
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
指代分割(Referring Image Segmentation,RIS) 是一项极具挑战性的多模态任务,要求算法能够同时理解精细的人类语言和视觉图像信息,并将图像中句子所指代的物体进行像素级别的分割。 RIS 技术的突破有望在人机交互、图像编辑、自动驾驶等诸多领域带来革命性变革。它能够极大地提升人机协作的效率和体验。尽管目前最先进的 RIS 算法已经取得了显着进展,但仍然面临着模态差异 (modality gap) 的问题,即图像和文本特征的分布并未完全对齐。这一问题在处理复杂的指代语言表达和罕见语境时尤为突出。 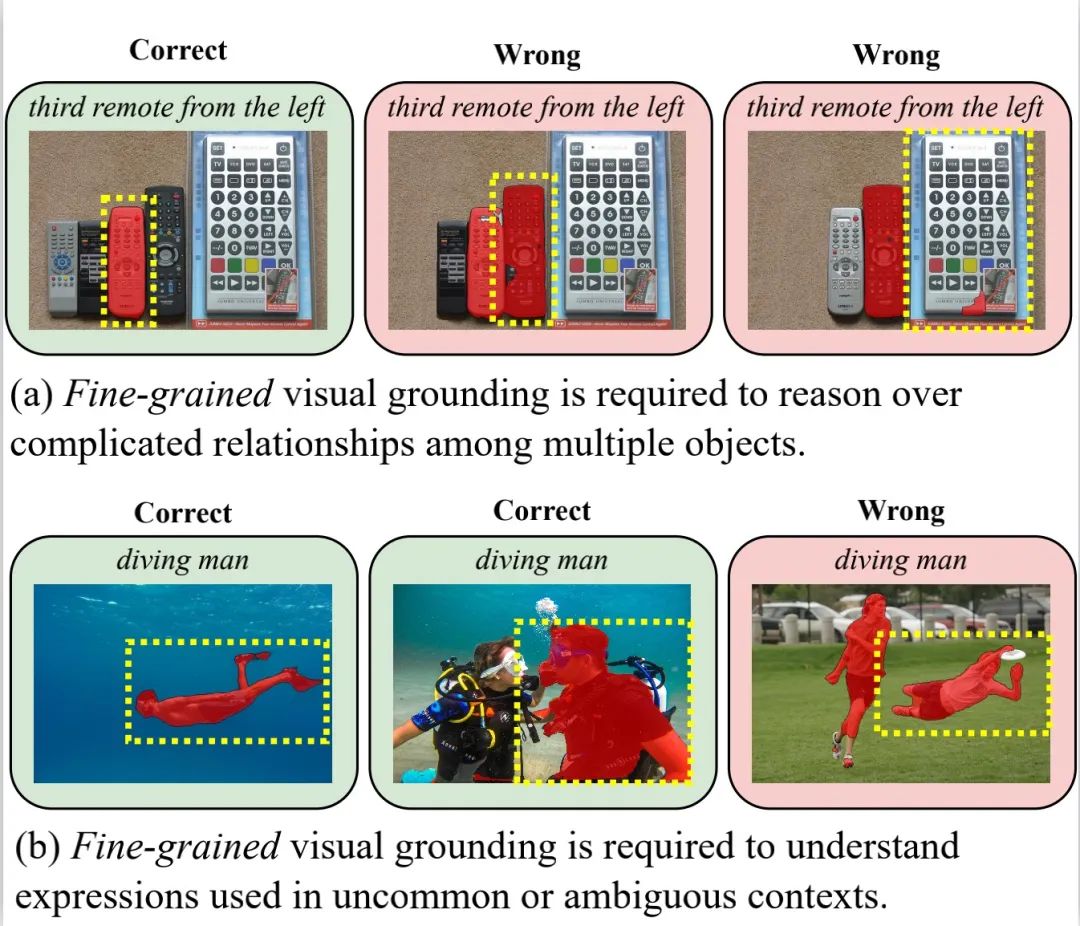
图 1:细粒度语言 - 图像对齐能力对 RIS 的重要性示意图。红色掩码是目前最先进的 RIS 算法之一 LAVT 的预测结果,而黄色虚线框则是正确的标注。 目前的RIS 研究主要集中在设计新颖的损失函数或引入创新的网络架构/ 模块,以增强语言- 图像的分布对齐。尽管取得了显着进展,但仍存在两个根本性问题,导致它们在细粒度语言- 图像对齐(Fine-grained Visual Grounding)方面能力不足: 1. 这些方法主要依赖于句子级别的语言特征进行语言- 图像对齐,导致它们在文字级别的语言- 图像对齐能力较为薄弱。 2. 这些方法在训练过程中往往缺乏显式的监督信号,无法有效地教会模型进行细粒度对齐,导致它们在处理复杂的指代语言时表现不佳。 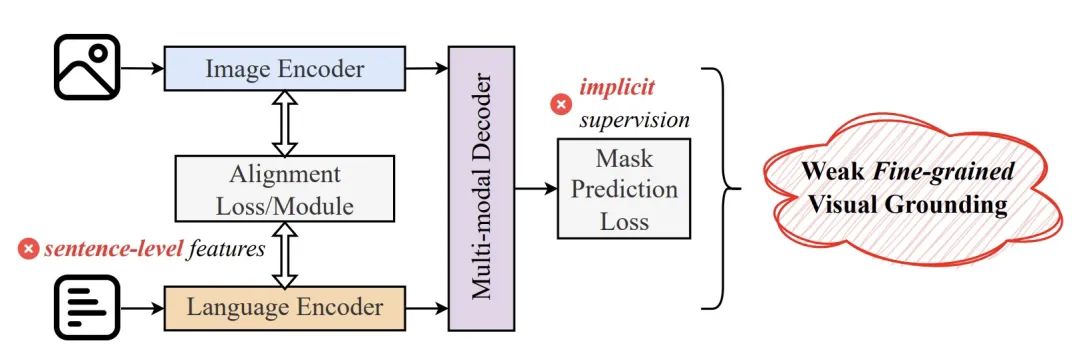
在近期一篇CVPR 2024 工作中,来自清华大学自动化系和博世中央研究院的联合研究团队设计了一种新的辅助任务Mask Grounding。通过随机掩码部分文本词汇,并让算法学习预测其真实身份,这一任务旨在显式地教会模型学习文本与视觉对象之间的细粒度对应关系。除此之外,他们还提出了一个新颖的跨模态对齐模块(Cross-modal Alignment Module)和一个新颖的跨模态对齐损失函数(Cross-modal Alignment Loss),来进一步全面缩小语言和图像之间的模态差距。基于这些技术,他们设计了一个全新的实例分割网络架构 Mask-grounded Network (MagNet)。 
- 论文标题:Mask Grounding for Referring Image Segmentation
- 论文地址:https://arxiv .org/abs/2312.12198
在RefCOCO、RefCOCO 和G-Ref 数据集上,MagNet 大幅超越了所有之前最优的算法,在整体交并比(oIoU) 这项核心指标上显着提升了2.48 个百分点。可视化结果也证实,MagNet 在处理复杂场景和语言表达时具有出色的表现。 MagNet 由3 个独立互补的模块组成,分别为Mask Grounding,Cross-modal Alignment Module 和Cross-modal Alignment Loss。 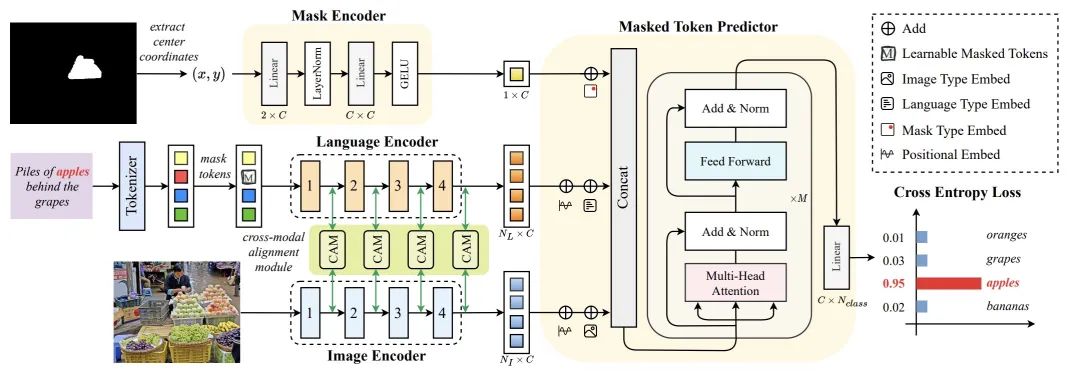
如图 3 所示,在给定输入图像、对应的指代表达以及分割掩码的情况下,作者随机选取句子中的某些词汇,并将其替换为一个特殊的可学习掩码 token。然后,训练模型来预测这些被替换词汇的实际身份。通过成功预测被掩码 token 的身份,模型能够理解文本中的哪些词汇对应于图像的哪些部分,从而在此过程中学习细粒度语言 - 图像对齐能力。为了执行这一辅助任务,首先提取掩码区域的中心坐标,并将其传递给一个 2 层 MLP,以编码分割掩码的特征。同时,使用线性层将语言特征映射到与图像特征相同的维度。然后,使用提出的掩码 token 预测器联合处理这些特征,并使用注意力机制模块来进行掩码 token 预测。虽然 Mask Grounding 需要通过语言编码器进行额外的前向传递来处理被掩码的表达式,但由于语言编码器非常小,整体计算成本几乎可以忽略不计。2.Cross-modal Alignment Module (CAM)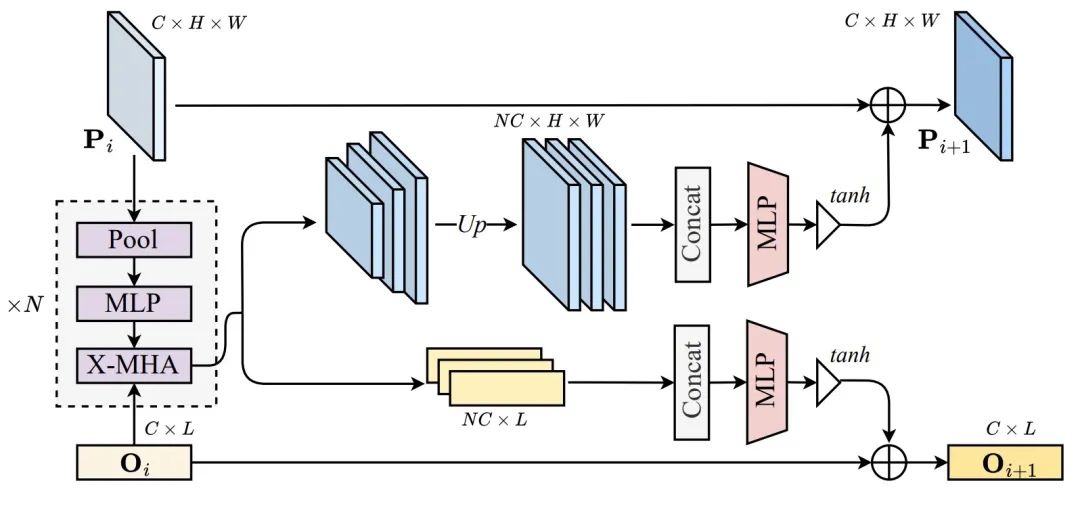
图 4:Cross-modal Alignment Module 结构图如图 4 所示,为了进一步提升模型性能,作者还提出了跨模态对齐模块(CAM),通过在执行语言 - 图像融合之前将全局上下文先验注入图像特征来增强语言 - 图像对齐效果。CAM 首先使用不同窗口大小的池化操作生成 K 个不同金字塔尺度的特征图。然后,每个特征图通过一个 3 层 MLP 以更好地提取全局信息,并与另一模态进行交叉注意力操作。接下来,所有输出特征通过双线性插值上采样到原始特征图尺寸,并在通道维度上拼接。随后,使用一个 2 层 MLP 将拼接后的特征通道数减少回原始维度。为了防止多模态信号淹没原始信号,使用一个带有 Tanh 非线性的门控单元来调制最终输出。最后,这个门控后的特征被加回到输入特征中,然后传递给图像或语言编码器的下一阶段。在作者的实现中,CAM 被加到图像和语言编码器的每个阶段末尾。3.Cross-modal Alignment Loss (CAL)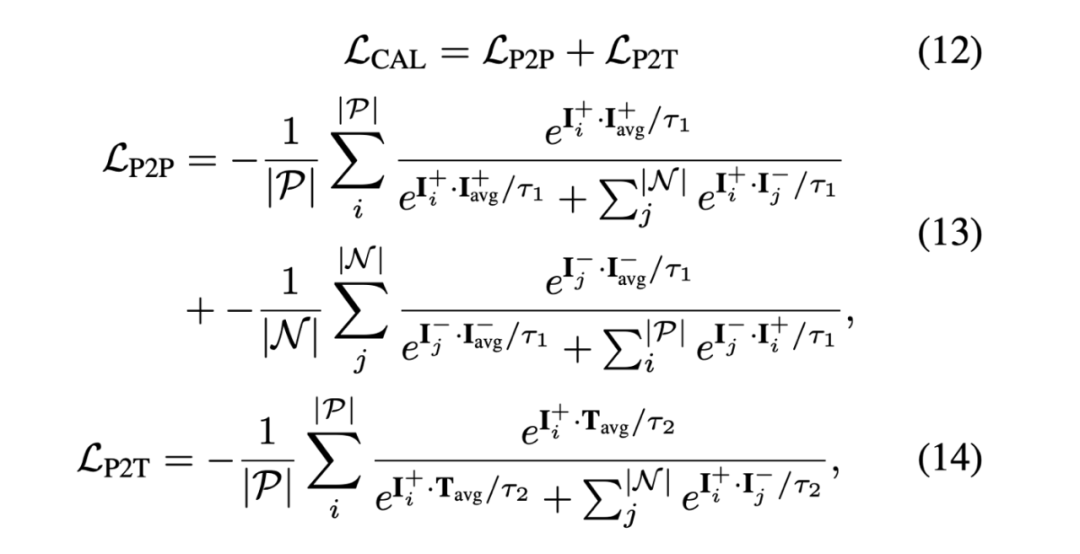
图 5:Cross-modal Alignment Loss 公式为了监督模型对齐语言和图像特征,作者提出了一种新颖的跨模态对齐损失函数 (CAL)。图五展示了该损失函数的数学公式。与之前工作不同,CAL 同时考虑了像素到像素 (Pixel-to-Pixel,P2P) 和像素到文本 (Pixel-to-Text,P2T) 之间的对齐。精确的像素到像素对齐能确保模型能分割输出具有准确形状和边界的分割掩码,而精确的像素到文本对齐能使模型能够正确地将文本描述与其匹配的图像区域进行合理的关联。在表 1 中,作者使用 oIoU 指标评估 MagNet,并与现有最先进的算法做性能比较。测试数据为 RefCOCO、RefCOCO 和 G-Ref。在单一和多个 / 额外数据集的设置下,MagNet 的性能在这些数据集上全都是 SOTA。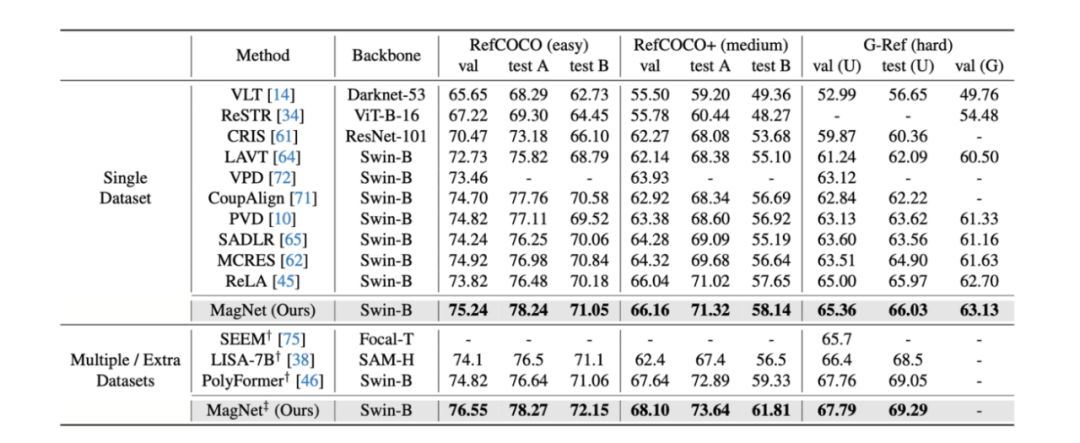
可视化结果 在图6 中,我们可以看到,MagNet 的可视化结果也非常突出,在许多困难的场景中都比对比基准LAVT 强很多。 这篇文章深入探讨了指代分割(RIS)领域的挑战和当前存在的问题,特别是在细粒度语言- 图像对齐方面的不足。针对这些问题,清华大学和博世中央研究院的研究人员提出了一种新的方法,名为MagNet,通过引入辅助任务Mask Grounding、跨模态对齐模块和跨模态对齐损失函数,全面提升了语言和图像之间的对齐效果。实验证明,MagNet 在 RefCOCO、RefCOCO 和 G-Ref 数据集上均取得了显着优异的性能,超越了之前最先进的算法,表现出了强大的泛化能力。可视化结果也证实了 MagNet 在处理复杂场景和语言表达时的优越性。这一研究为指代分割领域的进一步发展提供了有益的启示,有望推动该领域取得更大的突破。 此论文来源于清华大学自动化系(https:/ /www.au.tsinghua.edu.cn)和博世中央研究院(https://www.bosch.com/research/)。其中论文一作庄荣贤为清华大学在读博士生,并在博世中央研究院实习;项目负责人为邱旭冲博士,任博世中央研究院资深研发科学家;通讯作者为清华大学自动化系黄高教授。
在图6 中,我们可以看到,MagNet 的可视化结果也非常突出,在许多困难的场景中都比对比基准LAVT 强很多。 这篇文章深入探讨了指代分割(RIS)领域的挑战和当前存在的问题,特别是在细粒度语言- 图像对齐方面的不足。针对这些问题,清华大学和博世中央研究院的研究人员提出了一种新的方法,名为MagNet,通过引入辅助任务Mask Grounding、跨模态对齐模块和跨模态对齐损失函数,全面提升了语言和图像之间的对齐效果。实验证明,MagNet 在 RefCOCO、RefCOCO 和 G-Ref 数据集上均取得了显着优异的性能,超越了之前最先进的算法,表现出了强大的泛化能力。可视化结果也证实了 MagNet 在处理复杂场景和语言表达时的优越性。这一研究为指代分割领域的进一步发展提供了有益的启示,有望推动该领域取得更大的突破。 此论文来源于清华大学自动化系(https:/ /www.au.tsinghua.edu.cn)和博世中央研究院(https://www.bosch.com/research/)。其中论文一作庄荣贤为清华大学在读博士生,并在博世中央研究院实习;项目负责人为邱旭冲博士,任博世中央研究院资深研发科学家;通讯作者为清华大学自动化系黄高教授。 以上是CVPR 2024 | 擅长处理复杂场景和语言表达,清华&博世提出全新实例分割网络架构MagNet的详细内容。更多信息请关注PHP中文网其他相关文章!























