

译者 |陈峻
审校 | 重楼
最近,我们实施了一个定制化的人工智能(AI)项目。鉴于甲方持有着非常敏感的客户信息,为了安全起见,我们不能将它们传递给OpenAI或其他专有模型。因此,我们在AWS虚拟机中下载并运行了一个开源的AI模型,使之完全处于我们的控制之下。同时,Rails应用可以在安全的环境中,对AI进行API调用。当然,如果不必考虑安全问题,我们更倾向于直接与OpenAI合作。

下面,我将和大家分享如何在本地下载开源的AI模型,让它运行起来,以及如何针对其运行Ruby脚本。
这个项目的动机很简单:数据安全。在处理敏感的客户信息时,最可靠的做法通常是在公司内部进行。因此,我们需要定制化的AI模型,在提供更高级别的安全控制和隐私保护方面发挥作用。
在过去的6个月里,市场上出现了诸如:Mistral、Mixtral和Lama等大量开源的AI模型。它们虽然没有GPT-4那么强大,但是其中不少模型的性能已经超过了GPT-3.5,而且随着时间的推移,它们会越来越强。当然,该选用哪种模型,则完全取决于您的处理能力和需要实现的目标。
由于我们将在本地运行AI模型,因此选择了大小约为4GB的Mistral。它在大多数指标上都优于GPT-3.5。尽管Mixtral的性能优于Mistral,但它是一个庞大的模型,至少需要48GB内存才能运行。
在谈论大语言模型(LLM)时,我们往往会考虑提到它们的参数大小。在此,我们将在本地运行的Mistral模型是一个70亿参数的模型(当然,Mixtral拥有700亿个参数,而GPT-3.5大约有1750亿个参数)。
通常,大型语言模型使用基于神经网络的技术。神经网络是由神经元组成的,每个神经元与下一层的所有其他神经元相连。
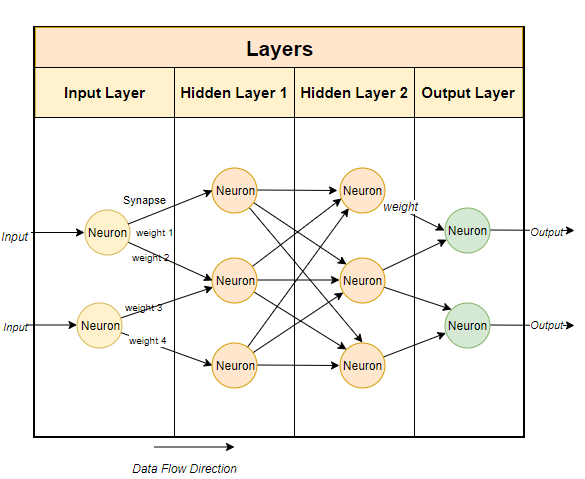
如上图所示,每个连接都有一个权重,通常用百分比表示。每个神经元还有一个偏差(bias),当数据通过某个节点时,偏差会对数据进行修正。
神经网络的目的是要“学到”一种先进的算法、一种模式匹配的算法。通过在大量文本中接受训练,它将逐渐学会预测文本模式的能力,进而对我们给出的提示做出有意义的回应。简单而言,参数就是模型中权重和偏差的数量。它可以让我们了解神经网络中有多少个神经元。例如,对于一个70亿参数的模型来说,大约有100层,每层都有数千个神经元。
要在本地运行开源模型,首先必须下载相关应用。虽然市场上有多种选择,但是我发现最简单,也便于在英特尔Mac上运行的是Ollama。
虽然Ollama目前只能在Mac和Linux上运行,不过它未来还能运行在Windows上。当然,您可以在Windows上使用WSL(Windows Subsystem for Linux)来运行Linux shell。
Ollama不但允许您下载并运行各种开源模型,而且会在本地端口上打开模型,让您能够通过Ruby代码进行API调用。这便方便了Ruby开发者编写能够与本地模型相集成的Ruby应用。
由于Ollama主要基于命令行,因此在Mac和Linux系统上安装Ollama非常简单。您只需通过链接//m.sbmmt.com/link/04c7f37f2420f0532d7f0e062ff2d5b5下载Ollama,花5分钟左右时间安装软件包,再运行模型即可。
在设置并运行Ollama之后,您将在浏览器的任务栏中看到Ollama图标。这意味着它正在后台运行,并可运行您的模型。为了下载模型,您可以打开终端并运行如下命令:
ollama run mistral
由于Mistral约有4GB大小,因此您需要花一段时间完成下载。下载完成后,它将自动打开Ollama提示符,以便您与Mistral进行交互和通信。
下一次您再通过Ollama运行mistral时,便可直接运行相应的模型了。
类似我们在OpenAI中创建自定义的GPT,通过Ollama,您可以对基础模型进行定制。在此,我们可以简单地创建一个自定义的模型。更多详细案例,请参考Ollama的联机文档。
首先,您可以创建一个Modelfile(模型文件),并在其中添加如下文本:
FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked questions about the Ruby Programminglanguage. You will provide an explanation along with code examples.”””
上面出现的系统消息是AI模型做出特定反应的基础。
接着,您可以在终端上运行如下命令,以创建新的模型:
ollama create-f './Modelfile
在我们的项目案例中,我将该模型命名为Ruby。
ollama create ruby -f './Modelfile'
同时,您可以使用如下命令罗列显示自己的现有模型:
ollama list
Ollama run ruby
虽然Ollama尚没有专用的gem,但是Ruby开发人员可以使用基本的HTTP请求方法与模型进行交互。在后台运行的Ollama可以通过11434端口打开模型,因此您可以通过“//m.sbmmt.com/link/dcd3f83c96576c0fd437286a1ff6f1f0”访问它。此外,OllamaAPI的文档也为聊天对话和创建嵌入等基本命令提供了不同的端点。
在本项目案例中,我们希望使用/api/chat端点向AI模型发送提示。下图展示了一些与模型交互的基本Ruby代码:
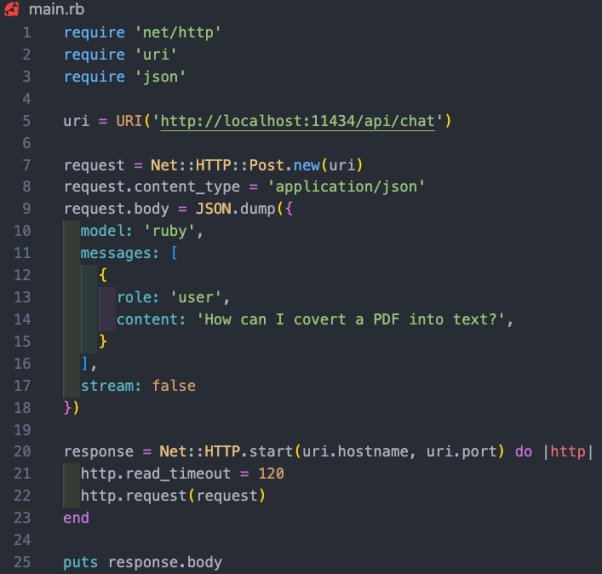
上述Ruby代码段的功能包括:
如上所述,运行本地AI模型的真正价值体现在,协助持有敏感数据的公司,处理电子邮件或文档等非结构化的数据,并提取有价值的结构化信息。在我们参加的项目案例中,我们对客户关系管理(CRM)系统中的所有客户信息进行了模型培训。据此,用户可以询问其任何有关客户的问题,而无需翻阅数百份记录。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How To Run Open-Source AI Models Locally With Ruby,作者:Kane Hooper
以上是为了保护客户隐私,使用Ruby在本地运行开源AI模型的详细内容。更多信息请关注PHP中文网其他相关文章!


































