthält der Text zu viele Informationen und zu viele Anomalien, um sie in deterministischen Begriffen auszudrücken.
Dies ist auch der Grund, warum neuronale Netze hauptsächlich in diesen Bereichen eingesetzt werden, und auch der Grund, warum die neuronale Netzforschung in den Anfängen (vor Beginn der Forschung) stagnierte 21. Jahrhundert), als große Datenmengen nicht verfügbar waren. Andere häufige Anwendungen neuronaler Netze beschränken sich auf groß angelegte Vorhersagen, wie z. B. YouTube-Videoempfehlungsalgorithmen, die sehr umfangreich sind und Wahrscheinlichkeiten verwenden müssen.
Das Data-Science-Team jedes Unternehmens wird wahrscheinlich baumbasierte Modelle anstelle von neuronalen Netzen verwenden, es sei denn, es erstellt eine anspruchsvolle Anwendung wie das Verwischen des Hintergrunds eines Video zoomen. Aber bei alltäglichen Geschäftsklassifizierungsaufgaben machen baumbasierte Methoden diese Aufgaben aufgrund ihrer deterministischen Natur leicht und ihre Methoden sind die gleichen wie bei neuronalen Netzen.
In vielen praktischen Situationen ist die deterministische Modellierung natürlicher als die probabilistische Modellierung. Um beispielsweise vorherzusagen, ob ein Benutzer einen Artikel auf einer E-Commerce-Website kaufen wird, ist ein Baummodell eine gute Wahl, da Benutzer natürlich einem regelbasierten Entscheidungsprozess folgen. Der Entscheidungsprozess eines Benutzers könnte wie folgt aussehen:
Im Allgemeinen folgt der Mensch einem regelbasierten und strukturierten Entscheidungsprozess. In diesen Fällen ist eine probabilistische Modellierung nicht erforderlich.
Der Hauptunterschied in der Verwendung zwischen baumbasierten Methoden und neuronalen Netzwerkmethoden sind deterministische (0/1) und probabilistische Datenstrukturen. Strukturierte (tabellarische) Daten können mithilfe deterministischer Modelle besser modelliert werden.
Das obige ist der detaillierte Inhalt vonMaschinelles Lernen: Unterschätzen Sie nicht die Leistungsfähigkeit von Baummodellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



