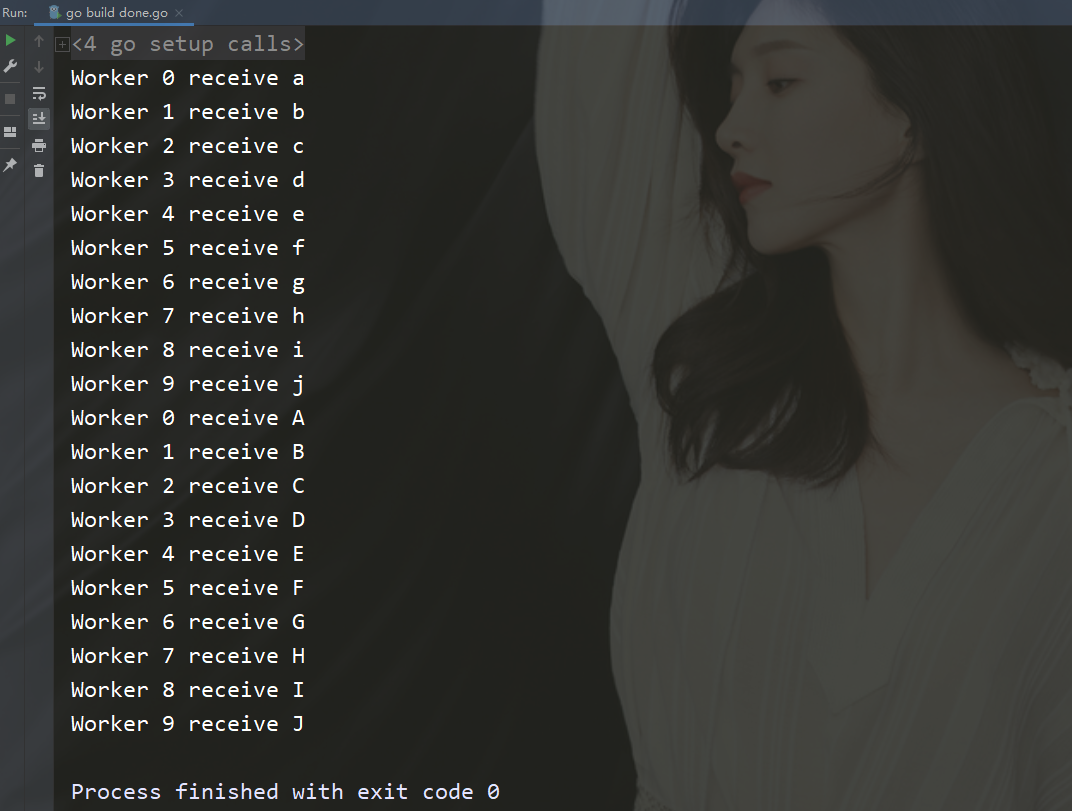
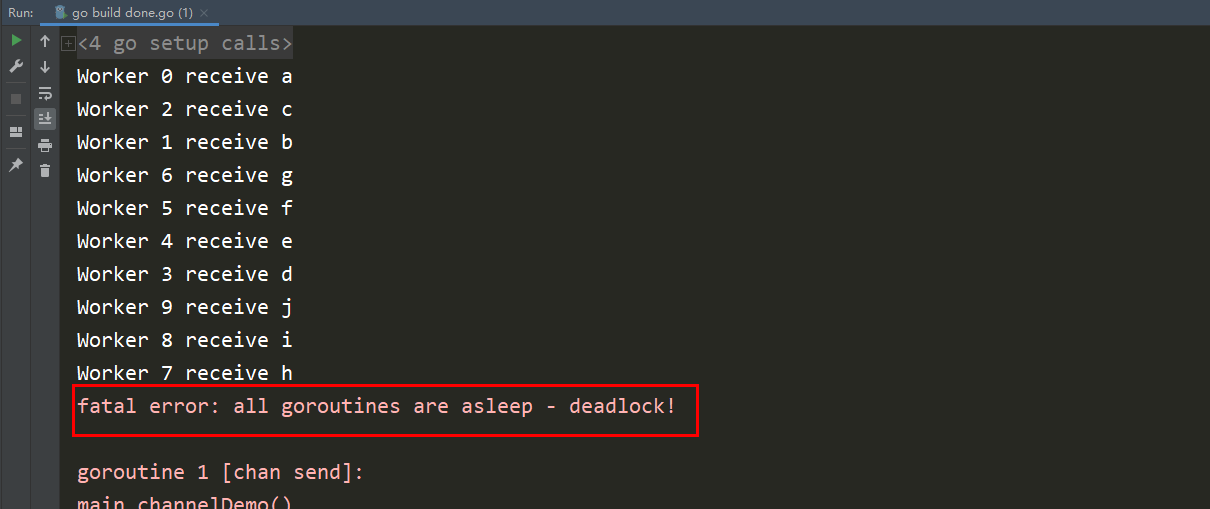
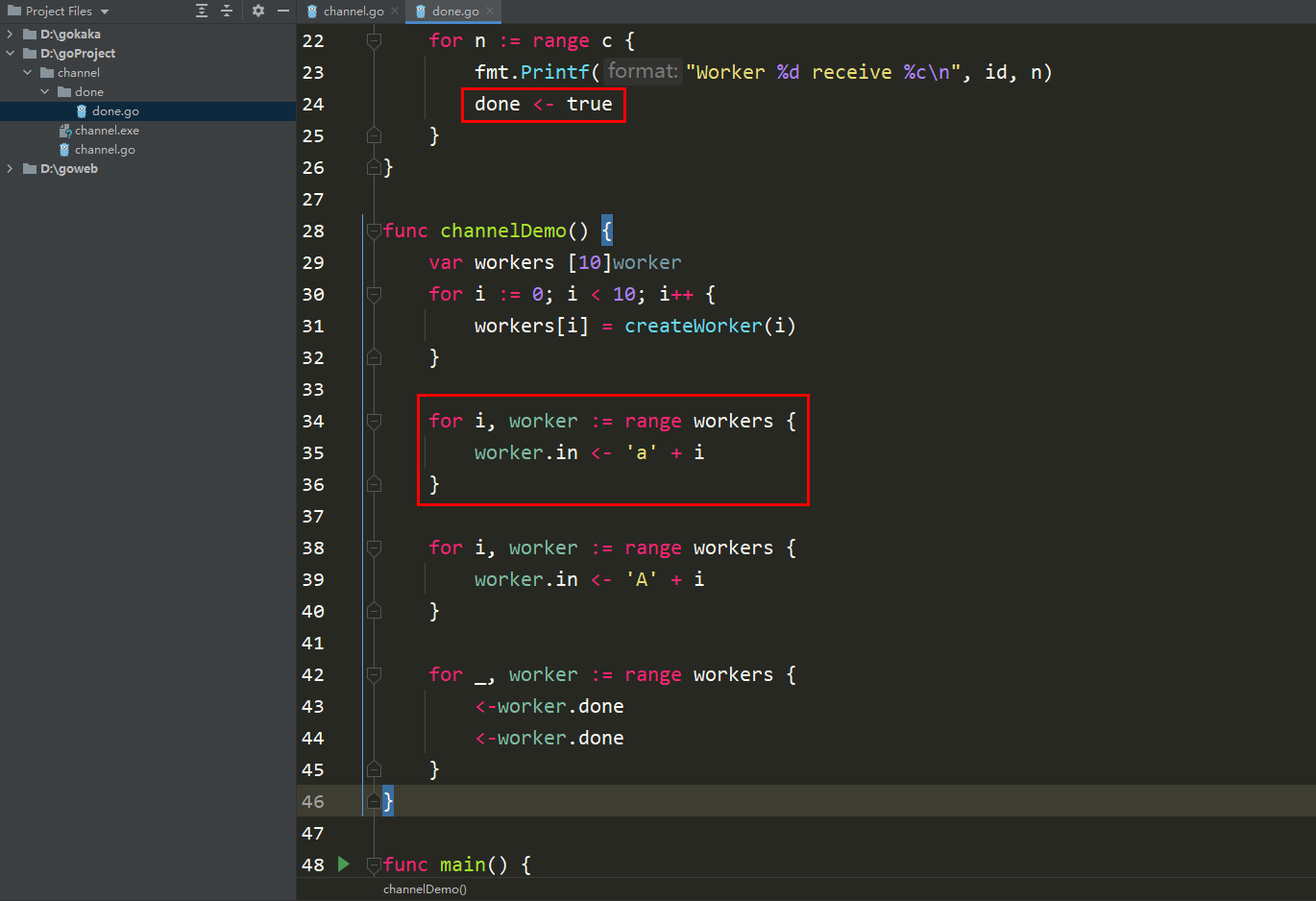
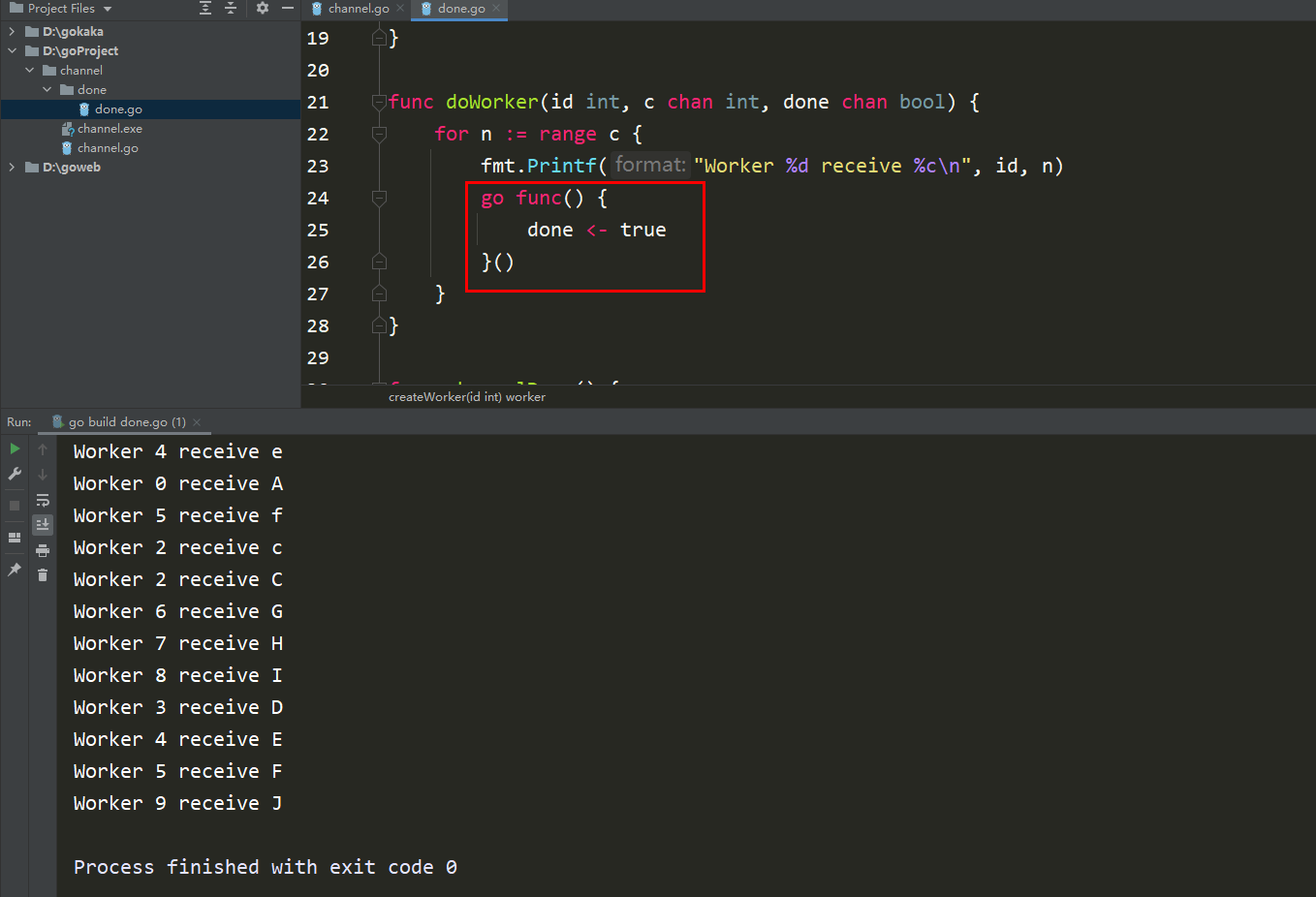
Der Anwendungsfall Im ersten Artikel befindet sich noch der in Abschnitt 2 geschriebene Code, hier ist jedoch nur ein Absatz erforderlich.
package mainimport ( "fmt" "time")func createWorker(id int) chan
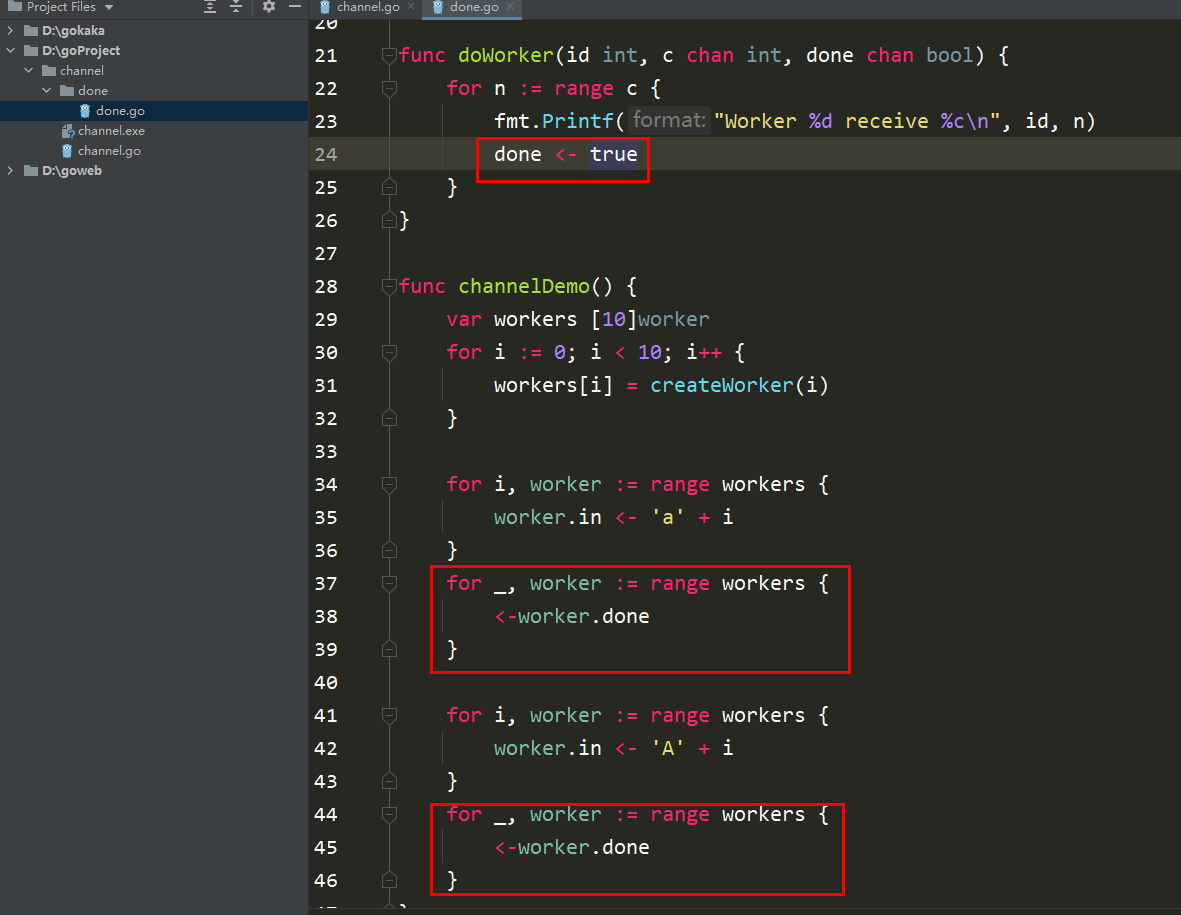
package mainimport ( "fmt")type worker struct { in chan int done chan bool}func createWorker(id int) worker { w := worker{ in: make(chan int), done: make(chan bool), } go doWorker(id, w.in, w.done) return w}func doWorker(id int, c chan int, done chan bool) { for n := range c { fmt.Printf("Worker %d receive %c\n", id, n) done
package mainimport ( "fmt")type worker struct { in chan int done chan bool}func createWorker(id int) worker { w := worker{ in: make(chan int), done: make(chan bool), } go doWorker(id, w.in, w.done) return w}func doWorker(id int, c chan int, done chan bool) { for n := range c { fmt.Printf("Worker %d receive %c\n", id, n) done
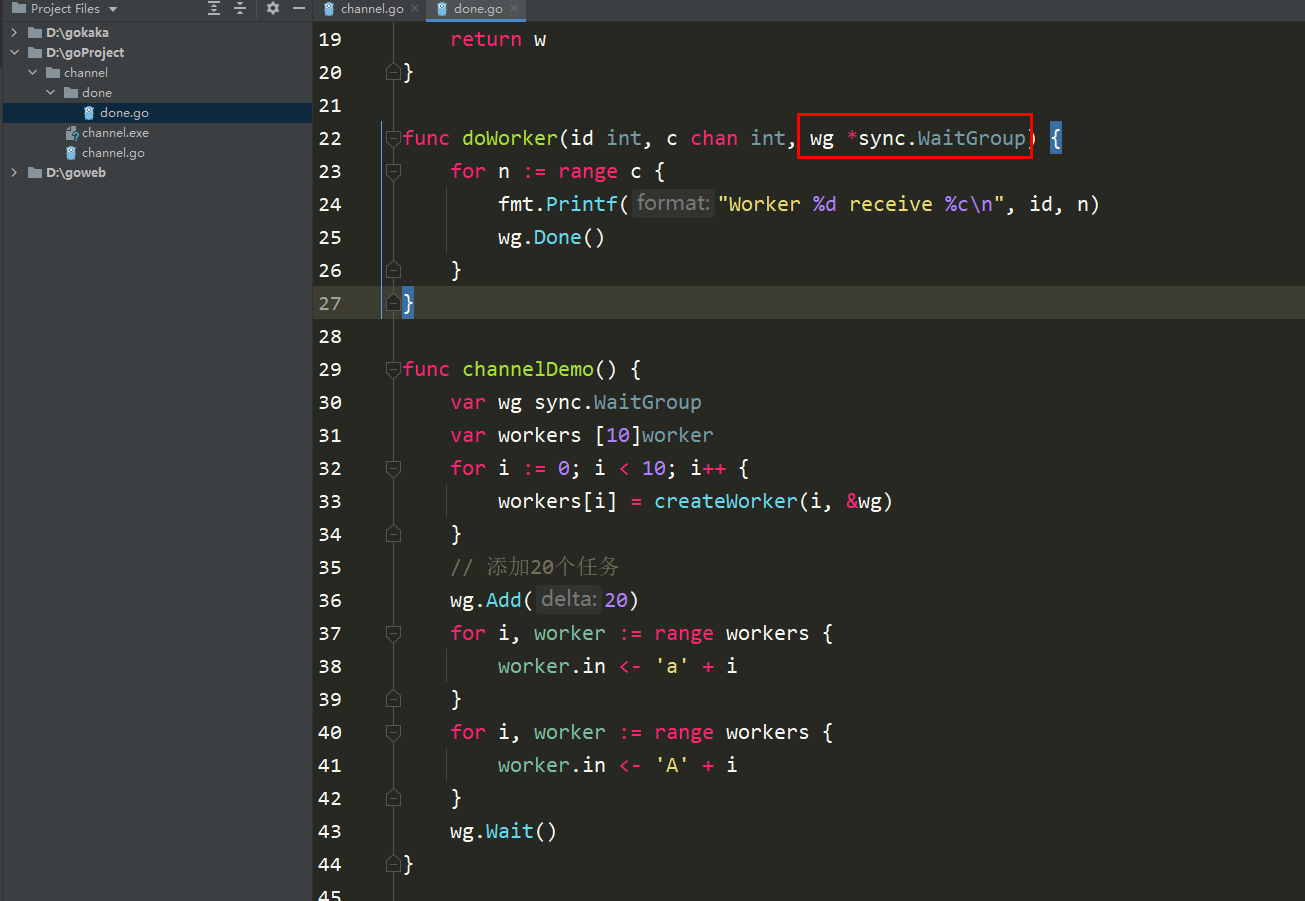
package mainimport ( "fmt" "sync")type worker struct { in chan int wg *sync.WaitGroup}func createWorker(id int, wg *sync.WaitGroup) worker { w := worker{ in: make(chan int), wg: wg, } go doWorker(id, w.in, wg) return w}func doWorker(id int, c chan int, wg *sync.WaitGroup) { for n := range c { fmt.Printf("Worker %d receive %c\n", id, n) wg.Done() }}func channelDemo() { var wg sync.WaitGroup var workers [10]worker for i := 0; i
package mainimport ( "fmt" "sync")type worker struct { in chan int done func()}func createWorker(id int, wg *sync.WaitGroup) worker { w := worker{ in: make(chan int), done: func() { wg.Done() }, } go doWorker(id, w) return w}func doWorker(id int, w worker) { for n := range w.in { fmt.Printf("Worker %d receive %c\n", id, n) w.done() }}func channelDemo() { var wg sync.WaitGroup var workers [10]worker for i := 0; i
package mainimport ( "fmt" "math/rand" "time")func generator() chan int { out := make(chan int) go func() { i := 0 for { // 随机睡眠1500毫秒以内 time.Sleep( time.Duration(rand.Intn(1500)) * time.Millisecond) // 往out这个channel发送i值 out
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan
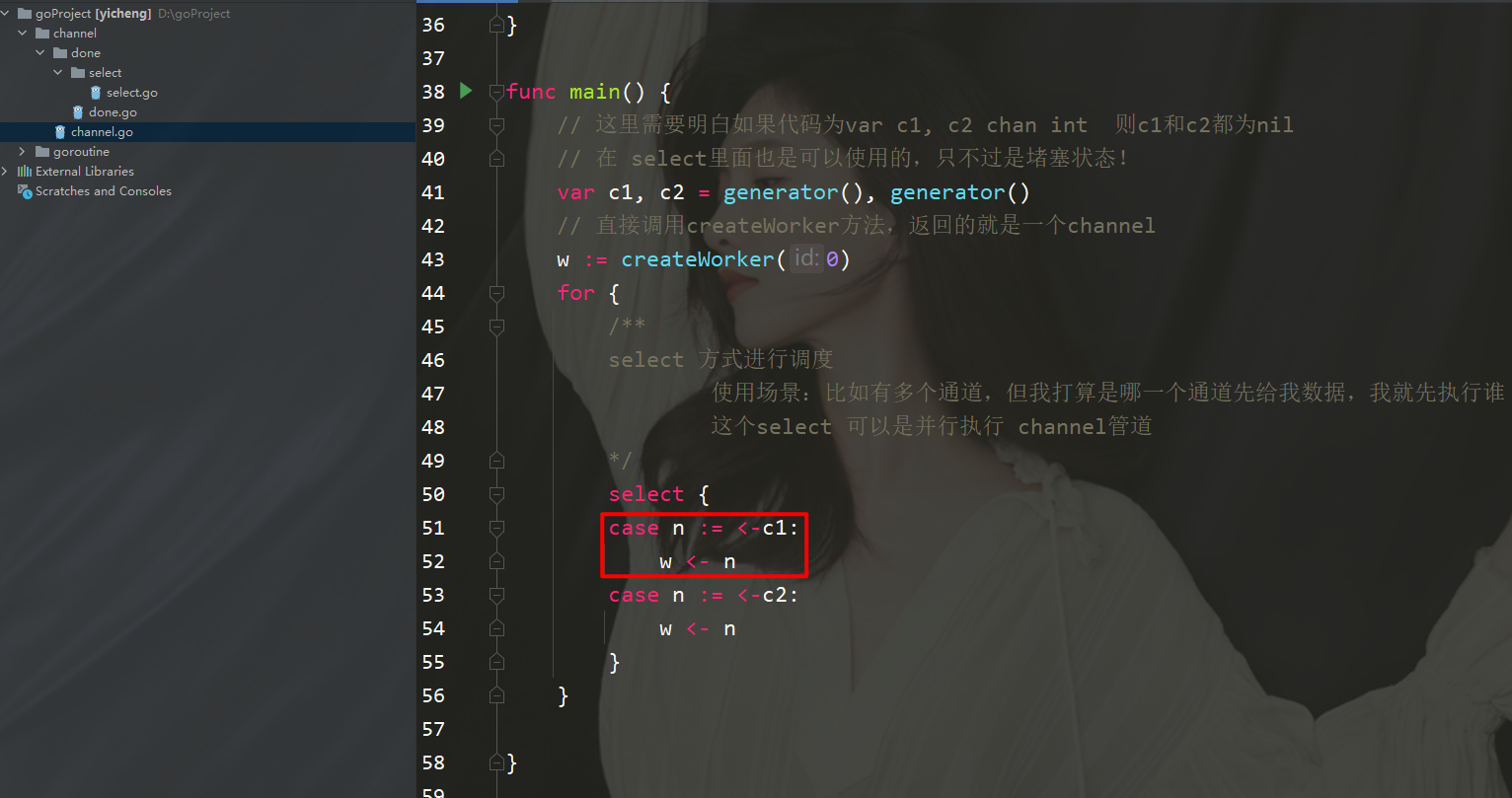
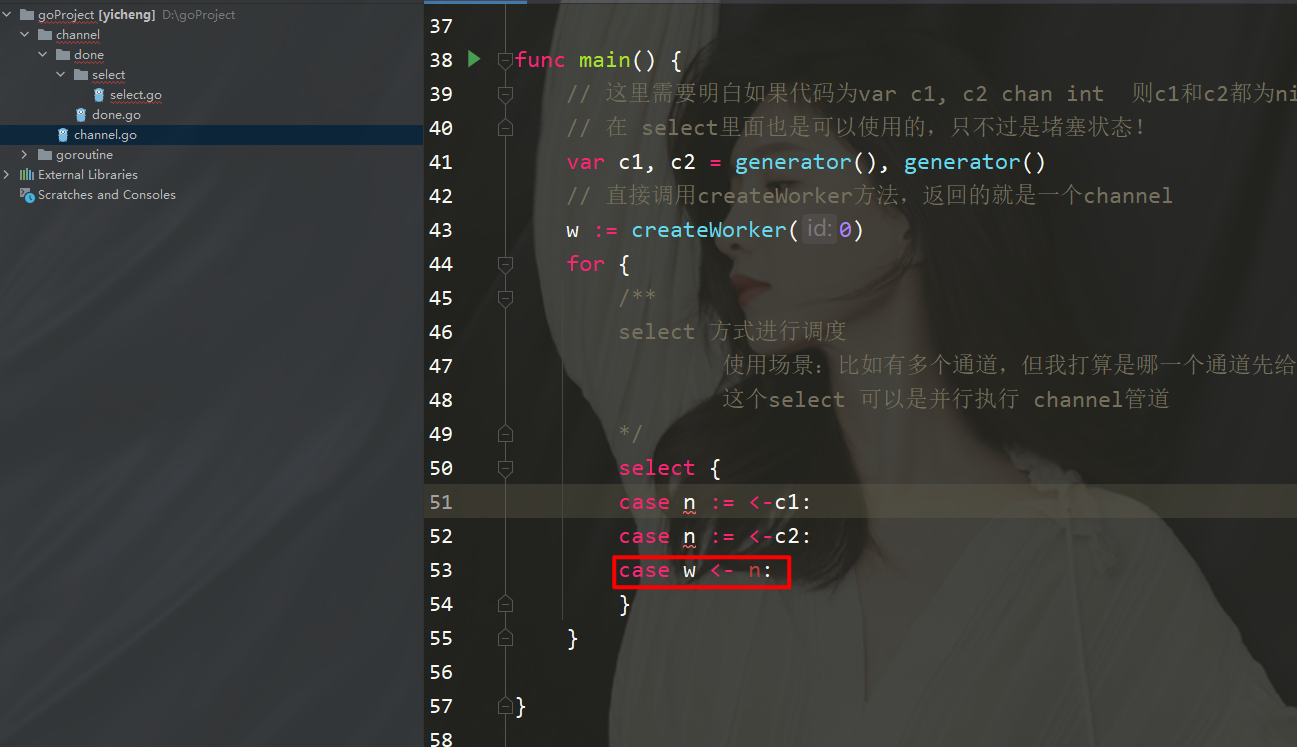
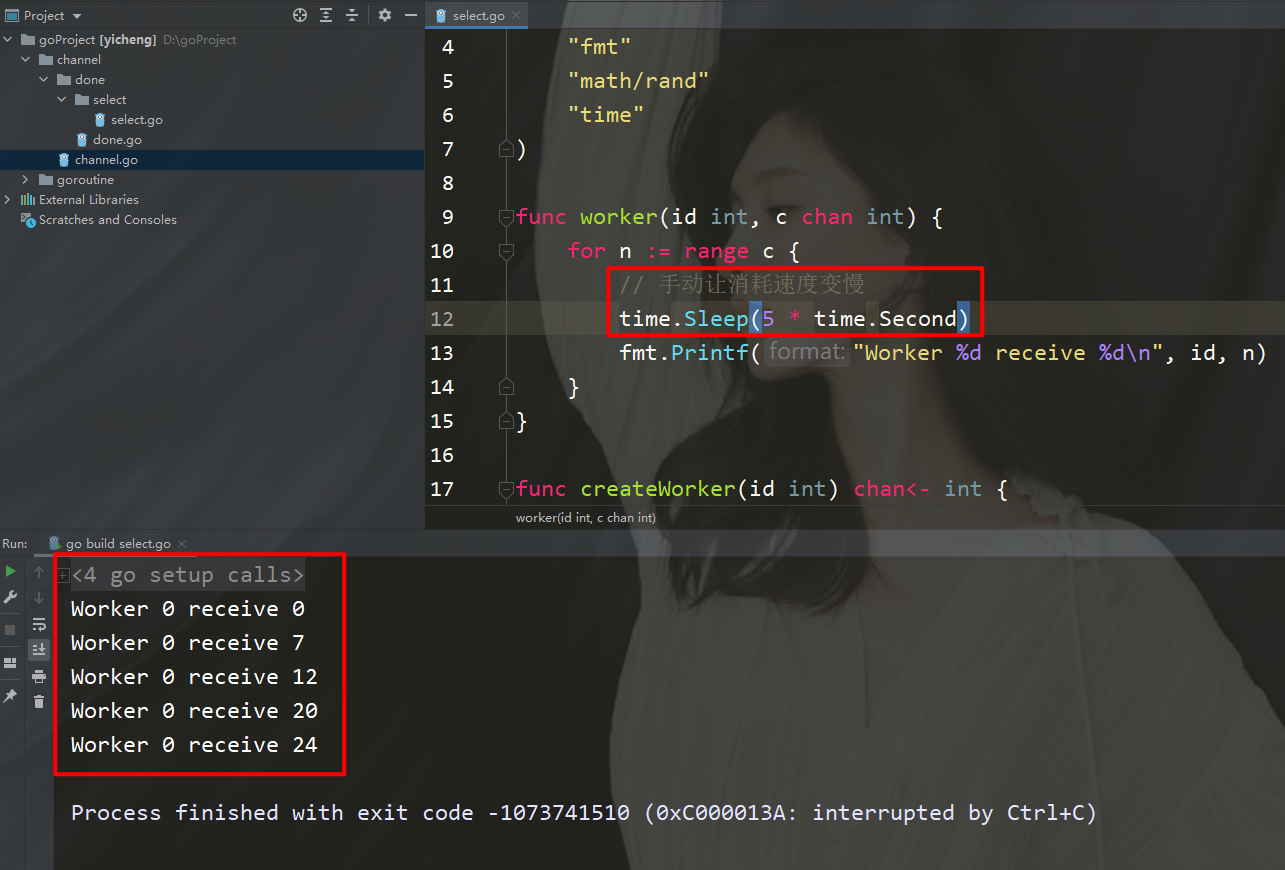
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { // 手动让消耗速度变慢 time.Sleep(5 * time.Second) fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan 0 { activeWorker = worker // 取出索引为0的值 activeValue = values[0] } /** select 方式进行调度 使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁 这个select 可以是并行执行 channel管道 */ select { case n :=
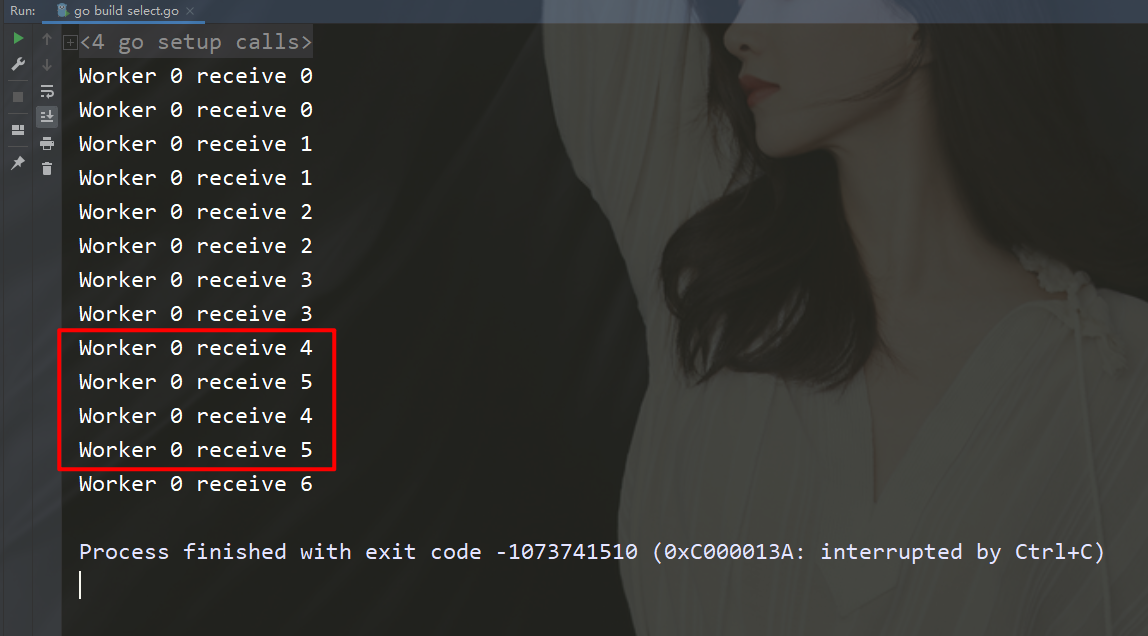
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { // 手动让消耗速度变慢 time.Sleep(time.Second) fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan 0 { activeWorker = worker // 取出索引为0的值 activeValue = values[0] } /** select 方式进行调度 使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁 这个select 可以是并行执行 channel管道 */ select { case n :=
package mainimport ( "fmt" "math/rand" "time")func worker(id int, c chan int) { for n := range c { // 手动让消耗速度变慢 time.Sleep(time.Second) fmt.Printf("Worker %d receive %d\n", id, n) }}func createWorker(id int) chan 0 { activeWorker = worker // 取出索引为0的值 activeValue = values[0] } /** select 方式进行调度 使用场景:比如有多个通道,但我打算是哪一个通道先给我数据,我就先执行谁 这个select 可以是并行执行 channel管道 */ select { case n :=
Das obige ist der detaillierte Inhalt vonLassen Sie uns über die gleichzeitige Programmierung in Go (2) sprechen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Verwendung von && und || in der C-Sprache
Verwendung von && und || in der C-Sprache So lösen Sie nicht verfügbar
So lösen Sie nicht verfügbar Der Unterschied zwischen Zugangs- und Trunk-Ports
Der Unterschied zwischen Zugangs- und Trunk-Ports Ist es umso besser, je höher die CPU-Frequenz des Computers ist?
Ist es umso besser, je höher die CPU-Frequenz des Computers ist? PS-Kurven-Tastenkombination
PS-Kurven-Tastenkombination Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher? Was bedeutet Pycharm bei paralleler Ausführung?
Was bedeutet Pycharm bei paralleler Ausführung? Raum für reguläre Ausdrücke
Raum für reguläre Ausdrücke