

原标题:LidarDM: Generative LiDAR Simulation in a Generated World
论文链接:https://arxiv.org/pdf/2404.02903.pdf
代码链接:https://github.com/vzyrianov/lidardm
作者单位:伊利诺伊大学 麻省理工学院

本文介绍了LidarDM,这是一种新颖的激光雷达生成模型,能够产生逼真、布局感知、物理可信以及时间上连贯的激光雷达视频。LidarDM在激光雷达生成建模方面具有两个前所未有的能力:(一)由驾驶场景引导的激光雷达生成,为自动驾驶模拟提供了重大激励;(二)4D激光雷达点云生成,使得创建逼真且时间上连贯的激光雷达序列成为可能。本文模型的核心是一个新颖的综合4D世界生成框架。具体来说,本文采用隐性扩散模型(latent diffusion models)来生成3D场景,将其与动态参与者(dynamic actors)结合,形成底层的4D世界,然后在这个虚拟环境中产生逼真的激光感知数据。本文的实验表明,本文的方法在逼真度、时间连贯性和布局一致性方面优于竞争算法。本文还展示了LidarDM可作为生成世界模拟器,用于训练和测试感知模型。
制定出的生成模型在处理数据分布和内容创作方面已经越来越引起人们的关注,例如在图像和视频生成[10, 33, 52-55]、3D物体生成[10,19,38,52]、压缩[5,29,68]以及编辑[37,47]等领域。生成模型对于模拟[6, 11, 18, 34, 46, 60, 64, 66, 76, 82]也表现出出色的潜力,能够创建逼真的场景及其相关的感知数据,用于训练和评估安全关键的智能能力,如机器人和自动驾驶车辆,无需昂贵的手工建模现实世界。这些能力对于依赖广泛的环境训练或场景测试的应用至关重要。
在条件图像和视频生成方面的进展非常显著,但自动驾驶应用生成功能特定场景下逼真的激光雷达点云序列的具体任务仍未得到充分探索。目前的激光雷达生成方法主要分为两大类,每一类都面临着特定的挑战。
为了应对这些挑战,本文提出了 LidarDM(激光雷达扩散模型),它能够创造出逼真的、布局感知的、物理上可信的、以及时间上连贯的激光雷达视频。本文探索了两种以前未曾涉及的新颖能力:(i)由驾驶场景引导的激光雷达合成,这对自动驾驶仿真具有巨大潜力,以及(ii)旨在产生逼真的、有标注的激光雷达点云序列的 4D 激光雷达点云合成。本文实现了这些目标的关键洞察在于首先生成和组合底层的 4D 世界,然后在这个虚拟环境中创造逼真的感知观察。为了实现这一点,本文整合了现有的 3D 物体生成方法来创造动态交通参与者(dynamic actors),并开发了一种基于潜扩散模型(latent diffusion models)的大规模 3D 场景生成的新方法。这种方法能够从粒子的语义布局中产生逼真多样化的 3D 驾驶场景,据本文所知,这是首次尝试。本文应用轨迹生成 3D 世界,并执行随机光线投射模拟(stochastic raycasting simulation)以生成最终的 4D 激光雷达序列。如图1所示,本文生成的结果多样化,与布局条件对齐,既逼真又时间上连贯。
本文的实验结果表明,由 LidarDM 生成的单帧图像展现出逼真性和多样性,其性能与最先进的无条纹单帧激光达点云生成技术相当。此外,本文展示了 LidarDM 能够产生保持时间连贯性的激光达点云视频,超越了稳健的 stable diffusion 传感器生成基线。据本文所知,这是第一个具备此能力的激光达点云生成方法。本文进一步通过展示生成的激光达点云与真实激光达点云在匹配地图条目下的良好吻合,来证明 LidarDM 的条目生成能力。最后,本文说明了使用 LidarDM 生成的数据在用真实数据训练的感知模块测试时展现出最小的域差距,并且还可以用来扩展训练数据,显著提升 3D 检测器的性能。这为使用生成的激光达点云模型创建逼真且可控的仿真环境以训练和测试驾驶模型提供了前提。
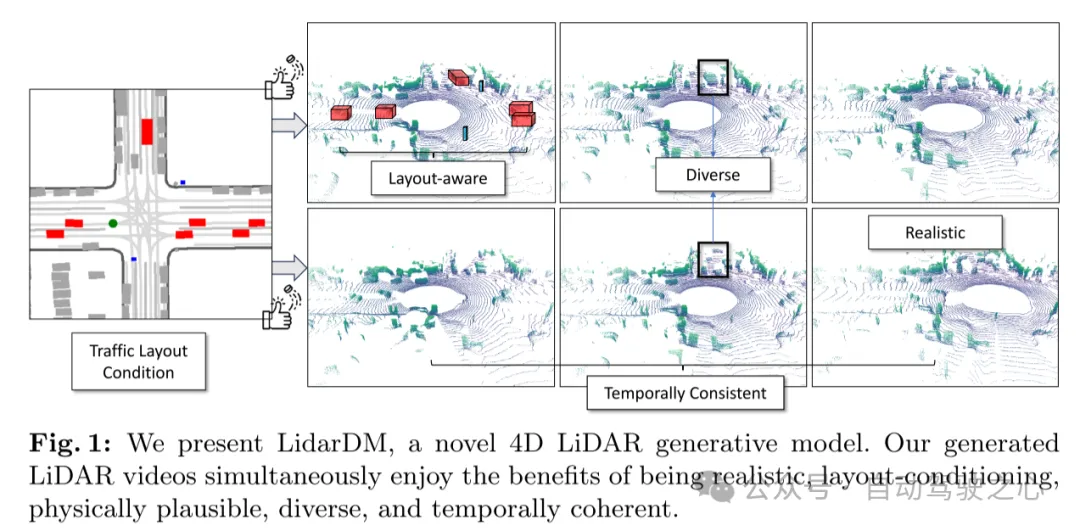
图 1:本文展示了 LidarDM,这是一个新颖的 4D 激光雷达生成模型。本文生成的激光雷达视频同时具有逼真性、布局条件性、物理可信性、多样性和时间连贯性的优势。
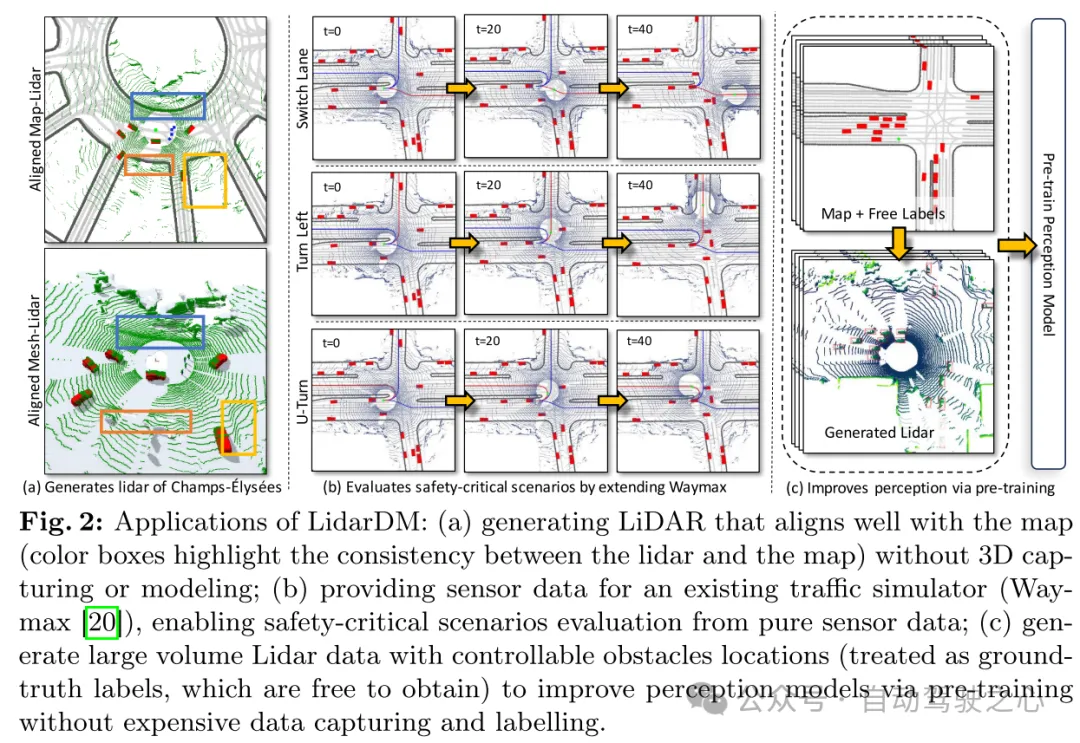
图 2:LidarDM 的应用:(a) 在没有 3D 捕捉或建模的情况下生成与地图紧密对齐的激光雷达(彩色框突出显示激光雷达与地图之间的一致性);(b) 为现有的交通模拟器(Waymax [20])提供传感器数据,使其能够仅从纯传感器数据评估安全关键场景;(c) 生成具有可控障碍物位置的大量激光雷达数据(被视为免费获得的真实标签),以通过无需昂贵数据捕捉和标注的预训练改进感知模型。
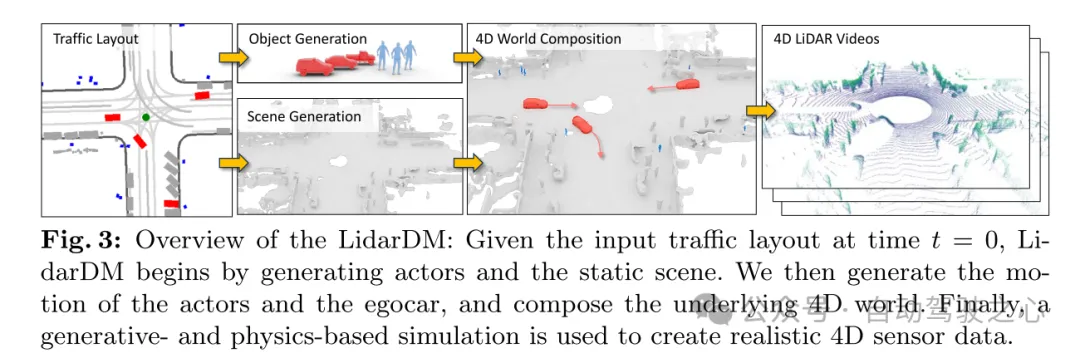
图 3:LidarDM 概览:给定时间 t = 0 时的交通布局输入,LidarDM 首先生成交通参与者(actors)和静态场景。然后,本文生成交通参与者(actors)和自车的运动,并构建底层的 4D 世界。最后,使用基于生成和物理的仿真来创建逼真的 4D 传感器数据。
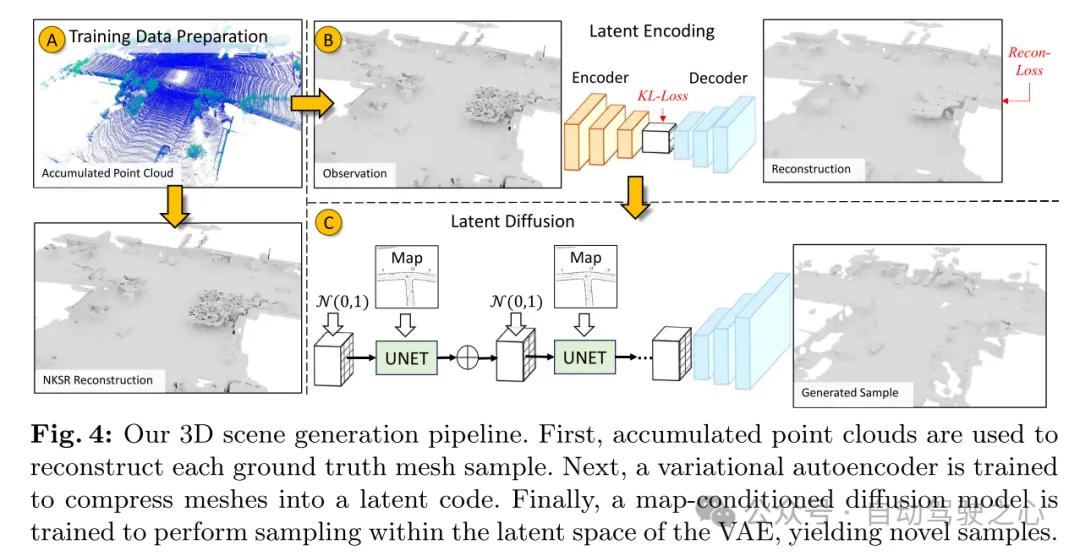
图 4:本文的 3D 场景生成流程。首先,累积的点云被用于重建每个真实网格样本。接下来,训练一个变分自编码器(VAE)将网格压缩成隐式编码。最后,训练一个以地图为条件的扩散模型,在 VAE 的隐空间内进行采样,产生新的样本。
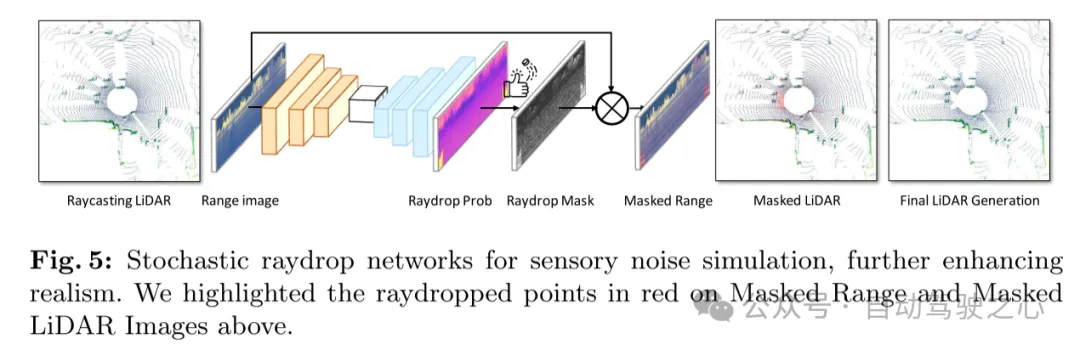
图 5:用于感知噪声模拟的随机光线丢弃(raydrop)网络,进一步增强了真实感。本文在上方的掩码距离图和掩码激光雷达图像中用红色突出显示了光线丢弃的(raydropped)点。

图 6:真实的 KITTI-360 样本与来自竞争方法的无条件样本对比。UltraLiDAR 样本可视化直接从它们的论文中获取。与之前的方法相比,LidarDM 生成的样本具有更多数量、更详细的显著物体(例如,汽车、行人)、更清晰的 3D 结构(例如,直墙)以及更逼真的道路布局。
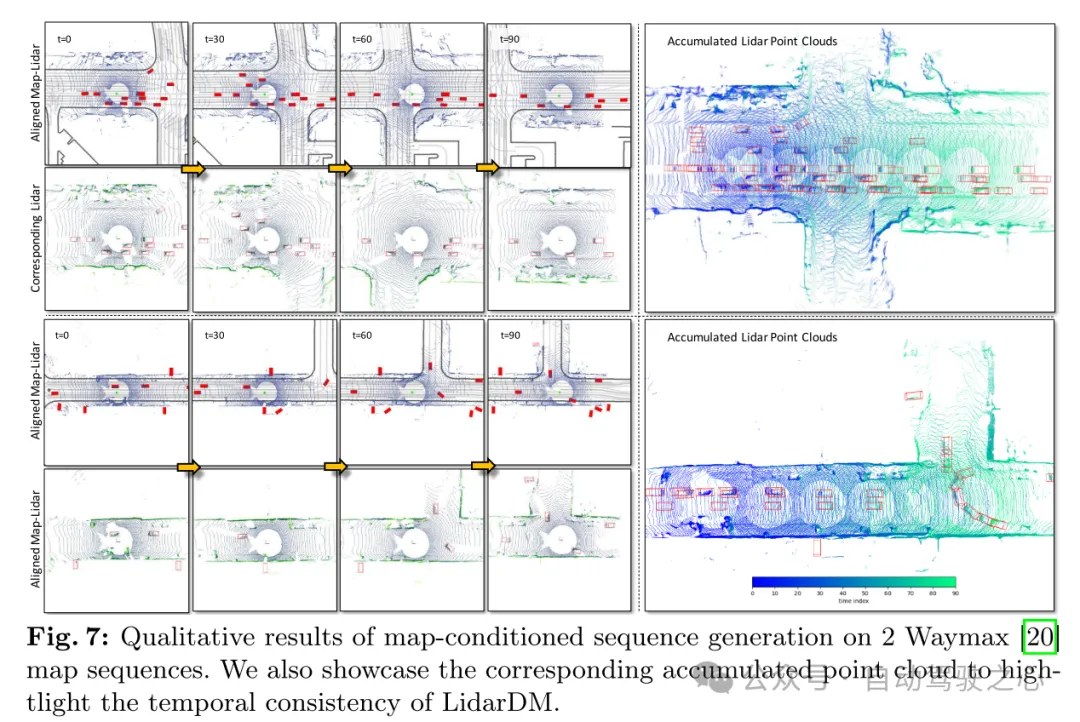
图 7:在 2 Waymax [20] 地图序列上进行的以地图为条件的序列生成的定性结果。本文还展示了相应的累积点云,以突出 LidarDM 的时序一致性。

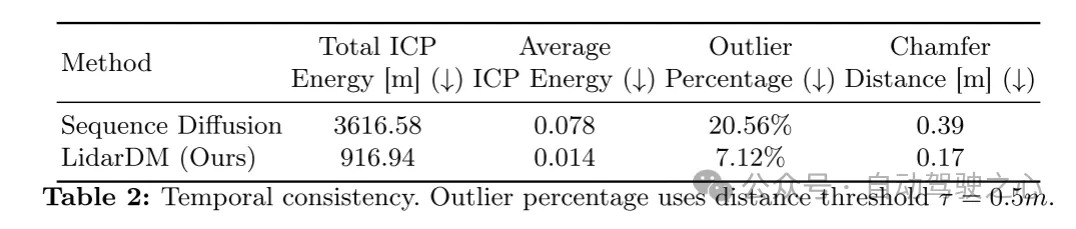


本文提出了 LidarDM,这是一个新颖的基于布局条件的隐扩散模型(latent diffusion models) ,用于生成逼真的激光雷达点云。本文的方法将问题框定为一个联合的 4D 世界创建和感知数据生成任务,并开发了一个新颖的隐扩散模型(latent diffusion models) 来创建 3D 场景。由此产生的点云视频是真实的、连贯的,并且具有布局感知(layout-aware)能力。
以上是LiDAR仿真新思路 | LidarDM:助力4D世界生成,仿真杀器~的详细内容。更多信息请关注PHP中文网其他相关文章!


































