

脑机接口(BCI)在科研和应用领域的发展近期获得广泛关注,大家通常对脑机接口的应用前景有着广泛的猎奇。
由于神经系统的缺陷导致的失语症不仅严重阻碍患者的日常生活,还可能限制他们的职业发展和社交活动。随着深度学习和脑机接口技术的迅猛发展,现代科学正向着通过神经语音假肢来辅助失语者重新获得交流能力的方向迈进。
人类的大脑已经有了一系列激动人心的进展,在解码语音、操作等方面的信号方面也有了很多突破。特别值得一提的是,埃隆·马斯克(Elon Musk)的Neuralink公司在这一领域也取得了突破性进展,他们的大脑接口技术具有破坏性的发展。
该公司成功地在一位试验对象的大脑中植入了电极,实现了通过简单的光标操作来进行打字、游戏等功能。这标志着我们在向更高复杂度的神经-语音/动作解码迈进的路上又迈出了一步。相比于其他脑机接口技术,神经-语音解码的复杂性更高,其研发工作主要依赖于特殊的数据源——皮层电图(ECoG)。
床上主要是照顾患者康复过程中接收的皮肤电图数据。研究人员利用这些电极,在发声时收集大脑活动的数据。这些数据不仅具有高度的时间空分辨率,并且已经在语音解码研究中取得显著成果,极大地推动了脑机接口技术的发展。通过这些先进技术的帮助,未来我们有望看到更多患有神经障碍的人士重获交流的自由。
最近在《自然》杂志上发表的一项研究取得了突破,研究中在一位植入设备的患者身上使用了量化的HuBERT特征作为中间表征,结合预训练的语音合成器将这些特征转化为语音,这种方法不仅提高了语音的自然度,也保持了高准确性。
然而,HuBERT特征并不能捕捉到发音者的独特声学特征,生成的声音通常是统一的发音者声音,因此仍需额外的模型来将这种通用声音转换为特定患者的声音。
另一个值得注意的点是,该研究及大部分先前尝试采用了非因果架构,这可能限制了其在需要因果操作的脑机接口应用中的实际使用。
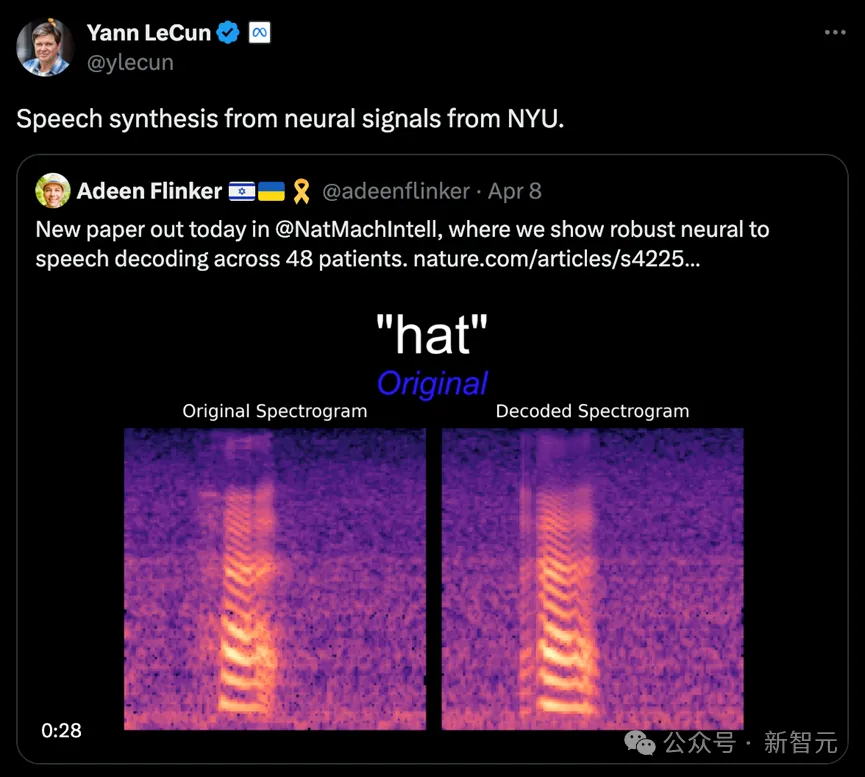
2024年4月8日,纽约大学VideoLab和Flinker Lab联合在《Nature Machine Intelligence》杂志上发表了一项突破性研究。
 图片
图片
论文链接:https://www.nature.com/articles/s42256-024-00824-8
研究相关代码开源在https://github.com/flinkerlab/neural_speech_decoding
更多生成的语音例子在:https://xc1490.github.io/nsd/
这项名为“A neural speech decoding framework leveraging deep learning and speech synthesis”的研究,介绍了一个创新的可微分语音合成器。
该合成器结合了轻量级卷积神经网络,能够将语音编码为一系列可解释的语音参数,如音高、响度和共振峰频率等,并利用可微分的技术重新合成语音。
此研究通过将神经信号映射到这些具体的语音参数,成功构建了一个高度可解释并适用于小数据集的神经语音解码系统。这一系统不仅能重构出高保真且听起来自然的语音,而且为未来脑机接口应用的高准确性提供了实证基础。
研究团队共收集了48位受试者的数据,并在这一基础上进行了语音解码的尝试,为高精度脑机接口技术的实际应用和发展打下了坚实的基础。
图灵奖得主Lecun也转发了研究进展。
 图片
图片
在当前神经信号到语音解码的研究中,面临两大核心挑战。
首先是数据量的限制:为了训练个性化的神经到语音解码模型,通常每个病人的可用的数据时间总长仅约十分钟,这对于依赖大量训练数据的深度学习模型而言是一个显著的制约因素。
其次,人类语音的高度多样性也增加了建模的复杂度。即便同一人反复发音拼读同一个单词,其语速、语调和音调等因素亦可能发生变化,从而为模型的构建增添了额外的难度。
在早期尝试中,研究者们主要采用线性模型来解码神经信号到语音。这类模型不需庞大的数据集支持,具备较强的可解释性,但其准确率通常较低。
近期,随着深度学习技术的进步,特别是卷积神经网络(CNN)和循环神经网络(RNN)的应用,研究者在模拟语音的中间潜在表征和提升合成语音质量方面进行了广泛尝试。
例如,一些研究通过将大脑皮层活动解码为口型运动,再转化为语音,尽管这种方法在解码性能上较为强大,重建的声音却往往听起来不够自然。
此外,一些新方法尝试利用Wavenet声码器和生成对抗网络(GAN)来重建自然听感的语音,虽然这些方法能够改善声音的自然度,但在准确度上仍有局限。
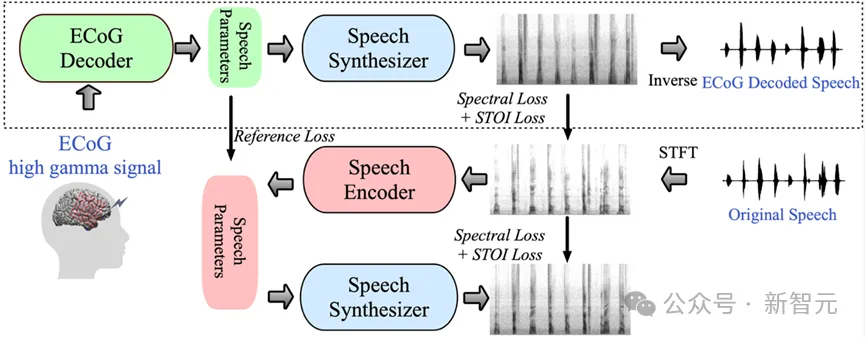
在该研究中,研究团队展示了一种创新的从脑电(ECoG)信号到语音的解码框架。他们构建了一个低维度的潜在表示空间,该空间通过一个轻量级的语音编解码模型,仅使用语音信号来生成。
这一框架包含两个核心部分:首先是ECoG解码器,它负责将ECoG信号转换为一系列可理解的声学语音参数,如音高、是否发声、响度及共振峰频率等;其次是语音合成器部分,负责将这些参数转换为频谱图。
通过构建一个可微分的语音合成器,研究人员实现了在训练ECoG解码器的同时,也对语音合成器进行优化,共同减少频谱图重建的误差。这种低维度潜在空间的可解释性强,结合轻量级的预训练语音编码器生成的参考语音参数,使得整个神经语音解码框架高效且适应性强,有效解决了该领域中数据稀缺的问题。
此外,这个框架不仅能生成与说话者非常接近的自然语音,而且在ECoG解码器部分支持插入多种深度学习模型架构,并能进行因果操作。
研究团队处理了48名神经外科病人的ECoG数据,并使用了多种深度学习架构(包括卷积、循环神经网络和Transformer)来实现ECoG解码。
这些模型在实验中均显示了高准确度,尤其是采用ResNet卷积架构的表现最为出色。该研究框架不仅通过因果操作和相对较低的采样率(10mm间隔)实现了高准确度,还展示了能从大脑的左右半球都有效进行语音解码的能力,从而将神经语音解码的应用范围扩展到了右脑。
 图片
图片
本研究的核心创新之一是开发了一种可微分的语音合成器,这大大提高了语音重合成的效率,并能合成接近原声的高保真音频。
这种语音合成器的设计灵感来源于人类的发声系统,将语音细分为两个部分:Voice(主要用于元音的模拟)和Unvoice(主要用于辅音的模拟)。
在Voice部分,首先使用基频信号生成谐波,然后通过由F1至F6共振峰构成的滤波器,以获得元音的频谱特征。
对于Unvoice部分,通过对白噪声进行特定滤波,生成相应的频谱。一个可学习的参数控制这两部分在每个时间点的混合比例。
最后,通过调整响度信号和添加背景噪声,生成最终的语音频谱。
基于这种语音合成器,研究团队设计了一个高效的语音重合成框架及神经-语音解码框架。详细的框架结构可以参考原文的图6。
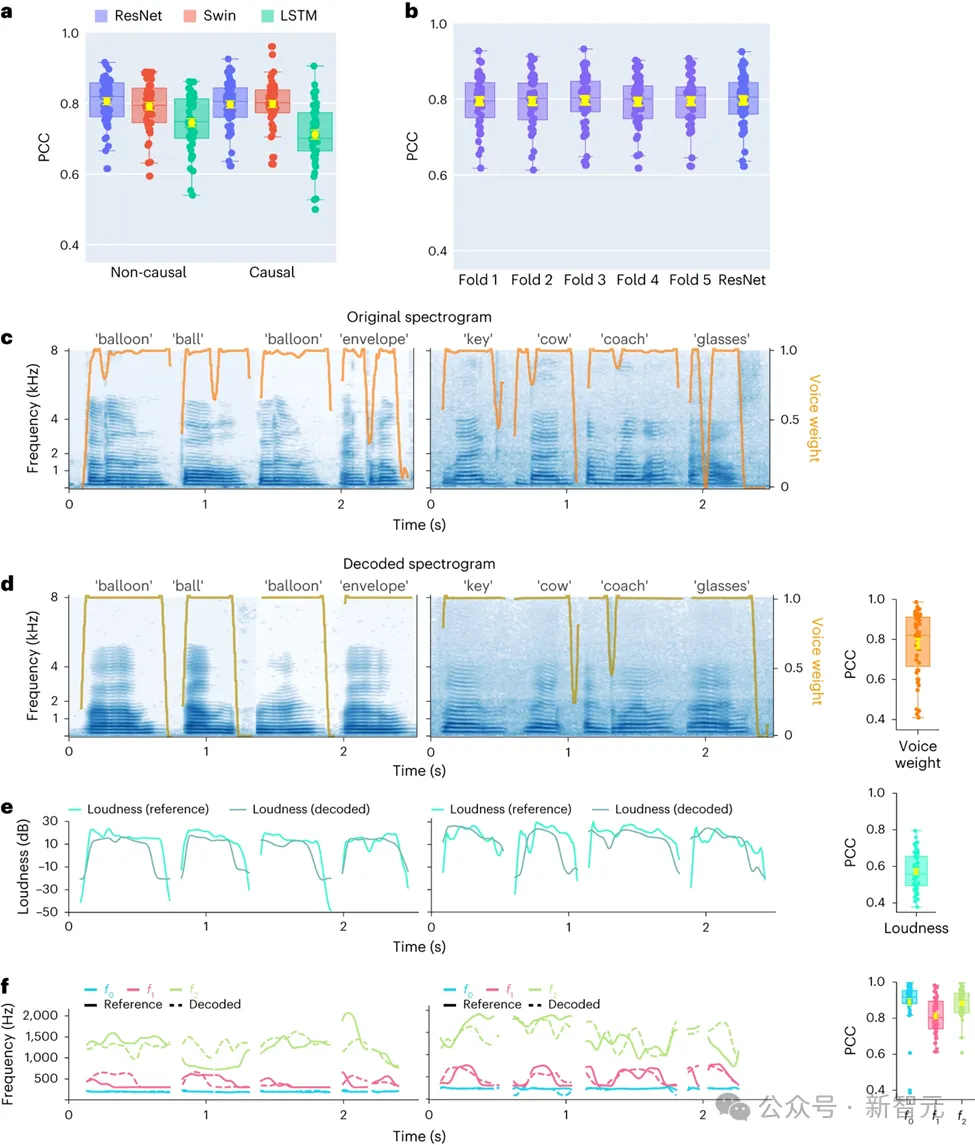
在此项研究中,研究者首先对不同的模型架构进行了直接比较,包括卷积网络(ResNet)、循环神经网络(LSTM)和Transformer架构(3D Swin),以评估它们在语音解码性能上的差异。
值得注意的是,这些模型均能执行时间序列上的非因果或因果操作。
 图片
图片
在大脑-计算机接口(BCI)的应用中,解码模型的因果性具有重要意义:因果模型只利用过去和当前的神经信号来生成语音,而非因果模型还会参考未来的神经信号,这在实际操作中是不可行的。
因此,研究的重点在于比较同一模型在执行因果和非因果操作时的性能表现。结果显示,即使是因果版本的ResNet模型,其性能也能与非因果版本相媲美,二者之间没有显着的性能差异。
类似地,Swin模型的因果和非因果版本性能相近,但LSTM的因果版本在性能上显着低于其非因果版本。研究还展示了几个关键的语音参数的平均解码准确率(总样本数为48),包括声音权重(区分元音和辅音的参数)、响度、基频f0、第一共振峰f1和第二共振峰f2。
准确地重建这些语音参数,特别是基频、声音权重和前两个共振峰,对于实现精确的语音解码和自然地重现参与者声音至关重要。
研究结果表明,无论是非因果还是因果模型,都能提供合理的解码效果,这为未来的相关研究和应用提供了积极的启示。
研究者在最新的研究中进一步探索了左右大脑半球在语音解码上的性能差异。
传统上,大多数研究主要集中在与语音和语言功能密切相关的左脑半球。
 图片
图片
然而,关于右脑半球在语言信息解码方面的能力,我们了解的还很有限。为了探索这一领域,研究团队比较了参与者左右脑半球的解码性能,验证了使用右脑半球进行语音恢复的可行性。
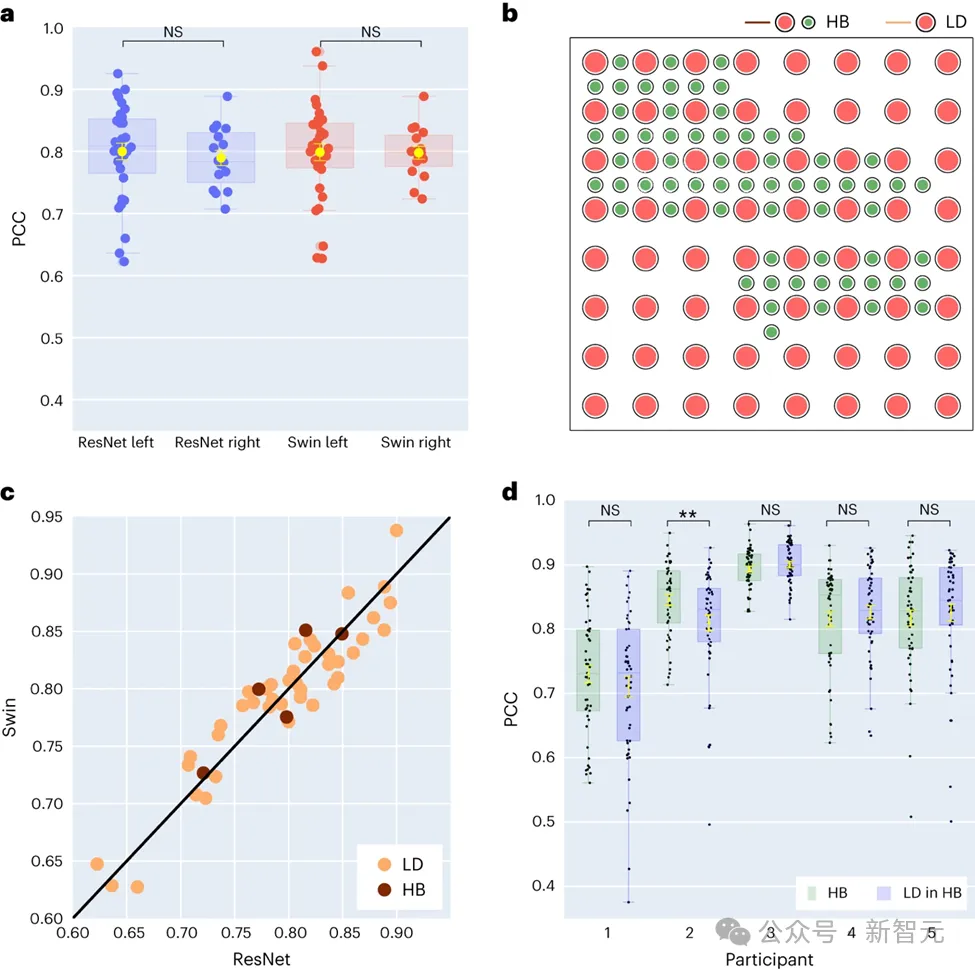
在研究中收集的48位受试者中,16位的ECoG信号来自右脑。研究者通过比较使用ResNet和Swin解码器的性能,发现右脑半球同样能够有效地进行语音解码,其效果与左脑半球相近。这一发现为那些左脑受损且失去语言功能的患者提供了一种可能的语言恢复方案。
研究还涉及到了电极采样密度对语音解码效果的影响。以往的研究多使用较高密度的电极网格(0.4 mm),而在临床实践中常用的电极网格密度则较低(1 cm)。
本研究中有五位参与者使用了混合类型(HB)的电极网格,这类网格主要是低密度,但添加了一些额外的电极。其余四十三位参与者均使用了低密度采样。
结果显示,这些混合采样(HB)的解码表现与传统的低密度采样(LD)相近,表明模型能够有效地从不同密度的大脑皮层电极网格中学习语音信息。这一发现暗示了在临床常用的电极采样密度可能已足够支持未来的脑机接口应用。
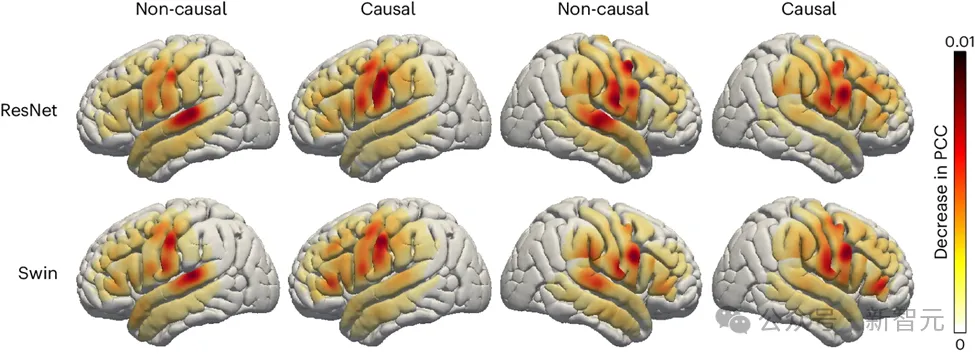
研究者还探讨了大脑中与语音相关区域在语音解码过程中的作用,这一点对于将来可能在左右脑半球植入语音恢复设备具有重要意义。为了评估不同大脑区域对语音解码的影响,研究团队采用了遮挡技术(occlusion analysis)。
通过对ResNet和Swin解码器的因果与非因果模型进行比较,研究发现,在非因果模型中,听觉皮层的作用更加显着。这一结果强调了在实时语音解码应用中使用因果模型的必要性,因为实时应用无法依赖未来的神经反馈信号。
 图片
图片
此外,研究也显示,无论在大脑的左半球还是右半球,传感运动皮层特别是腹部区域对语音解码的贡献度都相似。这一发现表明,在右半球植入神经假肢来恢复语音可能是一个可行的方案,提供了对未来治疗策略的重要见解。
研究团队开发了一种新型的可微分语音合成器,这一合成器使用轻型卷积神经网络将语音编码为一系列可解释的参数,如音高、响度和共振峰频率等,并利用同一可微分合成器对语音进行重新合成。
通过将神经信号映射到这些参数上,研究者们构建了一个高度可解释并适用于小数据集的神经语音解码系统,能够生成自然听感的语音。
这一系统在48名参与者中表现出高度的可复现性,能够处理不同空间采样密度的数据,并能同时处理左、右脑半球的脑电信号,展示了其在语音解码方面的强大潜力。
尽管取得了显著进展,研究者也指出了模型当前的一些局限性,如解码过程依赖于与ECoG记录配对的语音训练数据,这对于失语症患者可能不适用。
未来,研究团队希望建立能够处理非网格数据的模型架构,并更有效地利用多病人、多模态的脑电数据。随着硬件技术的持续进步和深度学习技术的快速发展,脑机接口领域的研究仍处于早期阶段,但随着时间的推移,科幻电影中的脑机接口设想将逐步成为现实。
https://www.nature.com/articles/s42256-024-00824-8
本文第一作者:Xupeng Chen (xc1490@nyu.edu), Ran Wang,通讯作者:Adeen Flinker
更多关于神经语音解码中的因果性讨论,可以参考作者们的另一篇论文:
https://www.pnas.org/doi/10.1073/pnas.2300255120
以上是LeCun转发,AI让失语者重新说话!纽约大学发布全新「神经-语音」解码器的详细内容。更多信息请关注PHP中文网其他相关文章!





















