


Heute sind Transformer zu Schlüsselmodulen in den fortschrittlichsten Architekturen für die Verarbeitung natürlicher Sprache (NLP) und Computer Vision (CV) geworden. Der Bereich der Tabellendaten wird jedoch immer noch von GBDT-Algorithmen (Gradient Boosted Decision Tree) dominiert. Es gab also Versuche, diese Lücke zu schließen. Unter ihnen ist das erste konverterbasierte tabellarische Datenmodellierungspapier das von Huang et al. im Jahr 2020 veröffentlichte Papier „TabTransformer: Tabular Data Modeling Using Context Embedding“.
Dieser Artikel soll eine grundlegende Darstellung des Inhalts des Papiers bieten. Außerdem wird er auf die Implementierungsdetails des TabTransformer-Modells eingehen und Ihnen zeigen, wie Sie es verwenden speziell für unsere eigenen Daten.
Die Hauptidee des oben genannten Papiers besteht darin, dass ein Konverter verwendet wird, um eine reguläre kategorische Einbettung in eine kontextuelle Einbettung, dann wird die Leistung herkömmlicher mehrschichtiger Perzeptrone (MLP) deutlich verbessert. Als nächstes wollen wir diese Beschreibung genauer verstehen.
In Deep-Learning-Modellen werden kategoriale Funktionen verwendet Trainieren Sie die Einbettung. Dies bedeutet, dass jeder Kategoriewert eine eindeutige dichte Vektordarstellung hat und an die nächste Ebene übergeben werden kann. Aus dem Bild unten können Sie beispielsweise ersehen, dass jedes kategoriale Merkmal durch ein vierdimensionales Array dargestellt wird. Diese Einbettungen werden dann mit numerischen Merkmalen verkettet und als Eingabe für das MLP verwendet. 2. Kontextuelle Einbettungen
Der Autor des Artikels ist der Ansicht, dass kategoriale Einbettungen keine kontextbezogene Bedeutung haben, das heißt, sie führen keine Interaktions- und Beziehungsinformationen zwischen der Kodierung kategorialer Variablen durch. Um den eingebetteten Inhalt konkreter zu machen, wurde vorgeschlagen, zu diesem Zweck derzeit im NLP-Bereich verwendete Transformatoren zu verwenden. 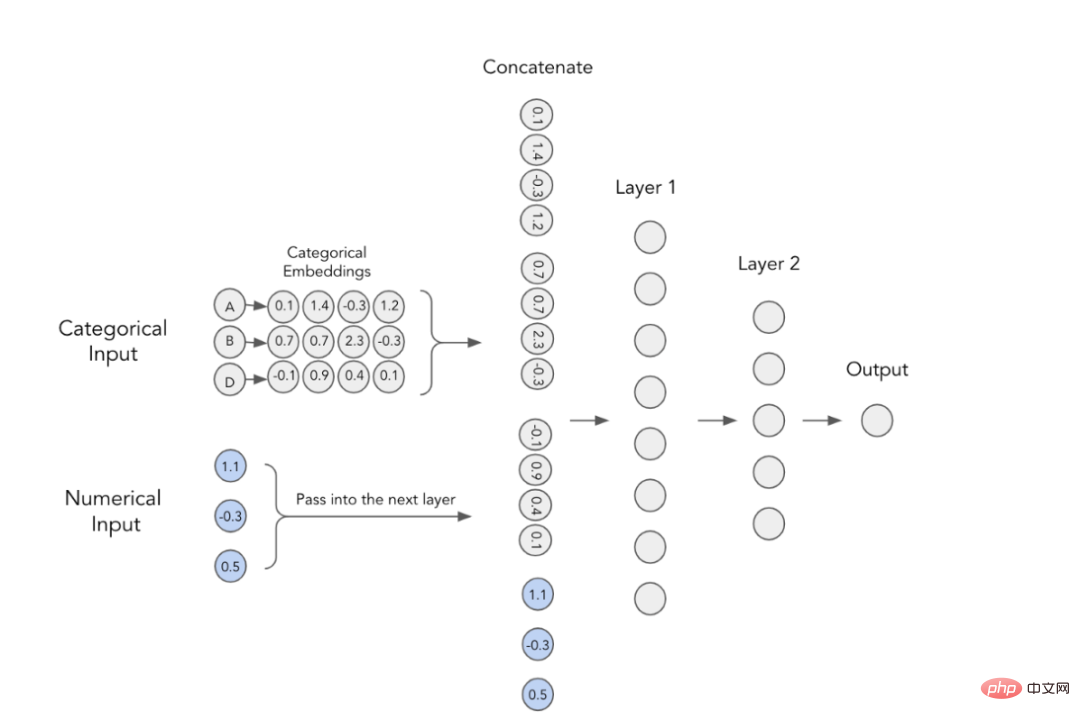
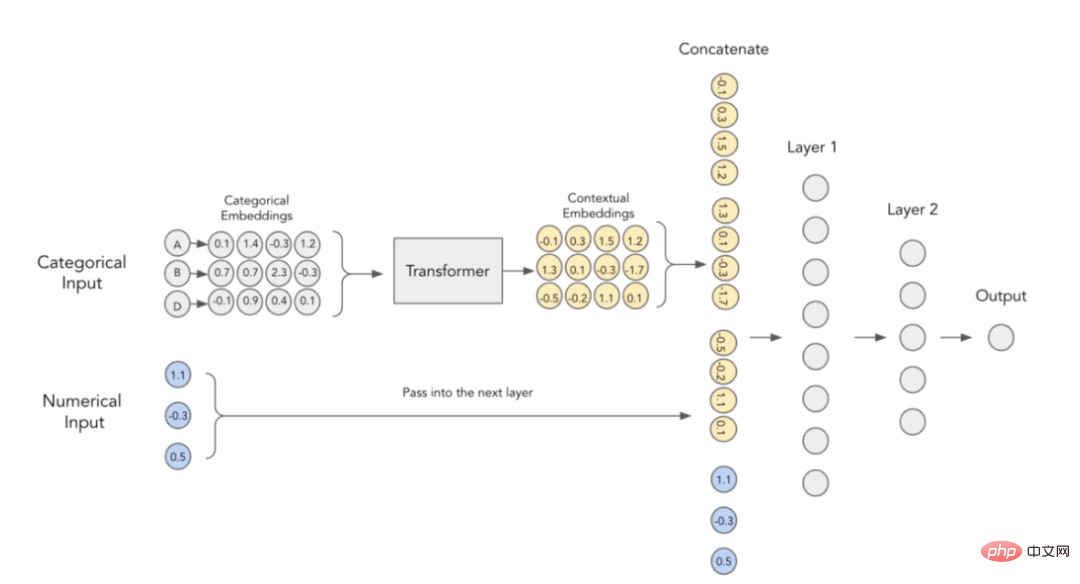
Um den oben genannten Zweck zu erreichen, schlug der Autor des Papiers vor die folgende Architektur: #🎜 🎜#
TabTransformer-Konverter-Architekturdiagramm
(Auszug aus Huang et al . 2020 Paper) 
Numerische Merkmale normalisieren und weiterleiten
Die Einbettungen werden von N Transformatorblöcken verarbeitet, um kontextbezogene Einbettungen zu erhalten
Kategorie die Kontext Einbettungen werden mit numerischen Merkmalen verkettet , Die Autoren des Papiers sagen, dass das Hinzufügen einer Konverterschicht die Rechenleistung erheblich verbessern kann. Natürlich geschieht die ganze „Magie“ innerhalb dieser Konverterblöcke. Schauen wir uns also die Implementierung genauer an.
4.Converter (Transformer) Architekturdiagramm 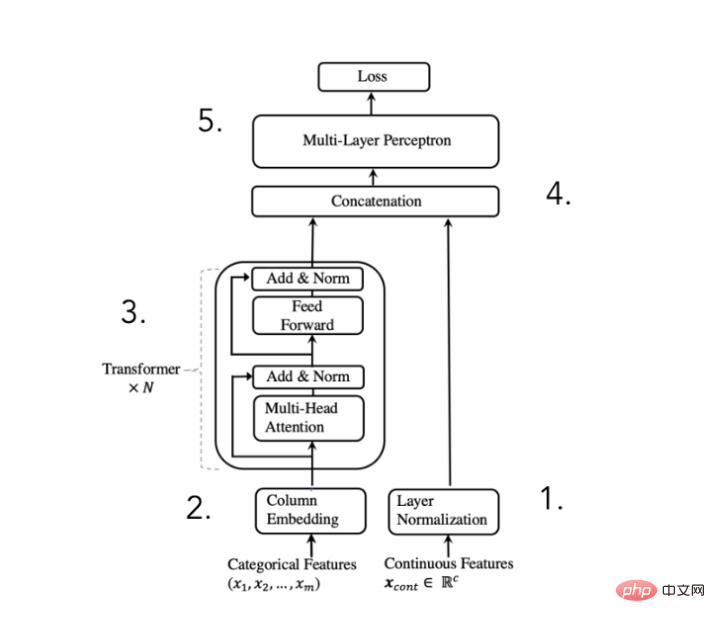
# 🎜🎜#
Vielleicht haben Sie die Transformatorarchitektur schon einmal gesehen, aber für eine schnelle Einführung denken Sie daran, dass der Konverter aus einem Encoder und einem Decoder besteht (siehe Bild oben). Für TabTransformer kümmern wir uns nur um den Encoder-Teil, der die Eingabeeinbettungen kontextualisiert (der Decoder-Teil wandelt diese Einbettungen in das endgültige Ausgabeergebnis um). Aber wie genau wird das gemacht? Die Antwort lautet: Mehrkopf-Aufmerksamkeitsmechanismus.
5. Mehrkopf-Aufmerksamkeitsmechanismus
Um eine Beschreibung aus meinem Lieblingsartikel über Aufmerksamkeitsmechanismen zu zitieren, lautet sie so:
„Das Schlüsselkonzept hinter der Selbstaufmerksamkeit besteht darin, dass dieser Mechanismus es einem neuronalen Netzwerk ermöglicht, zu lernen, wie es auf einzelne Teile einer Eingabesequenz reagiert. Informationsplanung mit dem besten Routing-Schema zwischen ihnen. „
Mit anderen Worten: Die Selbstaufmerksamkeit hilft dem Modell herauszufinden, welche Teile der Eingabe wichtiger sind, wenn es ein bestimmtes Wort/eine bestimmte Kategorie darstellt. Zu diesem Zweck empfehle ich dringend, den oben genannten Artikel zu lesen, um ein intuitiveres Verständnis dafür zu erlangen, warum Selbstfokussierung so effektiv ist. „Mehrkopf-Aufmerksamkeitsmechanismus“ Abfrage), Schlüssel (Key) und Wert (Value). Zuerst multiplizieren wir die Matrizen Q und K, um die Aufmerksamkeitsmatrix zu erhalten. Diese Matrix wird skaliert und durch die Softmax-Schicht geleitet. Anschließend multiplizieren wir dies mit der V-Matrix, um den Endwert zu erhalten. Betrachten Sie für ein intuitiveres Verständnis das folgende Schema, das zeigt, wie wir die Transformation von der Eingabeeinbettung zur Kontexteinbettung mithilfe der Matrizen Q, K und V implementieren.
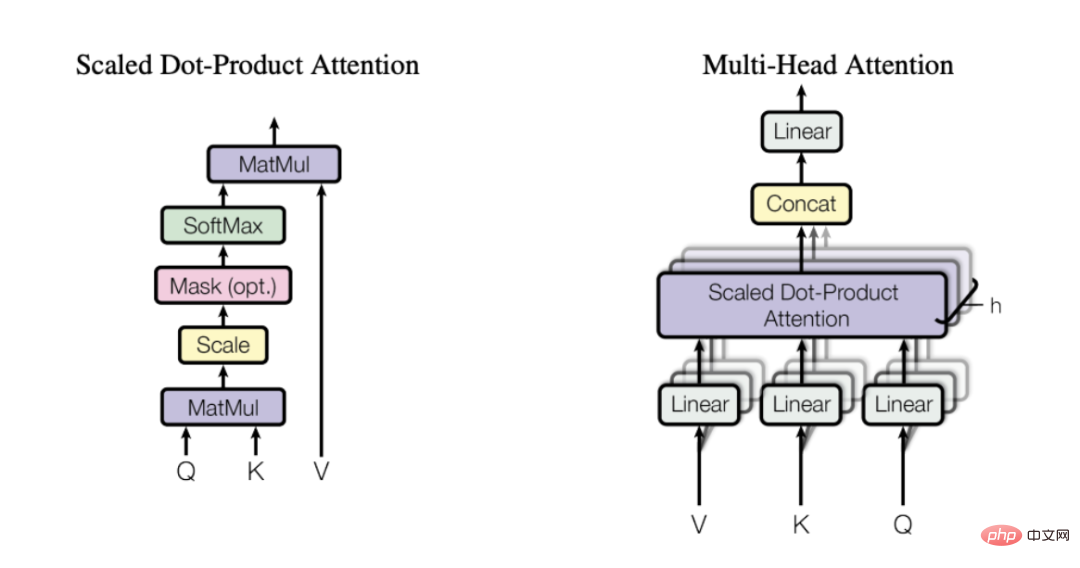
Visualisierung des Selbstaufmerksamkeitsprozesses
Indem wir diesen Vorgang h-mal wiederholen (unter Verwendung verschiedener Q-, K-, V-Matrizen), können wir mehrere Kontexteinbettungen erhalten, die unseren endgültigen Mehrkopf bilden Aufmerksamkeit .
6. Kurzer Rückblick
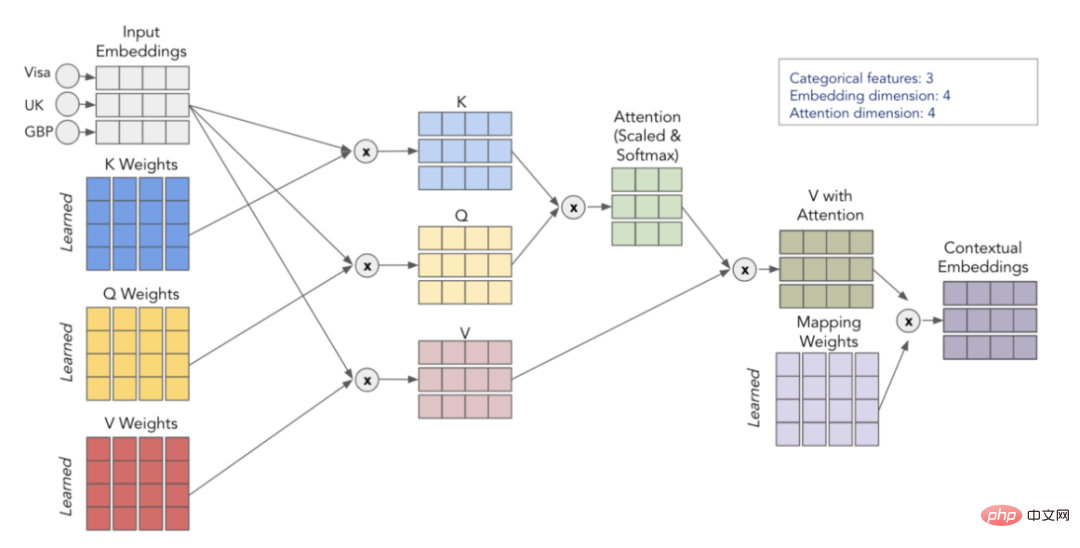
Einfache kategoriale Einbettungen enthalten keine Kontextinformationen
Indem wir die kategorialen Einbettungen durch den Transformer-Encoder übergeben, können wir die Kontextualisierung einbetten
Der Multi-Head-Aufmerksamkeitsmechanismus verwendet die Matrizen Q, K und V, um nützliche Interaktions- und Korrelationsinformationen beim Codieren von Variablen zu finden.
In TabTransformer kontextualisiert Einbettungen werden mit numerischen Eingaben verkettet und durch eine einfache MLP-Ausgabe vorhergesagt
pip install tabtransformertf
from tabtransformertf.utils.preprocessing import df_to_dataset, build_categorical_prep # 设置数据类型 train_data[CATEGORICAL_FEATURES] = train_data[CATEGORICAL_FEATURES].astype(str) val_data[CATEGORICAL_FEATURES] = val_data[CATEGORICAL_FEATURES].astype(str) train_data[NUMERIC_FEATURES] = train_data[NUMERIC_FEATURES].astype(float) val_data[NUMERIC_FEATURES] = val_data[NUMERIC_FEATURES].astype(float) # 转换成TF数据集 train_dataset = df_to_dataset(train_data[FEATURES + [LABEL]], LABEL, batch_size=1024) val_dataset = df_to_dataset(val_data[FEATURES + [LABEL]], LABEL, shuffle=False, batch_size=1024)
from tabtransformertf.utils.preprocessing import build_categorical_prep
category_prep_layers = build_categorical_prep(train_data, CATEGORICAL_FEATURES)
# 输出结果是一个字典结构,其中键部分是特征名称,值部分是StringLookup层
# category_prep_layers ->
# {'product_code': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05d28ee4e0>,
#'attribute_0': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4fb908>,
#'attribute_1': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4da5f8>}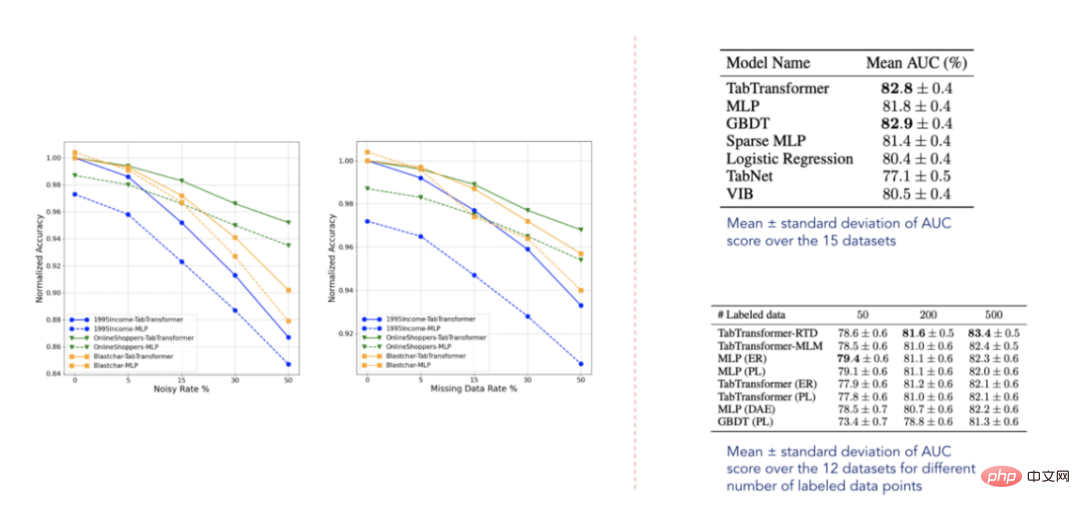
Das ist Vorverarbeitung! Jetzt können wir mit dem Aufbau des Modells beginnen.
2. Erstellen Sie das TabTransformer-Modell
from tabtransformertf.models.tabtransformer import TabTransformer tabtransformer = TabTransformer( numerical_features = NUMERIC_FEATURES,# 带有数字特征名称的列表 categorical_features = CATEGORICAL_FEATURES, # 带有分类特征名称的列表 categorical_lookup=category_prep_layers, # 带StringLookup层的Dict numerical_discretisers=None,# None代表我们只是简单地传递数字特征 embedding_dim=32,# 嵌入维数 out_dim=1,# Dimensionality of output (binary task) out_activatinotallow='sigmoid',# 输出层激活 depth=4,# 转换器块层的个数 heads=8,# 转换器块中注意力头的个数 attn_dropout=0.1,# 在转换器块中的丢弃率 ff_dropout=0.1,# 在最后MLP中的丢弃率 mlp_hidden_factors=[2, 4],# 我们为每一层划分最终嵌入的因子 use_column_embedding=True,#如果我们想使用列嵌入,设置此项为真 ) # 模型运行中摘要输出: # 总参数个数: 1,778,884 # 可训练的参数个数: 1,774,064 # 不可训练的参数个数: 4,820
Nachdem das Modell initialisiert wurde, können wir es wie jedes andere Keras-Modell installieren. Auch die Trainingsparameter sind einstellbar, sodass Lerngeschwindigkeit und frühes Stoppen nach Belieben angepasst werden können.
LEARNING_RATE = 0.0001 WEIGHT_DECAY = 0.0001 NUM_EPOCHS = 1000 optimizer = tfa.optimizers.AdamW( learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY ) tabtransformer.compile( optimizer = optimizer, loss = tf.keras.losses.BinaryCrossentropy(), metrics= [tf.keras.metrics.AUC(name="PR AUC", curve='PR')], ) out_file = './tabTransformerBasic' checkpoint = ModelCheckpoint( out_file, mnotallow="val_loss", verbose=1, save_best_notallow=True, mode="min" ) early = EarlyStopping(mnotallow="val_loss", mode="min", patience=10, restore_best_weights=True) callback_list = [checkpoint, early] history = tabtransformer.fit( train_dataset, epochs=NUM_EPOCHS, validation_data=val_dataset, callbacks=callback_list )
3. Bewertung
Der kritischste Indikator im Wettbewerb ist ROC AUC. Geben wir es also zusammen mit der PR-AUC-Metrik aus, um die Leistung des Modells zu bewerten.
val_preds = tabtransformer.predict(val_dataset)
print(f"PR AUC: {average_precision_score(val_data['isFraud'], val_preds.ravel())}")
print(f"ROC AUC: {roc_auc_score(val_data['isFraud'], val_preds.ravel())}")
# PR AUC: 0.26
# ROC AUC: 0.58您也可以自己给测试集评分,然后将结果值提交给Kaggle官方。我现在选择的这个解决方案使我跻身前35%,这并不坏,但也不太好。那么,为什么TabTransfromer在上述方案中表现不佳呢?可能有以下几个原因:
本文探讨了TabTransformer背后的主要思想,并展示了如何使用Tabtransformertf包来具体应用此转换器。
归纳起来看,TabTransformer的确是一种有趣的体系结构,它在当时的表现明显优于大多数深度表格模型。它的主要优点是将分类嵌入语境化,从而增强其表达能力。它使用在分类特征上的多头注意力机制来实现这一点,而这是在表格数据领域使用转换器的第一个应用实例。
TabTransformer体系结构的一个明显缺点是,数字特征被简单地传递到最终的MLP层。因此,它们没有语境化,它们的价值也没有在分类嵌入中得到解释。在下一篇文章中,我将探讨如何修复此缺陷并进一步提高性能。
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文链接:https://towardsdatascience.com/transformers-for-tabular-data-tabtransformer-deep-dive-5fb2438da820?source=collection_home---------4----------------------------
Das obige ist der detaillierte Inhalt vonDer TabTransformer-Konverter verbessert die Leistung von mehrschichtigen Perzeptronen und führt eine eingehende Analyse durch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



