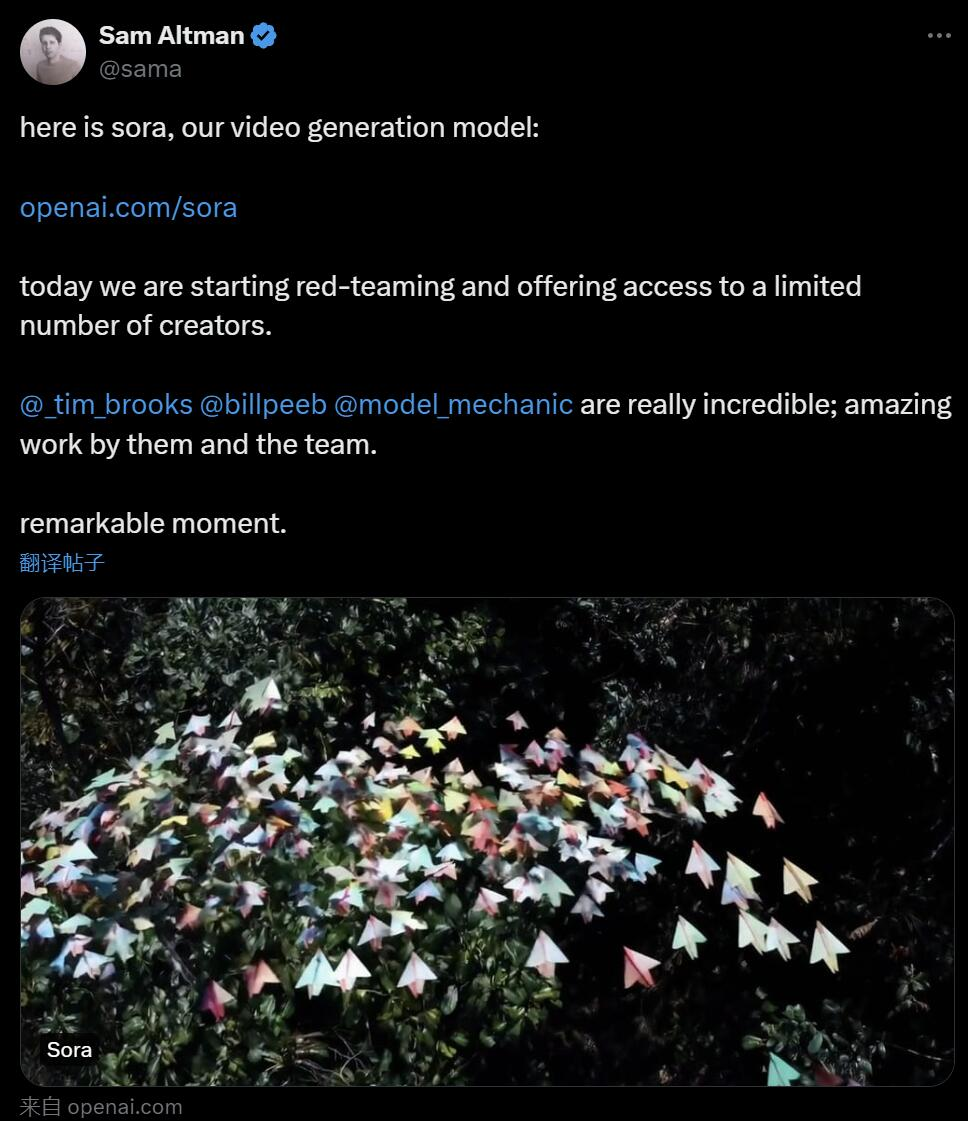
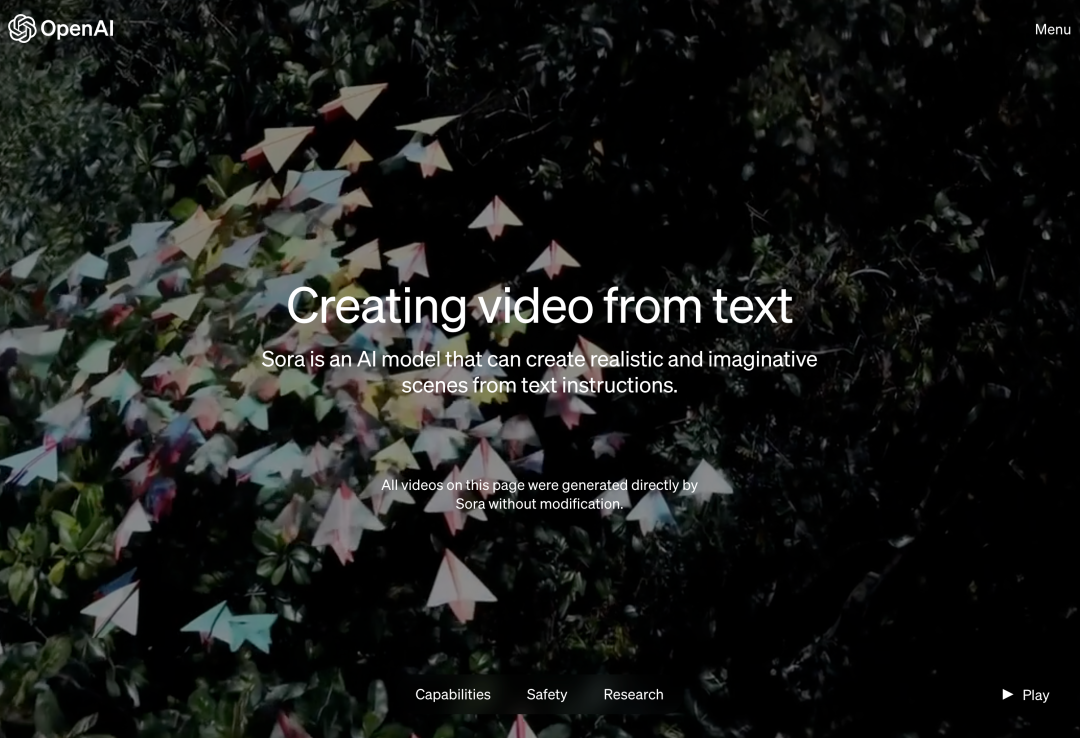
北京时间今天凌晨,OpenAI 正式发布了文本到视频生成模型 Sora,继 Runway、Pika、谷歌和 Meta 之后,OpenAI 终于加入视频生成领域的战争。山姆・奥特曼的消息放出后,看到 OpenAI 工程师第一时间展示的 AI 生成视频效果,人们纷纷表示感叹:好莱坞的时代结束了?OpenAI 声称,如果给定一段简短或详细的描述或一张静态图片,Sora 就能生成类似电影的 1080p 场景,其中包含多个角色、不同类型的动作和背景细节。Sora 有哪些特别之处呢?它对语言有着深刻的理解,能够准确地解释 prompt 并生成吸引人的字符来表达充满活力的情感。同时,Sora 不仅能够了解用户在 prompt 中提出的要求,还能 get 到在物理世界中的存在方式。在官方博客中,OpenAI 提供了很多 Sora 生成的视频示例,展示了令人印象深刻的效果,至少与此前出现过的文本生成视频技术相比是这样。对于初学者来说,Sora 可以生成各种风格的视频(例如,真实感、动画、黑白),最长可达一分钟 —— 比大多数文本到视频模型要长得多。这些视频保持了合理的连贯性,它们并不总是屈服于所说的「人工智能怪异」,比如物体朝物理上不可能的方向移动。
比如输入 prompt:加州淘金热时期的历史镜头。
输入 prompt:玻璃球的特写视图,里面有一个禅宗花园。球体中有一个小矮人正在沙子上创造图案。
输入 prompt:一位 24 岁女性眨眼的极端特写,在魔法时刻站在马拉喀什,70 毫米拍摄的电影,景深,鲜艳的色彩,电影。
输入 prompt:穿过东京郊区的火车窗外的倒影。
输入 promot:赛博朋克背景下机器人的生活故事。
但 OpenAI 承认,当前的模型也有弱点。它可能难以准确模拟复杂场景中的物理现象,也可能无法理解具体的因果关系。该模型还可能混淆提示的空间细节,例如混淆左和右,并可能难以精确描述随时间发生的事件,如跟随特定的摄像机轨迹。比如他们发现,在生成的过程中动物和人会自发出现,尤其是在包含许多实体的场景中。在下面这个例子中,Prompt 本来是「五只灰狼幼崽在草丛环绕的偏僻碎石路上嬉戏追逐。幼狼们奔跑着、跳跃着,互相追逐着、咬着,嬉戏着。」但所生成的这种「复制粘贴」的画面很容易让人想起某些神异鬼怪传说:
还有下面这个例子,吹蜡烛之前和吹蜡烛之后,火苗没有丝毫变化,透露出一种诡异:
对 Sora 背后的模型细节,我们知之甚少。据 OpenAI 博客,更多的信息将在后续的技术论文中公布。博客中透露了一些基础信息:Sora 是一种扩散模型,它生成的视频一开始看起来像静态噪音,然后通过多个步骤去除噪音,逐步转换视频。Midjourney 和 Stable Diffusion 的图像和视频生成器同样基于扩散模型。但我们可以看出,OpenAI Sora 生成视频的质量好得多。Sora 感觉像是创建了真实的视频,而以往这些竞争对手的模型则感觉像是 AI 生成图像的定格动画。Sora 可以一次性生成整个视频,也可以扩展生成的视频,使其更长。通过让模型一次预见多帧画面,OpenAI 解决了一个具有挑战性的问题,即确保被摄体即使暂时离开视线也能保持不变。与 GPT 模型类似,Sora 也使用了 transformer 架构,从而实现了卓越的扩展性能。OpenAI 将视频和图像表示为称为 patch 的较小数据单元的集合,每个 patch 类似于 GPT 中的 token。通过统一数据表示方式,OpenAI 能够在比以往更广泛的视觉数据上训练扩散 transformer,包括不同的持续时间、分辨率和宽高比。Sora 建立在过去 DALL・E 和 GPT 模型的研究基础之上。它采用了 DALL・E 3 中的重述技术,即为视觉训练数据生成高度描述性的字幕。因此,该模型能够在生成的视频中更忠实地遵循用户的文字提示。除了能够仅根据文字说明生成视频外,该模型还能根据现有的静态图像生成视频,并准确、细致地对图像内容进行动画处理。该模型还能提取现有视频,并对其进行扩展或填充缺失的帧。参考链接:https://openai.com/sora以上是春节大礼包!OpenAI首个视频生成模型发布,60秒高清大作,网友已叹服的详细内容。更多信息请关注PHP中文网其他相关文章!