

大型模型仅能记忆和理解有限的上下文,这已成为它们在实际应用中的一大制约。例如,对话型人工智能系统常常无法持久记忆前一天的对话内容,这导致利用大型模型构建的智能体表现出前后不一致的行为和记忆。
为了让大型模型能够更好地处理更长的上下文,研究人员提出了一种名为InfLLM的新方法。这一方法由清华大学、麻省理工学院和人民大学的研究人员联合提出,它能够使大型语言模型(LLM)无需额外的训练就能够处理超长文本。InfLLM利用了少量的计算资源和显存开销,从而实现了对超长文本的高效处理。

论文地址:https://arxiv.org/abs/2402.04617
代码仓库:https://github.com/thunlp/InfLLM
实验结果表明,InfLLM能够有效地扩展Mistral、LLaMA的上下文处理窗口,并在1024K上下文的海底捞针任务中实现100%召回。
大规模预训练语言模型(LLMs)近几年在众多任务上取得了突破性的进展,成为众多应用的基础模型。
这些实际应用也对LLMs处理长序列的能力提出了更高的挑战。例如,LLM驱动的智能体需要持续处理从外部环境接收的信息,这要求它具备更强的记忆能力。同时,对话式人工智能需要更好地记住与用户的对话内容,以便生成更个性化的回答。
然而,目前的大型模型通常只在包含数千个Token的序列上进行预训练,这导致将它们应用于超长文本时面临两大挑战:
1. 分布外长度:直接将LLMs应用到更长长度的文本中,往往需要LLMs处理超过训练范围的位置编码,从而造成Out-of-Distribution问题,无法泛化;
2. 注意力干扰:过长的上下文将使模型注意力被过度分散到无关的信息中,从而无法有效建模上下文中远距离语义依赖。
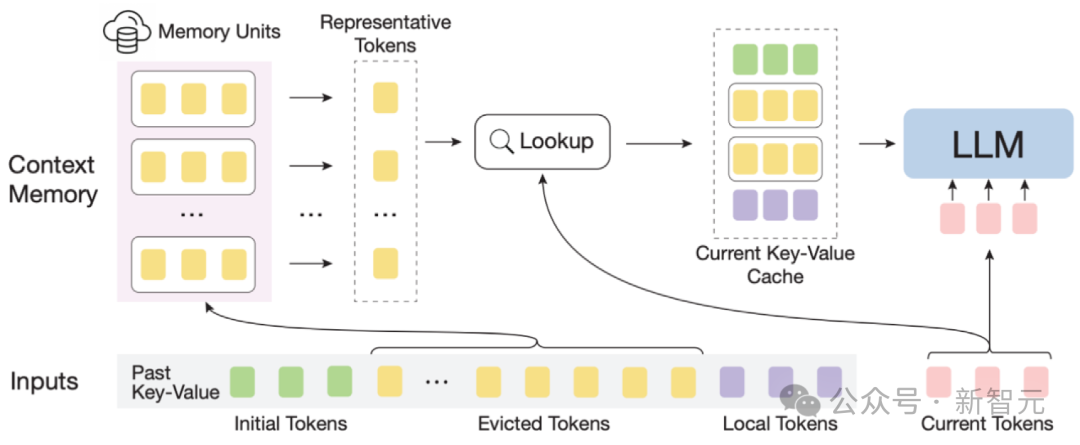
InfLLM示意图
为了高效地实现大模型的长度泛化能力,作者提出了一种无需训练的记忆增强方法,InfLLM,用于流式地处理超长序列。
InfLLM旨在激发LLMs的内在能力,以有限的计算成本捕获超长上下文中的长距离语义依赖关系,从而实现高效的长文本理解。
整体框架:考虑到长文本注意力的稀疏性,处理每个Token通常只需要其上下文的一小部分。
作者构建了一个外部记忆模块,用于存储超长上下文信息;采用滑动窗口机制,每个计算步骤,只有与当前Token距离相近的Tokens(Local Tokens)和外部记忆模块中的少量相关信息参与到注意力层的计算中,而忽略其他不相关的噪声。
因此,LLMs可以使用有限的窗口大小来理解整个长序列,并避免引入噪声。
然而,超长序列中的海量上下文对于记忆模块中有效的相关信息定位和记忆查找效率带来了重大挑战。
为了应对这些挑战,上下文记忆模块中每个记忆单元由一个语义块构成,一个语义块由连续的若干Token构成。
具体而言, (1)为了有效定位相关记忆单元,每个语义块的连贯语义比碎片化的Token更能有效满足相关信息查询的需求。
此外,作者从每个语义块中选择语义上最重要的Token,即接收到注意力分数最高的Token,作为语义块的表示,这种方法有助于避免在相关性计算中不重要Token的干扰。
(2)为了高效的内存查找,语义块级别的记忆单元避免了逐Token,逐注意力的相关性计算,降低了计算复杂性。
此外,语义块级别的记忆单元确保了连续的内存访问,并减少了内存加载成本。
得益于此,作者设计了一种针对上下文记忆模块的高效卸载机制(Offloading)。
考虑到大多数记忆单元的使用频率不高,InfLLM将所有记忆单元卸载到CPU内存上,并动态保留频繁使用的记忆单元放在GPU显存中,从而显着减少了显存使用量。
可以将InfLLM总结为:
1. 在滑动窗口的基础上,加入远距离的上下文记忆模块。
2. 将历史上下文切分成语义块,构成上下文记忆模块中的记忆单元。每个记忆单元通过其在之前注意力计算中的注意力分数确定代表性Token,作为记忆单元的表示。从而避免上下文中的噪音干扰,并降低记忆查询复杂度
作者在Mistral-7b-Inst-v0.2(32K) 和Vicuna-7b-v1.5(4K)模型上应用InfLLM,分别使用4K和2K的局部窗口大小。
与原始模型、位置编码内插、Infinite-LM以及StreamingLLM进行比较,在长文本数据 Infinite-Bench 和 Longbench 上取得了显着的效果提升。
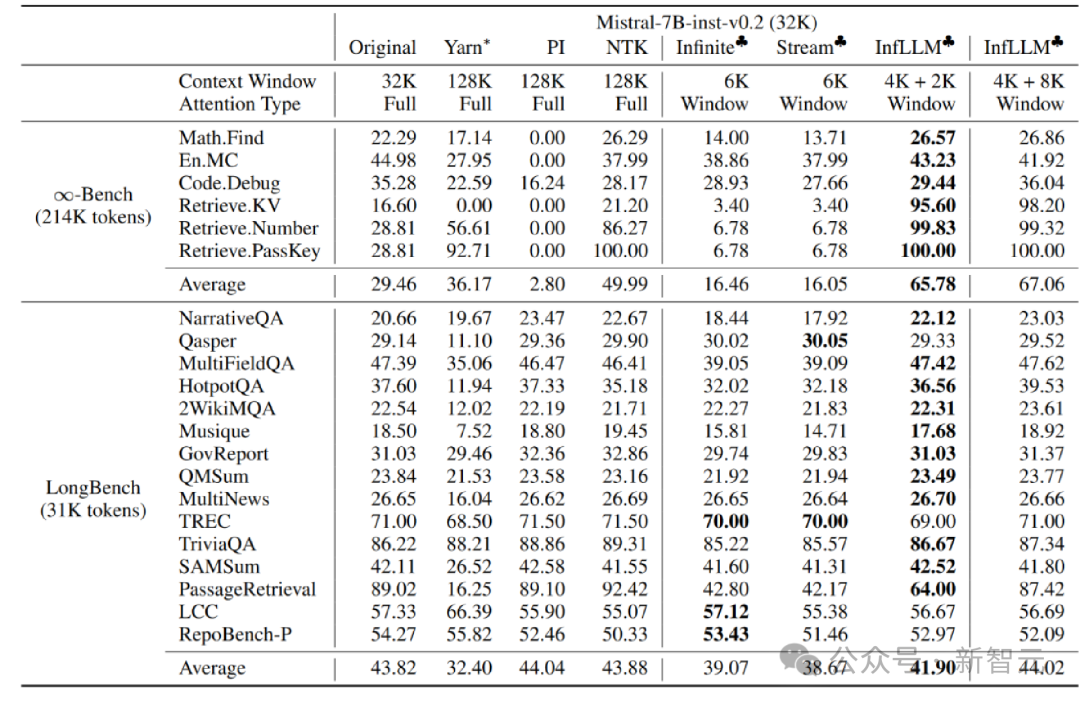
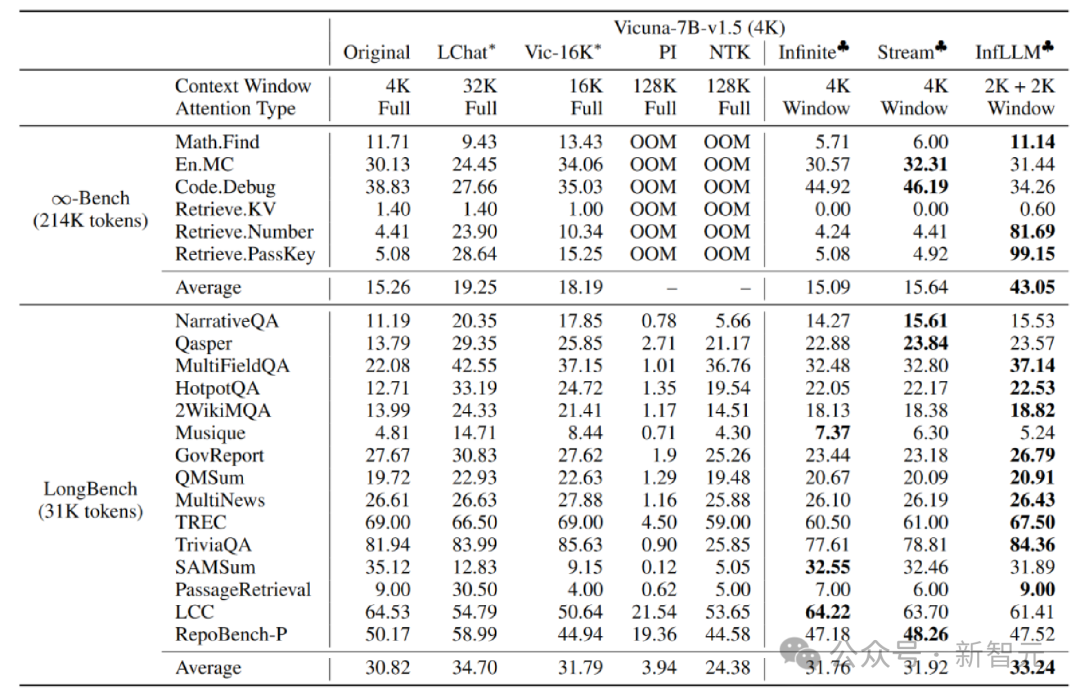
超长文本实验
此外,作者继续探索了InfLLM 在更长文本上的泛化能力,在1024K 长度的「海底捞针」任务中仍能保持100% 的召回率。
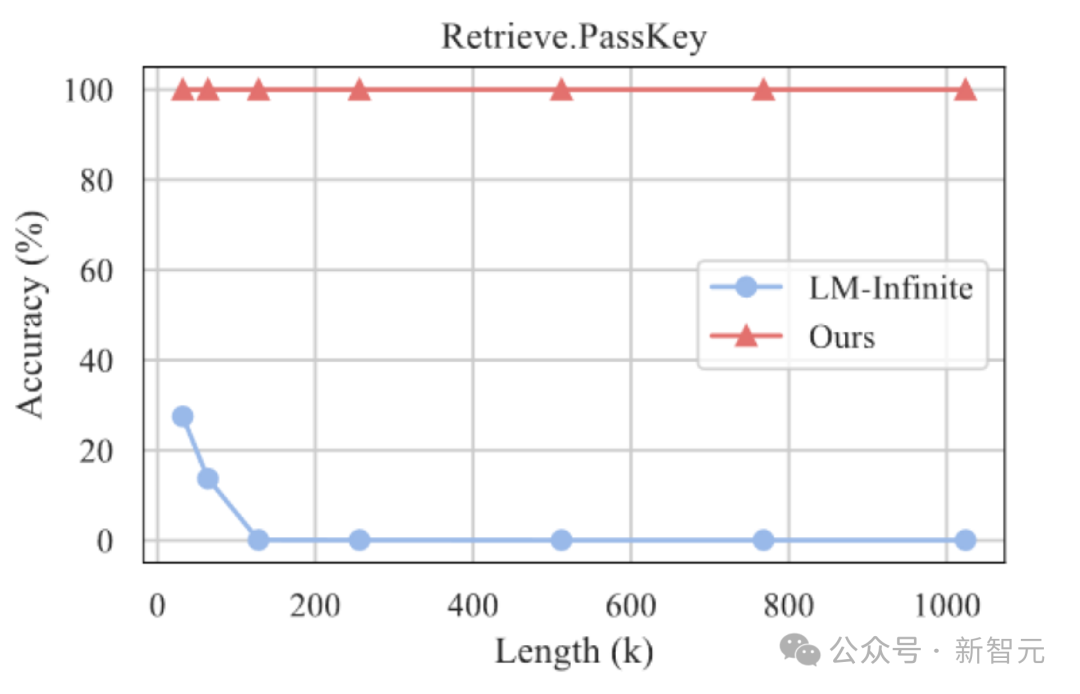
海底捞针实验结果
在本文中,团队提出了InfLLM,无需训练即可实现LLM 的超长文本处理拓展,并可以捕捉到长距离的语义信息。
InfLLM 在滑动窗口的基础上,增加了包含长距离上下文信息的记忆模块,并使用缓存和offload 机制实现了少量计算和显存消耗的流式长文本推理。
以上是清华NLP组发布InfLLM:无需额外训练,「1024K超长上下文」100%召回!的详细内容。更多信息请关注PHP中文网其他相关文章!





















