


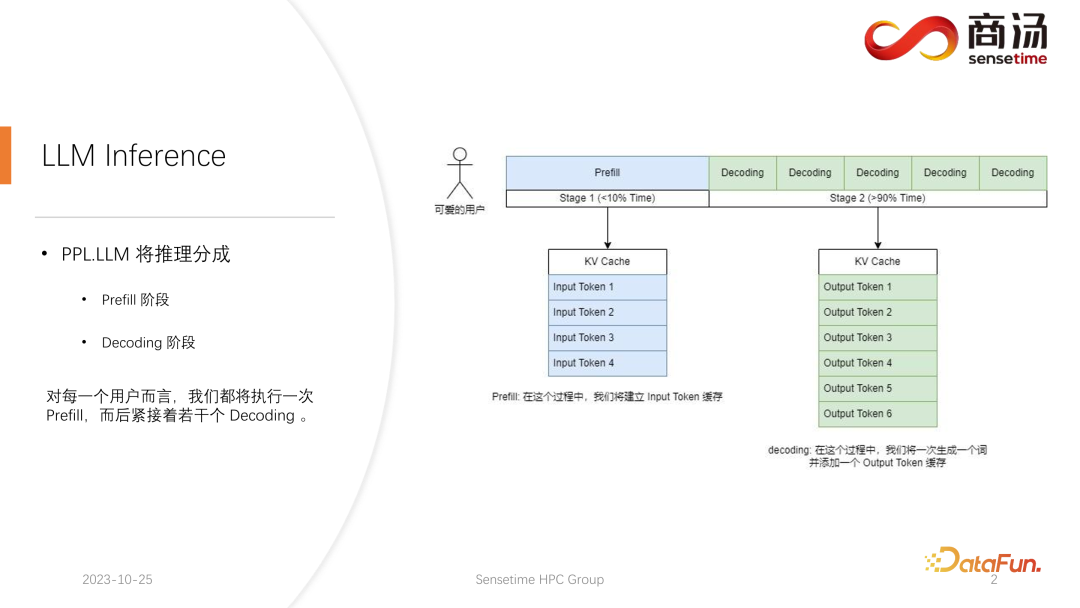
与传统的 CNN 模型推理不同,大语言模型的推理通常会分成 prefill 和 decoding 两个阶段。每一个请求发起后产生的推理过程都会先经历一个 Prefill 过程,prefill 过程会计算用户所有的输入,并生成对应的 KV 缓存,再经历若干个 decoding 过程,每一个 decoding 过程,服务器都会生成一个字符,并将其放入到 KV 缓存当中,之后依次迭代。
由于解码过程是逐字符生成的,每个答案片段的生成都需要大量时间,并且会生成大量字符。因此,解码阶段的数量非常庞大,占据了整个推理过程的绝大部分,超过了90%的比例。
在Prefill过程中,虽然需要处理大量的计算,因为要同时计算用户输入的所有词,但这只是一个一次性的过程。因此,在整个推理过程中,Prefill仅占不到 10% 的时间。
在大型语言模型推理中,通常会关注四个关键指标:吞吐量、首字延迟、总体延迟和每秒请求数(QPS)。这些性能指标从不同角度评估系统的服务能力。吞吐量衡量系统处理请求的速度和效率,而首字延迟则指系统生成第一个标记的时间。总体延迟是系统完成整个推理任务所需的时间。最后,QPS表示系统每秒处理的请求次数。这些指标在评估模型性能和系统优化方面起着关键作用,帮助确保系统能够高效地应对各种推理任务。
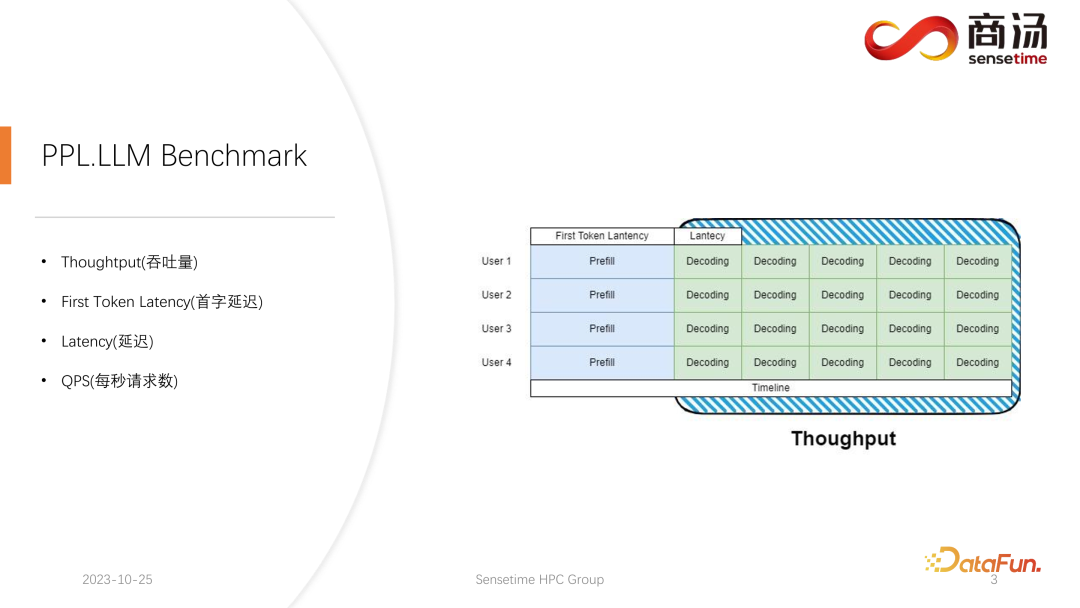
首先来介绍 Throughput(吞吐量)。从模型推理层面上看,最先关注的就是吞吐量。吞吐量是指当系统的负载达到最大的时候,在单位时间内,能够执行多少个 decoding,即生成多少个字符。测试吞吐量的方法是,假设所有用户都会在同一时刻到来,并且这些用户问的都是一样的问题,这些用户可以同时启动和结束,且他们生成的文本的长度和输入的文本长度都是一样的。通过使用完全相同的输入,组成一个完整的 batch。在这种情况下,系统的吞吐量会达到最高。但这种情况是不合实际的,所以这是一个理论的最大值。我们会测量在一秒钟之内,系统能够执行多少个独立的 decoding 阶段。
另一个关键指标是首字延迟(First Token Latency),即用户进入推理系统后完成Prefill阶段所需的时间。这指的是系统生成第一个字符的响应时间。很多用户期望在系统输入问题后,能在2-3秒内得到回答。
另一个重要的度量指标是延迟(Latency)。延迟表示每次解码操作所需的时间,它反映了大型语言模型系统在实时处理过程中生成每个字符所需的时间间隔,以及生成过程的流畅程度。通常,我们希望延迟保持在50毫秒以下,这意味着每秒可以生成20个字符。这样一来,大型语言模型的生成过程将更加流畅。
最后一个指标是 QPS(每秒请求数)。反映了在线上系统的服务当中,一秒钟能够处理多少个用户的请求。这一指标的测量方式比较复杂,后面会展开介绍。
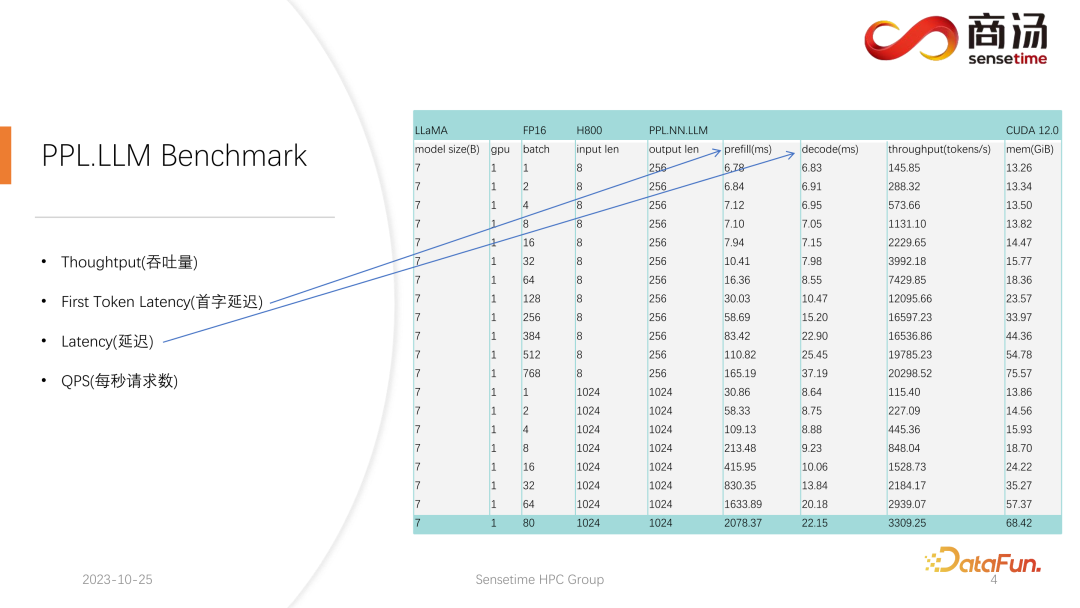
对于 First Token Latency 和 Latency 这两个指标,我们都进行了相对完善的测试。这两个指标会因为用户输入的长度不同、batch size 的不同而发生非常大的变化。
在上表中可以看到,对于同样的 7B 模型,如果用户的输入长度从 8 变成 2048,Prefill 的时间将从 6.78 毫秒,直到变成 2078 毫秒,即 2 秒的时间。如果有 80 个用户,每一个用户都输入 1,024 个词,那么 Prefill 在服务端就要跑 2 秒左右,这个时间已经超出了可以接受的范围。但如果用户输入长度都很短,比如每次访问只输入 8 个词,哪怕 768 个用户同时到来,首字延迟也只有 165 毫秒左右。
与首字延迟最相关的就是用户的输入长度,用户输入的长度越长,首字延迟也会越高。用户输入长度如果很短,那么首字延迟在整个大语言模型推理过程中都不会成为瓶颈。
而后面的 decoding 延迟,通常只要不是千亿级别的模型,decoding 的延迟都会控制在 50 毫秒以内。它主要受到 batch size 的影响,batch size 越大,推理延迟也会越大,但基本上增加的幅度不会很高。
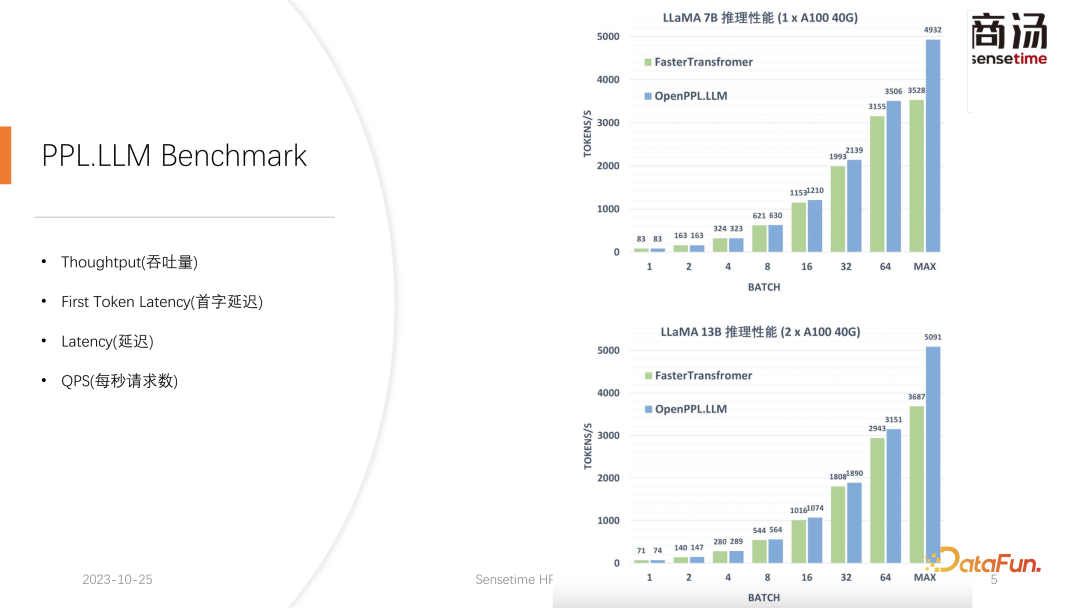
吞吐量其实也会受到这两个因素的影响。如果用户输入的长度和生成的长度很长,那么系统吞吐量也不会很高。如果用户输入长度和生成长度都不是很长,那么系统吞吐量可能会达到一个非常离谱的程度。
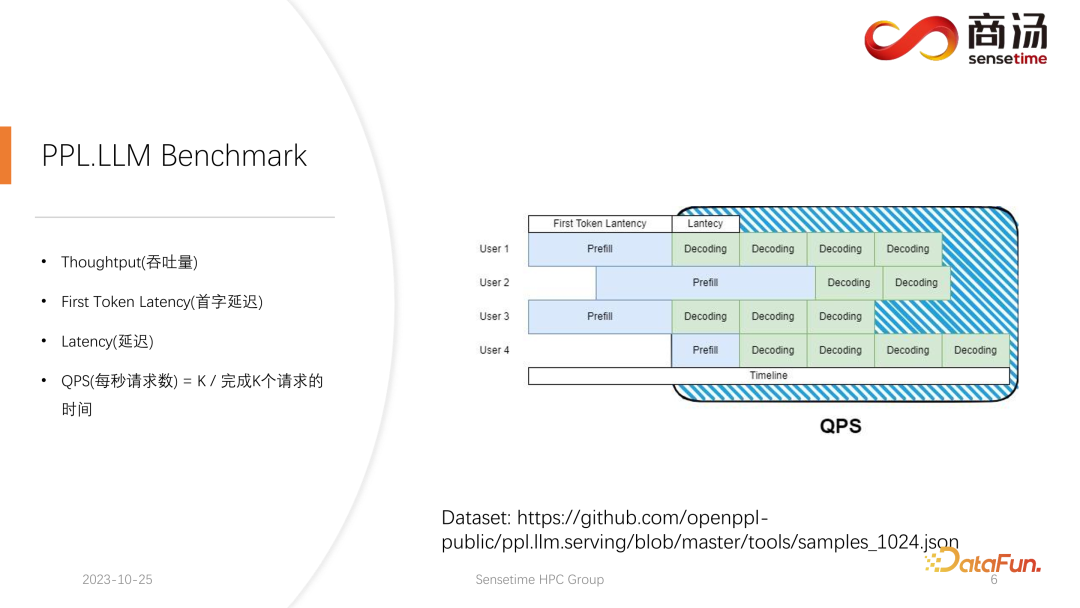
再来看 QPS。QPS 是一个非常具体的指标,它表示系统中每秒可以处理多少个请求,在进行这个测试的时候,我们会使用实际的数据。(关于这份数据,我们已经做好了采样,并且放在了 github 上。)
QPS 的测量跟吞吐量不太一样,因为在实际使用大语言模型系统的时候,每一个用户到来的时间是不确定的。有的用户可能早来,有的用户可能晚来,并且每一个用户做完 Prefill 之后的生成长度也是不确定的。有的用户可能生成 4 个词就退出,有的用户可能要生成 20 多个词。
在 Prefill 阶段,在实际线上推理当中,因为用户实际生成长度不一样,所以会遇到一个问题:有些用户会提前生成完,而有些用户要生成很多长度之后才会结束。在这样的生成过程中,有很多地方的 GPU 会空闲。因此在实际的推理过程中,我们的 QPS 并不能够发挥完全的吞吐量优势。我们的吞吐量可能很大,但实际的处理能力可能会很差,因为在这个处理过程当中充满了无法使用显卡的空洞。所以在 QPS 指标上,我们会有非常多的具体的优化方案,避免计算的空洞或者无法有效利用显卡的现象存在,从而使得吞吐量能够完全服务到用户上。
接下来进入到大语言模型的推理流程当中,看看我们究竟做了哪些优化,使得系统在 QPS 以及吞吐量等指标上都达到比较优秀的情况。
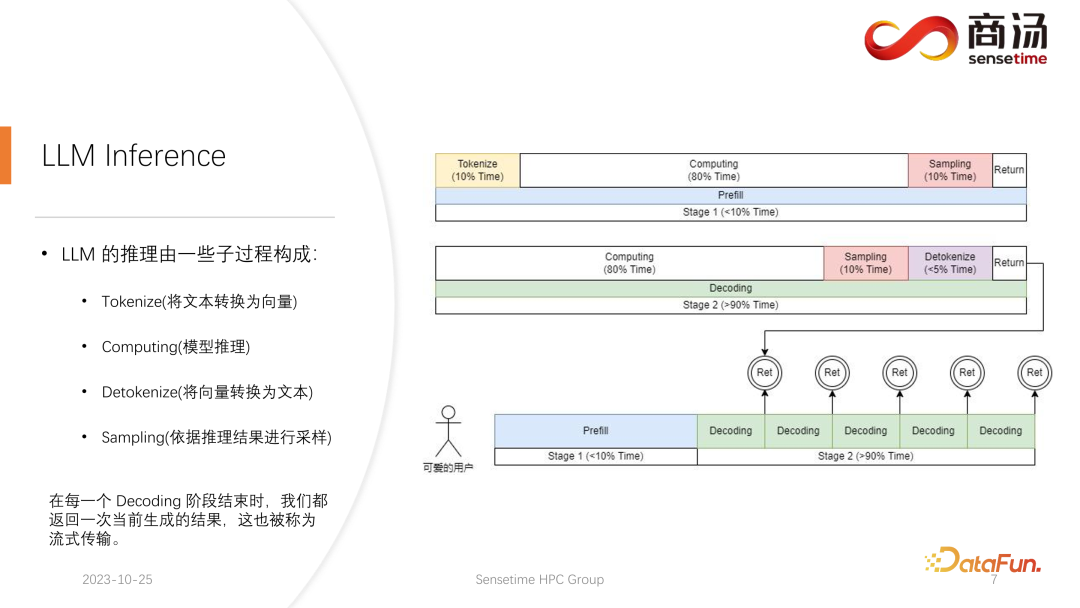
首先来详细介绍一下大语言模型的推理过程,前文中提到了每个请求都要经历 prefill 和 decoding 两个阶段,在 prefill 阶段,至少要做四件事情:
第一件事情是把用户的输入进行向量化,tokenize 的过程指的是将用户输入的文本转换为向量,相对于 prefill 整个阶段来说,大概要占掉 10% 的时间,这是有代价的。
之后就会进行真正的 prefill 计算,这一过程会占掉大概 80% 的时间。
计算之后会进行 sampling,这个过程在 Pytorch 里面一般会用 sample、top p。在大语言模型推理当中会用 argmax。总而言之,是根据模型的结果,生成最后词的一个过程。这个过程会占掉 10% 的时间。
最后将 refill 的结果返回给客户,这需要的时间会比较短,大概占 2% 到 5% 的时间。
Decoding 阶段不需要 tokenize,每一次做 decoding 都会直接从计算开始,整个decoding 过程会占掉 80% 的时间,而后面的 sampling,也就是采样生成词的过程,也要占掉 10% 的时间。但它会有一个 detokenize 的时间,detokenize 是指生成了一个词之后,这个生成的词是个向量,需要把它解码回文本,这一操作大概会占掉 5% 的时间,最后将这个生成的词返回给用户。
新的请求进来,在进行完 prefill 之后,会不断迭代进行 decoding,每一个 decoding 阶段结束之后,都会将结果当场返回给客户。这样的生成过程在大语言模型里面是很常见的,我们称这样的方式为流式传输。
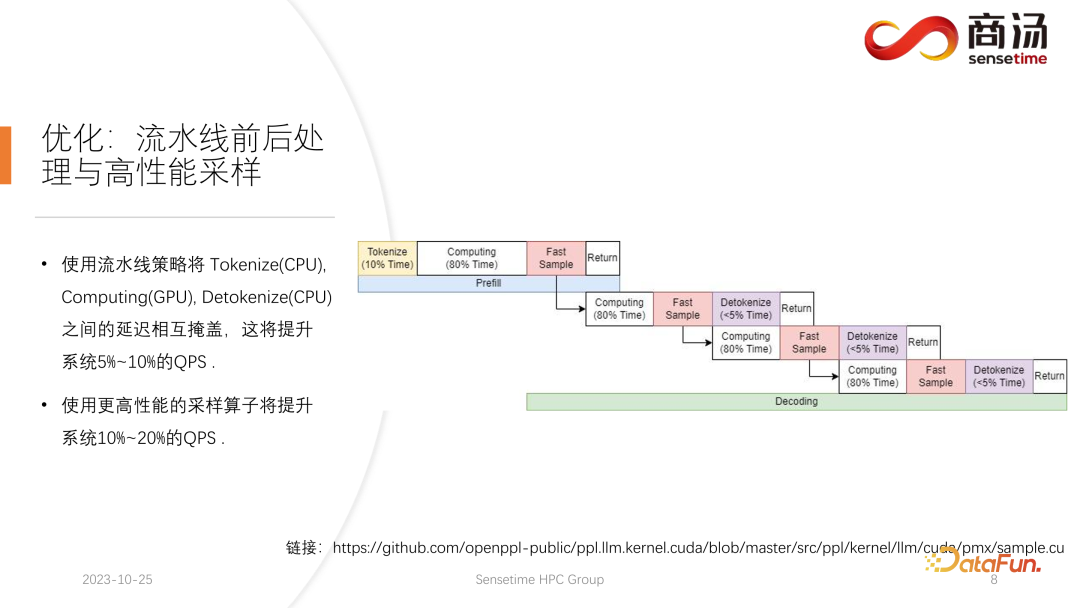
这里要介绍的第一个优化是流水线优化,其目的是尽可能让显卡利用率占满。
在大语言模型推理过程中,tokenize、fast sample 和 detokenize 这些过程都与模型的计算无关。我们可以把整个大语言模型的推理想象成这样一个过程,在执行 prefill 的过程中,当我拿到了 fast sample 的词向量之后,就可以立刻开始下一个阶段 decoding,不用等到结果返回,因为结果已经在 GPU 上了。而当完成了一次 decoding 后,不用等待 detokenize 的完成,可以立刻开始下一次的 decoding。因为 detokenize 是个 CPU 过程,后面这两个过程,只涉及到用户的结果返回,不涉及任何 GPU 的运算。并且在执行完采样过程之后,就已经知道下一个生成的词是什么了,我们已经拿到了所需的所有数据,可以立刻开始下一次运算,不需要再等待后面两个过程的完成。
在 PPL.LLM 的实现当中使用了三个线程池:
第一个线程池负责执行 tokenize 过程;
第三个线程池负责执行后面的 fast sample 以及返回结果的过程和 detokenize;
中间的线程池用来执行 computing 的过程。
这三个线程池互相异步地把这三部分的延迟相互隔离,从而尽可能地将这三部分的延迟掩蔽掉。这将给系统带来 10% 到 20% 的 QPS 提升,这就是我们所做的第一项优化。
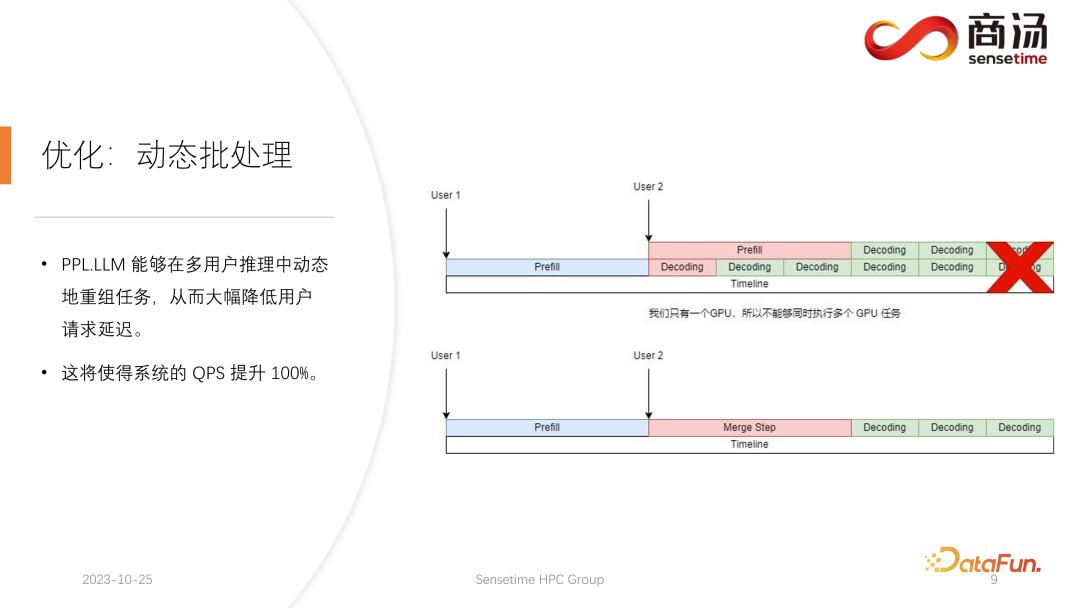
在这之后,PPL.LLM 还可以执行一项更有意思的优化,叫做动态批处理。
前文中提到,在实际的推理过程当中,用户的生成长度不同,并且用户到达的时间也并不一样。因此会存在这样一种情况,如果当前的 GPU 在推理过程当中,已经有一个请求在线上进行推理,在推理进行到一半时,第二个请求插入进来,这时第二个请求的生成过程会跟第一个请求的生成过程相冲突。因为我们只有一个 GPU,这个 GPU 上只能够串形地跑任务,所以不能简单地把它们在 GPU 上做并行。
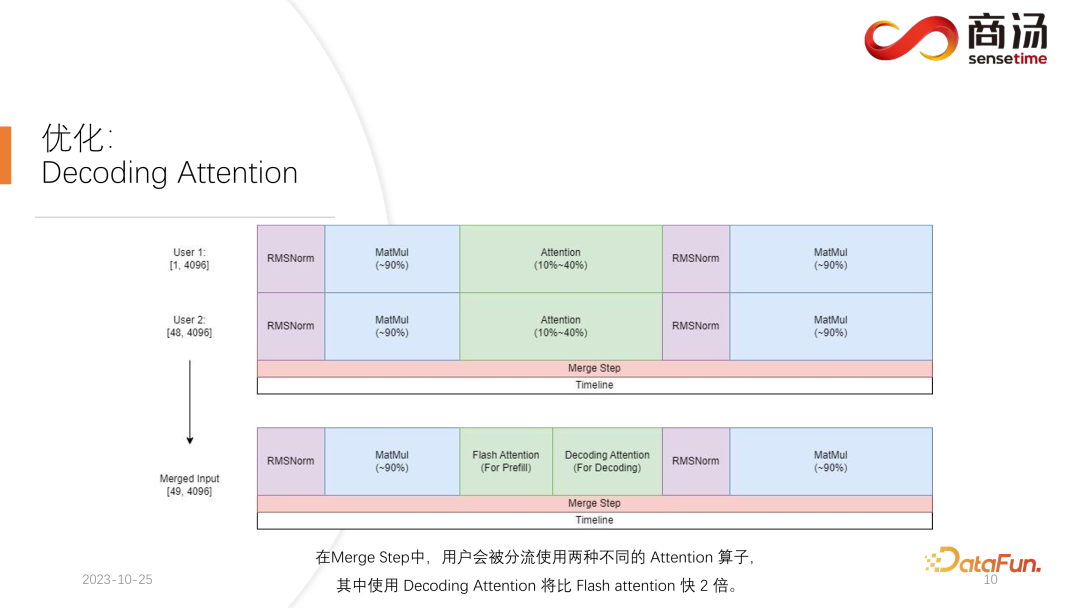
我们的做法是,在第二个请求进入的时间点,把它的 prefill 阶段和第一个请求对应的decoding 阶段进行混合,生成一个新的阶段称为 Merge Step。在这个 Merge Step 中,不仅会进行第一个请求的 decoding,同时会进行第二个请求的 Prefill。这项功能在许多大语言模型推理系统中都会存在,它的实现使得大语言模型的 QPS 提升达到了 100%。
具体过程为,第一个请求生成过程进行了一半,意味着它在进行 decoding 时会有一个长度为 1 的输入,而第二个请求是新进入的,在进行 Prefill 的过程当中,会有一个长度为 48 的输入。将这两个输入沿着第一个维度相互拼接,拼接完的输入长度为 49,并且 hidden dimension 是 4096 的输入。在这长度为 49 的输入当中,第一个词是第一个请求的,剩下的 48 个词是第二个请求的。
由于在大模型推理当中,所需要经历的算子,比如 RMSNorm、矩阵乘和 attention 等算子,不论是做 decoding 还是做 prefill,它们的结构都是不变的。因此拼接完的输入可以直接放入到整个网络中去跑。我们只需要在一个地方加以区分,那就是 attention。在 attention 的过程当中或者在执行 self attention 算子的过程当中,我们会做一次数据分流,将所有做 decoding 的请求分流成一波,把所有做 prefill 的请求分流到另外一波,执行两个不同的运算。所有做 prefill 的请求,将会执行 Flash Attention;所有做 decoding 的用户,将会执行一个非常特殊的算子,叫做 Decoding Attention。在分流执行完 attention 算子之后,这些用户的输入会再一次被拼接到一起,完成其它算子的计算。
对于 Merge Step,实际上当每个请求到来的时候,我们都会把这个请求跟系统上现在已有的所有请求的输入拼接在一起,完成这次计算,然后继续往下不停地做 decoding,这是动态批处理在大语言模型中的实现。
Decoding Attention 算子,不像 Flash Attention 算子那样出名,但其实在处理 decoding 任务上比 Flash Attention 要快得多。
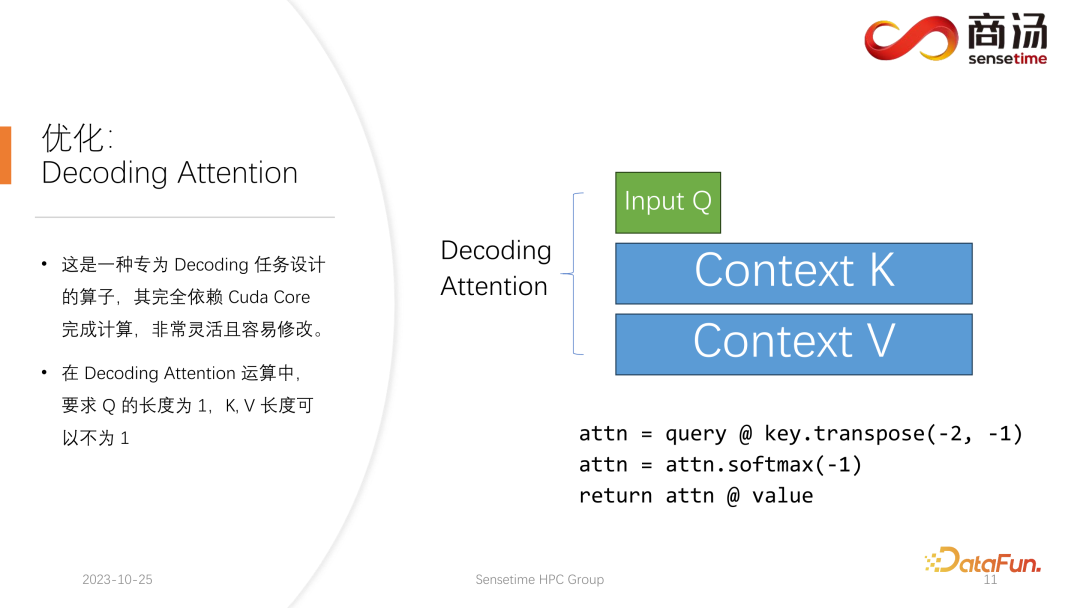
这是一种专门为 decoding 任务所设计的算子,完全依赖 Cuda Core,不会依赖Tensor Core 完成计算。它非常灵活并且容易修改,但它有一个限制,因为其特点是在 decoding 的 tensor 的运算当中,所以会要求输入的 q 的长度必须是 1,但 k 和 v 的长度是可变的。这是 Decoding Attention 的限制,在这种限制下,我们可以做一些特定的优化。

这种特定的优化使得在 decoding 阶段的 attention 算子的实现,会比 Flash Attention 更快。这个实现目前也已经开源,大家可以到上图中的网址进行访问。
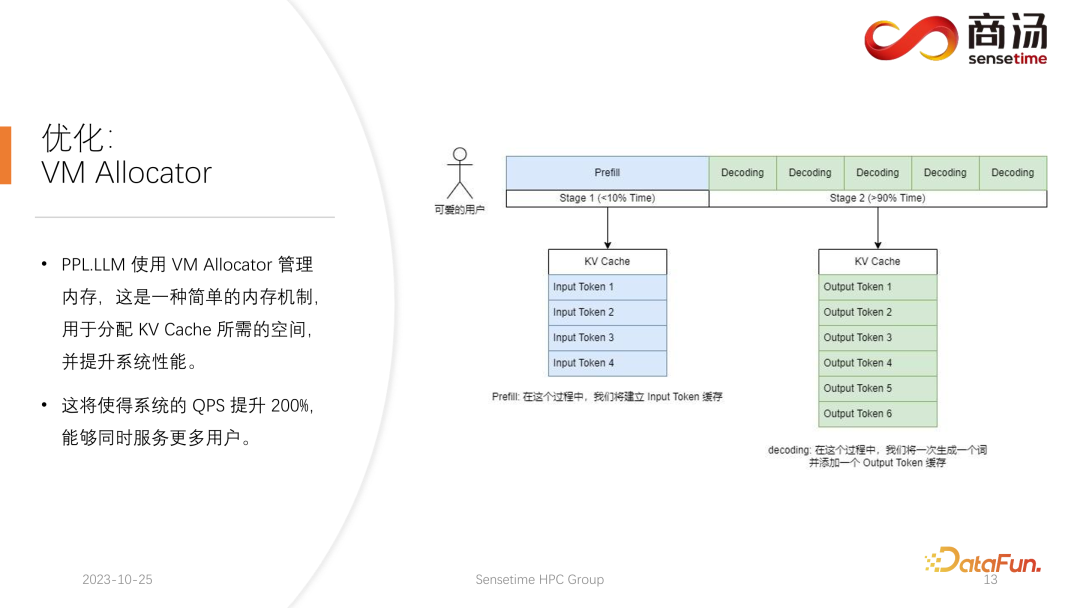
另一项优化是 Virtual Memory Allocator,对应 Page Attention 优化。当请求来到之后,要进行 prefill 阶段,又要进行 decoding 阶段,它所有输入的 token 会生成一个 KV 缓存,这个KV 缓存记录了这个请求所有的历史信息。那么要给这样一个请求分配多长的 KV 缓存空间,才能满足它完成此次生成任务呢?如果分的太多,显存会有浪费,如果分的太少,在 decoding 阶段,碰到了 KV 缓存的截止位置,就没有办法继续往下生成。
为了解决这一问题,有 3 种方案。
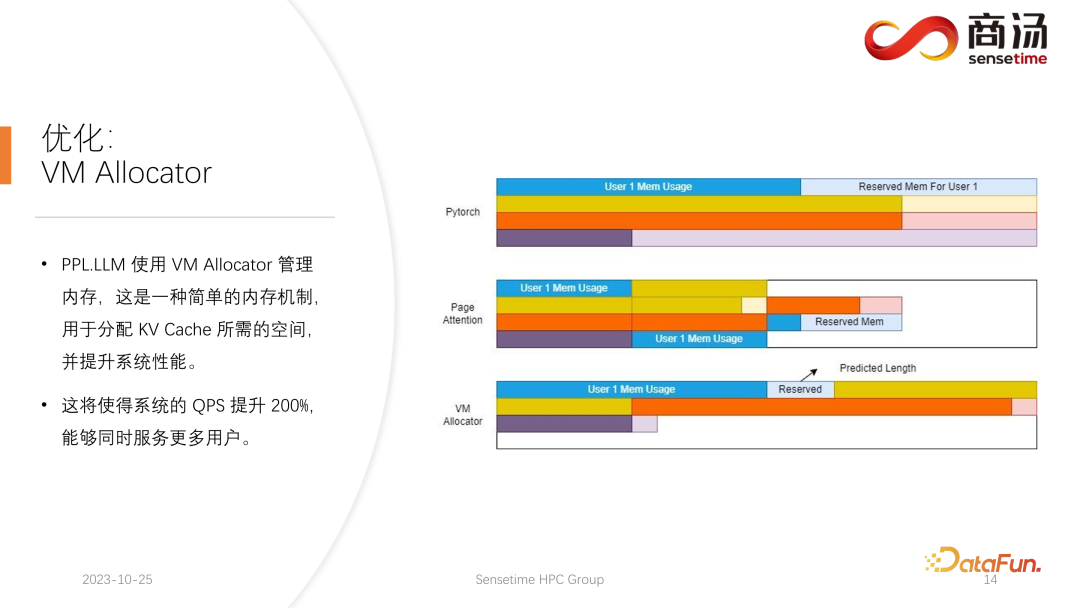
Pytorch 的显存管理方式是为每一个请求预留一片足够长的空间,通常是 2048 或者 4096,能够保证完成 4096 个词的生成。但大部分用户实际的生成长度不会有那么长,所以会有大量的内存空间被浪费掉。
Page Attention 采用的是另外一种显存管理方式。允许生成过程中不断为用户追加显存。类似于操作系统中的页式存储或者内存分页。当一个请求来到之后,系统会为这个请求分配一小块显存,这一小块显存通常只够生成 8 个字符,当请求生成了 8 个字符之后,系统会追加一块显存,可以把结果再写到这块显存里面,同时系统会维护一个显存块和显存块之间的链表,从而使得算子可以正常地进行输出。当生成的长度不断变长时,会不断地给用户追加显存块的分配,并且可以动态维护显存块分配的列表,使系统不会存在大量浪费的资源,不需要为这个请求保留太多的显存空间。
PPL.LLM 使用的是 Virtual Memory 的管理机制,为每一个请求预测一个它所需的生成长度。每个请求进来之后,都会直接为其分配一个连续的空间,这个连续空间的长度是预测出来的。但理论上看可能难以实现,尤其到了线上推理阶段,不太可能清楚地知道每个请求究竟要生成多长的内容。因此我们推荐训练一个模型去做这件事情。因为即使我们采用了 Page Attention 这样的模式,依然会遇到问题。Page Attention 在运行的过程中,具体到一个特定的时间点,比如当前系统上已经有了四个请求,系统里面还剩余 6 块显存没有被分配。这时我们无法知道是否会有新的请求进来,能否为其继续提供服务,因为当前的四个请求还没有结束,可能未来还要继续为它们追加新的显存块。所以即使是 Page Attention 机制,还是需要预测每一个用户实际的生成长度。这样才知道在具体的一个时间点上能不能接受一个新的用户的输入。
这是我们目前所有的推理系统都没有做到的事情,包括 PPL 目前也没有实现。但 Virtual Memory 的管理机制,还是让我们很大程度上避免了显存的浪费,从而使系统整体的 QPS 提升达到 200% 左右。
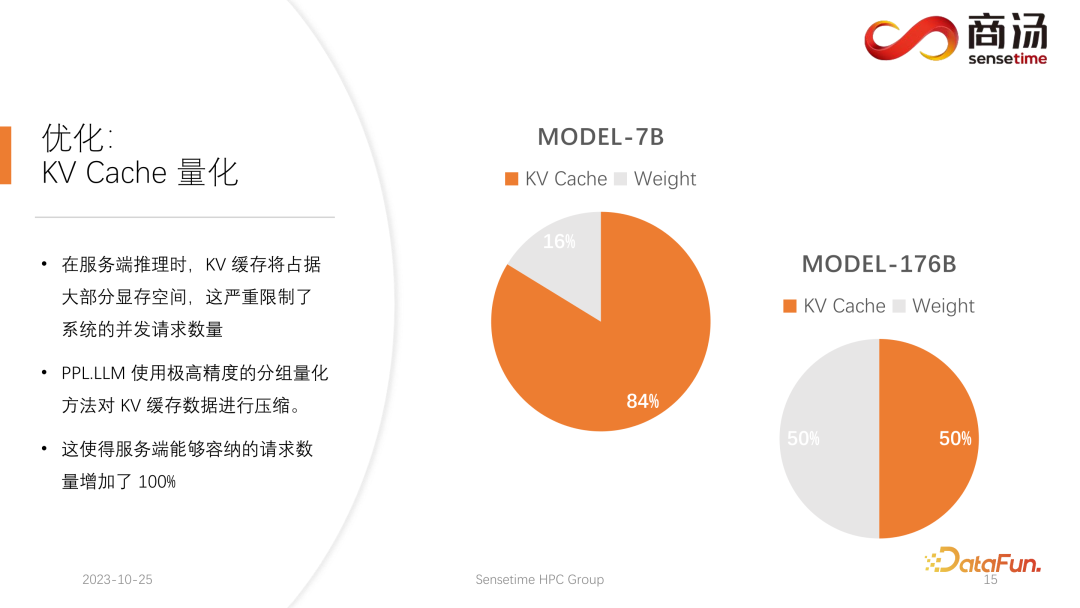
PPL.LLM 在做的另外一项优化,就是 KV 缓存的量化,在服务端推理的过程当中,KV 缓存会占据绝大部分的显存空间,这会严重限制系统的并发请求数量。
可以看到,在服务端,特别是 A100、H100 这样的大显存的服务器上运行如 7B 模型这样的大语言模型时,它的 KV 缓存将占到 84% 的显存空间,而对于如 176B 这样的千亿级大模型,它的 KV 缓存也将占用 50% 以上的缓存空间。这会严重地限制模型的并发数量,每一个请求到来后,都需要给它分配很大的显存。这样请求数量就无法提升上去,继而使得 QPS 以及吞吐量都无法提升。
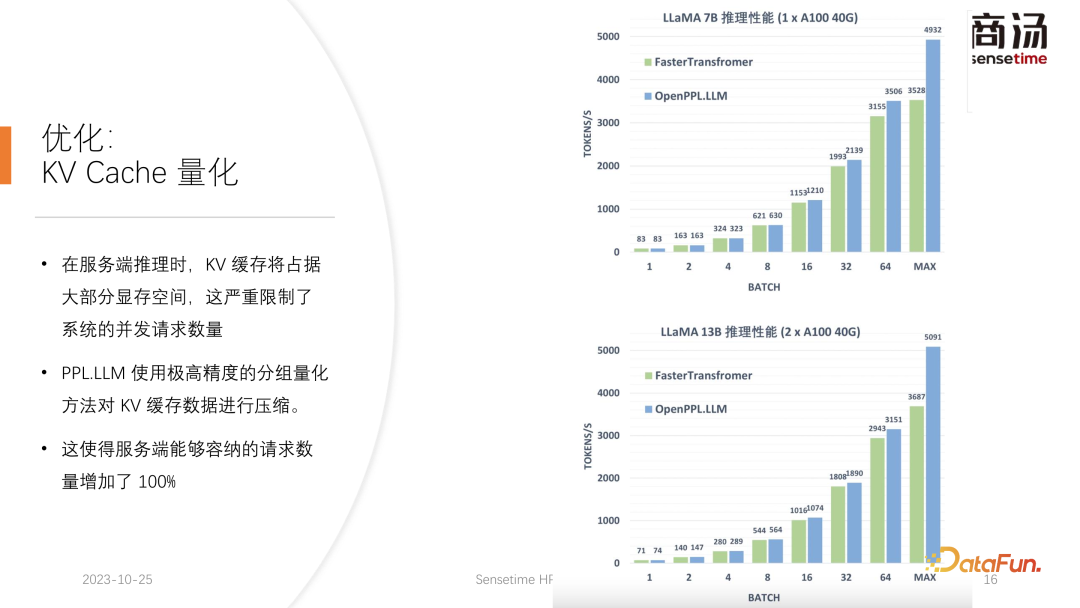
PPL.LLM 使用了一种非常特殊的量化方式,分组量化对 KV 缓存的数据进行压缩。也就是对原来 FP16 的数据,会尝试把它量化到 INT8。这样会使 KV 缓存的体积缩小 50%,并使得服务端能够容纳的请求数量增加 100%。
之所以相比 Faster Transformer 能够提升大约 50% 的吞吐量,正是得益于 KV 缓存量化所带来的 batch size 的提升。

在 KV 缓存量化之后,我们进行了更细力度的矩阵乘法的量化。在整个服务端推理的过程当中,矩阵乘法占到整个推理时间的 70% 以上,PPL.LLM 使用了一种动态的 per-channel/per-token 交替的混合量化方式来加速矩阵乘法。这些量化同样是精度极高的,并且能够提升接近 100% 的性能。
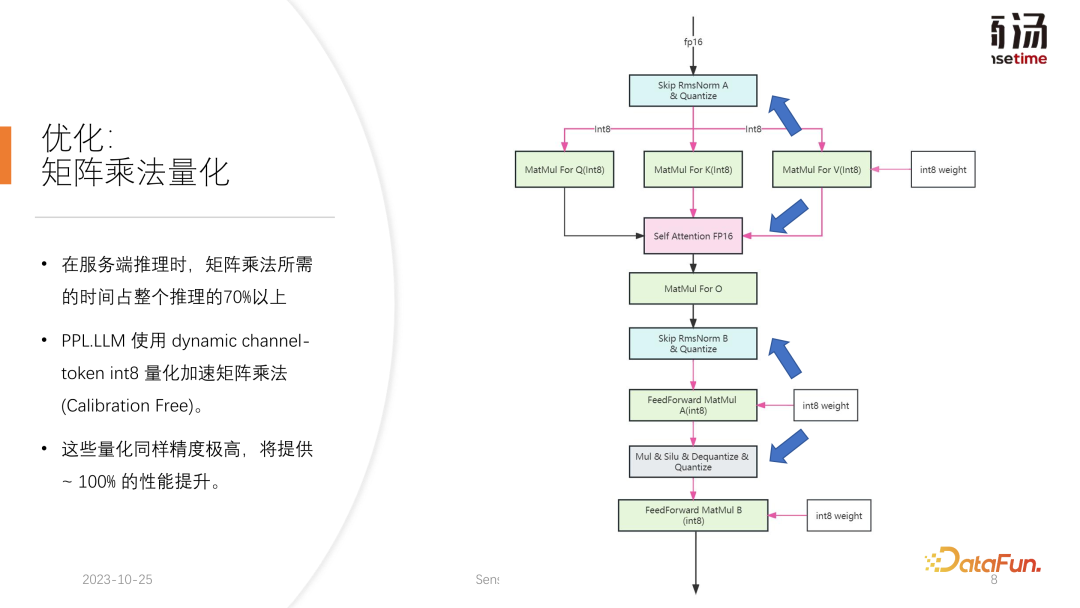
具体做法是,在 RMSNorm 算子的基础之上,融合一个量化算子,这个量化算子会在 RMSNorm 算子的功能基础之上统计其 Token 信息,统计每一个 token 的最大最小值,并且沿着 token 的维度,把这个数据进行量化。也就是说经过了RMSNorm 之后的数据将会从 FP16 转成 INT8,并且这一次量化是全动态的,不需要做 calibration。而在后面的 QKV 矩阵乘当中,这三个矩阵乘都将进行 per-channel 量化。它们接收的数据是 INT8 的,同样它们的权重也是 INT8 的,所以这些矩阵乘可以完整地执行 INT8 的矩阵乘法。它们的输出将会被 Soft Attention 接受,但在接受之前会执行一次解量化过程,这次解量化过程将和 soft attention 算子融合。
而后面的 O 矩阵乘法是不做量化的,Soft Attention 本身的计算过程也不做任何量化。在后续的 FeedForward 过程当中,这两个矩阵同样采用一样的方式进行量化,和上面的 RMSNorm 进行融合,或者与上面的 Silu 和 Mul 这样的激活函数进行融合。它们的解量化算子将和其下游算子进行融合。
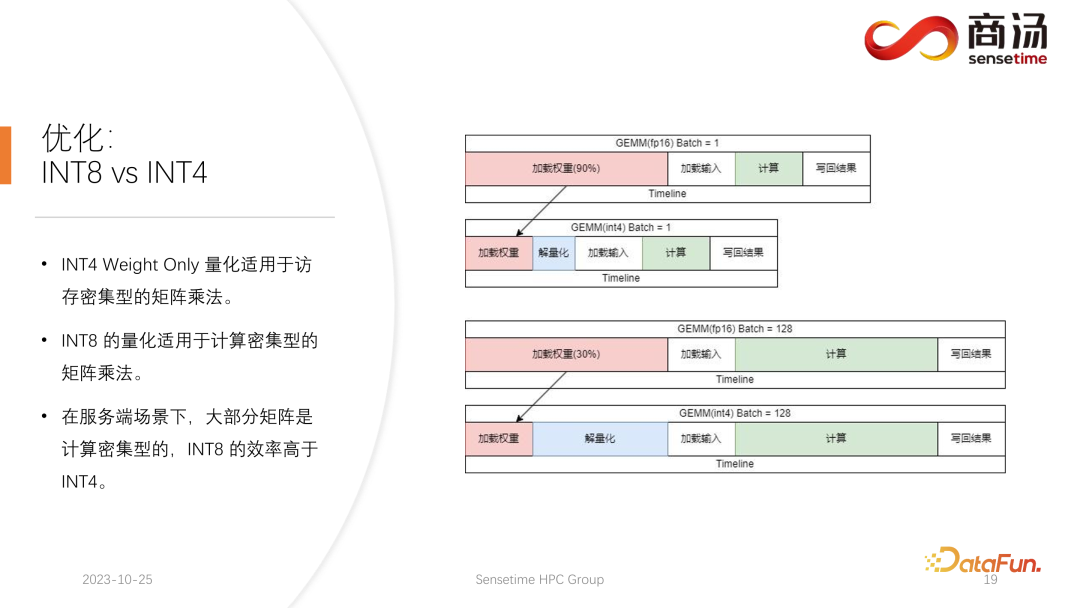
目前学术界对于大语言模型的量化关注点可能主要集中在 INT4 上,但是在服务端推理的过程中,其实更适合使用 INT8 的量化。
INT4 的量化也叫 Weight Only 的量化,这种量化方式出现的意义在于,当大语言模型推理过程中 batch 比较小时,在矩阵乘法的计算过程中,90% 的时间都会用来加载权重。因为权重的体积非常大,而加载输入的时间很短,它们的输入,即 activation 也非常短,计算的时间也不会很长,写回结果的时间同样不会很长,这意味着这个算子是一个访存密集型的算子。在这种情况下,我们会选用 INT4 的量化,前提是 batch 足够的小,使用 INT4 的量化每一次加载权重之后,会紧接着进行一个解量化的过程。这次解量化会把权重从 INT4 解量化成 FP16,经历解量化过程之后,后面的计算和 FP16 是完全一样的,也就是说 INT4 Weight Only 的量化适用于访存密集性的矩阵乘法,其计算过程还是由 FP16 的运算器件去完成的。
当 batch 足够大,比如 64 或者 128 时,INT4 的 Weight Only 量化将不会带来任何性能提升。因为如果 batch 足够大,那计算时间会被拉得很长。并且 INT4 Weight Only 量化有一个非常不好的点,它的解量化过程所需要的计算量是会随着 batch 的(GEMM Batch)提升而提升的,随着输入 batch 的提升,解量化的时间也会越来越长。当 batch 达到 128 的时候,解量化所带来的时间损耗和加载权重带来的性能优势,就已经相互抵消了。也就是说当 batch 达到 128 之后,INT4 的矩阵量化不会比 FP16 矩阵量化快,性能优势极小。大概在 batch等于 64 的时候,INT4 的 Weight Only 量化只会比 FP16 的快 30%,等到 128 的时候,大约只会快 20% 甚至更小。
但对于 INT8 来说,INT8 的量化与 INT4 量化最不同的一点,是它不需要任何解量化的过程,并且它的计算是可以压缩一倍时间的。在 batch 等于 128 时,从 FP16量化到 INT8,加载权重的时间将会减半,计算的时间也会减半,这会带来百分之百的加速。
在服务端场景下,特别是因为会有不断的请求涌入,大部分的矩阵乘,都会是计算密集型的。在这种情况下,如果为了追求极限的吞吐量,INT8 的效率其实是高于 INT4 的。这也是为什么我们目前已经完成的实现里面,在服务端上主推 INT8 的一个原因。
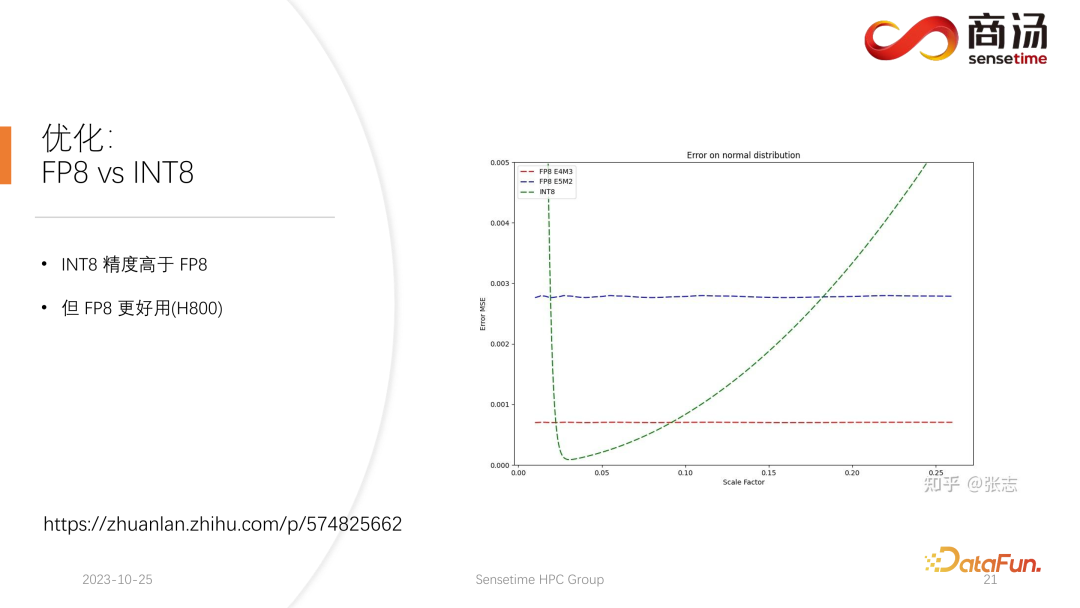
在 H100、H800、4090 上面,我们可能会执行 FP8 的量化。FP8 这样的数据格式,在 Nvidia 最新一代的显卡当中被引入。INT8 的精度从理论上是要高于 FP8 的,但是 FP8 会更好用,性能会更高一些。我们在后续服务端的推理过程的更新当中也会推进 FP8 的落地。上图中可以看到,FP8 的误差相比 INT8 会大 10 倍左右。INT8 会有一个量化的尺寸因子,可以通过调整尺寸因子,降低 INT8 的量化误差。而 FP8 的量化误差跟尺寸因子基本上是无关的,它不受尺寸因子的影响,这使得我们基本上不需要对它做任何的 calibration。但是它的误差总体来讲是要高于 INT8 的。

PPL.LLM 在后续的更新中,也会更新 INT4 的矩阵量化。这种 Weight Only 的矩阵量化主要是为端侧服务的,为了手机端移动端等 batch 固定为 1 的设备。在后续的更新当中会从 INT4 逐渐转变为非线性量化。因为在 Weight Only 的计算过程当中,会存在一个解量化的过程,这个解量化过程实际是可定制的,未必是一个线性的解量化过程,其使用其它解量化过程以及量化过程,会使得这一次计算的精度更高。
一个比较典型的例子,就是在一篇论文当中所提到的 NF4 的量化,这种量化实际上会通过一种打表的方式进行量化及解量化,是一种非线性的量化。PPL.LLM 的后续更新当中会尝试使用这样的量化来完成端侧推理的优化。
最后,介绍一下大语言模型处理的硬件。
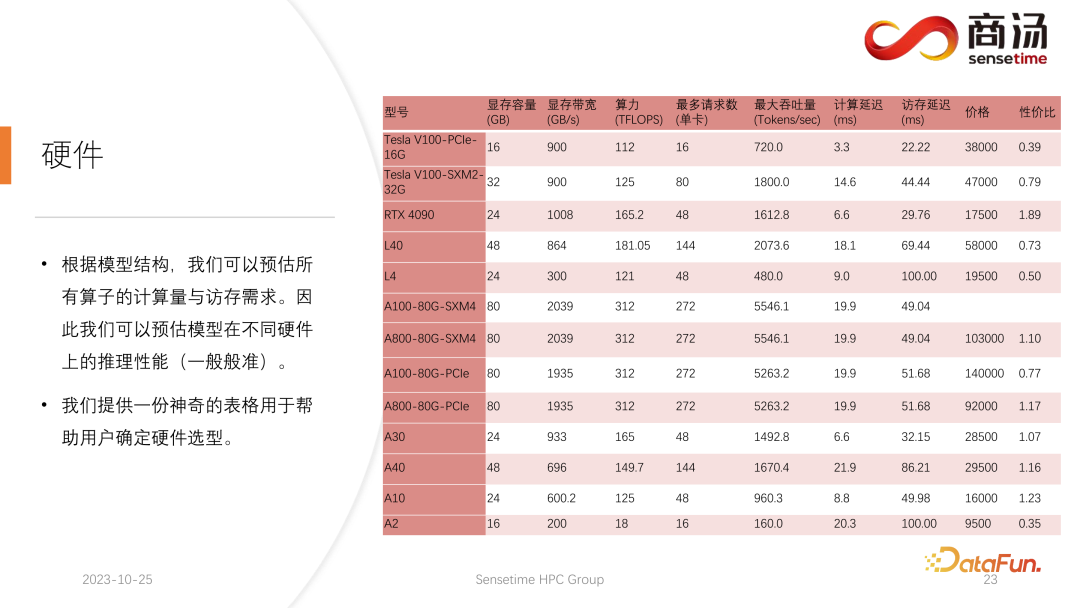
模型结构一旦确定,我们就会知道它具体的计算量,具体需要多少访存,需要多少计算量。同时还会知道每张显卡的带宽、算力、价格等。在确定了模型的结构以及确定了硬件指标之后,我们就可以通过这些指标去计算出在这张显卡上推理大模型的最大吞吐量会是多少、计算延迟是多少、访存访问时间需要多少,可以算出一个非常具体的表。我们把这个表格公开在后续的资料当中,大家可以访问这个表格,查看最适合大语言模型推理的显卡型号有哪些。
对于大语言模型推理来说,因为大部分算子都是访存密集型的,访存的延迟总会比计算延迟要高。因为大语言模型的参数矩阵确实太大了,所以哪怕是在 A100/80G 上,batch size 开到 272 的时候,它的计算延迟都是较小的,访存延迟反而会更高。因此,我们的许多优化都是从访存上着手的。而进行硬件选择时,我们主要的方向就是选择带宽比较高、显存比较大的设备。从而使得大语言模型在推理时,可以支撑更多的请求,支撑更快的访存,相应的吞吐量也会更高。

以上就是本次分享的内容。所有相关资料都放在了网盘中,链接参见上图。我们所有的代码也已经开源在了 github 上。欢迎大家随时与我们进行沟通。
A1:Decoding Attention 这个算子非常特殊,它的 Q 的长度永远是 1,所以它不会像Flash Attention 那样面临 Softmax 里有非常大的访存量。实际上在 Decoding Attention 的执行过程当中,就是完整地执行这次 Softmax 的过程,并不需要像 Flash Attention 那样更快执行。
A2:这是一个好问题,首先这个解量化不是像大家想的那样,只需要把权重从 INT4 塞回 FP16 就行了,如果只做这件事情,那权重有多少就要解多少。实际上不是这样的,因为这是一个融合在矩阵乘法里面的解量化,不能在执行矩阵乘法之前,把所有权重解量化出来,放在那然后再去读。这样我们所做的 INT4 的量化就没有意义了。它是在执行过程当中不停地去解量化,因为我们会执行分块的矩阵乘,每一个权重所要读写的次数并不是 1,需要不停地拿过来计算,这个次数实际上跟 batch 有关。也就是区别于之前那些优化量化的手段,会有单独的量化的算子和解量化算子。两个算子的插入,解量化还是直接融合在算子中的。我们执行的是矩阵乘法,所以所要解量化的次数并不是一次。
A3:根据我们的测试是可以被掩盖的,而且其实还远远有剩余。KV 计算中的反量化以及量化都会被融合进 self attention 算子当中,具体来说就是 Decoding Attention。根据测试,这个算子即使在 10 倍的计算量,可能都可以掩盖掉。就是访存的延迟都掩盖不了它,它主要的瓶颈在于访存,它计算量还远远达不到可以掩盖掉它访存的那个程度。所以 KV cache 当中的反量化计算,对于这个算子来说,基本上是一个很好被掩盖的东西。
以上是高性能 LLM 推理框架的设计与实现的详细内容。更多信息请关注PHP中文网其他相关文章!





















