在当前智能对话模型的发展中,强大的底层模型起着至关重要的作用。这些先进模型的预训练往往依赖于高质量且多样化的语料库,而如何构建这样的语料库,已成为行业中的一大挑战。在备受瞩目的 AI for Math 领域,由于高质量的数学语料相对稀缺,这限制了生成式人工智能在数学应用方面的潜力。为了应对这一挑战,上海交通大学生成式人工智能实验室推出了「MathPile」。这是一套专门针对数学领域的高质量、多样化预训练语料库,其中包含约 95 亿 tokens,旨在提升大型模型在数学推理方面的能力。此外,实验室还推出了 MathPile 的商业版 ——「MathPile_Commercial」,进一步拓宽其应用范围和商业潜力。
- 研究使用:https://huggingface.co/datasets/GAIR/MathPile
- 商用版本:https://huggingface.co/datasets/GAIR/MathPile_Commercial
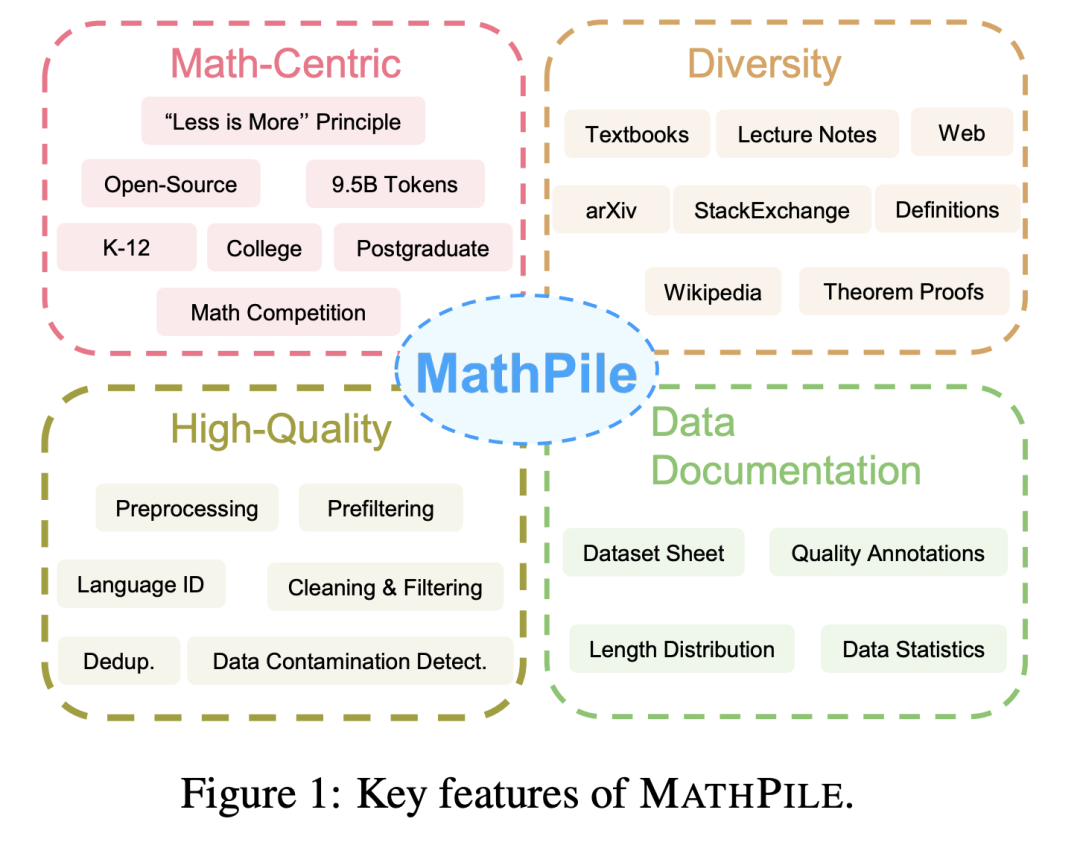
1. 以数学为中心:不同于过去专注于通用领域的语料,如 Pile, RedPajama, 或者多语言语料 ROOTS 等等,MathPile 专注于数学领域。尽管目前已经有一些专门的数学语料,但要么没有开源(比如 Google 用来训练 Minerva 的语料,OpenAI 的 MathMix),要么不够丰富多样(比如 ProofPile 和最近的 OpenWebMath)。2. 多样性:MathPile 的数据来源广泛,比如公开开源的数学教科书,课堂笔记,合成的教科书,arXiv 上的数学相关的论文,Wikipedia 上关于数学相关的条目,ProofWiki 上的引理证明和定义,StackExchange(社区问答网站)上的高质量数学问题和答案,以及来自 Common Crawl 上的数学网页。以上内容涵盖了适合中小学,大学,研究生以及数学竞赛等内容。MathPile 首次涵盖了 0.19B tokens 的高质量数学教科书。3. 高质量:研究团队在收集过程中遵循 「less is more」(少即是多) 的理念,坚信数据质量优于数量,即使在预训练阶段也是如此。他们从~520B tokens(大约 2.2TB)的数据源中,经过一套严谨复杂的预处理,预过滤,语言识别,清洁,过滤和去重等步骤,来确保语料库的高质量。值得一提的是,OpenAI 所用的 MathMix 也只有 1.5B tokens。4. 数据文档化:为了增加透明度,研究团队对 MathPile 进行了文档记录,提供了 dataset sheet。在数据处理过程中,研究团队还对来自 Web 的文档进行了「质量标注」。例如,语言识别的分数,文档中符号与单词的比例,方便研究者根据自身需要进一步过滤文档。他们还对语料进行了下游测试集的污染检测,来消除像来自 MATH,MMLU-STEM 这样的基准测试集中的样本。同时,研究团队还发现了 OpenWebMath 中也存在大量的下游测试样本,这说明在制作预训练语料时应该格外小心,避免下游的评测失效。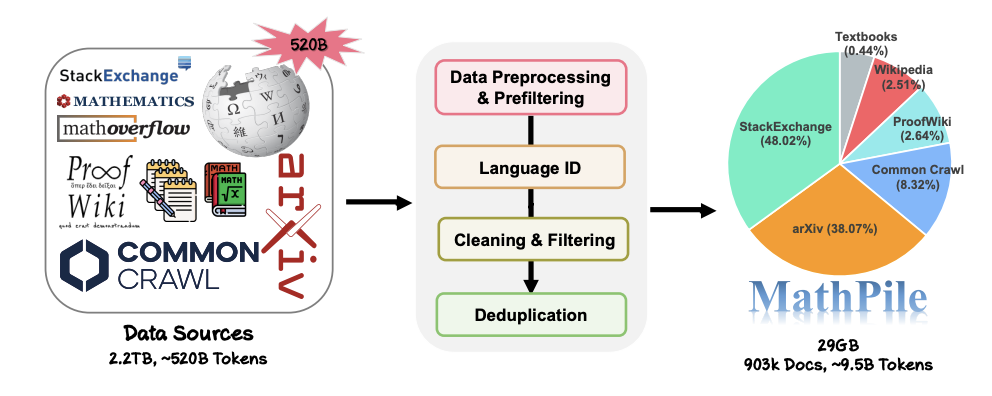
MathPile 的数据收集和处理过程。
在大模型领域竞争愈演愈烈的今天,很多科技公司都不再公开他们的数据,还有他们的数据来源,配比,更不用说详细的预处理细节。相反,MathPile 在前人探索的基础上总结了一套适用 Math 领域的数据处理方法。在数据的清洗和过滤部分,研究团队采用的具体步骤是:
- 检测包含 「lorem ipsum」的行,如果将行中「lorem ipsum」替换掉少于 5 个字符,便移除掉该行;
- 检测包含「javescript」并且同时包含「enable」,「disable」或者「browser」 的行,并且该行的字符数量小于 200 字符,便过滤掉该行;
- 过滤掉少于 10 个单词并且包含「Login」, 「sign-in」, 「read more...」, 或者 「items in cart」 的行;
- 过滤掉以省略号结尾的行占比整个文档超过 30% 的文档;
- 过滤掉文档平均英文单词字符长度介于(3,10)区间以外的文档;
- 过滤掉不包含至少两个停用词(比如 the, be, to, of, and, that, have 等)的文档;
- 过滤掉移除掉空格和标点符号后少于 200 个字符的文档;
此外,研究团队还提供了很多清洗过程中的数据样例。下图为通过 MinHash LSH 算法去重检测出来的 Common Crawl 中的近似重复的文档(如粉红色高亮处所示)。
如下图所示,研究团队在进行数据泄露检测过程中发现了来自 MATH 测试集的问题(如黄色高亮处所示)。
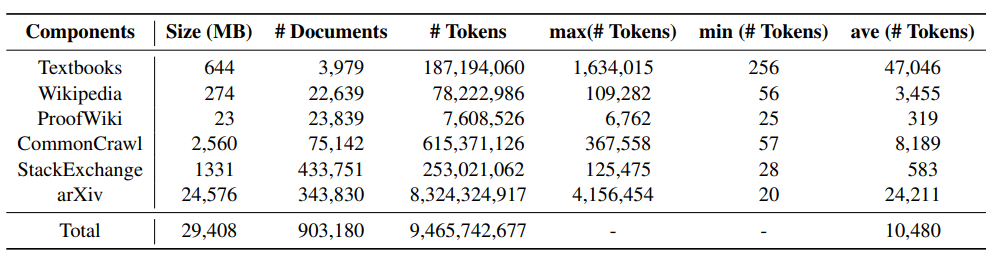
下表展示了 MathPile 各个组成部分的统计信息,可以发现 arXiv 论文,教科书通常文档长度较长,wiki 上的文档相对偏短。下图是 MathPile 语料中一个教科书的样例文档,可以看出其中的文档结构较为清晰,质量较高。
实验结果
研究团队还披露了一些初步的实验结果。他们在目前颇受欢迎的 Mistral-7B 模型的基础上进行了进一步的预训练。接着通过少量样本提示(few-shot prompting)方法,在一些常见的数学推理基准数据集上进行了评估。目前已获得的初步实验数据如下:
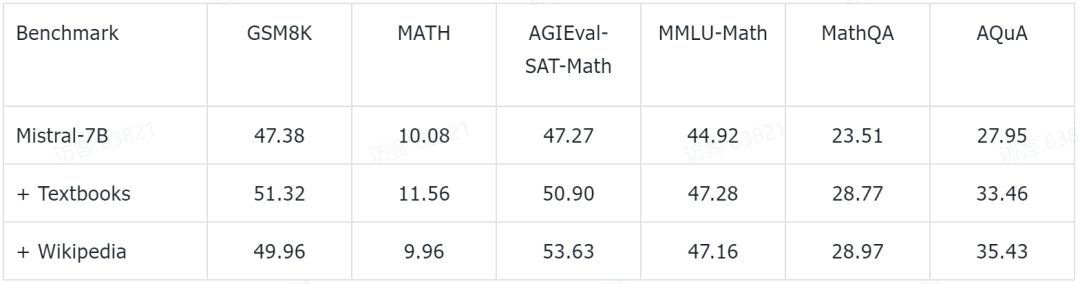
这些测试基准覆盖了各个层次的数学知识,包括小学数学(例如 GSM8K、TAL-SCQ5K-EN 和 MMLU-Math),高中数学(如 MATH、SAT-Math、MMLU-Math、AQuA 和 MathQA),以及大学数学(例如 MMLU-Math)。研究团队初步公布的实验结果显示,通过在 MathPile 中的教科书和维基百科子集上进行继续预训练,语言模型在不同难度级别的数学推理能力上均实现了比较可观的提升。
研究团队也强调,相关实验仍在继续进行中。
结语
MathPile 自发布之日起便受到了广泛关注,并被多方转载,目前更是荣登 Huggingface Datasets 趋势榜单。研究团队表示,他们将持续对数据集进行优化和升级,进一步提升数据质量。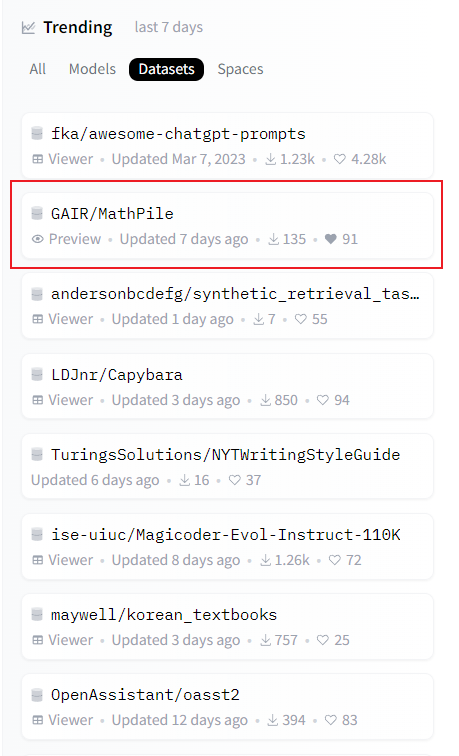
MathPile 登 Huggingface Datasets 趋势榜单。 MathPile 被知名 AI 博主 AK 转发,图源:https://twitter.com/_akhaliq/status/1740571256234057798。
MathPile 被知名 AI 博主 AK 转发,图源:https://twitter.com/_akhaliq/status/1740571256234057798。
目前,MathPile 已更新至第二版,旨在为开源社区的研究发展贡献力量。同时,其商业版数据集也已向公众开放。以上是为大模型恶补数学,上交开源MathPile语料库,95亿tokens,还可商用的详细内容。更多信息请关注PHP中文网其他相关文章!