

大语言模型(Large Language Models, LLMs)在过去两年内迅速发展,涌现出一些现象级的模型和产品,如 GPT-4、Gemini、Claude 等,但大多数是闭源的。研究界目前能接触到的大部分开源 LLMs 与闭源 LLMs 存在较大差距,因此提升开源 LLMs 及其他小模型的能力以减小其与闭源大模型的差距成为了该领域的研究热点。
LLM 的强大能力,特别是闭源 LLM,使得科研人员和工业界的从业者在训练自己的模型时都会利用到这些大模型的输出和知识。这一过程本质上是知识蒸馏(Knowledge, Distillation, KD)的过程,即从教师模型(如 GPT-4)中蒸馏知识到较小的模型(如 Llama)中,显着提升了小模型的能力。可以看出,大语言模型的知识蒸馏技术无处不在,且对于研究人员来说是一种性价比高、有效的方法,有助于训练和提升自己的模型。
那么,当前的工作如何利用闭源 LLM 进行知识蒸馏和获取数据?如何有效地将这些知识训练到小模型中?小模型能够获取教师模型的哪些强大技能?在具有领域特点的工业界,LLM 的知识蒸馏如何发挥作用?这些问题值得深入思考和研究。
在 2020 年,陶大程团队发表了《Knowledge Distillation: A Survey》,全面探讨了知识蒸馏在深度学习中的应用。该技术主要用于模型的压缩和加速。随着大型语言模型的兴起,知识蒸馏的应用领域得到了不断拓展,不仅能够提升小型模型的性能,还能实现模型自我提升。
2024 年初,陶大程团队与香港大学和马里兰大学等合作,发表了最新综述《A Survey on Knowledge Distillation of Large Language Models》,总结了374 篇相关工作,探讨了如何从大语言模型中获取知识,训练较小模型,以及知识蒸馏在模型压缩和自我训练中的作用。同时,该综述也涵盖了对大语言模型技能的蒸馏以及垂直领域的蒸馏,帮助研究者全面了解如何训练和提升自己的模型。

论文题目:A Survey on Knowledge Distillation of Large Language Models
论文链接:https: //arxiv.org/abs/2402.13116
项目链接:https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
综述架构
大语言模型知识蒸馏的整体框架总结如下图所示:
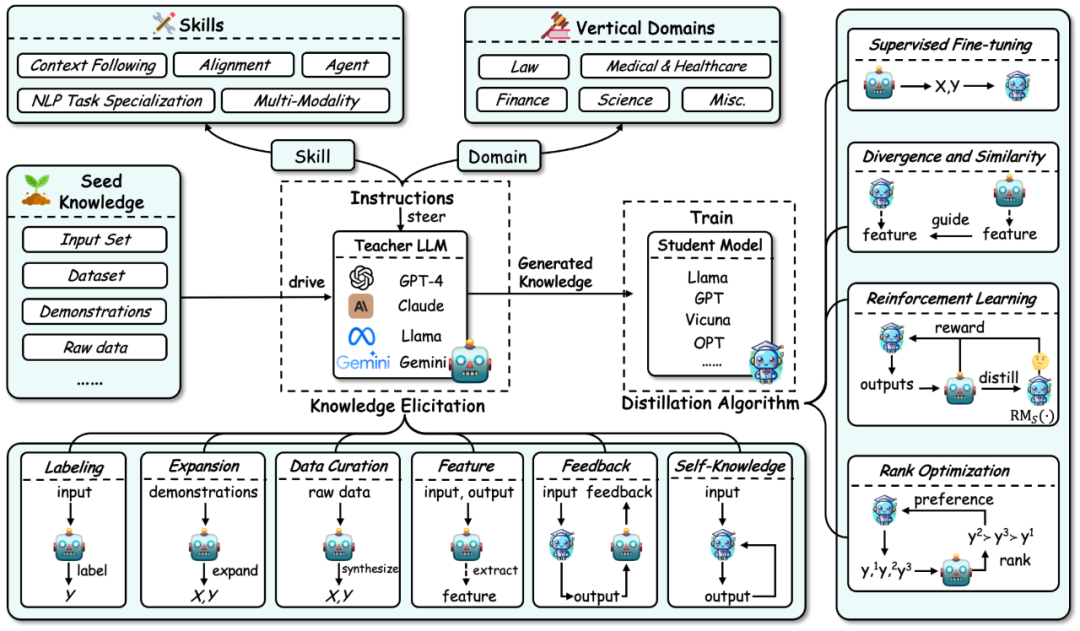
首先,根据大语言模型知识蒸馏的流程,该综述将知识蒸馏分解为了两个步骤:
1. 知识获取(Knowledge Elicitation):即如何从教师模型中获取知识。其过程主要包括:
a) 首先构建指令来确定要从教师模型中蒸馏的技能或垂直领域的能力。
b) 然后使用种子知识(如某个数据集)作为输入来驱动教师模型,生成对应的回应,从而将相应的知识引导出来。
c) 同时,知识的获取包含一些具体技术:标注、扩展、合成、抽取特征、反馈、自身知识。
2. 蒸馏算法(Distillation Algorithms):即如何将获取的知识注入到学生模型中。该部分具体算法包括:有监督微调、散度及相似度、强化学习(即来自 AI 反馈的强化学习,RLAIF)、排序优化。
该综述的分类方法根据此过程,将相关工作从三个维度进行了总结:知识蒸馏的算法、技能蒸馏、以及垂直领域的蒸馏。后两者都基于知识蒸馏算法来进行蒸馏。该分类的细节以及对应的相关工作总结如下图所示。
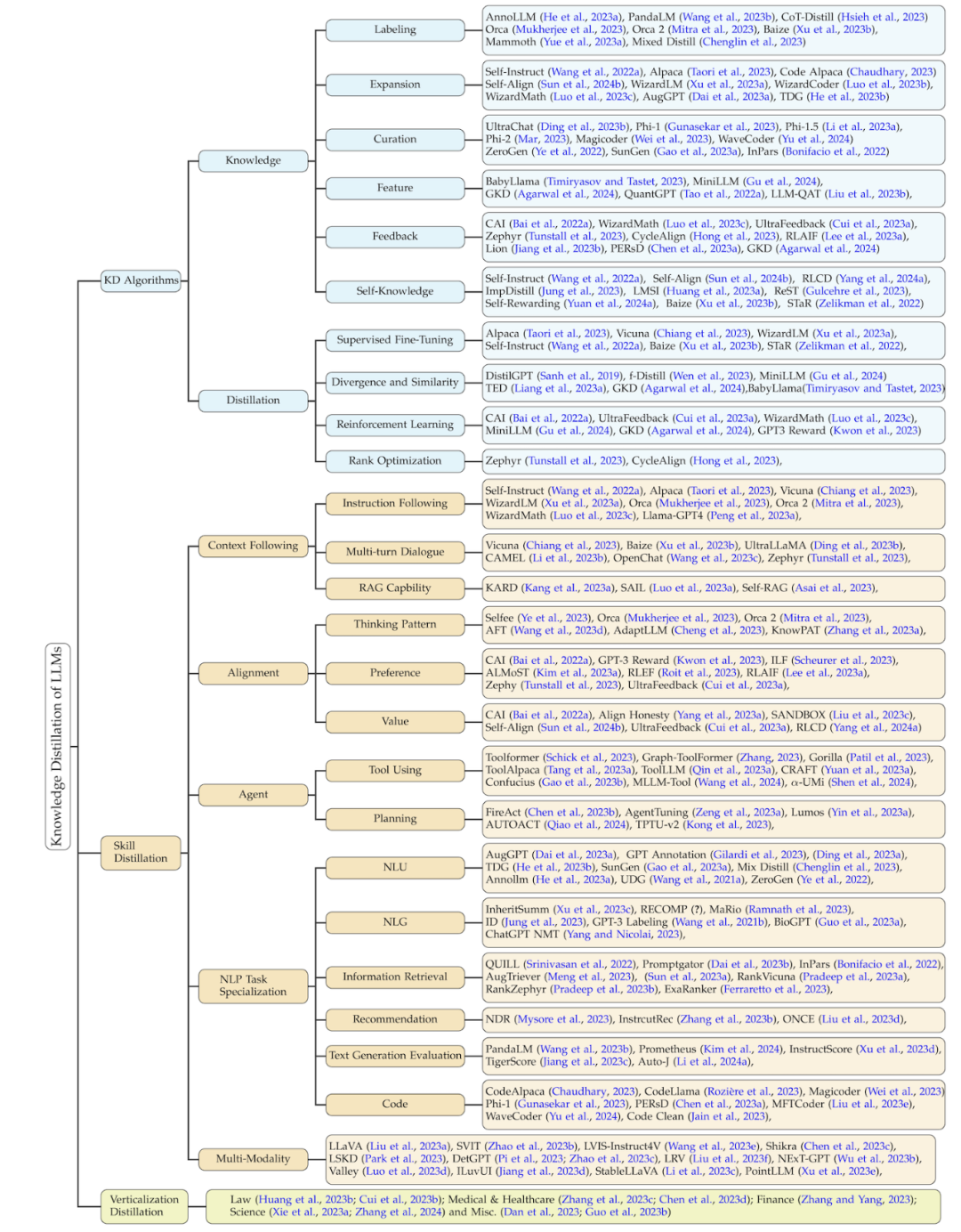
知识蒸馏算法
知识获取(Knowledge Elicitation)
根据从教师模型中获取知识的方式,该综述将其技术分为标注(Labeling)、扩展(Expansion)、数据合成(Data Curation)、特征抽取(Feature)、反馈(Feedback)、自生成的知识(Self- Knowledge)。每个方式的示例如下图所示:
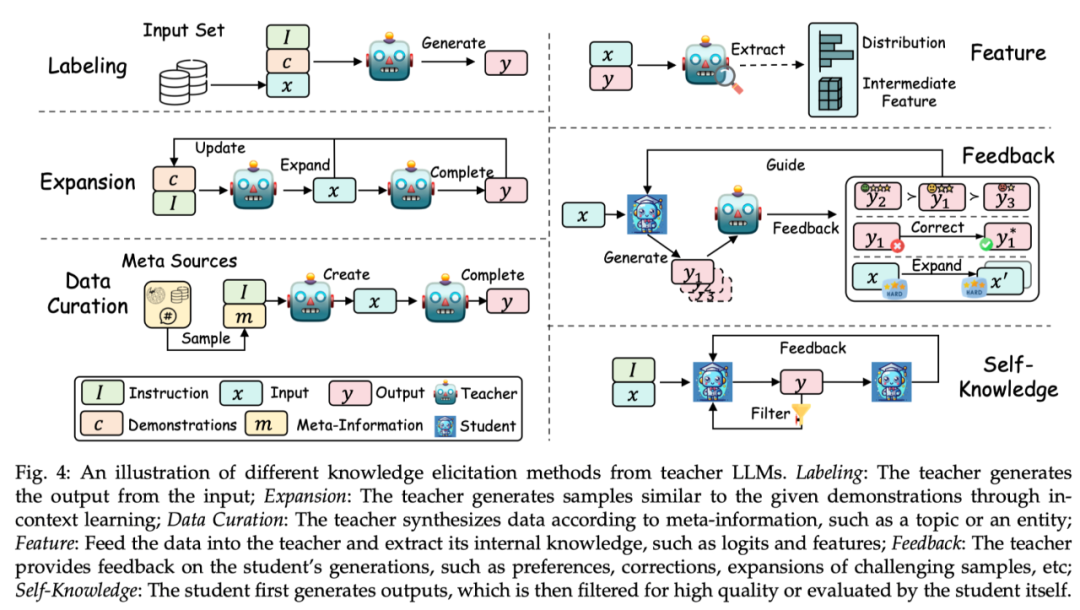
标注(Labeling):知识标注是指由教师 LLMs 根据指令或示例,对给定的输入作为种子知识,生成对应的输出。例如,种子知识为某一个数据集的输入,教师模型标注思维链输出。
扩展(Expansion):该技术的一个关键特征是利用 LLMs 的上下文学习能力,根据提供的种子示例,来生成与示例相似的数据。其优点在于通过示例能生成更加多样化和广泛的数据集。但是随着生成数据的继续增大,可能会造成数据同质化问题。
数据合成(Data Curation):数据合成的一个显着特点是其从零开始合成数据。其利用大量且多样的元信息(如话题、知文档、原始数据等)来作为多样且巨量的种子知识,以从教师 LLMs 中获取规模庞大而且质量高的数据集。
特征获取(Feature):获取特征知识的典型方法主要为将输入输出序列输出到教师 LLMs 中,然后抽取其内部表示。该方式主要适用于开源的 LLMs,常用于模型压缩。
反馈(Feedback):反馈知识通常为教师模型对学生的输出提供反馈,如提供偏好、评估或纠正信息来指导学生生成更好输出。
自生成知识(Self-Knowledge):知识也可以从学生自身中获取,称之为自生成知识。在这种情况下,同一个模型既充当教师又充当学生,通过蒸馏技术以及改进自己先前生成的输出来迭代地改进自己。该方式非常适用于开源 LLMs。
总结:目前,扩展方法仍然被广泛应用,数据合成方式因为能够生成大量高质量的数据而逐渐成为主流。反馈方法能够提供有利于学生模型提升对齐能力的知识。特征获取和自生成知识的方式因为将开源大模型作为教师模型而变得流行起来。特征获取方式有助于压缩开源模型,而自生成知识的方式能够持续地提升大语言模型。重要的是,以上方法可以有效地组合,研究人员可以探索不同方式的组合来引导出更有效的知识。
蒸馏算法(Distilling Algorithms)
获取知识之后,就需要将知识蒸馏到学生模型中。蒸馏的算法有:有监督微调、散度及相似度、强化学习,以及排序优化。示例如下图所示:
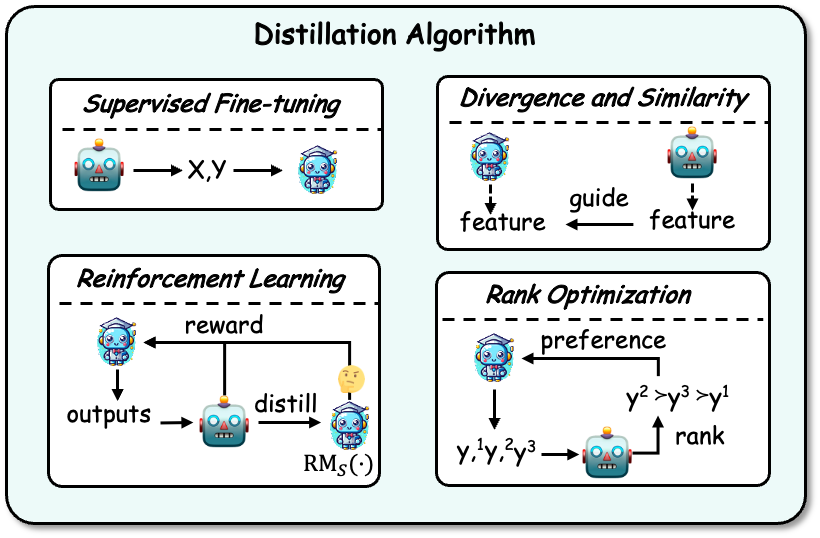
有监督微调:监督微调(SFT)通过最大化教师模型生成的序列的似然性来微调学生模型,让学生模型来模仿教师模型。这是目前 LLMs 知识蒸馏中最常用的一个技术。
散度及相似度(Divergence and Similarity):该算法将教师模型内部的参数知识作为学生模型训练的监督信号,适用于开源教师模型。基于散度与相似度的方法分别对齐概率分布以及隐藏状态。
强化学习(Reinforcement Learning):该算法适用于利用教师的反馈知识来训练学生模型,即 RLAIF 技术。主要有两个方面:(1)使用教师生成的反馈数据训练一个学生奖励模型,(2)通过训练好的奖励模型,以最大化预期奖励来优化学生模型。教师也可以直接作为奖励模型。
排序优化(Rank Optimization):排序优化也可以将偏好知识注入到学生模型中,其优点在于稳定且计算效率高,一些经典算法如 DPO,RRHF 等。
技能蒸馏
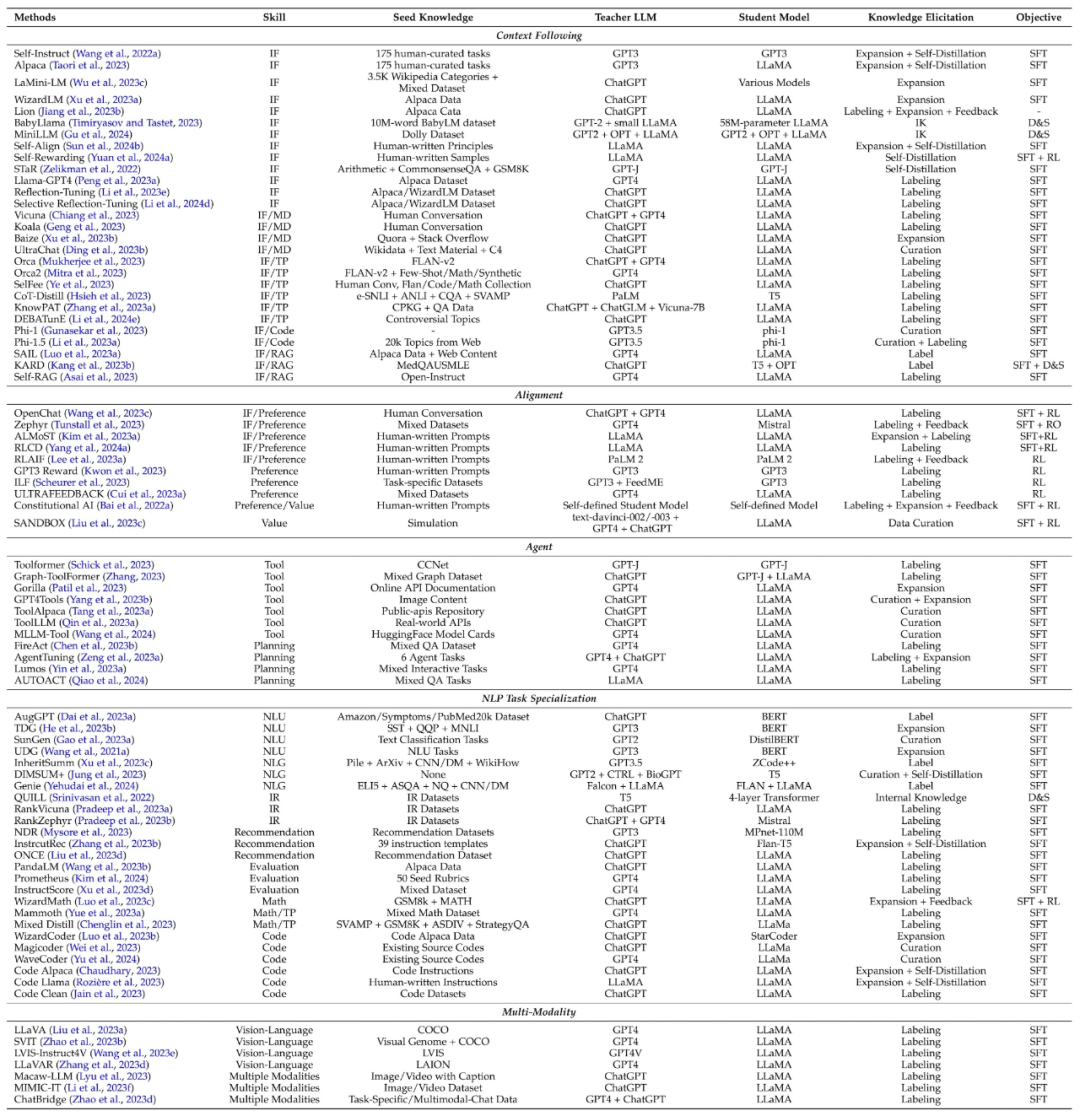
众所周知,大语言模型具有许多出色的能力。通过知识蒸馏技术,提供指令来控制教师生成包含对应技能的知识并训练学生模型,从而使其获取这些能力。这些能力主要包括遵循语境(如指令)、对齐、智能体、自然语言处理(NLP)任务和多模态等能力。
下表总结了技能蒸馏的经典的工作,同时总结了各个工作涉及到的技能、种子知识、教师模型、学生模型、知识获取方式、蒸馏算法。
垂直领域蒸馏
除了在通用领域的大语言模型,现在有很多工作训练垂直领域的大语言模型,这有助于研究界以及工业界对大语言模型的应用与部署。而大语言模型(如 GPT-4)在垂直领域上虽然具备的领域知识是有限的,但是仍能够提供一些领域知识、能力或者增强已有的领域数据集。这里涉及到的领域主要有(1)法律,(2)医疗健康,(3)金融,(4)科学,以及一些其他领域。该部分的分类学以及相关工作如下图所示:

未来方向
该综述探讨了目前大语言模型知识蒸馏的问题以及潜在的未来研究方向,主要包括:
数据选择:如何自动选择数据以实现更好的蒸馏效果?
多教师蒸馏:探究将不同教师模型的知识蒸馏到一个学生模型中。
教师模型中更丰富的知识:可以探索教师模型中更丰富的知识,包括反馈和特征知识,以及探索多种知识获取方法的组合。
克服蒸馏过程中的灾难性遗忘:在知识蒸馏或迁移过程中有效地保留原始模型的能力仍然是一个具有挑战性的问题。
可信知识蒸馏:目前 KD 主要集中在蒸馏各种技能,对于大模型可信度方面的关注相对较少。
弱到强的蒸馏(Weak-to-Strong Distillation)。OpenAI 提出了 “弱到强泛化” 概念,这需要探索创新的技术策略,使较弱的模型能够有效地引导较强的模型的学习过程。
自我对齐(自蒸馏)。可以设计指令使得学生模型通过生成反馈、批评和解释等内容使其自主地改进、对齐其生成内容。
结论
该综述对如何利用大语言模型的知识来提升学生模型,如开源大语言模型,进行了全面且系统地总结,同时包括了近期较流行的自蒸馏的技术。该综述将知识蒸馏分为了两个步骤:知识获取以及蒸馏算法,同时总结了技能蒸馏以及垂直领域蒸馏。最后,该综述探讨了蒸馏大语言模型的未来方向,希望推动大语言模型知识蒸馏的边界,得到更易获取、高效、有效、可信的大语言模型。
以上是总结374篇相关工作,陶大程团队联合港大、UMD发布LLM知识蒸馏最新综述的详细内容。更多信息请关注PHP中文网其他相关文章!





















