

随着对Sora技术分析的展开,AI基础设施的重要性愈发凸显。
来自字节和北大的一篇新论文在此时吸引关注:
文章披露,字节搭建起的万卡集群,能在1.75天内完成GPT-3规模模型(175B)的训练。
具体来说,字节提出了一个名为MegaScale的生产系统,旨在解决在万卡集群上训练大模型时面临的效率和稳定性挑战。
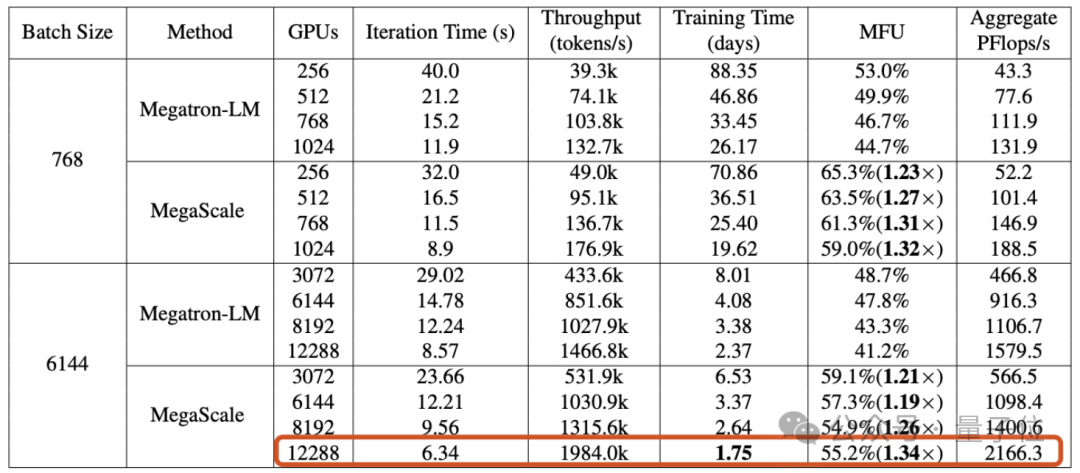
在12288块GPU上训练1750亿参数大语言模型时,MegaScale实现了55.2%的算力利用率(MFU),是英伟达Megatron-LM的1.34倍。
论文还透露,截止2023年9月,字节已建立起超过1万张卡的Ampere架构GPU(A100/A800)集群,目前正在建设大规模Hopper架构(H100/H800)集群。
大模型时代,GPU的重要性已无需赘述。
但大模型的训练,并不是把卡的数量拉满就能直接开干的——当GPU集群的规模来到“万”字级别,如何实现高效、稳定的训练,本身就是一个颇具挑战的工程问题。

第一重挑战:效率。
训练大语言模型并非简单的并行任务,需要在多个GPU之间分布模型,并且这些GPU需要频繁通信才能共同推进训练进程。通信之外,操作符优化、数据预处理和GPU内存消耗等因素,都对算力利用率(MFU)这个衡量训练效率的指标有影响。
MFU是实际吞吐量与理论最大吞吐量之比。
第二重挑战:稳定性。
我们知道,训练大语言模型往往需要花费非常长的时间,这也意味着,训练过程中失败和延迟的现象并不鲜见。
失败的成本是高昂的,因此如何缩短故障恢复时间变得尤为重要。
为了应对这些挑战,字节跳动的研究人员构建了MegaScale,并已将其部署到字节的数据中心中,用以支持各种大模型的训练。
MegaScale是在英伟达Megatron-LM的基础上改进的。
具体改进包括,算法和系统组件的共同设计、通信和计算重叠的优化、操作符优化、数据流水线优化以及网络性能调优等:
论文提到,MegaScale能够自动检测和修复超过90%的软硬件故障。
实验结果表明,MegaScale在12288个GPU上训练175B大语言模型时,实现了55.2%的MFU,是Megatrion-LM算力利用率的1.34倍。
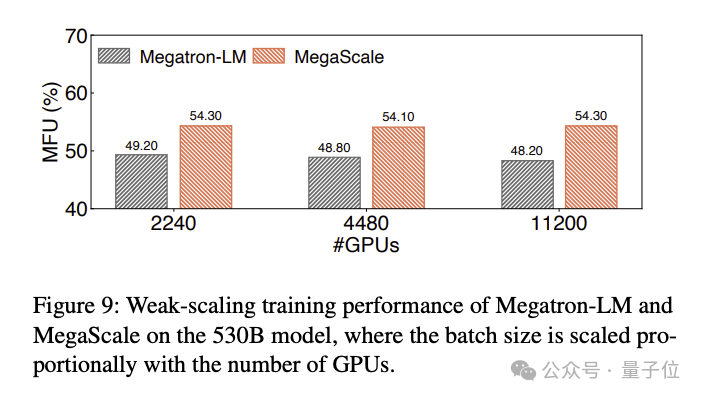
训练530B大语言模型的MFU对比结果如下:
就在这篇技术论文引发讨论之际,字节类Sora产品也传出了新消息:
剪映旗下类似Sora的AI视频工具已经启动邀请内测。

看样子地基已经打好,那么对于字节的大模型产品,你期待吗?
论文地址:https://arxiv.org/abs/2402.15627
以上是字节万卡集群技术细节公开:2天搞定GPT-3训练,算力利用率超英伟达Megatron-LM的详细内容。更多信息请关注PHP中文网其他相关文章!





















