



Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Yizuo Diao Haiwen ist Doktorand an der Dalian University of Technology und sein Betreuer ist Professor Lu Huchuan. Derzeit absolviert er ein Praktikum am Beijing Zhiyuan Artificial Intelligence Research Institute. Der Dozent ist Dr. Wang Xinlong. Seine Forschungsinteressen sind Vision und Sprache, effiziente Übertragung großer Modelle, multimodale große Modelle usw. Co-Erstautor Cui Yufeng hat seinen Abschluss an der Beihang-Universität und ist Algorithmenforscher am Vision Center des Beijing Zhiyuan Artificial Intelligence Research Institute. Seine Forschungsinteressen sind multimodale Modelle, generative Modelle und Computer Vision, und sein Hauptwerk ist die Emu-Reihe.
In letzter Zeit ist die Forschung an multimodalen Großmodellen in vollem Gange und die Industrie investiert immer mehr in diese. Im Ausland wurden beliebte Modelle eingeführt, darunter GPT-4o (OpenAI), Gemini (Google), Phi-3V (Microsoft), Claude-3V (Anthropic) und Grok-1.5V (xAI). Gleichzeitig blühen die inländischen Modelle GLM-4V (Wisdom Spectrum AI), Step-1,5V (Step Star), Emu2 (Beijing Zhiyuan), Intern-VL (Shanghai AI Laboratory), Qwen-VL (Alibaba) usw. auf .
Das aktuelle visuelle Sprachmodell (VLM) basiert normalerweise auf dem visuellen Encoder (Vision Encoder, VE), um visuelle Merkmale zu extrahieren, und kombiniert dann die Benutzeranweisungen mit dem großen Sprachmodell (LLM) zur Verarbeitung und Beantwortung. Die größte Herausforderung liegt darin im visuellen Encoder und Trennung des Trainings für große Sprachmodelle. Diese Trennung führt dazu, dass visuelle Encoder Probleme mit der visuellen Induktionsverzerrung verursachen, wenn sie mit großen Sprachmodellen interagieren, wie z. B. eine begrenzte Bildauflösung und ein begrenztes Seitenverhältnis sowie starke visuelle semantische Prioritäten. Da die Kapazität visueller Encoder immer weiter zunimmt, ist auch die Einsatzeffizienz multimodaler großer Modelle bei der Verarbeitung visueller Signale stark eingeschränkt. Darüber hinaus ist es immer komplexer und herausfordernder geworden, die optimale Kapazitätskonfiguration für visuelle Encoder und große Sprachmodelle zu finden.
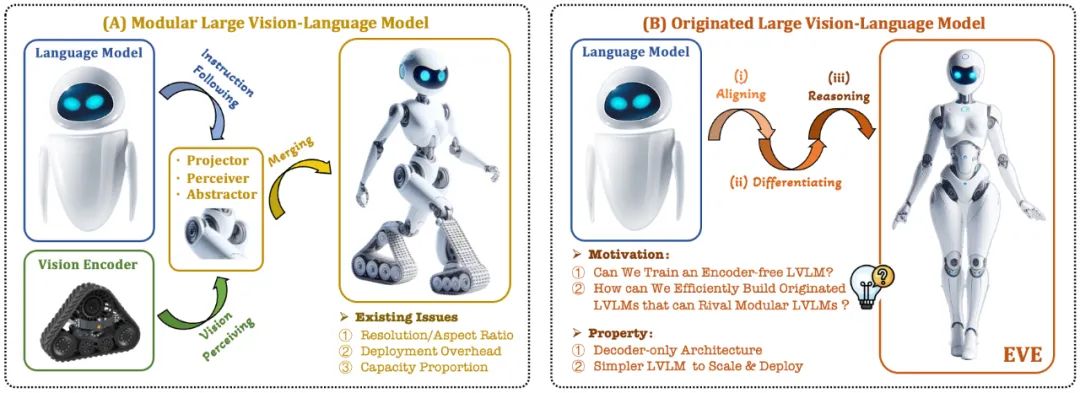
In diesem Zusammenhang entstanden schnell einige weitere innovative Ideen:
Können wir den visuellen Encoder entfernen, also direkt ein natives multimodales großes Modell ohne visuellen Encoder erstellen?
Wie kann man ein großes Sprachmodell effizient und reibungslos in ein natives multimodales großes Modell ohne visuellen Encoder entwickeln?
Wie kann die Leistungslücke zwischen nativen multimodalen Frameworks ohne Encoder und den gängigen multimodalen Paradigmen auf Encoderbasis geschlossen werden?
Adept AI veröffentlichte das Modell der Fuyu-Serie Ende 2023 und unternahm einige damit verbundene Versuche, gab jedoch keine Trainingsstrategien, Datenressourcen und Ausrüstungsinformationen bekannt. Gleichzeitig besteht eine erhebliche Leistungslücke zwischen dem Fuyu-Modell und den gängigen Algorithmen bei öffentlichen visuellen Textbewertungsindikatoren. Im gleichen Zeitraum zeigten einige von uns durchgeführte Pilotexperimente, dass das native multimodale große Modell ohne Encoder immer noch mit heiklen Problemen wie langsamer Konvergenzgeschwindigkeit und schlechter Leistung konfrontiert ist, selbst wenn der Umfang der Vortrainingsdaten in großem Maßstab erhöht wird.
Als Reaktion auf diese Herausforderungen hat das Vision-Team des Zhiyuan Research Institute zusammen mit der Dalian University of Technology, der Peking University und anderen inländischen Universitäten eine neue Generation des programmiererfreien visuellen Sprachmodells EVE auf den Markt gebracht. Durch verfeinerte Trainingsstrategien und zusätzliche visuelle Überwachung integriert EVE visuell-sprachliche Darstellung, Ausrichtung und Inferenz in eine einheitliche reine Decoder-Architektur. Unter Verwendung öffentlich verfügbarer Daten schneidet EVE bei mehreren visuell-linguistischen Benchmarks gut ab, konkurriert mit gängigen Encoder-basierten multimodalen Methoden ähnlicher Kapazität und übertrifft sein Pendant Fuyu-8B deutlich. EVE soll einen transparenten und effizienten Weg für die Entwicklung nativer multimodaler Architekturen für reine Decoder bieten.


Papieradresse: https://arxiv.org/abs/2406.11832
Projektcode: https://github.com/baaivision/EVE
Modelladresse: https ://huggingface.co/BAAI/EVE-7B-HD-v1.0
1. Technische Highlights
Natives visuelles Sprachmodell: bricht das feste Paradigma der gängigen multimodalen Modelle, entfernt den visuellen Encoder und kann jedes Bildseitenverhältnis verarbeiten. Es übertrifft den gleichen Typ des Fuyu-8B-Modells in mehreren visuellen Sprachbenchmarks deutlich und kommt der gängigen visuellen Encoder-basierten visuellen Spracharchitektur nahe.
Geringe Daten- und Schulungskosten: Das Vortraining des EVE-Modells überprüfte nur öffentliche Daten von OpenImages, SAM und LAION und nutzte 665.000 LLaVA-Anweisungsdaten und zusätzlich 1,2 Millionen visuelle Dialogdaten, um regulär und hoch zu erstellen. Auflösungsversionen von EVE-7B. Die Schulung dauert auf zwei 8-A100 (40G)-Knoten etwa 9 Tage, auf vier 8-A100-Knoten etwa 5 Tage.
Transparente und effiziente Erkundung: EVE versucht, einen effizienten, transparenten und praktischen Weg zum nativen visuellen Sprachmodell zu erkunden und liefert neue Ideen und wertvolle Erfahrungen für die Entwicklung einer neuen Generation reiner Decoder-Visual-Language-Modellarchitektur zukünftiger multimodaler Modelle eröffnet neue Erkundungsrichtungen.
2. Modellstruktur
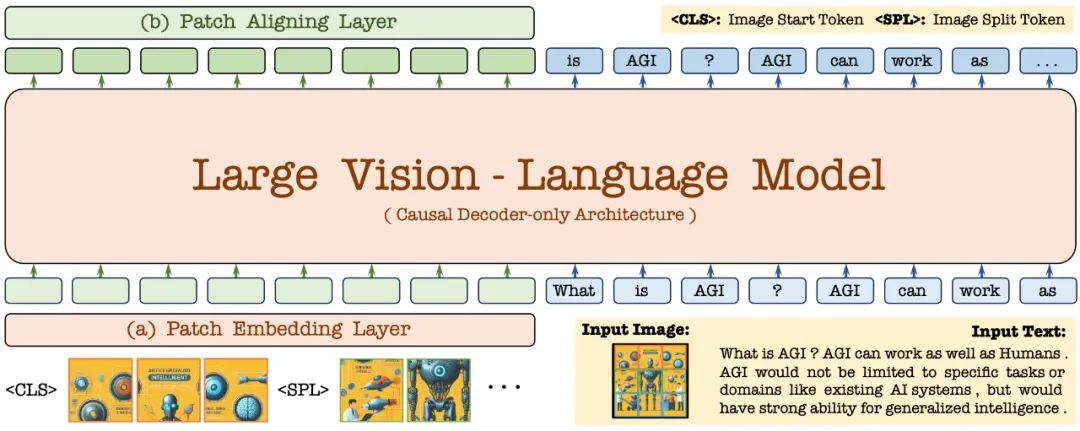
Zuerst wird es durch das Vicuna-7B-Sprachmodell initialisiert, sodass es über umfassende Sprachkenntnisse und leistungsstarke Funktionen zur Befehlsverfolgung verfügt. Auf dieser Grundlage wird der tiefe visuelle Encoder entfernt, eine leichte visuelle Codierungsschicht aufgebaut, die Bildeingabe effizient und verlustfrei codiert und zusammen mit Benutzersprachbefehlen in einen einheitlichen Decoder eingegeben. Darüber hinaus führt die visuelle Ausrichtungsschicht eine Merkmalsausrichtung mit einem allgemeinen visuellen Encoder durch, um die feinkörnige Kodierung und Darstellung visueller Informationen zu verbessern.
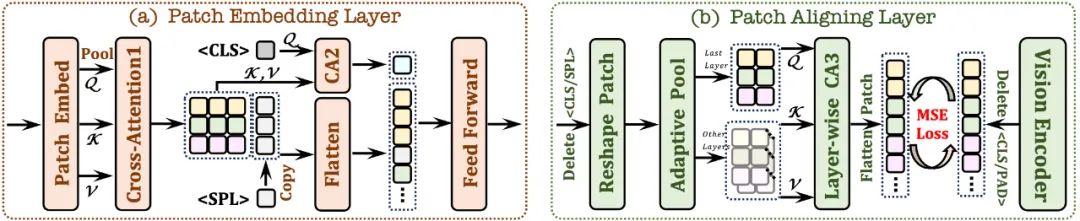
2.1 Patch-Einbettungsschicht
Verwenden Sie zunächst eine einzelne Faltungsschicht, um die 2D-Feature-Map des Bildes zu erhalten, und führen Sie dann ein Downsampling durch die durchschnittliche Pooling-Schicht durch.
Verwenden Sie das Cross-Attention-Modul (CA1). Interagieren Sie in einem begrenzten Empfangsfeld, um die lokalen Funktionen jedes Patches zu verbessern.
verwendet -Token und kombiniert mit dem Cross-Attention-Modul (CA2), um globale Informationen für jede nachfolgende Patch-Funktion bereitzustellen Am Ende der Zeile wird ein lernbares
-Token eingefügt, um dem Netzwerk zu helfen, die zweidimensionale räumliche Struktur des Bildes zu verstehen.2.2 Patch-Ausrichtungsebene
Zeichnen Sie die 2D-Form des gültigen Patches auf; verwerfen Sie
/
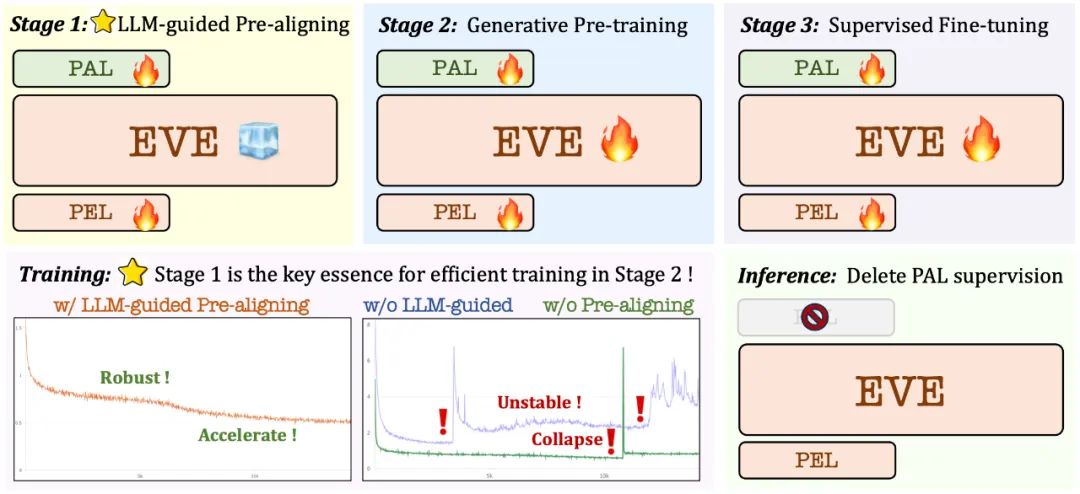 Vorschulungsphase anhand eines großen Sprachmodells: Stellen Sie die anfängliche Verbindung zwischen Vision und Sprache her und legen Sie den Grundstein für ein anschließendes stabiles und effizientes groß angelegtes Vortraining ;
Vorschulungsphase anhand eines großen Sprachmodells: Stellen Sie die anfängliche Verbindung zwischen Vision und Sprache her und legen Sie den Grundstein für ein anschließendes stabiles und effizientes groß angelegtes Vortraining ;
Generative Vortrainingsphase: Verbesserung der Fähigkeit des Modells, visuell-linguistische Inhalte zu verstehen und einen reibungslosen Übergang von einem reinen Sprachmodell zu einem multimodalen Modell zu erreichen;
Überwachte Feinabstimmungsphase: weiter Standardisieren Sie das Modell, um Sprachanweisungen zu befolgen und Konversationsmuster zu erlernen, die den Anforderungen verschiedener Benchmarks für visuelle Sprache entsprechen.
 In der Vortrainingsphase wurden 33 Millionen öffentliche Daten von SA-1B, OpenImages und LAION gefiltert und nur Bildbeispiele mit einer Auflösung von mehr als 448×448 beibehalten. Um insbesondere das Problem der hohen Redundanz in LAION-Bildern anzugehen, wurden 50.000 Cluster durch Anwendung von K-Means-Clustering auf die von EVA-CLIP extrahierten Bildmerkmale generiert und schließlich die 300 Bilder ausgewählt, die jedem Clusterzentrum am nächsten liegen 15 Millionen LAION-Bildbeispiele ausgewählt. Anschließend wurden hochwertige Bildbeschreibungen mit Emu2 (17B) und LLaVA-1.5 (13B) neu generiert.
In der Vortrainingsphase wurden 33 Millionen öffentliche Daten von SA-1B, OpenImages und LAION gefiltert und nur Bildbeispiele mit einer Auflösung von mehr als 448×448 beibehalten. Um insbesondere das Problem der hohen Redundanz in LAION-Bildern anzugehen, wurden 50.000 Cluster durch Anwendung von K-Means-Clustering auf die von EVA-CLIP extrahierten Bildmerkmale generiert und schließlich die 300 Bilder ausgewählt, die jedem Clusterzentrum am nächsten liegen 15 Millionen LAION-Bildbeispiele ausgewählt. Anschließend wurden hochwertige Bildbeschreibungen mit Emu2 (17B) und LLaVA-1.5 (13B) neu generiert.
In der überwachten Feinabstimmungsphase verwenden Sie den Feinabstimmungsdatensatz LLaVA-mix-665K, um die Standardversion von EVE-7B zu trainieren und gemischte Daten wie AI2D, Synthdog, DVQA, ChartQA, DocVQA, zu integrieren. Vision-Flan und Bunny-695K machen sich auf den Weg, um eine hochauflösende Version von EVE-7B zu erhalten.
Das EVE-Modell übertrifft das ähnliche Fuyu-8B-Modell in mehreren visuellen Sprachbenchmarks deutlich und schneidet auf Augenhöhe mit einer Vielzahl gängiger Encoder-basierter visueller Sprachmodelle ab. Aufgrund der Verwendung einer großen Menge visueller Sprachdaten für das Training ist es jedoch schwierig, genau auf bestimmte Anweisungen zu reagieren, und die Leistung in einigen Benchmark-Tests muss verbessert werden. Spannend ist, dass das Encoder-lose EVE durch effiziente Trainingsstrategien eine mit dem Encoder-basierten visuellen Sprachmodell vergleichbare Leistung erzielen kann, wodurch die Probleme der Eingabegrößenflexibilität, der Bereitstellungseffizienz und der Modalität von Mainstream-Modellen grundsätzlich gelöst werden.
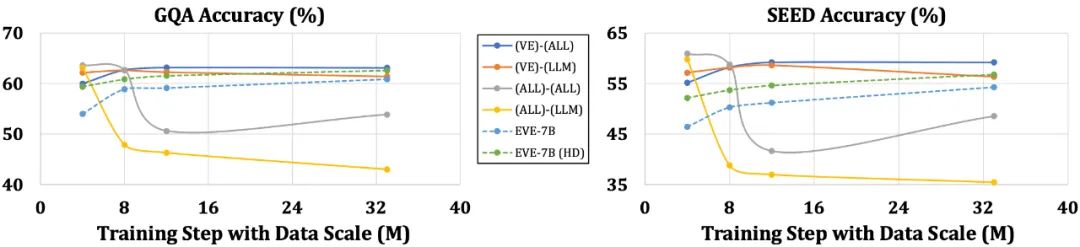
Im Vergleich zu Modellen mit Encodern, die anfällig für Probleme wie die Vereinfachung der Sprachstruktur und den Verlust umfangreicher Kenntnisse sind, hat EVE mit zunehmender Datengröße eine allmähliche und stabile Leistungsverbesserung gezeigt und nähert sich allmählich der Leistung des Encoders an -basierte Modelle Ebene. Dies kann daran liegen, dass die Codierung und Ausrichtung visueller und sprachlicher Modalitäten in einem einheitlichen Netzwerk eine größere Herausforderung darstellt, wodurch Encoder-freie Modelle im Vergleich zu Modellen mit Encodern weniger anfällig für Überanpassungen sind.
5. Was denken Ihre Kollegen?
Ali Hatamizadeh, leitender Forscher bei NVIDIA, sagte, dass EVE erfrischend sei und versuche, eine neue Erzählung vorzuschlagen, die sich von der Konstruktion komplexer Bewertungsstandards und progressiven Verbesserungen des visuellen Sprachmodells unterscheidet.

Armand Joulin, Hauptforscher bei Google Deepmind, sagte, dass es spannend sei, ein reines Decoder-Modell für visuelle Sprache zu erstellen.

Apple Machine Learning Engineer Prince Canuma sagte, dass die EVE-Architektur sehr interessant und eine gute Ergänzung zum MLX VLM-Projektset sei.

6. Zukunftsaussichten
Als Encoder-loses natives visuelles Sprachmodell hat EVE derzeit ermutigende Ergebnisse erzielt. Auf diesem Weg gibt es einige interessante Richtungen, die es wert sind, in Zukunft erkundet zu werden:
Weitere Leistungsverbesserung: Experimente ergaben, dass das Vortraining, bei dem nur visuell-linguistische Daten verwendet wurden, die Sprachfähigkeit des Modells erheblich verringerte (der SQA-Wert sank von 65,3 %). auf 63,0 % erhöht, aber die multimodale Leistung des Modells schrittweise verbessert. Dies weist darauf hin, dass es bei der Aktualisierung großer Sprachmodelle zu einem internen katastrophalen Vergessen von Sprachkenntnissen kommt. Es wird empfohlen, reinsprachliche Pre-Training-Daten angemessen zu integrieren oder eine Expertenmix-Strategie (MoE) zu verwenden, um die Interferenz zwischen visuellen und sprachlichen Modalitäten zu reduzieren.
Vorstellung einer Encoder-losen Architektur: Mit geeigneten Strategien und Training mit hochwertigen Daten können Encoder-lose visuelle Sprachmodelle mit Modellen mit Encodern konkurrieren. Wie hoch ist also die Leistung der beiden bei gleicher Modellkapazität und umfangreichen Trainingsdaten? Wir spekulieren, dass die Encoder-lose Architektur durch die Erweiterung der Modellkapazität und der Trainingsdatenmenge die Encoder-basierte Architektur erreichen oder sogar übertreffen kann, da erstere Bilder nahezu verlustfrei eingibt und die a priori-Verzerrung des visuellen Encoders vermeidet.
Konstruktion nativer multimodaler Modelle: EVE demonstriert vollständig, wie native multimodale Modelle effizient und stabil erstellt werden können, was Transparenz für die anschließende Integration weiterer Modalitäten (wie Audio, Video, Wärmebild, Tiefe, etc.) und praktische Wege. Die Kernidee besteht darin, diese Modalitäten vorab durch ein eingefrorenes großes Sprachmodell auszurichten, bevor ein umfassendes einheitliches Training eingeführt wird, und entsprechende Einzelmodal-Encoder und Sprachkonzeptausrichtung zur Überwachung zu nutzen.
Das obige ist der detaillierte Inhalt vonDieses multimodale große Modell der „nativen Version' verzichtet auf den visuellen Encoder und ist auch mit Mainstream-Methoden vergleichbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



