

在自动驾驶领域,研究人员也在朝着 GPT/Sora 等大模型方向进行探索。
与生成式 AI 相比,自动驾驶也是近期 AI 最活跃的研究和开发领域之一。要想构建完全的自动驾驶系统,人们面临的主要挑战是 AI 的场景理解,这会涉及到复杂、不可预测的场景,例如恶劣天气、复杂的道路布局和不可预见的人类行为。
目前的自动驾驶系统通常由3D感知、运动预测和规划三部分组成。具体而言,3D感知主要用于检测和跟踪熟悉的物体,但对于罕见物体及其属性的识别能力有所局限;而运动预测和规划主要关注物体的轨迹动作,但通常忽视了物体与车辆之间的决策级交互。这些局限性可能会影响自动驾驶系统在处理复杂交通场景时的准确性和安全性。因此,未来的自动驾驶技术需要进一步改进,以更好地识别和预测各种类型的物体,以及更有效地规划车辆的行驶路径,以提高系统的智能性和可靠性
实现自动驾驶的关键在于将数据驱动的方法转变为知识驱动,这需要训练具备逻辑推理能力的大型模型。只有这样,自动驾驶系统才能真正解决长尾问题,并且向 L4 级能力迈进。目前,随着像 GPT4、Sora 这样的大型模型不断涌现,规模效应也展现出了强大的 few-shot/zero-shot 能力,这使人们开始考虑一种新的发展方向。
最新的研究论文来自清华大学交叉信息研究院和理想汽车,其中他们介绍了名为DriveVLM的新模型。这一模型受到了生成式人工智能领域中兴起的视觉语言模型(VLM)的启发。DriveVLM在视觉理解和推理方面展现出了出色的能力。
这项工作在业界是首个提出自动驾驶速度控制系统的工作,其方法充分结合了主流自动驾驶流程和具备逻辑思考能力的大型模型流程,并首次成功将大型模型部署到终端进行测试(基于Orin平台)。
DriveVLM涵盖一个Chain-of-Though (CoT)流程,包括三个主要模块:场景描述、场景分析和分层规划。在场景描述模块中,使用语言描述驾驶环境并确定场景中的关键对象;场景分析模块深入研究这些关键对象的特征以及它们对自动驾驶车辆的影响;而分层规划模块则逐步制定计划,从元动作和决策描述到路径点。
这些模块对应于传统自动驾驶系统的感知、预测和规划步骤,但不同之处在于它们处理对象感知、意图级预测和任务级规划,这些在以往是非常具有挑战性的。
虽然 VLM 在视觉理解方面表现出色,但它们在空间基础和推理方面存在局限性,而且其算力需求对端侧推理速度提出了挑战。因此,作者进一步提出了 DriveVLMDual,这是一种结合了 DriveVLM 和传统系统优点的混合系统。DriveVLM-Dual 可选择将 DriveVLM 与传统 3D 感知和规划模块(如 3D 物体探测器、占用网络和运动规划器)集成,使系统能够实现 3D 接地和高频规划能力。这种双系统设计类似于人脑的慢速和快速思维过程,可以有效地适应驾驶场景中不同的复杂性。
新研究还进一步明确了场景理解和规划(SUP)任务的定义,并提出了一些新的评估指标,以评估 DriveVLM 和 DriveVLM-Dual 在场景分析和元动作规划方面的能力。此外,作者还进行了大量的数据挖掘和注释工作,为 SUP 任务构建了内部 SUP-AD 数据集。
经过 nuScenes 数据集和自有数据集上的大量实验,人们证明了 DriveVLM 的优越性,尤其是在少量镜头的情况下。此外,DriveVLM-Dual 超越了最先进的端到端运动规划方法。
论文《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》

论文链接:https://arxiv.org/abs/2402.12289
项目连接:https://tsinghua-mars-lab.github.io/DriveVLM/
DriveVLM 的整体流程如图 1 所示:
将连续帧视觉图像进行编码,通过特征对齐模块,与 LMM 进行交互;
从场景描述开始引导 VLM 模型的思考,先引导时间、场景、车道环境等静态场景,再引导影响驾驶决策关键障碍物;
对关键障碍物进行分析,通过传统 3D 检测和 VLM 理解的障碍物进行匹配,进⼀步确认障碍物的有效性并消除幻觉,描述该场景下的关键障碍物的特征和对我们驾驶的影响;
给出关键的「元决策」,如减速、停车、左右转等,在根据元决策给出驾驶策略描述,并最终给出主车未来的驾驶轨迹。
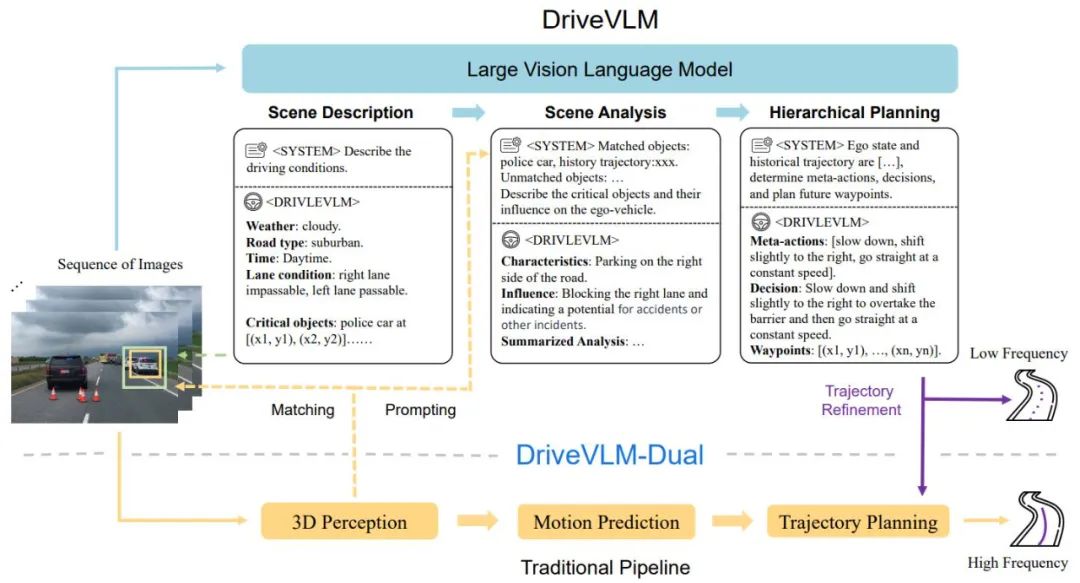
图 1.DriveVLM 和 DriveVLM-Dual 模型管道。一系列图像由大视觉语言模型 (VLM) 处理,以执行特殊的思想链 (CoT) 推理,从而得出驾驶规划结果。大型 VLM 涉及视觉变换器编码器和大语言模型(LLM)。视觉编码器产生图像标记;然后基于注意力的提取器将这些标记与 LLM 对齐;最后,LLM 进行 CoT 推理。CoT 过程可以分为三个模块:场景描述、场景分析和层次规划。
DriveVLM-Dual 是一种混合系统,利用 DriveVLM 对环境的综合理解和决策轨迹的建议,提升了传统自动驾驶 Pipeline 的决策和规划能力。它将 3D 感知结果合并为语言提示,以增强 3D 场景理解能力,并通过实时运动规划器进一步细化轨迹路点。
尽管 VLM 擅长识别长尾物体和理解复杂场景,但它们经常难以精确理解物体的空间位置和详细运动状态,这一不足构成了重大挑战。更糟糕的是,VLM 巨大的模型体量导致高延迟,阻碍了自动驾驶的实时响应能力。为了应对这些挑战,作者提出了 DriveVLM-Dual,让 DriveVLM 和传统自动驾驶系统进行合作。这种新方法涉及两个关键策略:结合 3D 感知进行关键对象分析,给出高维驾驶决策信息,以及高频轨迹细化。
另外,为了充分发挥 DriveVLM 和 DriveVLMDual 在处理复杂和长尾驾驶场景方面的潜力,研究人员正式定义了一项名为场景理解规划的任务,以及一组评估指标。此外,作者提出了一种数据挖掘和注释协议来管理场景理解和规划数据集。
为了充分训练模型,作者全新开发了⼀套 Drive LLM 的标注工具和标注方案,通过自动化挖掘、感知算法预刷、GPT-4 大模型总结和人工标注等多种方式相结合,形成了目前这⼀套高效的标注方案,每⼀个 Clip 数据都包含了多达数十种标注内容。

图 2. SUP-AD 数据集的带注释样本。
作者还提出了一个全面的数据挖掘和注释管道,如图 3 所示,为所提出的任务构建场景理解规划 (SUP-AD,Scene Understanding for Planning in Autonomous Driving) 数据集,包含 100k+ 图像和 1000k+ 图文对 。具体来说,作者首先从大型数据库中进行长尾对象挖掘和具有挑战性的场景挖掘来收集样本,然后从每个样本中选择一个关键帧并进一步进行场景注释。
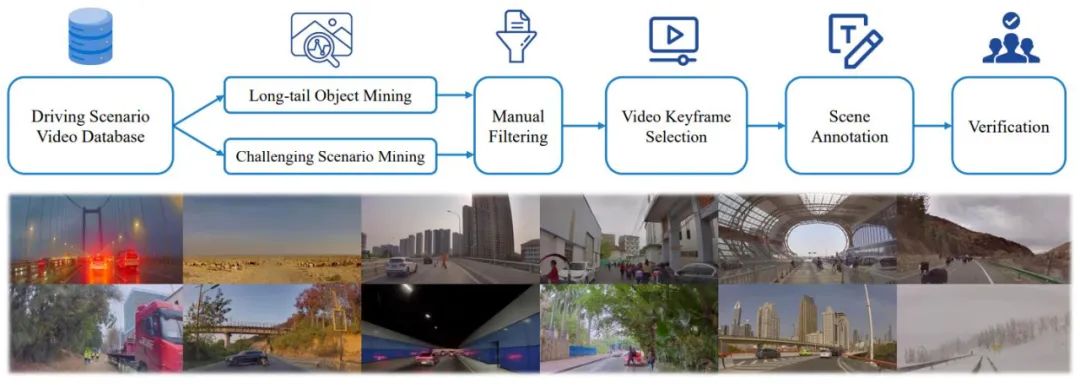
图 3. 用于构建场景理解和规划数据集的数据挖掘和注释管道(上图)。从数据集中随机采样的场景示例(如下)展示了数据集的多样性和复杂性。
SUP-AD 分为训练、验证和测试部分,比例为 7.5 : 1 : 1.5。作者在训练分割上训练模型,并使用新提出的场景描述和元动作指标来评估验证 / 测试分割上的模型性能。
nuScenes 数据集是一个大规模的城市场景驾驶数据集,有 1000 个场景,每个场景持续约 20 秒。关键帧在整个数据集上以 2Hz 的频率均匀注释。在这里,作者采用位移误差(DE)和碰撞率(CR)作为指标来评估模型在验证分割上的性能。
作者展示了 DriveVLM 与几种大型视觉语言模型的性能,并将它们与 GPT-4V 进行比较,如表 1 所示。DriveVLM 利用 Qwen-VL 作为其骨干,其实现了与其他开源 VLM 相比的最佳性能,具有应答和灵活交互的特点。其中前两个大模型已开源,使用了同样的数据进进了微调训练,GPT-4V 使用了复杂的 Prompt 进行 Prompt 工程。
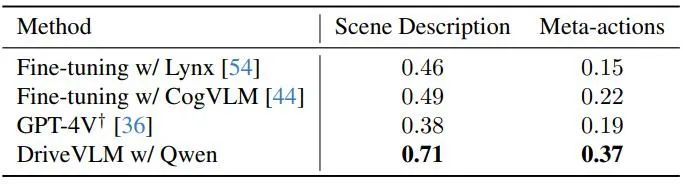
表 1. 在 SUP-AD 数据集上的测试集结果。这里使用了 GPT-4V 的官方 API,对于 Lynx 和 CogVLM,利用训练分割来进行微调。
如表 2 所示,DriveVLM-Dual 与 VAD 配合时,在 nuScenes 规划任务上取得了最先进的性能。这表明新方法虽然是为理解复杂场景而定制的,但在普通场景中也表现出色。请注意,DriveVLM-Dual 比 UniAD 有了显着提升:平均规划位移误差降低了 0.64 米,碰撞率降低了 51%。
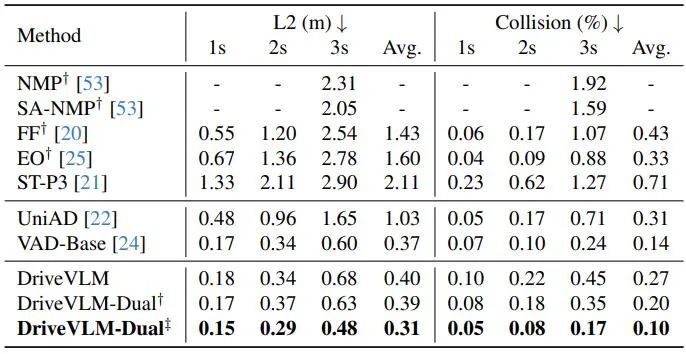
表 2. nuScenes 验证数据集的规划结果。 DriveVLM-Dual 实现了最佳性能。 † 表示使用 Uni-AD 的感知和占用预测结果。 ‡ 表示与 VAD 合作,所有模型都以自我状态作为输入。 
图 4. DriveVLM 的定性结果。橙色曲线代表模型在接下来 3 秒内计划的未来轨迹。
DriveVLM 的定性结果如图 4 所示。在图 4a 中,DriveVLM 准确预测当前场景条件,并结合有关接近我们的骑车人的有思考的规划决策。 DriveVLM 还有效地理解了前方交警手势,向自我车辆发出继续前进的信号,并且还考虑了右侧骑三轮车的人,从而做出正确的驾驶决策。这些定性结果证明了 DriveVLM 模型具有理解复杂场景并制定合适驾驶计划的卓越能力。

图 7:SUP-AD 数据集中的各种驾驶场景。

图 9. SUP-AD 数据集中牛群和羊群的示例。一群牛在本车前方缓慢移动,要求策略推理出本车缓慢行驶并与牛保持安全距离。

图 16. DriveVLM 输出的可视化。 DriveVLM 可以精确检测倒下的树木及其位置,随后规划合适的绕行轨迹。
以上是清华叉院、理想提出DriveVLM,视觉大语言模型提升自动驾驶能力的详细内容。更多信息请关注PHP中文网其他相关文章!





















