

检索增强生成(RAG)和微调(Fine-tuning)是提升大语言模型性能的两种常用方法,那么到底哪种方法更好?在建设特定领域的应用时哪种更高效?微软的这篇论文供你选择时进行参考。
在构建大语言模型应用程序时,常常使用两种方法来整合专有和特定领域的数据:检索增强生成和微调。检索增强生成是通过引入外部数据来增强模型的生成能力,而微调则是将额外的知识融入到模型本身中。然而,对于这两种方法的优缺点,我们的了解还不够充分。
本文介绍了微软研究者提出的一个新的关注点,即为农业行业创建具有特定背景和自适应响应能力的AI助手。通过引入一个全面的大语言模型流程,可以生成高质量的、行业特定的问题和答案。该流程包含了一系列系统化的步骤,首先是鉴别和收集涵盖广泛农业主题的相关文档。然后对这些文档进行清理和结构化,以便使用基本的GPT模型生成有意义的问答对。最后,生成的问答对会根据其质量进行评估和筛选。这一方法为农业行业提供了一个有力的工具,可以提供准确、实用的信息,帮助农民和相关从业人员更好地应对各种问题和挑战。
本文旨在为农业行业创造有价值的知识资源,以农业作为案例研究。其最终目标是为农业领域的LLM发展作出贡献。

论文地址:https://arxiv.org/pdf/2401.08406.pdf
论文标题:RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
本文流程的目标是生成满足特定行业专业人员和利益相关者需求的领域特定问题和答案。在该行业中,期望从AI助手那里获得的答案应基于相关的行业特定因素。
本文涉及的是农业研究,目标是生成该特定领域的答案。因此研究的起点是农业数据集,它被输入到三个主要组件中:问答生成、检索增强生成和微调过程。问答生成根据农业数据集中的信息创建问答对,检索增强生成将其用作知识源。生成的数据经过精炼,并用于微调多个模型,其质量通过一组提出的度量标准进行评估。通过这种全面的方法,利用大语言模型的力量,造福农业行业及其他利益相关者。
本文对大语言模型在农业领域的理解做出了一些特殊贡献,这些贡献可以归纳如下:
1、对 LLMs 的全面评估:本文对大语言模型进行了广泛评估,包括 LlaMa2-13B、GPT-4 和 Vicuna,以回答与农业相关的问题。使用了来自主要农业生产国的基准数据集进行评估。本文的分析中,GPT-4 一直表现优于其它模型,但也需要考虑与其微调和推理相关的成本。
2、检索技术和微调对性能的影响:本文研究了检索技术和微调对 LLMs 性能的影响。研究发现,检索增强生成和微调都是提高 LLMs 性能的有效技术。
3、LLMs 在不同行业潜在应用的影响:对于想要建立 RAG 和微调技术在 LLMs 中应用的流程而言,本文走出了开创性的一步,并促进了多个行业之间的创新和合作。
方法
本文第 2 部分详细介绍采用了方法论,包括数据获取过程、信息提取过程、问题和答案生成,以及模型的微调。该方法论围绕着一个旨在生成和评估用于构建领域特定助手的问答对流程展开,如下图 1 所示。
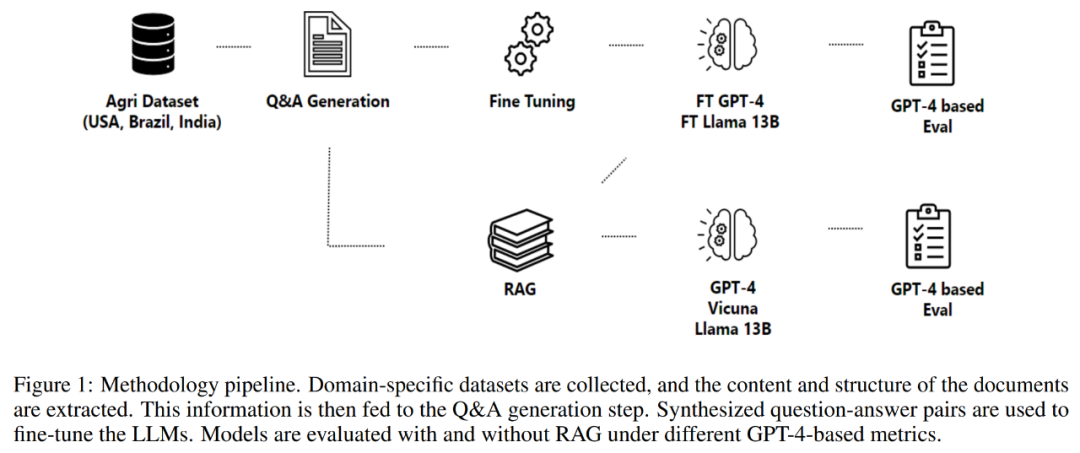
该流程以数据获取开始,这包括从各种高质量的存储库中获取数据,比如政府机构、科学知识数据库,以及必要时使用专有数据。
在完成数据获取后,流程继续从收集的文档中提取信息。这一步骤至关重要,因为它涉及解析复杂且非结构化的 PDF 文件,以恢复其中的内容和结构。下图 2 展示了数据集中一个 PDF 文件的示例。

流程的下一个组成部分是问题和答案生成。这里的目标是生成有上下文基础的高质量问题,准确反映提取文本的内容。本文方法采用了一个框架来控制输入和输出的结构组成,从而增强语言模型生成响应的整体效果。
随后,流程为制定的问题生成答案。此处采用的方法利用了检索增强生成,结合了检索和生成机制的能力,以创建高质量的答案。
最后,流程通过 Q&A 对微调模型。优化过程采用了低秩调整(LoRA)等方法,确保全面理解科学文献的内容和背景,使其成为各个领域或行业的有价值资源。
数据集
研究中评估了经过微调和检索增强生成的语言模型,使用与背景相关的问题和答案数据集,这些数据集来源于三个主要的作物生产国:美国、巴西和印度。本文的案例中,以农业作为工业背景。可用的数据在格式和内容上变化很大,涵盖了法规文件、科学报告、农学考试以及知识数据库等各种类型。
本文从美国农业部、州农业和消费者服务机构等公开可获得的在线文档、手册和报告中收集了信息。
可获得的文档包括了有关作物和牲畜管理、疾病和最佳实践的联邦法规和政策信息,质量保证和出口法规,援助计划的详细信息,以及保险和定价指南。收集的数据总计超过 23,000 个 PDF 文件,包含超过 5000 万个 tokens,涵盖了美国 44 个州。研究者下载并预处理了这些文件,提取了可以用作问答生成流程输入的文本信息。
为了对模型进行基准测试和评估,本文使用了与华盛顿州相关的文档,其中包括 573 个文件,包含超过 200 万个 tokens。如下清单 5 展示了这些文件中的内容示例。

度量标准
本节的主要目的是建立一套全面的度量标准,目的是指导对问答生成过程的质量评估,尤其是对微调和检索增强生成方法的评估。
在开发度量标准时,必须考虑几个关键因素。首先,问题质量中固有的主观性提出了重大挑战。
其次,度量标准必须考虑到问题的相关性、实用性对上下文的依赖性。
第三,需要评估生成问题的多样性和新颖性。强大的问题生成系统应该能够产生涵盖给定内容各个方面的广泛问题。然而,对多样性和新颖性进行量化可能面临着挑战,因为这涉及到评估问题的独特性以及它们与内容、其他生成问题的相似性。
最后,好的问题应该能够基于提供的内容得到回答。评估问题是否可以使用现有信息来准确回答,这需要对内容进行深刻的理解,并具备识别回答问题的相关信息的能力。
这些度量标准在确保模型提供的答案准确、相关且有效地回答问题方面发挥着不可或缺的作用。然而,在专门设计用于评估问题质量的度量标准方面存在显著的缺失。
意识到这一缺失,本文专注于开发旨在评估问题质量的度量标准。考虑到问题在推动有意义的对话和生成有用答案方面的关键作用,确保问题质量与确保答案质量同样重要。
本文开发的度量标准旨在弥补以往研究在这一领域的空缺,提供一种全面评估问题质量的手段,这将对问答生成过程的进展产生显著影响。
问题评估
本文开发的用于评估问题的度量标准如下:
相关性
全局相关性
覆盖范围
重叠度
多样性
详细程度
流畅度
答案评估
由于大语言模型倾向于生成长而详细的、富有信息的对话式回答,因此评估它们生成的答案是具有挑战性的。
本文使用了 AzureML 模型评估,采用以下度量标准来将生成的答案与实际情况进行比较:
一致性:在给定上下文的情况下,比较实际情况与预测之间的一致性。
相关性:衡量答案在上下文中如何有效地回答问题的主要方面。
真实性:定义了答案是否逻辑上符合上下文中包含的信息,并提供一个整数分数来确定答案的真实性。
模型评估
为了评估不同的微调模型,本文使用了 GPT-4 作为评估器。利用 GPT-4 从农业文档中生成了约 270 个问题和答案对,作为实际情况数据集。对于每个微调模型和检索增强生成模型,生成这些问题的答案。
本文对 LLMs 进行了多个不同度量标准的评估:
带有指南的评估:对于每个问答实际情况对,本文提示 GPT-4 生成一个评估指南,列出正确答案应包含的内容。然后,GPT-4 被提示根据评估指南中的标准,为每个答案打分,分数范围从 0 到 1。下面是一个例子:
简洁性:创建了描述简洁和冗长答案可能包含内容的评分表。基于该评分表、实际情况答案和 LLM 答案提示 GPT-4,并要求根据 1 到 5 的分数给出评分。
正确性:本文创建了一个描述完整、部分正确或不正确的答案应包含内容的评分表。基于该评分表、实际情况答案和 LLM 答案提示 GPT-4,并要求给出正确、不正确或部分正确的评分。
实验
本文的实验被划分为几个独立的实验,每个实验都侧重于问答生成和评估、检索增强生成和微调的特定方面。
这些实验探索以下领域:
问答质量
上下文研究
模型到度量的计算
组合生成与分别生成对比
检索消融研究
微调
问答质量
该实验评估了三个大语言模型,即 GPT-3、GPT-3.5 和 GPT-4,在不同上下文设置下生成的问答对的质量。质量评估基于多个指标,包括相关性、覆盖范围、重叠度和多样性。
上下文研究
该实验研究了不同上下文设置对模型生成问答对性能的影响。它在三种上下文设置下评估生成的问答对:无上下文、上下文和外部上下文。表 12 中提供了一个示例。

在无上下文设置中,GPT-4 在三个模型中具有最高的覆盖率和大小的提示,表明它可以涵盖更多的文本部分,但生成的问题更冗长。然而,三个模型在多样性、重叠度、相关性和流畅度方面的数值都相似。
当包含上下文时,与 GPT-3 相比,GPT-3.5 的覆盖率略有增加,而 GPT-4 保持了最高的覆盖率。对于 Size Prompt,GPT-4 具有最大的数值,表明其能够生成更冗长的问题和答案。
在多样性和重叠度方面,三个模型表现相似。对于相关性和流畅度,与其他模型相比,GPT-4 略有增加。
在外部上下文设置中,也有类似的情况。
此外,观察每个模型时,无上下文设置似乎在平均覆盖率、多样性、重叠度、相关性和流畅度方面为 GPT-4 提供了最佳平衡,但生成的问答对较短。上下文设置导致了较长的问答对和其他指标的轻微下降,除了大小。外部上下文设置生成的问答对最长,但保持了平均覆盖率,并在平均相关性和流畅度上略有增加。
总体而言,对于 GPT-4,无上下文设置在平均覆盖率、多样性、重叠度、相关性和流畅度方面似乎提供了最佳平衡,但生成的答案较短。上下文设置导致了更长的提示和其他指标的轻微下降。外部上下文设置生成的提示最长,但保持了平均覆盖率,并在平均相关性和流畅度上略有增加。
因此,在这三者之间的选择将取决于任务的具体要求。如果不考虑提示的长度,则由于更高的相关性和流畅度分数,外部上下文可能是最佳选择。
模型到度量的计算
该实验比较了在用于计算评估问答对质量的度量标准时,GPT-3.5 和 GPT-4 的表现。
总体上,虽然 GPT-4 通常将生成的问答对评价为更具流畅性和上下文真实性,但与 GPT-3.5 的评分相比, 它们的多样性和相关性较低。这些观点对于理解不同模型如何感知和评估生成内容的质量至关重要。
组合生成与单独生成的对比
该实验探讨了单独生成问题和答案与组合生成问题和答案之间的优劣,并侧重于在 token 使用效率方面的比较。
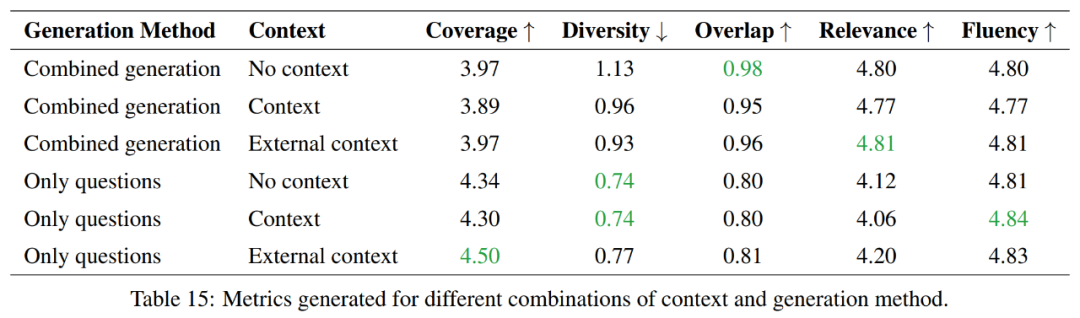
总的来说,仅生成问题的方法提供更好的覆盖范围和较低的多样性,而组合生成方法在重叠度和相关性方面得分更高。在流畅度方面,两种方法表现相似。因此在这两种方法之间的选择将取决于任务的具体要求。
如果目标是覆盖更多信息并保持更多的多样性,那么只生成问题的方法会更受青睐。然而,如果要与源材料保持较高的重叠度,那么组合生成方法将是更好的选择。
检索消融研究
这个实验评估了检索增强生成的检索能力,这是一种通过在问题回答过程中提供额外上下文来增强 LLMs 固有知识的方法。
本文研究了检索的片段数量 (即 top-k) 对结果的影响,并在表 16 中呈现了结果。通过考虑更多的片段,检索增强生成能够更一致地恢复原始摘录。
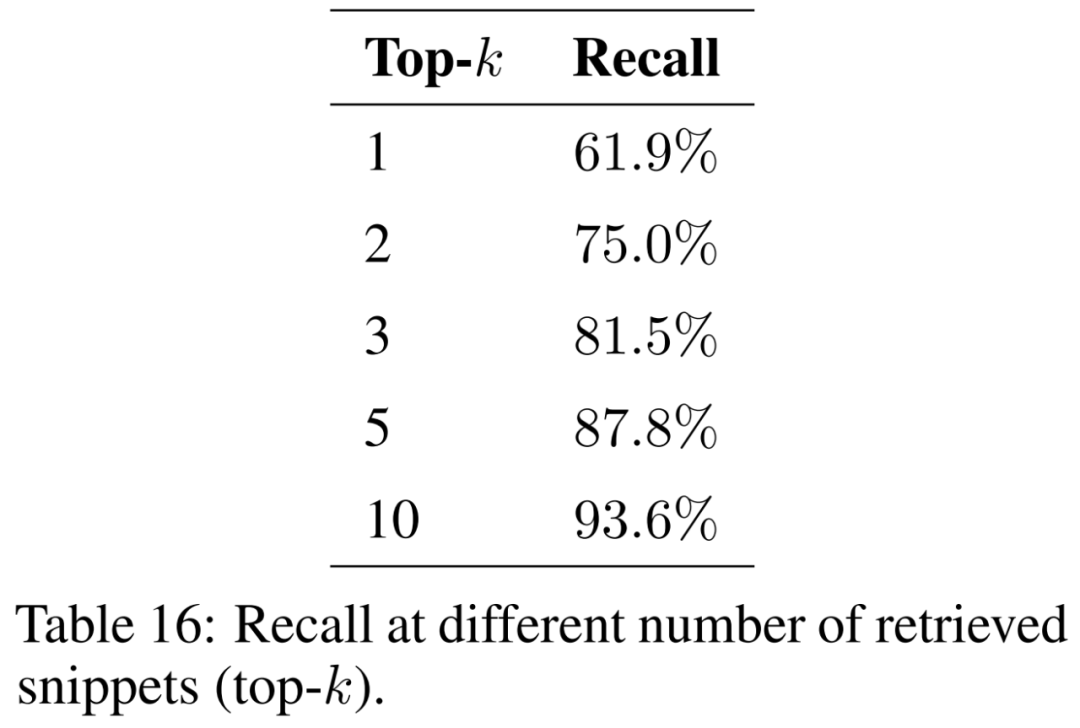
为确保模型能够处理来自各种地理背景和现象的问题,需要扩展支持文档的语料库,以涵盖各种主题。随着考虑更多文档,预计索引的大小将增加。这可能会在检索过程中增加相似片段之间的碰撞数量,从而阻碍恢复输入问题的相关信息的能力,降低召回率。
微调
该实验评估了微调模型与基础指令微调模型的性能差异。目的在于了解微调对帮助模型学习新知识的潜力。
对于基础模型,本文评估了开源模型 Llama2-13B-chat 和 Vicuna-13B-v1.5-16k。这两个模型相对较小,代表了计算与性能之间的有趣权衡。这两个模型都是 Llama2-13B 的微调版本,使用了不同的方法。
Llama2-13B-chat 通过监督微调和强化学习进行了指令微调。Vicuna-13B-v1.5-16k 是通过在 ShareGPT 数据集上进行监督微调的指令微调版本。此外,本文还评估了基础的 GPT-4,作为一个更大、更昂贵和更强大的替代方案。
对于微调模型,本文直接在农业数据上对 Llama2-13B 进行微调,以便将其性能与为更通用任务进行微调的类似模型进行比较。本文还对 GPT-4 进行微调,以评估微调在非常大的模型上是否仍然有帮助。带有指南的评估结果见表 18。
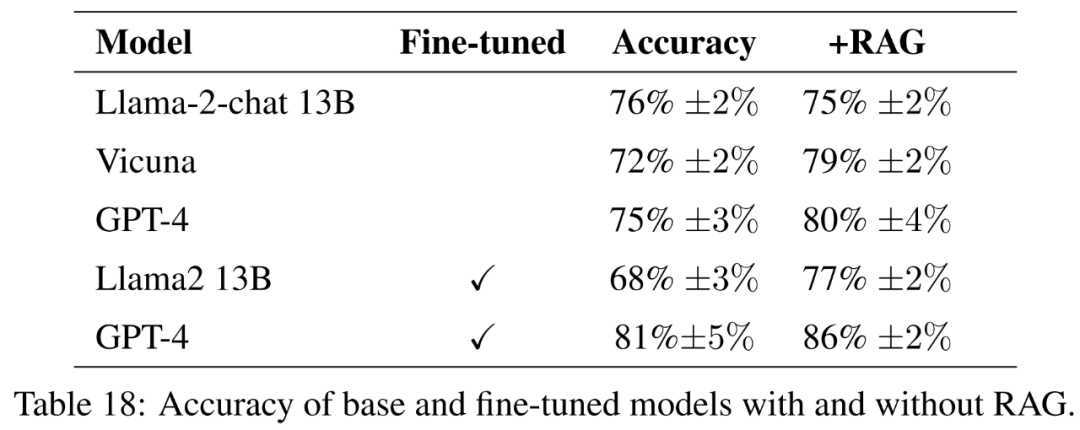
为全面衡量回答的质量,除了准确性外,本文还评估了回答的简洁性。
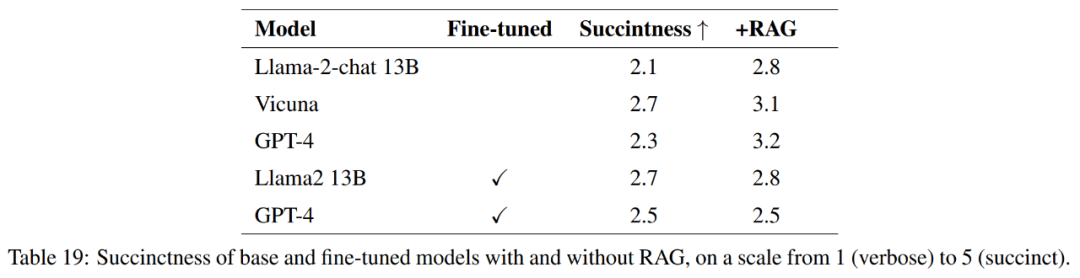
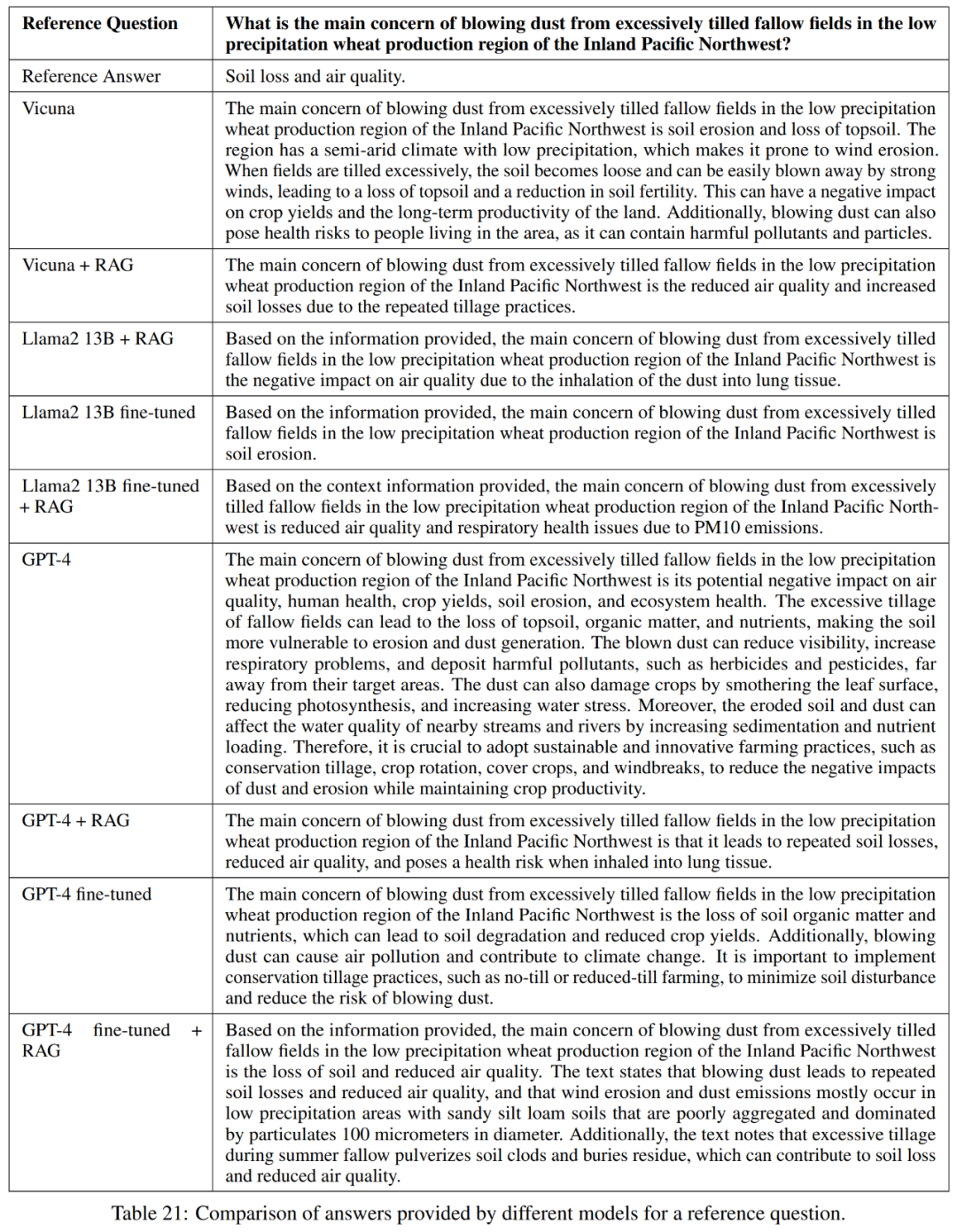
表 21 中显示,这些模型并不始终对问题提供完整的回答。例如,有些回答指出土壤流失是一个问题,但并没有提到空气质量。
总的来说,就准确而简洁地回答参考答案而言,性能最好的模型是 Vicuna + 检索增强生成、GPT-4 + 检索增强生成、GPT-4 微调和 GPT-4 微调 + 检索增强生成。这些模型提供了精确性、简洁性和信息深度的平衡混合。
知识发现
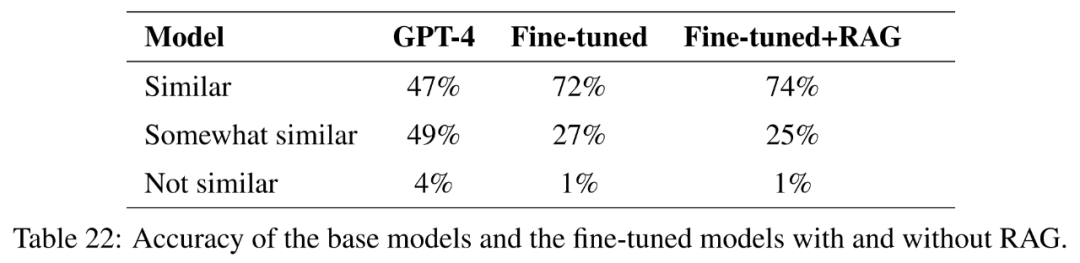
本文的研究目标是探索微调对帮助 GPT-4 学习新知识的潜力,这对应用研究至关重要。
为了测试这一点,本文选择了在美国的 50 个州中至少有三个州相似的问题。然后计算了嵌入的余弦相似度,并确定了 1000 个这样的问题列表。这些问题从训练集中删除,使用微调和带有检索增强生成的微调来评估 GPT-4 是否能够根据不同州之间的相似性学习新知识。
更多实验结果请参阅原论文。
以上是RAG还是微调?微软出了一份特定领域大模型应用建设流程指南的详细内容。更多信息请关注PHP中文网其他相关文章!





















