


In der Mathematik ist Gaußsches Rauschen eine Art Rauschen, das durch Addition normalverteilter Zufallswerte mit Mittelwert Null und Standardabweichung (σ) zu den Eingabedaten entsteht. Die Normalverteilung, auch Gaußsche Verteilung genannt, ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die durch ihre Wahrscheinlichkeitsdichtefunktion (PDF) definiert ist:
pdf(x) = (1 / (σ * sqrt(2 * π))) * e^(- (x — μ)² / (2 * σ²))
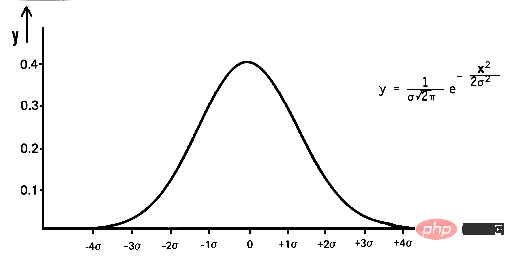
wobei x eine Zufallsvariable, μ der Mittelwert und σ die ist Standardabweichung.
Indem zufällige Werte mit Normalverteilung generiert und zu den Eingabedaten hinzugefügt werden. Wenn Sie beispielsweise einem Bild Gaußsches Rauschen hinzufügen, können Sie das Bild als zweidimensionale Matrix von Pixelwerten darstellen und dann die Numpy-Bibliothek np.random.randn(rows,cols) verwenden, um Zufallswerte mit a zu generieren Normalverteilung und addiere sie in Pixelwerten zum Bild. Dies führt zu einem neuen Bild mit hinzugefügtem Gaußschen Rauschen.
Gaußsches Rauschen, auch weißes Rauschen genannt, ist eine Art zufälliges Rauschen, das einer Normalverteilung folgt. Beim Deep Learning wird den Eingabedaten während des Trainings häufig Gaußsches Rauschen hinzugefügt, um die Robustheit und Generalisierungsfähigkeit des Modells zu verbessern. Dies wird als Datenerweiterung bezeichnet. Durch das Hinzufügen von Rauschen zu den Eingabedaten wird das Modell gezwungen, Funktionen zu lernen, die gegenüber kleinen Änderungen in der Eingabe robust sind, was dazu beitragen kann, dass es bei neuen, unsichtbaren Daten eine bessere Leistung erbringt. Gaußsches Rauschen kann während des Trainings auch zu den Gewichten eines neuronalen Netzwerks hinzugefügt werden, um dessen Leistung zu verbessern, eine Technik, die als Dropout bezeichnet wird.
Beginnen wir mit einem einfachen Beispiel:
Die Standardabweichung des Rauschens (noise_std) wird auf einen größeren Wert von 50 eingestellt, wodurch dem Bild mehr Rauschen hinzugefügt wird. Es ist ersichtlich, dass das Rauschen deutlicher ist und die Merkmale des Originalbilds weniger offensichtlich sind.
Es ist zu beachten, dass Sie beim Hinzufügen von mehr Rauschen sicherstellen müssen, dass das Rauschen den gültigen Bereich der Pixelwerte (d. h. zwischen 0 und 255) nicht überschreitet. In diesem Beispiel wird die Funktion np.clip() verwendet, um sicherzustellen, dass die Pixelwerte des verrauschten Bildes innerhalb des gültigen Bereichs liegen.
Während mehr Rauschen es möglicherweise einfacher macht, den Unterschied zwischen dem Originalbild und dem verrauschten Bild zu erkennen, kann es für das Modell auch schwieriger sein, nützliche Funktionen aus den Daten zu lernen, und es kann zu einer Über- oder Unteranpassung kommen. Daher ist es am besten, mit einem geringen Geräuschpegel zu beginnen und ihn dann schrittweise zu erhöhen, während Sie gleichzeitig die Leistung des Modells überwachen.
import cv2
import numpy as np
# Load the image
image = cv2.imread('dog.jpg')
# Add Gaussian noise to the image
noise_std = 50
noise = np.random.randn(*image.shape) * noise_std
noisy_image = np.clip(image + noise, 0, 255).astype(np.uint8)
# Display the original and noisy images
cv2.imshow('Original Image', image)
cv2.imshow('Noisy Image', noisy_image)
cv2.waitKey(0)
cv2.destroyAllWindows()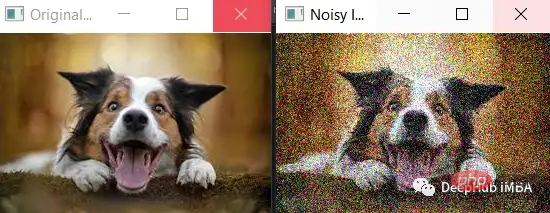
Einige Beispiele, wie Gaußsches Rauschen beim Deep Learning verwendet werden kann.
In allen oben genannten Beispielen wird der Eingabe oder den Gewichten auf kontrollierte Weise Gaußsches Rauschen mit einem bestimmten Mittelwert und einer bestimmten Standardabweichung hinzugefügt. Ziel ist es, die Leistung und Robustheit des Modells zu verbessern, ohne das Lernen des Modells aus den Daten zu erschweren.
Hier erklären wir, wie man den Eingabedaten während des Trainings mit Python und Keras Gaußsches Rauschen hinzufügt, bevor man es an das Modell übergibt:
from keras.preprocessing.image import ImageDataGenerator # Define the data generator datagen = ImageDataGenerator( featurewise_center=False,# set input mean to 0 over the dataset samplewise_center=False,# set each sample mean to 0 featurewise_std_normalization=False,# divide inputs by std of the dataset samplewise_std_normalization=False,# divide each input by its std zca_whitening=False,# apply ZCA whitening rotation_range=0,# randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.1,# randomly shift images horizontally (fraction of total width) height_shift_range=0.1,# randomly shift images vertically (fraction of total height) horizontal_flip=False,# randomly flip images vertical_flip=False,# randomly flip images noise_std=0.5# add gaussian noise to the data with std of 0.5 ) # Use the generator to transform the data during training model.fit_generator(datagen.flow(x_train, y_train, batch_size=32), steps_per_epoch=len(x_train) / 32, epochs=epochs)
Keras 的 ImageDataGenerator 类用于定义一个数据生成器,该数据生成器将指定的数据增强技术应用于输入数据。 我们将 noise_std 设置为 0.5,这意味着标准偏差为 0.5 的高斯噪声将添加到输入数据中。 然后在调用 model.fit_generator 期间使用生成器在训练期间将数据扩充应用于输入数据。
至于Dropout,可以使用Keras中的Dropout层,设置dropout的rate,如果设置rate为0.5,那么dropout层会drop掉50%的权重。 以下是如何向模型添加 dropout 层的示例:
from keras.layers import Dropout model = Sequential() model.add(Dense(64, input_dim=64, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(64, activation='relu')) model.add(Dense(10, activation='softmax'))
需要注意的是,标准差、Dropout的实际值将取决于具体问题和数据的特征。使用不同的值进行试验并监视模型的性能通常是一个好主意。
下面我们介绍使用Keras 在训练期间将高斯噪声添加到输入数据和权重。为了向输入数据添加噪声,我们可以使用 numpy 库生成随机噪声并将其添加到输入数据中。 这是如何执行此操作的示例:
import numpy as np # Generate some random input data x_train = np.random.rand(1000, 64) y_train = np.random.rand(1000, 10) # Add Gaussian noise to the input data noise_std = 0.5 x_train_noisy = x_train + noise_std * np.random.randn(*x_train.shape) # Train the model model.fit(x_train_noisy, y_train, epochs=10)
我们输入数据 x_train 是形状为 (1000, 64) 的二维数组,噪声是使用 np.random.randn(*x_train.shape) 生成的,它将返回具有相同形状的正态分布均值为 0,标准差为 1的随机值数组。然后将生成的噪声与噪声的标准差 (0.5) 相乘,并将其添加到输入数据中,从而将其添加到输入数据中。
为了给权重添加噪声,我们可以使用 Keras 中的 Dropout 层,它会在训练过程中随机丢弃一些权重。 高斯噪声是深度学习中广泛使用的技术,在图像分类训练时可以在图像中加入高斯噪声,提高图像分类模型的鲁棒性。 这在训练数据有限或具有很大可变性时特别有用,因为模型被迫学习对输入中的小变化具有鲁棒性的特征。
以下是如何在训练期间向图像添加高斯噪声以提高图像分类模型的鲁棒性的示例:
from keras.preprocessing.image import ImageDataGenerator # Define the data generator datagen = ImageDataGenerator( featurewise_center=False,# set input mean to 0 over the dataset samplewise_center=False,# set each sample mean to 0 featurewise_std_normalization=False,# divide inputs by std of the dataset samplewise_std_normalization=False,# divide each input by its std zca_whitening=False,# apply ZCA whitening rotation_range=0,# randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0,# randomly shift images horizontally (fraction of total width) height_shift_range=0,# randomly shift images vertically (fraction of total height) horizontal_flip=False,# randomly flip images vertical_flip=False,# randomly flip images noise_std=0.5# add gaussian noise to the data with std of 0.5 ) # Use the generator to transform the data during training model.fit_generator(datagen.flow(x_train, y_train, batch_size=32), steps_per_epoch=len(x_train) / 32, epochs=epochs)
目标检测:在目标检测模型的训练过程中,可以将高斯噪声添加到输入数据中,以使其对图像中的微小变化(例如光照条件、遮挡和摄像机角度)更加鲁棒。
def add_noise(image, std): """Add Gaussian noise to an image.""" noise = np.random.randn(*image.shape) * std return np.clip(image + noise, 0, 1) # Add noise to the training images x_train_noisy = np.array([add_noise(img, 0.1) for img in x_train]) # Train the model model.fit(x_train_noisy, y_train, epochs=10)
语音识别:在训练过程中,可以在音频数据中加入高斯噪声,这可以帮助模型更好地处理音频信号中的背景噪声和其他干扰,提高语音识别模型的鲁棒性。
def add_noise(audio, std): """Add Gaussian noise to an audio signal.""" noise = np.random.randn(*audio.shape) * std return audio + noise # Add noise to the training audio x_train_noisy = np.array([add_noise(audio, 0.1) for audio in x_train]) # Train the model model.fit(x_train_noisy, y_train, epochs=10)
生成模型:在 GAN、Generative Pre-training Transformer (GPT) 和 VAE 等生成模型中,可以在训练期间将高斯噪声添加到输入数据中,以提高模型生成新的、看不见的数据的能力。
# Generate random noise noise = np.random.randn(batch_size, 100) # Generate fake images fake_images = generator.predict(noise) # Add Gaussian noise to the fake images fake_images_noisy = fake_images + 0.1 * np.random.randn(*fake_images.shape) # Train the discriminator discriminator.train_on_batch(fake_images_noisy, np.zeros((batch_size, 1)))
在这个例子中,生成器被训练为基于随机噪声作为输入生成新的图像,并且在生成的图像传递给鉴别器之前,将高斯噪声添加到生成的图像中。这提高了生成器生成新的、看不见的数据的能力。
对抗训练:在对抗训练时,可以在输入数据中加入高斯噪声,使模型对对抗样本更加鲁棒。
下面的对抗训练使用快速梯度符号法(FGSM)生成对抗样本,高斯噪声为 在训练期间将它们传递给模型之前添加到对抗性示例中。 这提高了模型对对抗性示例的鲁棒性。
# Generate adversarial examples x_adv = fgsm(model, x_train, y_train, eps=0.01) # Add Gaussian noise to the adversarial examples noise_std = 0.05 x_adv_noisy = x_adv + noise_std * np.random.randn(*x_adv.shape) # Train the model model.fit(x_adv_noisy, y_train, epochs=10)
去噪:可以将高斯噪声添加到图像或信号中,模型的目标是学习去除噪声并恢复原始信号。下面的例子中输入图像“x_train”首先用标准的高斯噪声破坏 0.1 的偏差,然后将损坏的图像通过去噪自动编码器以重建原始图像。 自动编码器学习去除噪声并恢复原始信号。
# Add Gaussian noise to the images noise_std = 0.1 x_train_noisy = x_train + noise_std * np.random.randn(*x_train.shape) # Define the denoising autoencoder input_img = Input(shape=(28, 28, 1)) x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same')(x) # at this point the representation is (7, 7, 32) x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_img, decoded) autoencoder.compile(optimizer='adam', loss='binary
异常检测:高斯噪声可以添加到正常数据中,模型的目标是学习将添加的噪声作为异常检测。
# Add Gaussian noise to the normal data noise_std = 0.1 x_train_noisy = x_train + noise_std * np.random.randn(*x_train.shape) # Concatenate the normal and the noisy data x_train_concat = np.concatenate((x_train, x_train_noisy)) y_train_concat = np.concatenate((np.zeros(x_train.shape[0]), np.ones(x_train_noisy.shape[0]))) # Train the anomaly detection model model.fit(x_train_concat, y_train_concat, epochs=10)
稳健优化:在优化过程中,可以将高斯噪声添加到模型的参数中,使其对参数中的小扰动更加稳健。
Define the loss function def loss_fn(params): model.set_weights(params) return model.evaluate(x_test, y_test, batch_size=32)[0] # Define the optimizer optimizer = optimizers.Adam(1e-3) # Define the step function def step_fn(params): with tf.GradientTape() as tape: loss = loss_fn(params) grads = tape.gradient(loss, params) optimizer.apply_gradients(zip(grads, params)) return params + noise_std * np.random.randn(*params.shape) # Optimize the model params = model.get_weights()
高斯噪声是深度学习中用于为输入数据或权重添加随机性的一种技术。 它是一种通过将均值为零且标准差 (σ) 正态分布的随机值添加到输入数据中而生成的随机噪声。 向数据中添加噪声的目的是使模型对输入中的小变化更健壮,并且能够更好地处理看不见的数据。 高斯噪声可用于广泛的应用,例如图像分类、对象检测、语音识别、生成模型和稳健优化。
Das obige ist der detaillierte Inhalt vonGaußsches Rauschen beim Deep Learning: Warum und wie man es nutzt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 mybatis First-Level-Cache und Second-Level-Cache
mybatis First-Level-Cache und Second-Level-Cache
 So verwenden Sie Oracleparameter
So verwenden Sie Oracleparameter
 Lösung für fehlende xlive.dll
Lösung für fehlende xlive.dll
 Was ist eine 3c-Zertifizierung?
Was ist eine 3c-Zertifizierung?
 Wie viel kostet ein Bitcoin in RMB?
Wie viel kostet ein Bitcoin in RMB?
 So öffnen Sie eine IMG-Datei
So öffnen Sie eine IMG-Datei
 Können Daten zwischen dem Hongmeng-System und dem Android-System interoperabel sein?
Können Daten zwischen dem Hongmeng-System und dem Android-System interoperabel sein?
 C#-Tutorial
C#-Tutorial








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



