

视听语音分离(AVSS)技术的主要目的是在混合信号中识别并分离出目标说话者的声音,利用面部信息来实现这一目标。这项技术在多个领域都有广泛的应用,包括智能助手、远程会议和增强现实等。通过AVSS技术,可以显着改善在嘈杂环境下的语音信号质量,从而提高语音识别和交流的效果。这种技术的发展为人们的日常生活和工作带来了便利,使得人们能够更加轻松
传统的视听语音分离方法通常需要复杂的模型和大量的计算资源,特别是在有嘈杂背景或多说话者的情况下,其性能容易受到限制。为了克服这些问题,研究人员开始探索基于深度学习的方法。然而,现有的深度学习技术存在计算复杂度高和难以适应未知环境的挑战。
具体来说,当前视听语音分离方法存在如下问题:
时域方法:可提供高质量的音频分离效果,但由于参数较多,计算复杂度较高,处理速度较慢。
时频域方法:计算效率更高,但与时域方法相比,历来表现不佳。它们面临三个主要挑战:
1. 缺乏时间和频率维度的独立建模。
2. 没有充分利用来自多个感受野的视觉线索来提高模型性能。
3. 对复数特征处理不当,导致丢失关键的振幅和相位信息。
为了应对这些挑战,清华大学胡晓林副教授团队的研究人员提出了一种全新的视听语音分离模型,名为RTFS-Net。该模型采用了压缩 - 重建的方法,在提高分离性能的同时,显着减少了模型的计算复杂度和参数数量。 RTFS-Net 是首个使用少于100万个参数的视听语音分离方法,同时也是首个在时频域多模态分离方面优于所有时域模型的方法。

论文地址:https://arxiv.org/abs/2309.17189
论文主页:https://cslikai.cn/RTFS-Net/AV-Model-Demo.html
代码地址:https://github.com/spkgyk/RTFS-Net(即将发布)
方法简介
RTFS-Net的整体网络架构如下图1所示:
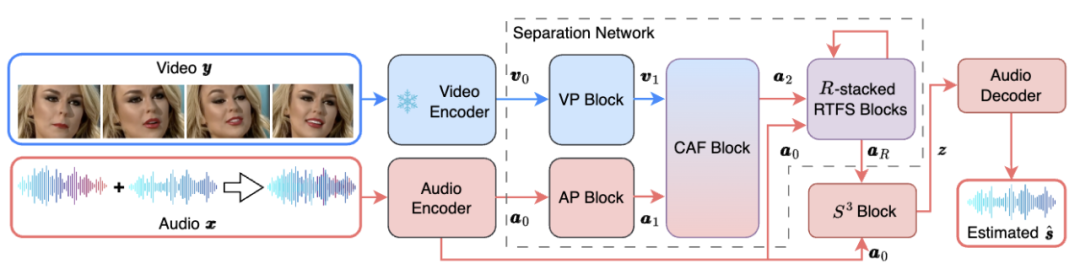
图1. RTFS-Net 的网络框架
其中,RTFS 块(如图2 所示)对声学维度(时间和频率)进行压缩和独立建模,在创建低复杂度子空间的同时尽量减少信息丢失。具体来说,RTFS 块采用了一种双路径架构,用于在时间和频率两个维度上对音频信号进行有效处理。通过这种方法,RTFS 块能够在减少计算复杂度的同时,保持对音频信号的高度敏感性和准确性。下面是 RTFS 块的具体工作流程:
1. 时间 - 频率压缩:RTFS 块首先对输入的音频特征进行时间和频率维度的压缩。
2. 独立维度建模:在完成压缩后,RTFS 块对时间和频率维度进行独立建模。
3. 维度融合:独立处理时间和频率维度之后,RTFS 块通过一个融合模块将两个维度的信息合并起来。
4. 重构和输出:最后,融合后的特征通过一系列逆卷积层被重构回原始的时间 - 频率空间。
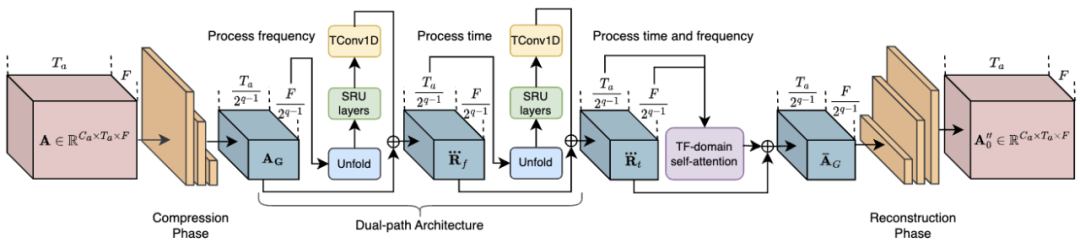
图2. RTFS 块的网络结构
跨维注意力融合(CAF)模块(如图3 所示)有效融合音频和视觉信息,增强语音分离效果,计算复杂度仅为之前SOTA 方法的1.3%。具体来说,CAF 模块首先使用深度和分组卷积操作生成注意力权重。这些权重根据输入特征的重要性动态调整,使模型能够聚焦于最相关的信息。然后,通过对视觉和听觉特征应用生成的注意力权重,CAF 模块能够在多个维度上聚焦于关键信息。这一步骤涉及到对不同维度的特征进行加权和融合,以产生一个综合的特征表示。除了注意力机制外,CAF 模块还可以采用门控机制来进一步控制不同源特征的融合程度。这种方式可以增强模型的灵活性,允许更精细的信息流控制。
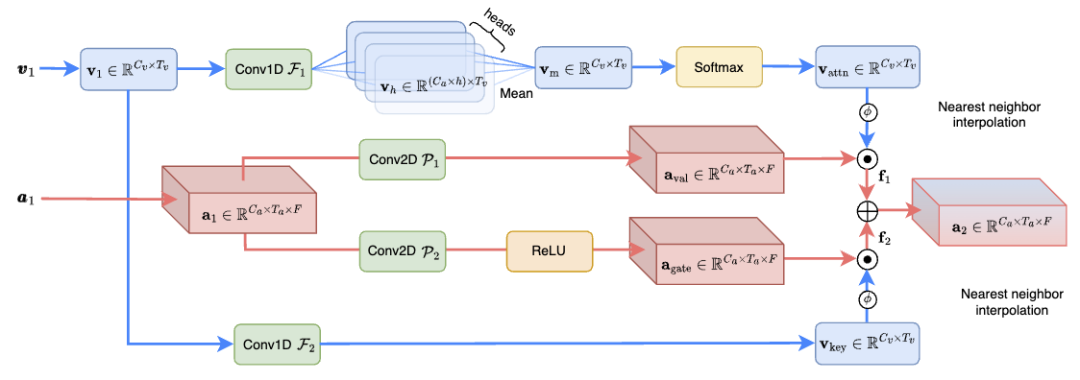
图 3. CAF 融合模块的结构示意图
频谱源分离 ( S^3 ) 块的设计理念在于利用复数表示的频谱信息,从混合音频中有效提取目标说话者的语音特征。这种方法充分利用了音频信号的相位和幅度信息,提高了源分离的准确性和效率。并使用复数网络使得 S^3 块在分离目标说话者的语音时能够更准确地处理信号,尤其是在保留细节和减少伪影方面表现出色,如下所示。同样地,S^3 块的设计允许容易地集成到不同的音频处理框架中,适用于多种源分离任务,并具有良好的泛化能力。
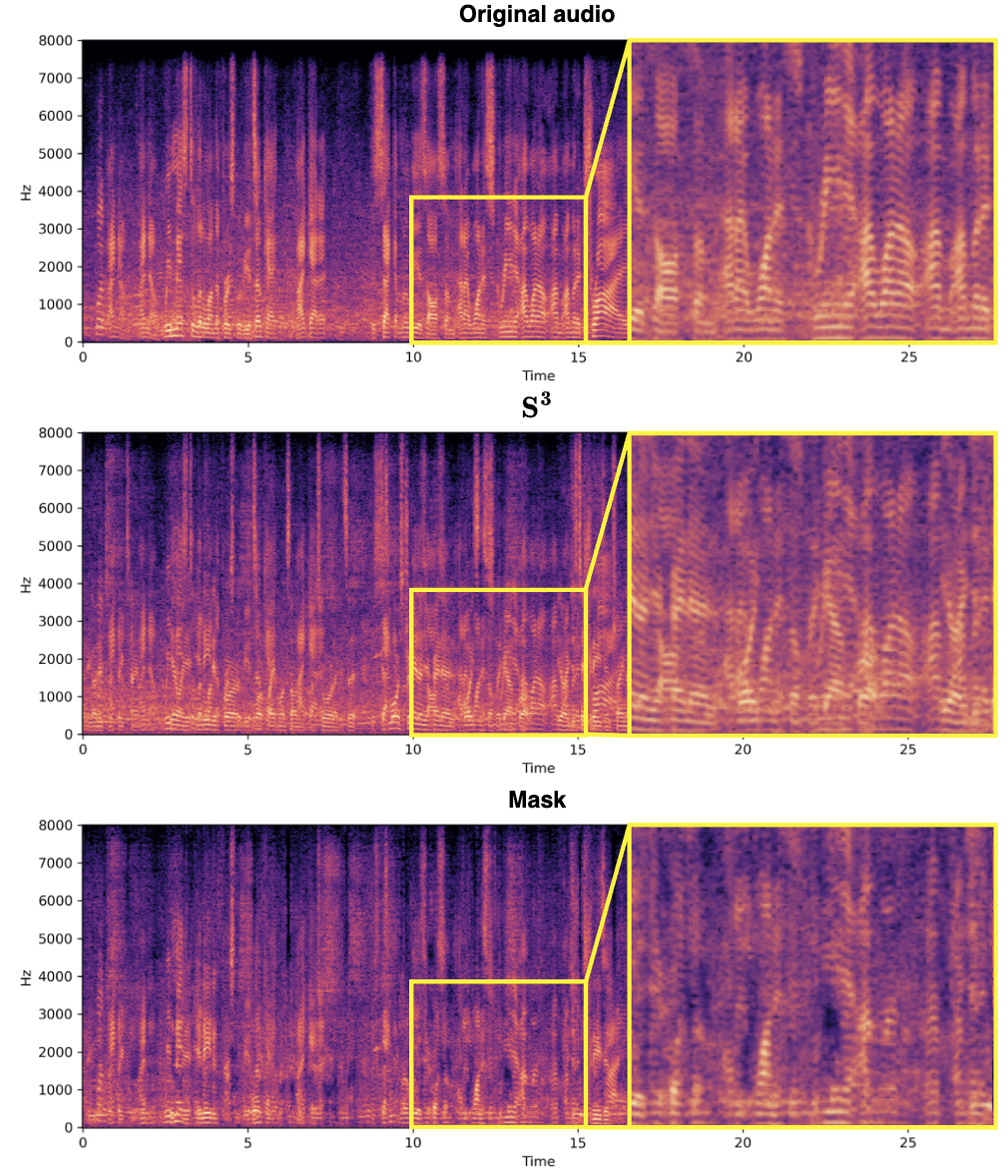
实验结果
分离效果
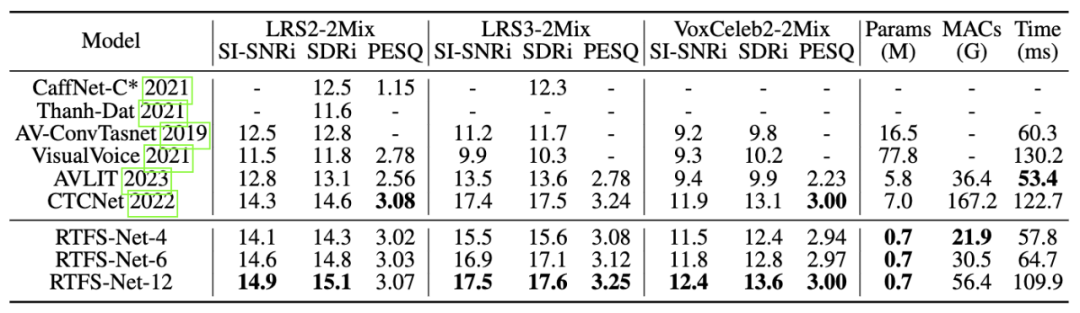
在三个基准多模态语音分离数据集(LRS2,LRS3 和 VoxCeleb2)上,如下所示,RTFS-Net 在大幅降低模型参数和计算复杂度的同时,接近或超越了当前最先进的性能。通过不同数量的 RTFS 块(4, 6, 12 块)的变体展示了在效率和性能之间的权衡,其中 RTFS-Net-6 提供了性能与效率的良好平衡。RTFS-Net-12 在所有测试的数据集上均表现最佳,证明了时频域方法在处理复杂音视频同步分离任务中的优势。
实际效果
混合视频: 女性说话人音频:
女性说话人音频:  男性说话人音频:
男性说话人音频: 
总结
随着大模型技术的不断发展,视听语音分离领域也在追求大模型来提升分离质量。然而,这对于端上设备并不是可行的。RTFS-Net 在保持显著降低的计算复杂度和参数数量的同时,还实现了显著的性能提升。这表明,提高 AVSS 性能并不一定需要更大的模型,而是需要创新、高效的架构,以更好地捕捉音频和视觉模式之间错综复杂的相互作用。
以上是ICLR 2024 | 为音视频分离提供新视角,清华大学胡晓林团队推出RTFS-Net的详细内容。更多信息请关注PHP中文网其他相关文章!





















