


Die vier großen VLMs versuchen alle, den Elefanten blind zu berühren?
Lassen Sie die beliebtesten SOTA-Modelle (GPT-4o, Gemini-1.5, Sonnet-3, Sonnet-3.5) zählen, wie viele Schnittpunkte es zwischen zwei Linien gibt. Werden sie besser abschneiden als Menschen?
Die Antwort ist wahrscheinlich nein.
Seit der Einführung von GPT-4V haben visuelle Sprachmodelle (VLMs) die Intelligenz großer Modelle einen großen Schritt nach vorne in Richtung des Niveaus der künstlichen Intelligenz gemacht, das wir uns vorgestellt haben.
VLMs können sowohl Bilder verstehen als auch Sprache verwenden, um zu beschreiben, was sie sehen, und auf der Grundlage dieser Erkenntnisse komplexe Aufgaben ausführen. Wenn Sie dem VLM-Modell beispielsweise ein Bild eines Esstisches und ein Bild einer Speisekarte senden, kann es aus den beiden Bildern die Anzahl der Bierflaschen und den Stückpreis auf der Speisekarte extrahieren und berechnen, wie viel das Bier kostet die Mahlzeit.
VLMs haben sich so schnell weiterentwickelt, dass es für das Modell zu einer Aufgabe geworden ist, herauszufinden, ob in diesem Bild einige unvernünftige „abstrakte Elemente“ vorhanden sind. Beispielsweise muss das Modell gefragt werden, ob eine Person bügelt Kleidung in einem zu schnell fahrenden Taxi.

Der aktuelle Benchmark-Testsatz bewertet jedoch die visuellen Fähigkeiten von VLMs nicht gut. Am Beispiel MMMU lassen sich 42,9 % der Fragen ohne Betrachtung von Bildern lösen, sodass viele Antworten allein aus Textfragen und Optionen abgeleitet werden können. Zweitens sind die derzeit von VLM gezeigten Fähigkeiten größtenteils das Ergebnis des „Speicherns“ großer Internetdaten. Dies führt dazu, dass VLMs im Testsatz sehr hohe Werte erzielen. Dies bedeutet jedoch nicht, dass das Urteil wahr ist: Können VLMs Bilder wie Menschen wahrnehmen?
Um die Antwort auf diese Frage zu erhalten, beschlossen Forscher der Auburn University und der University of Alberta, das Sehvermögen für VLMs zu „testen“. Inspiriert durch den „Sehtest“ des Optikers, baten sie vier Top-VLMs: GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet und Claude-3.5 Sonnet, eine Reihe von „Fragen zum Sehtest“ zu erstellen.

Papiertitel: Sehsprachmodelle sind blind
Papierlink: https://arxiv.org/pdf/2407.06581
Projektlink: https://vlmsareblind.github.io/
Diese Reihe von Fragen ist sehr einfach. Um beispielsweise die Anzahl der Schnittpunkte zweier Linien zu zählen und herauszufinden, welcher Buchstabe durch einen roten Kreis markiert ist, sind nahezu keine Kenntnisse der Welt erforderlich. Die Testergebnisse sind tatsächlich „kurzsichtig“ und die Details des Bildes sind in ihrer Sicht tatsächlich verschwommen.
VLM Blind oder nicht? Sieben Hauptaufgaben, die Sie mit nur einem Test kennen können
Um zu verhindern, dass VLMs Antworten direkt aus Internet-Datensätzen „kopieren“, hat der Autor des Papiers eine neue Reihe von „Sehtests“ entwickelt. Die Autoren des Artikels entschieden sich dafür, VLMs die Beziehung zwischen geometrischen Figuren im Raum bestimmen zu lassen, beispielsweise ob sich zwei Figuren schneiden. Denn die räumlichen Informationen dieser Muster auf einer weißen Leinwand lassen sich meist nicht in natürlicher Sprache beschreiben.
Wenn Menschen diese Informationen verarbeiten, nehmen sie sie über das „visuelle Gehirn“ wahr. Bei VLMs sind sie jedoch auf die Kombination von Bildmerkmalen und Textmerkmalen in den frühen Phasen des Modells angewiesen, d. h. auf die Integration des visuellen Encoders in ein großes Sprachmodell, bei dem es sich im Wesentlichen um ein Wissensgehirn ohne Augen handelt.
Vorexperimente zeigen, dass VLMs bei menschlichen Sehtests, wie zum Beispiel der umgedrehten „E“-Sehtafel, die jeder von uns getestet hat, erstaunlich gut abschneiden.
Test und Ergebnisse
Level 1: Zählen Sie, wie viele Schnittpunkte es zwischen den Linien gibt?
Der Autor des Artikels hat 150 Bilder erstellt, die zwei Liniensegmente auf weißem Hintergrund enthalten. Die x-Koordinaten dieser Liniensegmente sind fest und gleichmäßig verteilt, während die y-Koordinaten zufällig generiert werden. Es gibt nur drei Schnittpunkte zwischen zwei Liniensegmenten: 0, 1 und 2.

Wie in Abbildung 5 gezeigt, schnitten alle VLMs im Test von zwei Versionen von Aufforderungswörtern und drei Versionen der Liniensegmentdicke bei dieser einfachen Aufgabe schlecht ab.

Sonnet-3.5, das die beste Genauigkeit aufweist, beträgt nur 77,33 % (siehe Tabelle 1).

Genauer gesagt neigen VLMs dazu, eine schlechtere Leistung zu erbringen, wenn der Abstand zwischen zwei Linien kleiner wird (siehe Abbildung 6 unten). Da jedes Liniendiagramm aus drei Schlüsselpunkten besteht, wird der Abstand zwischen zwei Linien als durchschnittlicher Abstand dreier entsprechender Punktpaare berechnet.

Dieses Ergebnis steht in scharfem Kontrast zur hohen Genauigkeit von VLMs auf ChartQA, die zeigt, dass VLMs den Gesamttrend des Liniendiagramms erkennen können, aber nicht „heranzoomen“ können, um Details wie „welche Linien sich schneiden“ zu sehen ".
Zweite Ebene: Bestimmen Sie die Positionsbeziehung zwischen zwei Kreisen
Wie im Bild gezeigt, hat der Autor des Papiers zufällig zwei Kreise derselben Größe auf einer Leinwand einer bestimmten Größe generiert. Es gibt nur drei Situationen in der Positionsbeziehung zwischen zwei Kreisen: Schnittpunkt, Tangentialität und Trennung. 
Überraschenderweise kann bei dieser für den Menschen intuitiv sichtbaren Aufgabe, deren Antwort auf einen Blick erkennbar ist, kein VLM die Antwort perfekt geben (siehe Abbildung 7).

Das Modell mit der besten Genauigkeit (92,78 %) ist Gemini-1.5 (siehe Tabelle 2).

In Experimenten kam es häufig zu einer Situation: Wenn zwei Kreise sehr nahe beieinander liegen, zeigen VLMs tendenziell eine schlechte Leistung, treffen aber fundierte Vermutungen. Wie in der Abbildung unten gezeigt, antwortet Sonnet-3.5 normalerweise mit einem konservativen „Nein“.

Wie in Abbildung 8 gezeigt, kann GPT-4o, das die schlechteste Genauigkeit aufweist, keine 100 % erreichen, selbst wenn der Abstand zwischen den beiden Kreisen weit auseinander liegt und einen so großen Radius (d = 0,5) aufweist. präzise.
Dennoch scheint die Vision von VLM nicht klar genug zu sein, um die kleinen Lücken oder Schnittpunkte zwischen den beiden Kreisen zu erkennen.

Level 3: Wie viele Buchstaben sind rot eingekreist?
Da der Abstand zwischen Buchstaben in einem Wort sehr gering ist, stellten die Autoren der Arbeit die Hypothese auf, dass VLMs, wenn sie „kurzsichtig“ sind, die rot eingekreisten Buchstaben nicht erkennen können.
Also wählten sie Zeichenfolgen wie „Acknowledgement“, „Subdermatoglyphic“ und „tHyUiKaRbNqWeOpXcZvM“. Generieren Sie als Test zufällig einen roten Kreis, um einen Buchstaben in der Zeichenfolge einzukreisen.

Die Testergebnisse zeigen, dass die getesteten Modelle auf diesem Niveau sehr schlecht abgeschnitten haben (siehe Abbildung 9 und Tabelle 3).


Beispielsweise neigen visuelle Sprachmodelle dazu, Fehler zu machen, wenn Buchstaben leicht durch rote Kreise verdeckt werden. Sie verwechseln oft die Buchstaben neben dem roten Kreis. Manchmal erzeugt das Modell beispielsweise Halluzinationen, obwohl es das Wort genau buchstabieren kann, fügt es dem Wort jedoch verstümmelte Zeichen hinzu (z. B. „9“, „n“, „©“).

Alle Modelle außer GPT-4o schnitten bei Wörtern etwas besser ab als bei zufälligen Zeichenfolgen, was darauf hindeutet, dass die Kenntnis der Schreibweise eines Wortes visuellen Sprachmodellen dabei helfen kann, Urteile zu fällen, wodurch die Genauigkeit leicht verbessert wird.
Gemini-1.5 und Sonnet-3.5 sind die beiden Spitzenmodelle mit Genauigkeitsraten von 92,81 % bzw. 89,22 % und übertreffen GPT-4o und Sonnet-3 um fast 20 %.

Level 4 und Level 5: Wie viele überlappende Formen gibt es? Wie viele „Matroschka“-Quadrate gibt es?
Angenommen, VLMs sind „kurzsichtig“, können sie den Schnittpunkt zwischen jeweils zwei Kreisen in einem Muster ähnlich den „Olympischen Ringen“ möglicherweise nicht klar erkennen. Zu diesem Zweck generierte der Autor des Artikels zufällig 60 Mustergruppen ähnlich den „Olympischen Ringen“ und bat VLMs, zu zählen, wie viele überlappende Muster sie hatten. Für weitere Tests erstellten sie außerdem eine fünfeckige Version der „Olympischen Ringe“.

Da VLMs beim Zählen der Anzahl sich schneidender Kreise schlecht abschneiden, haben die Autoren den Fall weiter getestet, bei dem sich die Kanten des Musters nicht schneiden und jede Form vollständig in einer anderen Form verschachtelt ist. Sie erzeugten ein „Matroschka“-ähnliches Muster aus 2–5 Quadraten und baten VLMs, die Gesamtzahl der Quadrate im Bild zu zählen.

Anhand der leuchtend roten Kreuze in der Tabelle unten ist leicht zu erkennen, dass diese beiden Ebenen auch für VLMs unüberwindbare Hindernisse darstellen.

Im Nested-Square-Test variiert die Genauigkeit jedes Modells stark: GPT-4o (Genauigkeit 48,33 %) und Sonnet-3 (Genauigkeit 55,00 %) sind mindestens besser als Gemini-1,5 (Genauigkeit 80,00 %) und Sonett-3,5 (Genauigkeit 87,50 %) 30 Prozentpunkte niedriger.
Diese Lücke wird größer, wenn das Modell überlappende Kreise und Fünfecke zählt, aber Sonnet-3.5 schneidet um ein Vielfaches besser ab als andere Modelle. Wie in der Tabelle unten gezeigt, übersteigt die Genauigkeit von Sonnet-3.5 mit 75,83 % die Genauigkeit von Gemini-1.5 bei weitem, wenn es sich um ein Fünfeck handelt.
Überraschenderweise erreichten alle vier getesteten Modelle beim Zählen von 5 Ringen eine Genauigkeit von 100 %, aber das Hinzufügen nur eines zusätzlichen Rings reichte aus, um die Genauigkeit deutlich auf nahezu Null zu senken.
Allerdings schneiden alle VLMs (außer Sonnet-3.5) bei der Berechnung von Fünfecken schlecht ab, selbst wenn sie 5 Fünfecke berechnen. Insgesamt ist die Berechnung von 6 bis 9 Formen (einschließlich Kreisen und Fünfecken) für alle Modelle schwierig.

Das zeigt, dass VLM voreingenommen ist und eher dazu neigt, die berühmten „Olympischen Ringe“ als Ergebnis auszugeben. Beispielsweise wird Gemini-1.5 das Ergebnis als „5“ in 98,95 % der Versuche vorhersagen, unabhängig von der tatsächlichen Anzahl der Kreise (siehe Tabelle 5). Bei anderen Modellen tritt dieser Vorhersagefehler bei Ringen viel häufiger auf als bei Fünfecken.

Neben der Menge hat VLM auch unterschiedliche „Vorlieben“ bei der Farbe der Formen.
GPT-4o schneidet bei farbigen Formen besser ab als bei rein schwarzen Formen, während Sonnet-3.5 mit zunehmender Bildgröße immer bessere Vorhersagen trifft. Als die Forscher jedoch die Farbe und Bildauflösung änderten, änderte sich die Genauigkeit anderer Modelle nur geringfügig.
Es ist erwähnenswert, dass GPT-4o und Sonnet-3 bei der Berechnung verschachtelter Quadrate immer noch schwierig zu berechnen sind, selbst wenn die Anzahl der Quadrate nur 2-3 beträgt. Wenn sich die Anzahl der Quadrate auf vier und fünf erhöht, erreichen alle Modelle eine Genauigkeit von weit weniger als 100 %. Dies zeigt, dass es für VLM schwierig ist, die Zielform genau zu extrahieren, selbst wenn sich die Kanten der Formen nicht schneiden.

Level 6: Zählen Sie, wie viele Zeilen es in der Tabelle gibt? Wie viele Spalten gibt es?
Während VLMs Schwierigkeiten haben, Grafiken zu überlappen oder zu verschachteln, was sehen sie als Kachelmuster? Im Basistestsatz, insbesondere DocVQA, der viele tabellarische Aufgaben enthält, beträgt die Genauigkeit der getesteten Modelle ≥90 %. Der Autor des Artikels hat zufällig 444 Tabellen mit unterschiedlicher Anzahl von Zeilen und Spalten generiert und VLMs gebeten, zu zählen, wie viele Zeilen die Tabelle enthält. Wie viele Spalten gibt es?
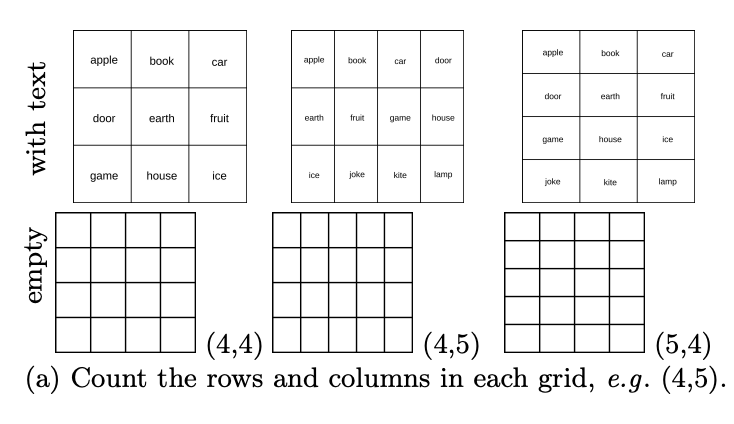
Die Ergebnisse zeigen, dass VLM zwar hohe Werte im Basisdatensatz erzielte, wie in der Abbildung unten dargestellt, aber auch beim Zählen von Zeilen und Spalten in leeren Tabellen schlecht abgeschnitten hat.

Konkret sind sie meist 1-2 Takte günstiger. Wie in der Abbildung unten gezeigt, erkennt GPT-4o das 4×5-Raster als 4×4 und Gemini-1.5 erkennt es als 5×5.

Dies zeigt, dass VLMs zwar wichtige Inhalte aus Tabellen extrahieren können, um tabellenbezogene Fragen in DocVQA zu beantworten, Tabellen Zelle für Zelle jedoch nicht eindeutig identifizieren können.
Dies kann daran liegen, dass die Tabellen im Dokument größtenteils nicht leer sind und VLM nicht zum Leeren von Tabellen verwendet wird. Nachdem die Forscher die Aufgabe vereinfacht hatten, indem sie versuchten, jeder Zelle ein Wort hinzuzufügen, wurde interessanterweise eine deutliche Verbesserung der Genauigkeit für alle VLMs beobachtet, beispielsweise verbesserte sich GPT-4o von 26,13 % auf 53,03 % (siehe Tabelle 6). Allerdings ist die Leistung des getesteten Modells in diesem Fall noch nicht perfekt. Wie in Abbildung 15a und b dargestellt, erzielte das leistungsstärkste Modell (Sonnet-3.5) eine Leistung von 88,68 % in Rastern mit Text und 59,84 % in leeren Rastern.
Und die meisten Modelle (Gemini-1.5, Sonnet-3 und Sonnet-3.5) schneiden beim Zählen von Spalten durchweg besser ab als beim Zählen von Zeilen (siehe Abbildung 15c und d).

Level 7: Wie viele direkte U-Bahn-Linien gibt es vom Startpunkt zum Ziel?
Dieser Test testet die Fähigkeit von VLMs, Pfaden zu folgen, was für das Modell von entscheidender Bedeutung ist, um Karten und Diagramme zu interpretieren und Anmerkungen wie Pfeile zu verstehen, die von Benutzern in Eingabebildern hinzugefügt wurden. Zu diesem Zweck hat der Autor der Arbeit zufällig 180 U-Bahn-Linienpläne mit jeweils vier festen Stationen erstellt. Sie baten VLMs, zu zählen, wie viele monochromatische Pfade es zwischen zwei Standorten gibt.

Die Testergebnisse sind schockierend. Selbst wenn der Pfad zwischen den beiden Standorten auf nur einen vereinfacht wird, können nicht alle Modelle eine 100-prozentige Genauigkeit erreichen. Wie in Tabelle 7 gezeigt, ist Sonnet-3.5 das leistungsstärkste Modell mit einer Genauigkeit von 95 %; das schlechteste Modell ist Sonnet-3 mit einer Genauigkeit von 23,75 %.

Aus der folgenden Abbildung ist nicht schwer zu erkennen, dass die Vorhersage von VLM normalerweise eine Abweichung von 1 bis 3 Pfaden aufweist. Wenn die Kartenkomplexität von 1 auf 3 Pfade steigt, verschlechtert sich die Leistung der meisten VLMs.

Angesichts der „brutalen Tatsache“, dass das heutige Mainstream-VLM bei der Bilderkennung extrem schlecht abschneidet, legten viele Internetnutzer zunächst ihren Status als „KI-Verteidiger“ beiseite und hinterließen viele pessimistische Kommentare.
Ein Internetnutzer sagte: „Es ist peinlich, dass die SOTA-Modelle (GPT-4o, Gemini-1.5 Pro, Sonnet-3, Sonnet-3.5) so schlecht abschneiden, und diese Modelle behaupten tatsächlich in ihrer Werbung: Sie können Bilder verstehen?“ Sie könnten beispielsweise verwendet werden, um blinden Menschen zu helfen oder Kindern Geometrie beizubringen. Ungefähr 100.000 Beispiele und trainiert mit echten Daten, das Problem ist gelöst
Der Autor des Papiers hat auch weitere Fragen dazu erhalten, ob dieser Test wissenschaftlich ist.
Tatsächlich hängen die Herausforderungen, mit denen diese visuellen Sprachmodelle (VLMs) bei der Bewältigung solcher Aufgaben konfrontiert sind, möglicherweise eher mit ihren Denkfähigkeiten und der Art und Weise zusammen, wie sie Bildinhalte interpretieren, als nur mit einem Problem der visuellen Auflösung. Mit anderen Worten: Selbst wenn jedes Detail eines Bildes deutlich sichtbar ist, können Modelle diese Aufgaben möglicherweise immer noch nicht genau erledigen, wenn ihnen die richtige Logik oder ein tiefes Verständnis der visuellen Informationen fehlt. Daher muss sich diese Forschung möglicherweise eingehender mit den Fähigkeiten von VLMs zum visuellen Verständnis und Denken befassen und nicht nur mit ihren Bildverarbeitungsfähigkeiten.
Einige Internetnutzer glauben, dass, wenn das menschliche Sehvermögen durch Faltung verarbeitet wird, auch der Mensch selbst auf Schwierigkeiten bei der Beurteilung des Schnittpunkts von Linien stoßen wird.
Weitere Informationen finden Sie im Originalpapier.
Referenzlinks:
https://arxiv.org/pdf/2407.06581
https://news.ycombinator.com/item?id=40926734
https://vlmsareblind.github.io/
Das obige ist der detaillierte Inhalt vonSind alle diese VLMs blind? GPT-4o und Sonnet-3.5 haben den Sehtest nacheinander nicht bestanden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So legen Sie die Schriftart in CSS fest
So legen Sie die Schriftart in CSS fest
 Das neueste Ranking der zehn besten Börsen im Währungskreis
Das neueste Ranking der zehn besten Börsen im Währungskreis
 Wie viele Arten von USB-Schnittstellen gibt es?
Wie viele Arten von USB-Schnittstellen gibt es?
 Hauptzweck des Dateisystems
Hauptzweck des Dateisystems
 Windows prüft den Portbelegungsstatus
Windows prüft den Portbelegungsstatus
 Ist es legal, Bitcoin auf Huobi.com zu kaufen und zu verkaufen?
Ist es legal, Bitcoin auf Huobi.com zu kaufen und zu verkaufen?
 Liste der Mac-Tastenkombinationen
Liste der Mac-Tastenkombinationen
 Was ist ein leeres Array in PHP?
Was ist ein leeres Array in PHP?







 Allerdings haben sich sowohl die „KI-Verteidiger“ als auch die „KI-Pessimisten“ damit abgefunden, dass VLM im Bildtest immer noch gut abschneidet. Es gibt sachliche Mängel, die äußerst schwer zu vereinbaren sind.
Allerdings haben sich sowohl die „KI-Verteidiger“ als auch die „KI-Pessimisten“ damit abgefunden, dass VLM im Bildtest immer noch gut abschneidet. Es gibt sachliche Mängel, die äußerst schwer zu vereinbaren sind. 

![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



