

遮挡是计算机视觉很基础但依旧未解决的问题之一,因为遮挡意味着视觉信息的缺失,而机器视觉系统却依靠着视觉信息进行感知和理解,并且在现实世界中,物体之间的相互遮挡无处不在。牛津大学 VGG 实验室 Andrew Zisserman 团队最新工作系统性解决了任意物体的遮挡补全问题,并且为这一问题提出了一个新的更加精确的评估数据集。该工作受到了 MPI 大佬 Michael Black、CVPR 官方账号、南加州大学计算机系官方账号等在 X 平台的点赞。以下为论文「Amodal Ground Truth and Completion in the Wild」的主要内容。

非模态分割(Amodal Segmentation)旨在补全物体被遮挡的部分,即给出物体可见部分和不可见部分的形状掩码。这个任务可以使得诸多下游任务受益:物体识别、目标检测、实例分割、图像编辑、三维重建、视频物体分割、物体间支撑关系推理、机器人的操纵和导航,因为在这些任务中知道被遮挡物体完整的形状会有所帮助。

然而,如何去评估一个模型在真实世界做非模态分割的性能却是一个难题:虽然很多图片中都有大量的被遮挡物体,可是如何得到这些物体完整形状的参考标准 或是非模态掩码呢?前人的工作有通过人手动标注非模态掩码的,可是这样标注的参考标准难以避免引入人类误差;也有工作通过制造合成数据集,比如在一个完整的物体上贴直接另一个物体,来得到被遮挡物体的完整形状,但这样得到的图片都不是真实图片场景。因此,这个工作提出了通过 3D 模型投影的方法,构造了一个大规模的涵盖多物体种类并且提供非模态掩码的真实图片数据集(MP3D-Amodal)来精确评估非模态分割的性能。各不同数据集的对比如下图:
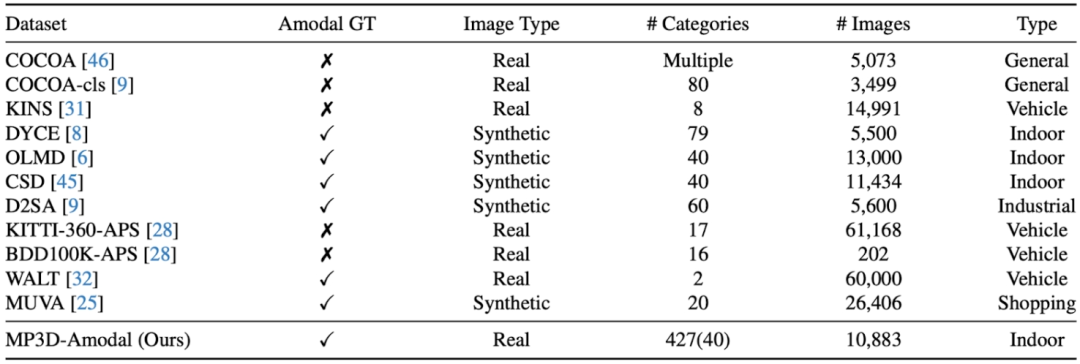
具体而言,以 MatterPort3D 数据集为例,对于任意的有真实照片并且有场景三维结构的数据集,我们可以将场景中所有物体的三维形状同时投影到相机上以得到每个物体的模态掩码(可见形状,因为物体相互之间有遮挡),然后将场景中每个物体的三维形状分别投影到相机以得到这个物体的非模态掩码,即完整的形状。通过对比模态掩码和非模态掩码,即可以挑选出被遮挡的物体。

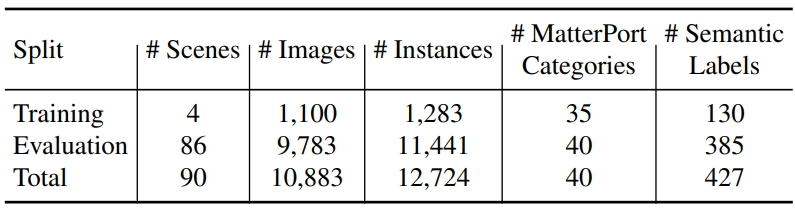
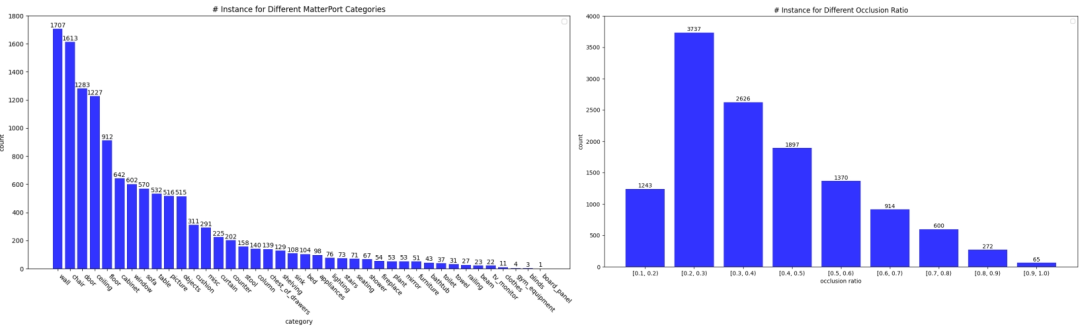
数据集的统计数据如下:
数据集的样例如下:

此外,为解决任意物体的完整形状重建任务,作者提取出 Stable Diffusion 模型的特征中关于物体完整形状的先验知识,来对任意被遮挡物体做非模态分割,具体的架构如下(SDAmodal):
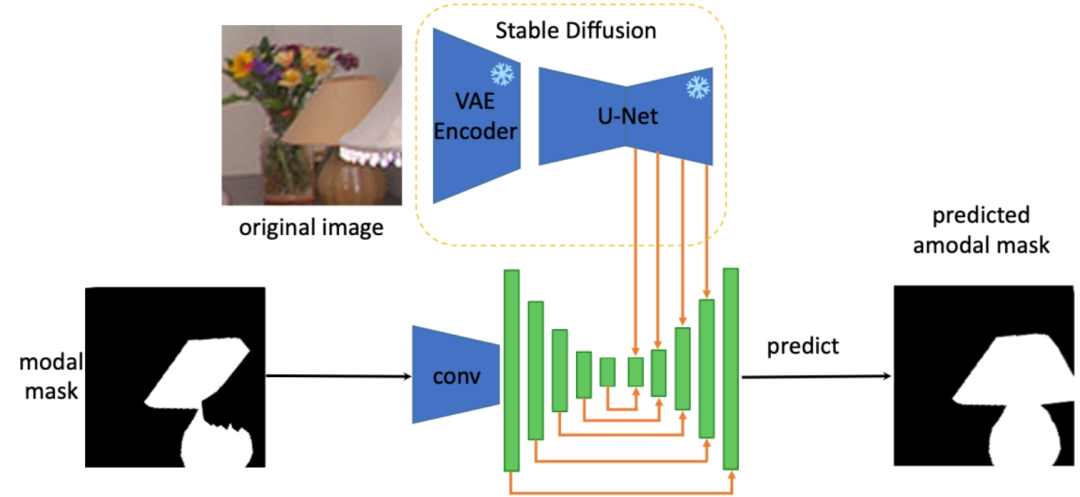
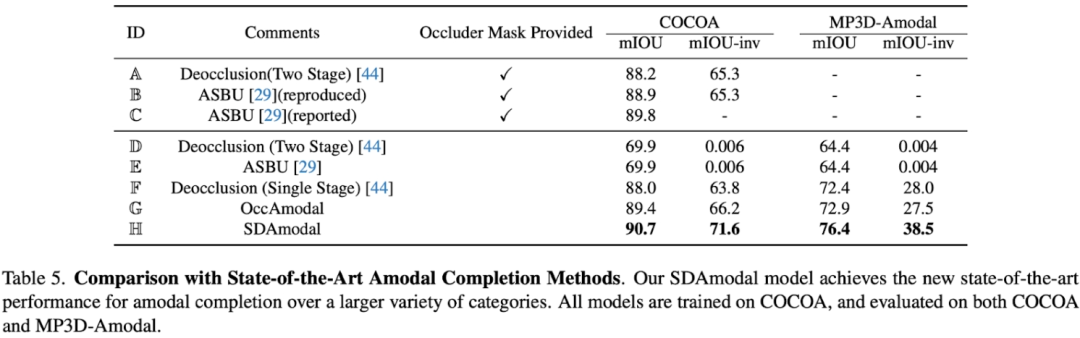
提出使用 Stable Diffusion Feature 的动机在于,Stable Diffusion 具有图片补全的能力,所以可能一定程度上包含了有关物体的全部信息;而且由于 Stable Diffusion 经过大量图片的训练,所以可以期待其特征在任意环境下有对任意物体的处理能力。和前人 two-stage 的框架不同,SDAmodal 不需要已经标注好的遮挡物掩码作为输入;SDAmodal 架构简单,却体现出很强的零样本泛化能力(比较下表 Setting F 和 H,仅在 COCOA 上训练,却能在另一个不同域、不同类别的数据集上有所提升);即使没有关于遮挡物的标注,SDAmodal 在目前已有的涵盖多种类被遮挡物体的数据集 COCOA 以及新提出的 MP3D-Amodal 数据集上,都取得了SOTA表现(Setting H)。
除了定量实验,定性的比较也体现出了 SDAmodal 模型的优势:从下图可以观察到(所有模型都只在 COCOA 上训练),对于不同种类的被遮挡物体,无论是来自于 COCOA,还是来自于另一个MP3D-Amodal,SDAmodal 都能大大提升非模态分割的效果,所预测的非模态掩码更加接近真实的。

更多细节,请阅读论文原文。
以上是「AI透视眼」,三次马尔奖获得者Andrew带队解决任意物体遮挡补全难题的详细内容。更多信息请关注PHP中文网其他相关文章!





















