


In diesem Tutorial führen wir Sie durch den Prozess der Verpackung Ihres ML-Modells als Docker-Container und der Bereitstellung auf dem Serverless-Computing-Dienst AWS Lambda.
Am Ende dieses Tutorials verfügen Sie über ein funktionierendes ML-Modell, das über die API aufgerufen werden kann, und Sie verfügen über ein tieferes Verständnis für die Bereitstellung von ML-Modellen in der Cloud. Unabhängig davon, ob Sie ein Ingenieur für maschinelles Lernen, Datenwissenschaftler oder Entwickler sind, ist dieses Tutorial so konzipiert, dass es für jeden zugänglich ist, der über grundlegende Kenntnisse von ML und Docker verfügt. Also, fangen wir an!
Docker ist ein Tool, das das Erstellen, Bereitstellen und Ausführen von Anwendungen mithilfe von Containern erleichtern soll. Container ermöglichen es Entwicklern, eine Anwendung zusammen mit allen benötigten Teilen, wie Bibliotheken und anderen Abhängigkeiten, zu verpacken und als ein Paket zu versenden. Durch die Verwendung von Containern können Entwickler sicherstellen, dass ihre Anwendungen auf jedem anderen Computer ausgeführt werden, unabhängig von benutzerdefinierten Einstellungen des Computers, die sich möglicherweise von denen des Computers unterscheiden, der zum Schreiben und Testen des Codes verwendet wird. Docker bietet eine Möglichkeit, Anwendungen und ihre Abhängigkeiten in leichte, tragbare Container zu packen, die problemlos von einer Umgebung in eine andere verschoben werden können. Dies erleichtert die Erstellung konsistenter Entwicklungs-, Test- und Produktionsumgebungen sowie die schnellere und zuverlässigere Bereitstellung von Anwendungen. Installieren Sie Docker von hier aus: https://docs.docker.com/get-docker/.
Amazon Web Services (AWS) Lambda ist eine serverlose Computerplattform, die Code als Reaktion auf Ereignisse ausführt und die zugrunde liegenden Computerressourcen automatisch für Sie verwaltet. Dabei handelt es sich um einen von AWS bereitgestellten Dienst, der es Entwicklern ermöglicht, ihren Code in der Cloud auszuführen, ohne sich um die für die Ausführung des Codes erforderliche Infrastruktur kümmern zu müssen. AWS Lambda skaliert Ihre Anwendung automatisch als Reaktion auf eingehenden Anforderungsverkehr und Sie zahlen nur für die Rechenzeit, die Sie verbrauchen. Dies macht es zu einer attraktiven Wahl für den Aufbau und Betrieb von Microservices, Echtzeit-Datenverarbeitung und ereignisgesteuerten Anwendungen.
Amazon Web Services (AWS) Elastic Container Registry (ECR) ist eine vollständig verwaltete Docker-Container-Registrierung, die es Entwicklern ermöglicht, Docker-Container-Images einfach zu speichern, zu verwalten und bereitzustellen. Es handelt sich um einen sicheren und skalierbaren Dienst, der es Entwicklern ermöglicht, Docker-Images in der AWS-Cloud zu speichern und zu verwalten und sie einfach im Amazon Elastic Container Service (ECS) oder anderen cloudbasierten Container-Orchestrierungsplattformen bereitzustellen. ECR lässt sich in andere AWS-Dienste wie Amazon ECS und Amazon EKS integrieren und bietet native Unterstützung für die Docker-Befehlszeilenschnittstelle (CLI). Dies macht es einfach, vertraute Docker-Befehle zu verwenden, um Docker-Images aus ECR zu pushen und zu ziehen und den Prozess des Erstellens, Testens und Bereitstellens von Containeranwendungen zu automatisieren.
Verwenden Sie dies, um die AWS CLI auf Ihrem System zu installieren. Erhalten Sie die AWS-Zugriffsschlüssel-ID und den geheimen AWS-Zugriffsschlüssel, indem Sie in Ihrem AWS-Konto einen IAM-Benutzer erstellen. Führen Sie nach der Installation den folgenden Befehl aus, um Ihre AWS CLI zu konfigurieren und die erforderlichen Felder einzufügen.
aws configure
In diesem Tutorial werden wir das OpenAI-Clip-Modell bereitstellen, um Eingabetext zu vektorisieren. Die Lambda-Funktion erfordert Amazon Linux 2 in einem Docker-Container, daher verwenden wir
public.ecr.aws/lambda/python:3.8. Da Lambda außerdem über ein schreibgeschütztes Dateisystem verfügt, ist es uns nicht möglich, Modelle intern herunterzuladen, sodass wir sie beim Erstellen des Images herunterladen und kopieren müssen.
Holen Sie sich hier den Arbeitscode und extrahieren Sie ihn.
Ändern Sie das Arbeitsverzeichnis, in dem sich die Docker-Datei befindet, und führen Sie den folgenden Befehl aus:
docker build -t lambda_image .
Jetzt haben wir das Image für die Bereitstellung auf Lambda bereit. Um es lokal zu überprüfen, führen Sie den Befehl aus:
docker run -p 9000:8080 lambda_image
Um es zu überprüfen, senden Sie ihm eine Curl-Anfrage und es sollte einen Vektor des Eingabetextes zurückgeben:
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"text": "This is a test for text encoding"}'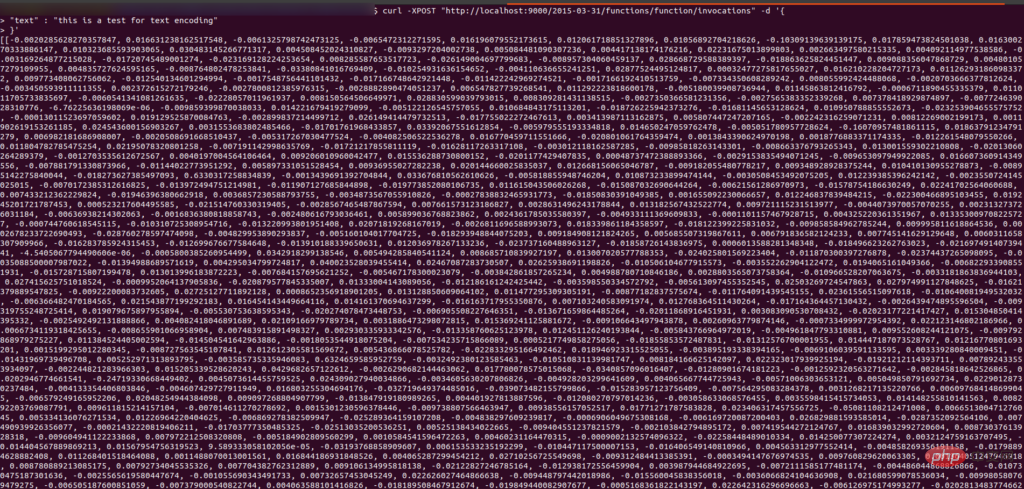
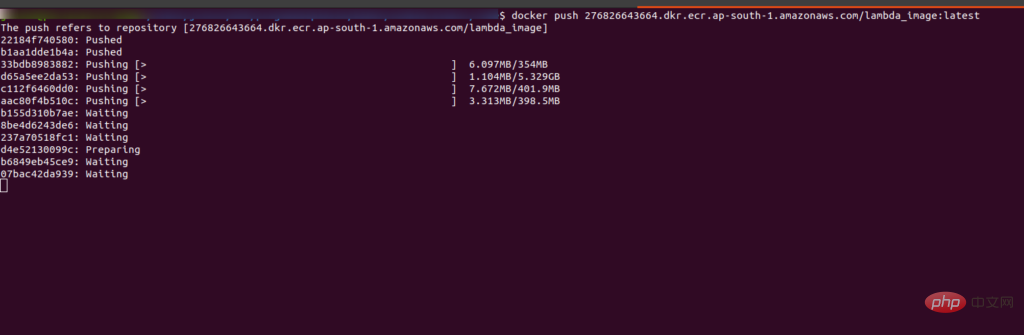
运行最后一条命令将镜像推送到 ECR 中。运行后你会看到界面是这样的:
推送完成后,您将在 ECR 的存储库中看到带有“:latest”标签的图像。
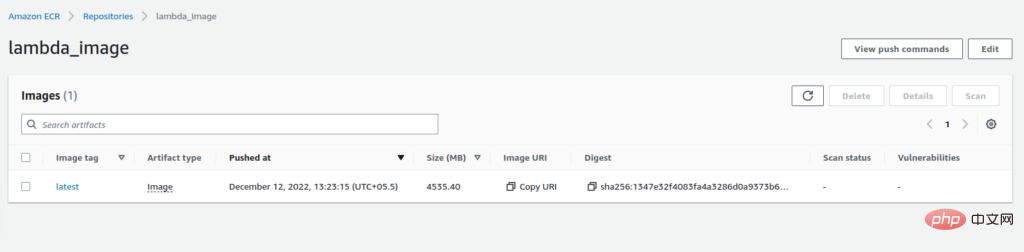
复制图像的 URI。我们在创建 Lambda 函数时需要它。
现在转到 Lambda 函数并单击“创建函数”选项。我们正在从图像创建一个函数,因此选择容器图像的选项。添加函数名称并粘贴我们从 ECR 复制的 URI,或者您也可以浏览图像。选择architecture x84_64,最后点击create_image选项。
构建 Lambda 函数可能需要一些时间,请耐心等待。执行成功后,你会看到如下界面:

Lambda 函数默认有 3 秒的超时限制和 128 MB 的 RAM,所以我们需要增加它,否则它会抛出错误。为此,请转到配置选项卡并单击“编辑”。
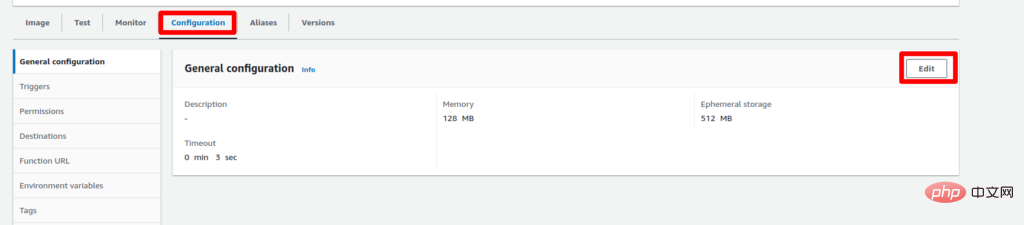
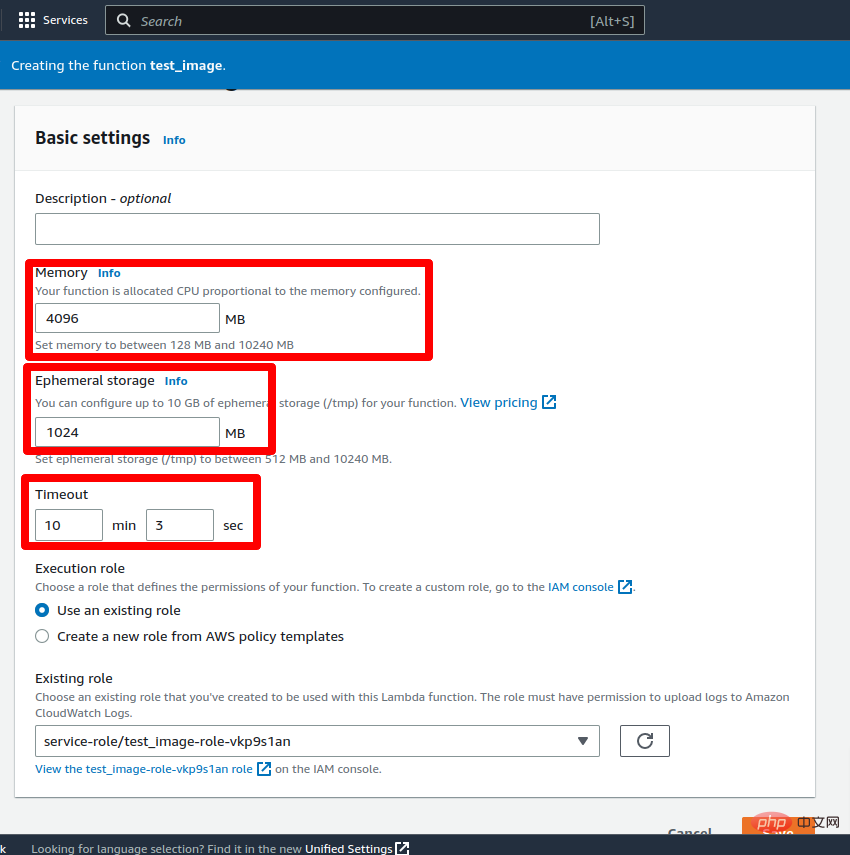
现在将超时设置为 5-10 分钟(最大限制为 15 分钟)并将 RAM 设置为 2-3 GB,然后单击保存按钮。更新 Lambda 函数的配置需要一些时间。
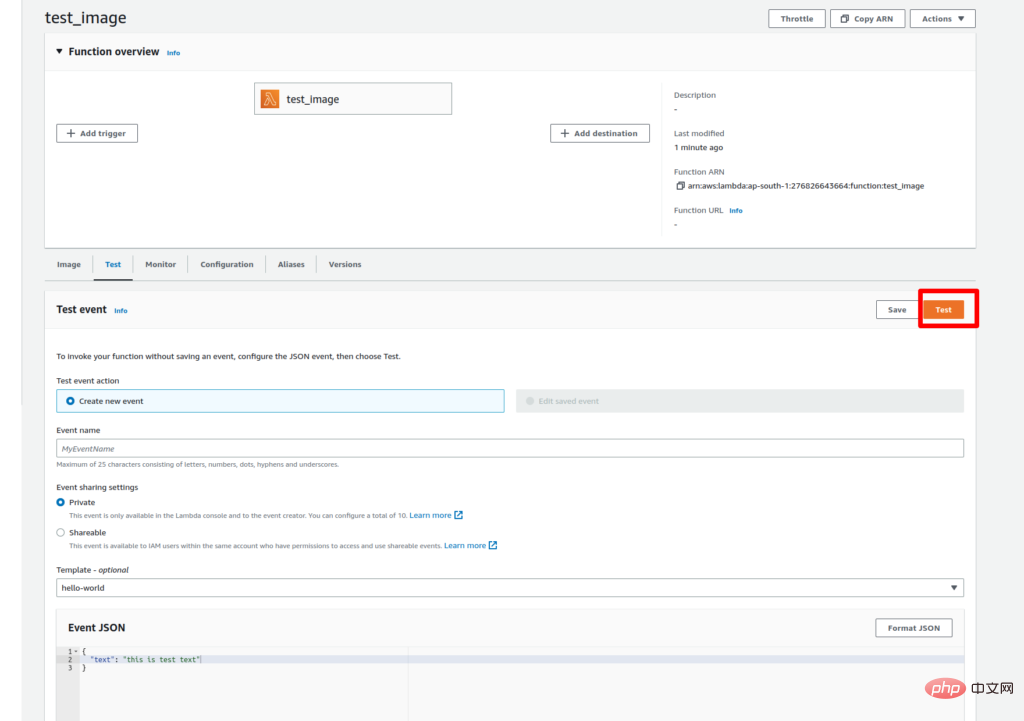
更新更改后,该功能就可以进行测试了。要测试 lambda 函数,请转到“测试”选项卡并将键值添加到事件 JSON 中作为文本:“这是文本编码测试。” 然后点击测试按钮。
由于我们是第一次执行 Lambda 函数,因此执行可能需要一些时间。成功执行后,您将在执行日志中看到输入文本的向量。
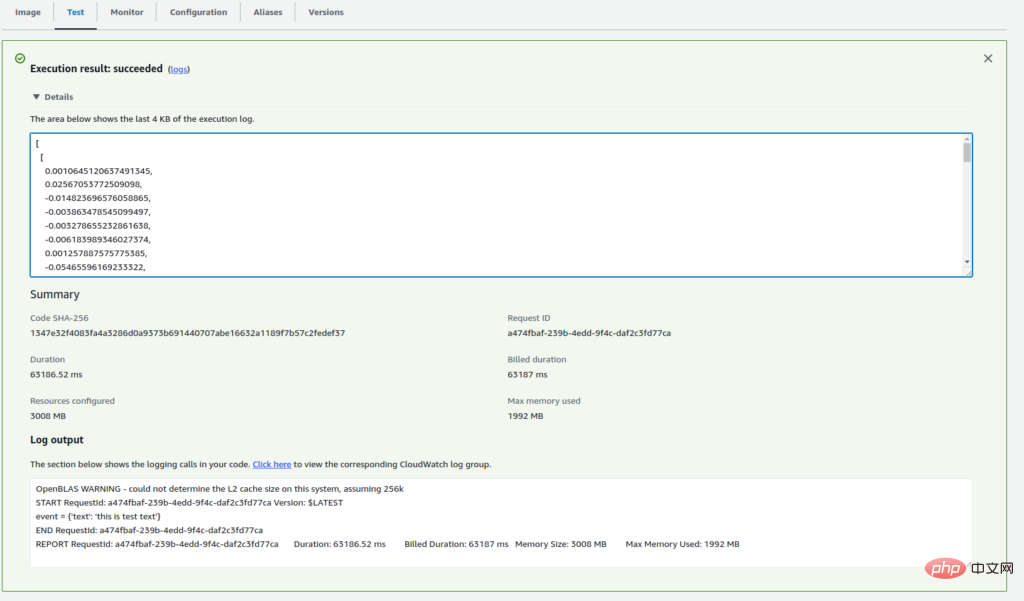
现在我们的 Lambda 函数已部署并正常工作。要通过 API 访问它,我们需要创建一个函数 URL。
要为 Lambda 函数创建 URL,请转到 Configuration 选项卡并选择 Function URL 选项。然后单击创建函数 URL 选项。

现在,保留身份验证 None 并单击 Save。
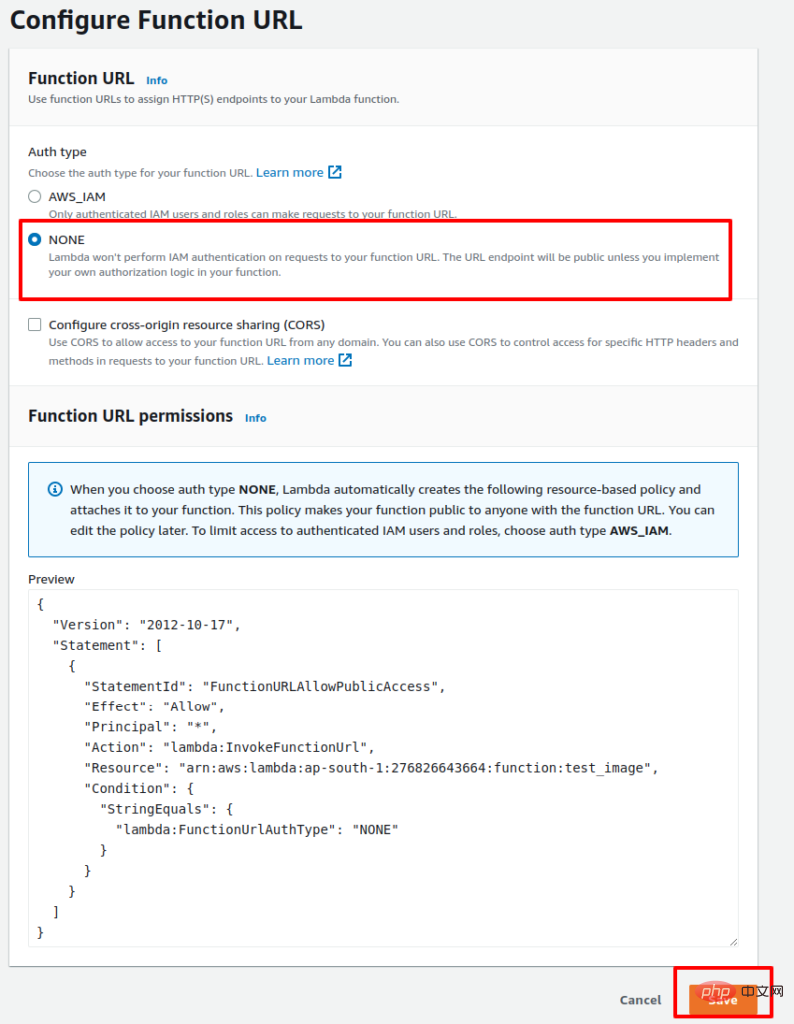
该过程完成后,您将获得用于通过 API 访问 Lambda 函数的 URL。以下是使用 API 访问 Lambda 函数的示例 Python 代码:
import requests function_url = ""url = f"{function_url}?text=this is test text" payload={}headers = {} response = requests.request("GET", url, headers=headers, data=payload) print(response.text)成功执行代码后,您将获得输入文本的向量。

所以这是一个如何使用 Docker 在 AWS Lambda 上部署 ML 模型的示例。如果您有任何疑问,请告诉我们。
Das obige ist der detaillierte Inhalt vonSo stellen Sie Modelle für maschinelles Lernen auf AWS Lambda mit Docker bereit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Unterschied zwischen k8s und Docker
Der Unterschied zwischen k8s und Docker
 Mit welchen Methoden kann Docker in den Container gelangen?
Mit welchen Methoden kann Docker in den Container gelangen?
 Was soll ich tun, wenn der Docker-Container nicht auf das externe Netzwerk zugreifen kann?
Was soll ich tun, wenn der Docker-Container nicht auf das externe Netzwerk zugreifen kann?
 Wozu dient das Docker-Image?
Wozu dient das Docker-Image?
 Wie kann man Douyin-Flammen wiederherstellen, nachdem sie verschwunden sind?
Wie kann man Douyin-Flammen wiederherstellen, nachdem sie verschwunden sind?
 Welche Versionen des Linux-Systems gibt es?
Welche Versionen des Linux-Systems gibt es?
 Lösung für den Failedtofetch-Fehler
Lösung für den Failedtofetch-Fehler
 Was ist der Unterschied zwischen Legacy und UEFI?
Was ist der Unterschied zwischen Legacy und UEFI?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



