

拍张照片,输入文字指令,手机就开始自动修图?
这一神奇功能,来自苹果刚刚开源的图片编辑神器「MGIE」。

把背景中的人移除
在桌子上添加披萨
最近,AI在图片编辑方面取得了显着的进展。一方面,通过多模态大模型(MLLM),AI能够将图像作为输入,并提供视觉感知响应,从而实现更自然的图片编辑。另一方面,基于指令的编辑技术使得编辑过程不再依赖于详细描述或区域掩码,而是允许用户直接下达指令,以表达编辑的方式和目标。这种方法非常实用,因为它更符合人类的直觉方式。通过这些创新技术,AI在图片编辑领域正逐渐成为人们的得力助手。
基于上述技术的启发,苹果提出了 MGIE(MLLM-Guided Image Editing),将 MLLM 用于解决指令引导不足的问题。

MGIE(Mind-Guided Image Editing)由MLLM(Mind-Language Linking Model)和扩散模型组成,如图2所示。 MLLM通过学习获得简明的表达指令,并提供明确的视觉相关引导。扩散模型利用预期目标的潜在想象力执行图像编辑,并通过端到端训练同步更新。这样,MGIE能够从固有的视觉推导中获益,并解决模糊的人类指令,从而实现合理的编辑。
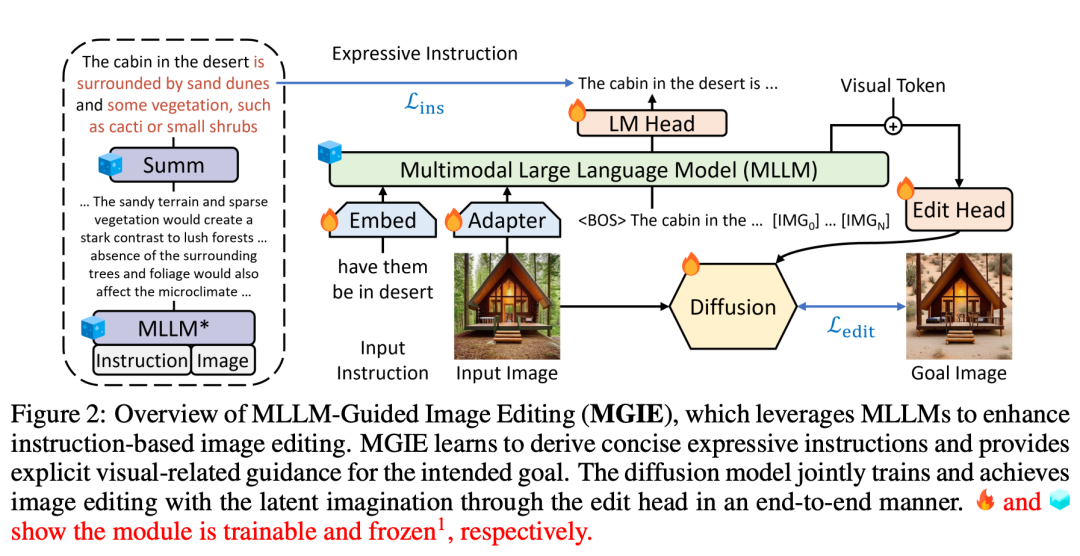
在人类指令的引导下,MGIE 可进行 Photoshop 风格的修改、全局照片优化和局部对象修改。以下图为例,在没有额外语境的情况下,很难捕捉到「健康」的含义,但 MGIE 可以将「蔬菜配料」与披萨精确地联系起来,并按照人类的期望进行相关编辑。

这让我们想起,库克前不久在财报电话会议上表达的「雄心壮志」:「我认为苹果在生成式AI 方面存在着巨大的机会,但我不想谈更多细节。」他透露的信息包括,苹果正在积极开发生成式AI 软件功能,且这些功能在2024 年晚些时候就能向客户提供。
结合苹果在近段时间发布的一系列生成式 AI 理论研究成果,看来我们期待一下苹果接下来要发布的新 AI 功能了。
该研究提出的 MGIE 方法能够通过给定的指令 X 将输入图片 V 编辑为目标图片  。对于那些不精确的指令,MGIE 中的 MLLM 会进行学习推导,从而得到简洁的表达指令 ε。为了在语言和视觉模态之间架起桥梁,研究者还在 ε 之后添加了特殊的 token [IMG],并采用编辑头(edit head)
。对于那些不精确的指令,MGIE 中的 MLLM 会进行学习推导,从而得到简洁的表达指令 ε。为了在语言和视觉模态之间架起桥梁,研究者还在 ε 之后添加了特殊的 token [IMG],并采用编辑头(edit head)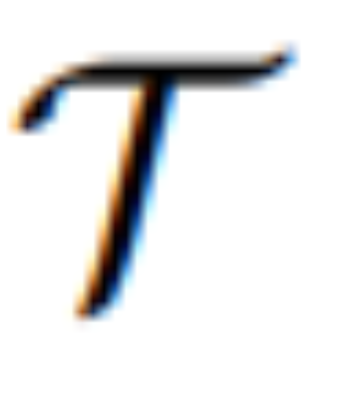 对它们进行转换。转换后的信息将作为 MLLM 中的潜在视觉想象,引导扩散模型
对它们进行转换。转换后的信息将作为 MLLM 中的潜在视觉想象,引导扩散模型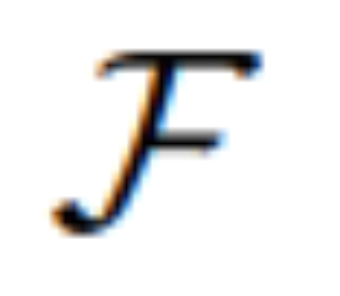 实现预期的编辑目标。然后,MGIE 能够理解具有视觉感知的模糊命令,从而进行合理的图像编辑(架构图如上图 2 所示)。
实现预期的编辑目标。然后,MGIE 能够理解具有视觉感知的模糊命令,从而进行合理的图像编辑(架构图如上图 2 所示)。
简洁的表达指令
通过特征对齐和指令调整,MLLM 能够跨模态感知提供与视觉相关的响应。对于图像编辑,该研究使用提示「what will this image be like if [instruction]」作为图像的语言输入,并导出编辑命令的详细解释。然而,这些解释往往过于冗长、甚至误导了用户意图。为了获得更简洁的描述,该研究应用预训练摘要器让 MLLM 学习生成摘要输出。这一过程可以总结为如下方式:
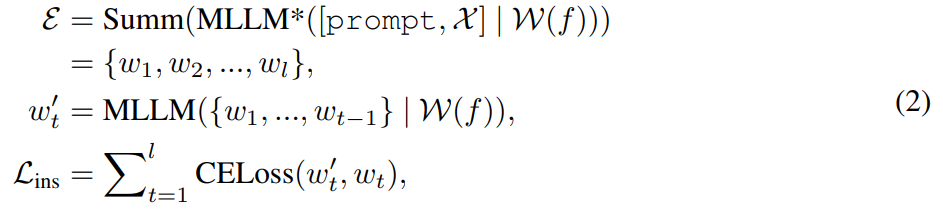
通过潜在想象进行图片编辑
该研究采用编辑头 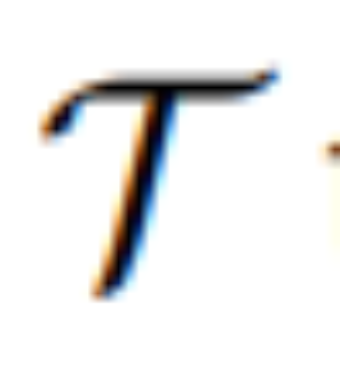 将 [IMG] 转化为实际的视觉引导。其中
将 [IMG] 转化为实际的视觉引导。其中 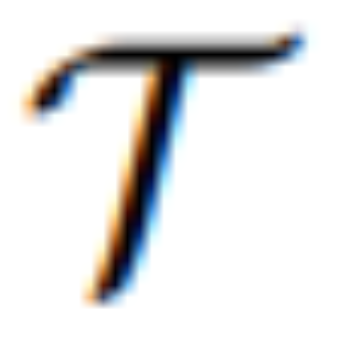 是一个序列到序列模型,它将来自 MLLM 的连续视觉 tokens 映射到语义上有意义的潜在 U = {u_1, u_2, ..., u_L} 并作为编辑引导:
是一个序列到序列模型,它将来自 MLLM 的连续视觉 tokens 映射到语义上有意义的潜在 U = {u_1, u_2, ..., u_L} 并作为编辑引导:
为了实现通过视觉想象 U 引导图像编辑这一过程,该研究考虑使用扩散模型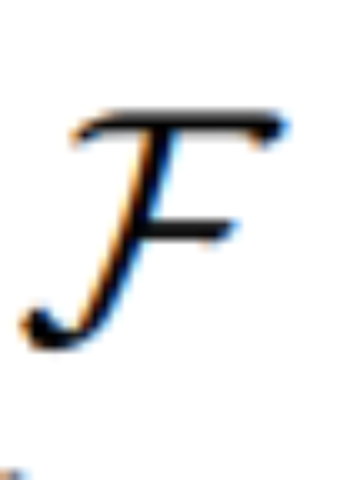 ,该模型在包含变分自动编码器(VAE)的同时,还能解决潜在空间中的去噪扩散问题。
,该模型在包含变分自动编码器(VAE)的同时,还能解决潜在空间中的去噪扩散问题。
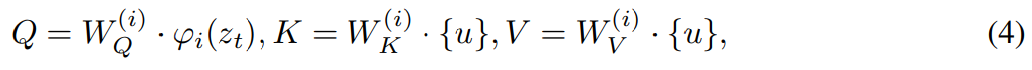
算法 1 展示了 MGIE 学习过程。MLLM 通过指令损失 L_ins 导出简洁指令 ε。借助 [IMG] 的潜在想象,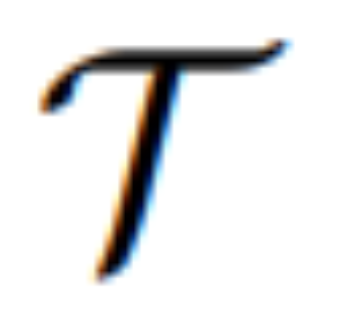 转变其模态并引导
转变其模态并引导 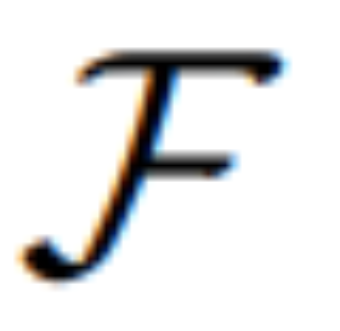 合成结果图像。编辑损失 L_edit 用于扩散训练。由于大多数权重可以被冻结(MLLM 内的自注意力块),因而可以实现参数高效的端到端训练。
合成结果图像。编辑损失 L_edit 用于扩散训练。由于大多数权重可以被冻结(MLLM 内的自注意力块),因而可以实现参数高效的端到端训练。

对于输入图片,在相同的指令下,不同方法之间的比较,如第一行的指令是「把白天变成黑夜」:
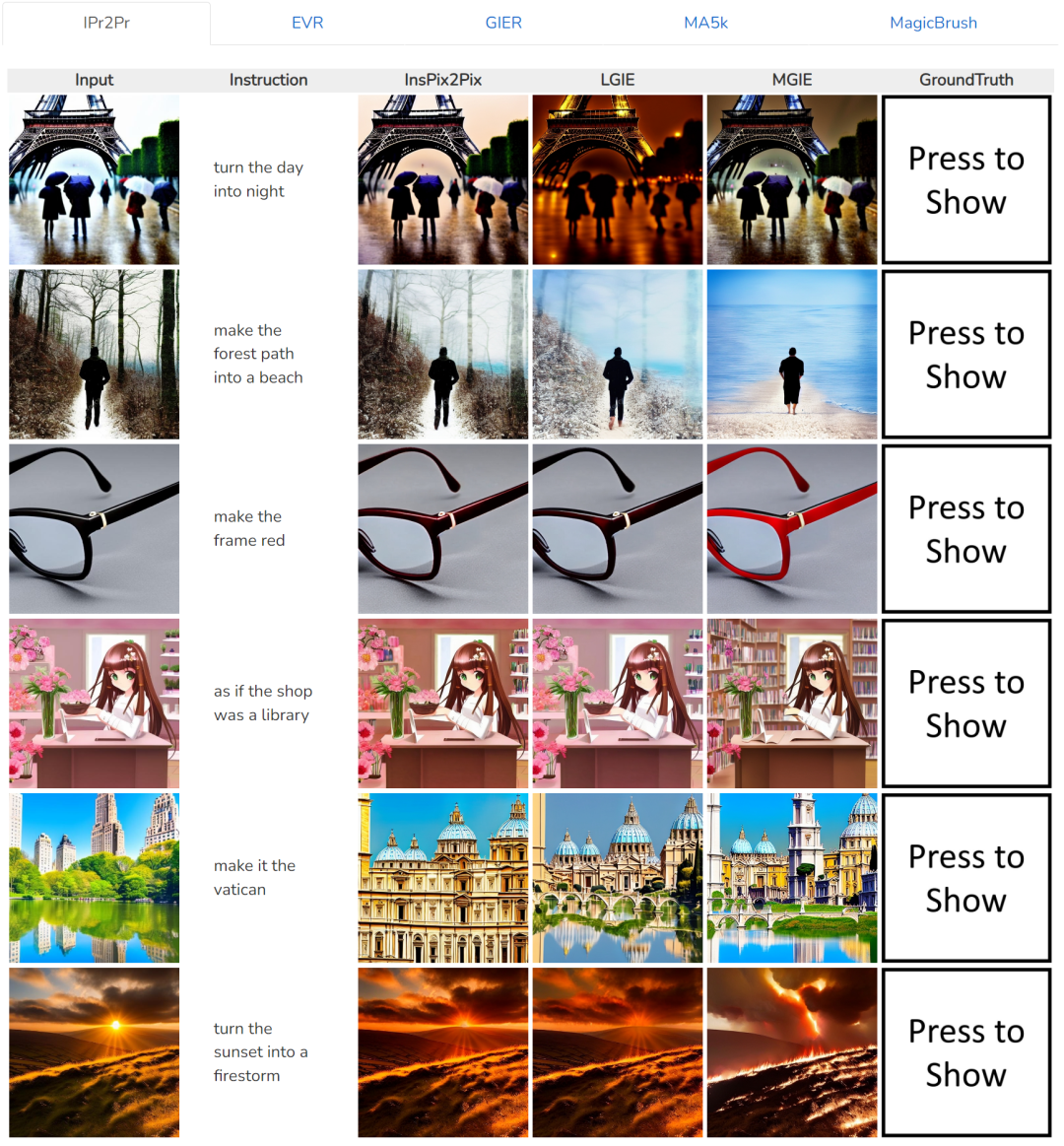
表 1 显示了模型仅在数据集 IPr2Pr 上训练的零样本编辑结果。对于涉及 Photoshop 风格修改的 EVR 和 GIER,编辑结果更接近引导意图(例如,LGIE 在 EVR 上获得了更高的 82.0 CVS)。对于 MA5k 上的全局图片优化,由于相关训练三元组的稀缺,InsPix2Pix 很难处理。 LGIE 和 MGIE 可以通过 LLM 的学习提供详细的解释,但 LGIE 仍然局限于其单一的模态。通过访问图像,MGIE 可以得出明确的指令,例如哪些区域应该变亮或哪些对象更加清晰,从而带来显着的性能提升(例如,更高的66.3 SSIM 和更低的0.3 拍照距离),在MagicBrush上也发现了类似的结果。 MGIE 还从精确的视觉想象中获得最佳性能,并修改指定目标作为目标(例如,更高的 82.2 DINO 视觉相似度和更高的 30.4 CTS 全局字幕对齐)。
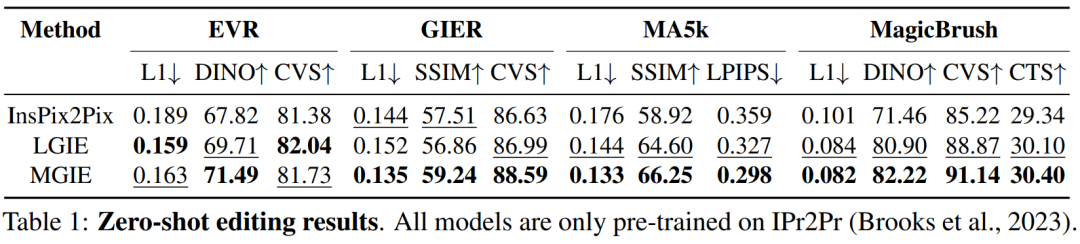
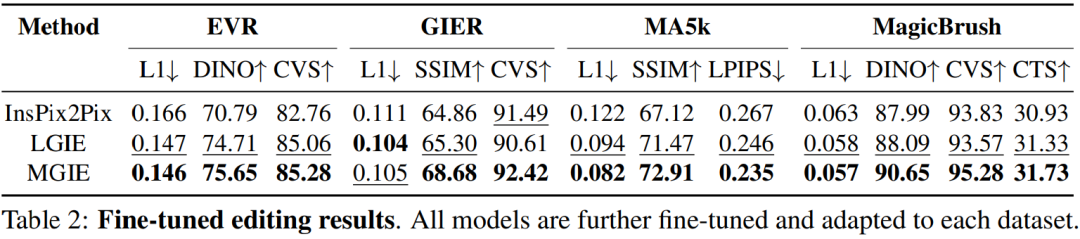
为了研究针对特定目的的基于指令的图像编辑,表 2 对每个数据集上的模型进行了微调。对于 EVR 和 GIER,所有模型在适应 Photoshop 风格的编辑任务后都获得了改进。 MGIE 在编辑的各个方面始终优于 LGIE。这也说明了使用表达指令进行学习可以有效地增强图像编辑,而视觉感知在获得最大增强的明确引导方面起着至关重要的作用。
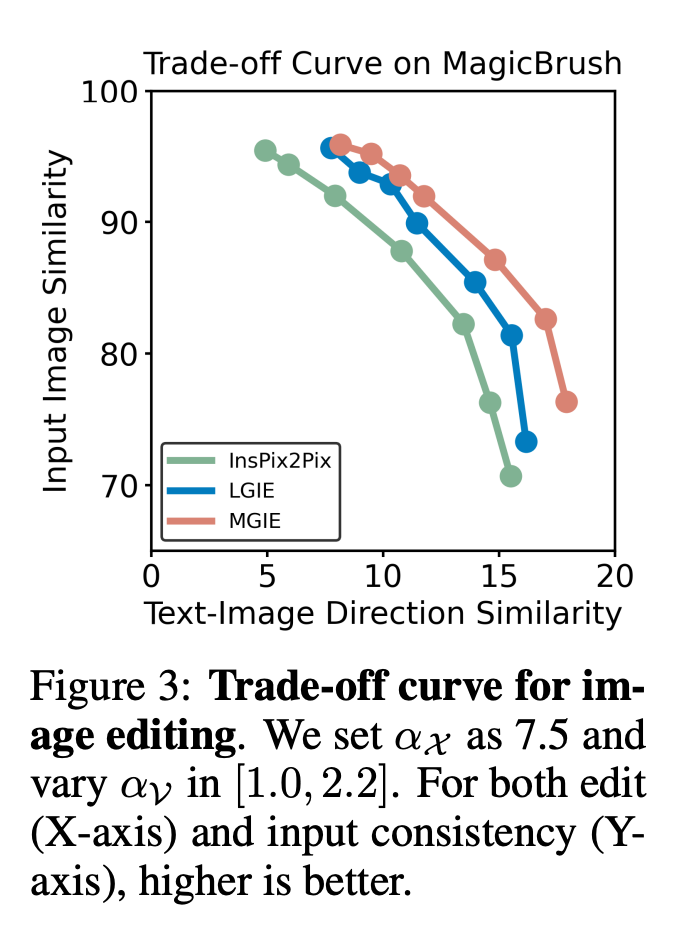
α_X 和 α_V 之间的权衡。图像编辑有两个目标:操作作为指令的目标和保留作为输入图像的剩余部分。图 3 显示了指令 (α_X) 和输入一致性 (α_V) 之间的权衡曲线。该研究将 α_X 固定为 7.5,α_V 在 [1.0, 2.2] 范围内变化。 α_V 越大,编辑结果与输入越相似,但与指令的一致性越差。 X 轴计算的是 CLIP 方向相似度,即编辑结果与指令的一致程度;Y 轴是 CLIP 视觉编码器与输入图像的特征相似度。通过具体的表达指令,实验在所有设置中都超越了 InsPix2Pix。此外, MGIE 还能通过明确的视觉相关引导进行学习,从而实现全面提升。无论是要求更高的输入相关性还是编辑相关性,这都支持稳健的改进。
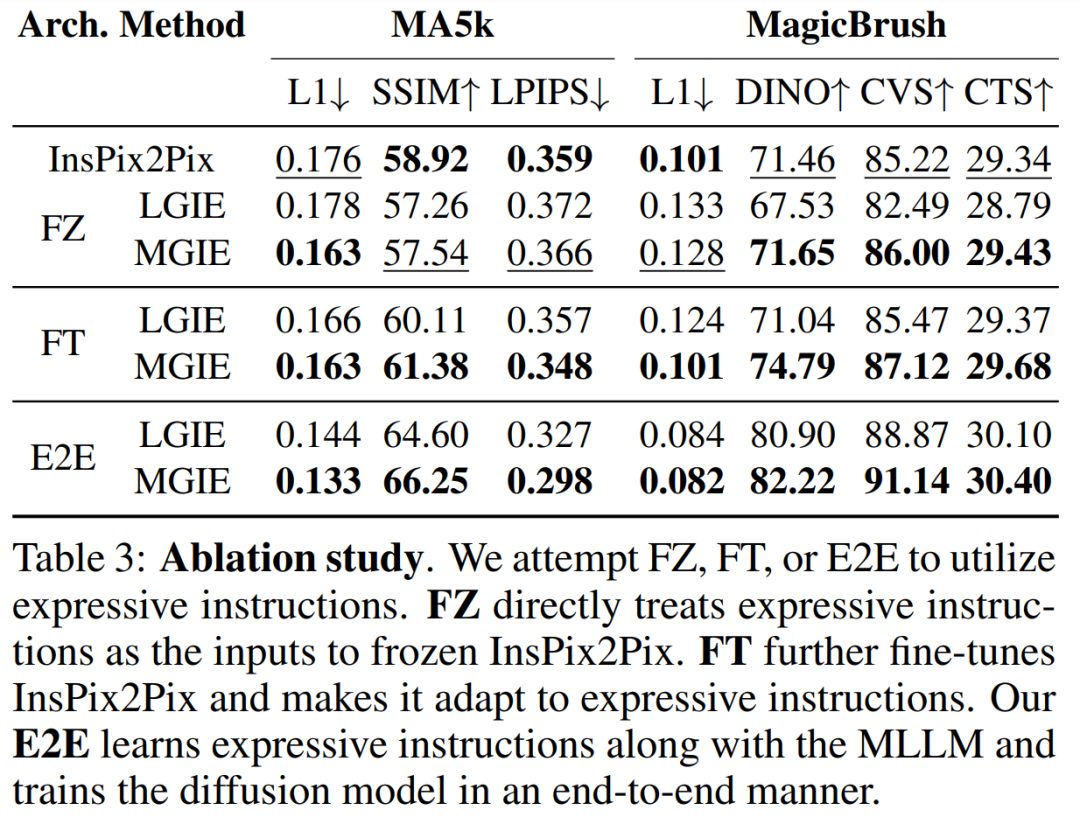
消融研究
除此以外,研究者还进行了消融实验,考虑了不同的架构 FZ、FT 以及 E2E 在表达指令上的性能 。结果表明,在 FZ、FT、E2E 中,MGIE 持续超过 LGIE。这表明具有关键视觉感知的表达指令在所有消融设置中始终具有优势。
为什么 MLLM 引导有用?图 5 显示了输入或 ground-truth 目标图像与表达式指令之间的 CLIP-Score 值。输入图像的 CLIP-S 分数越高,说明指令与编辑源相关,而更好地与目标图像保持一致可提供明确、相关的编辑引导。如图所示,MGIE 与输入 / 目标更加一致,这就解释了为什么其表达性指令很有帮助。有了对预期结果的清晰叙述,MGIE 可以在图像编辑方面取得最大的改进。

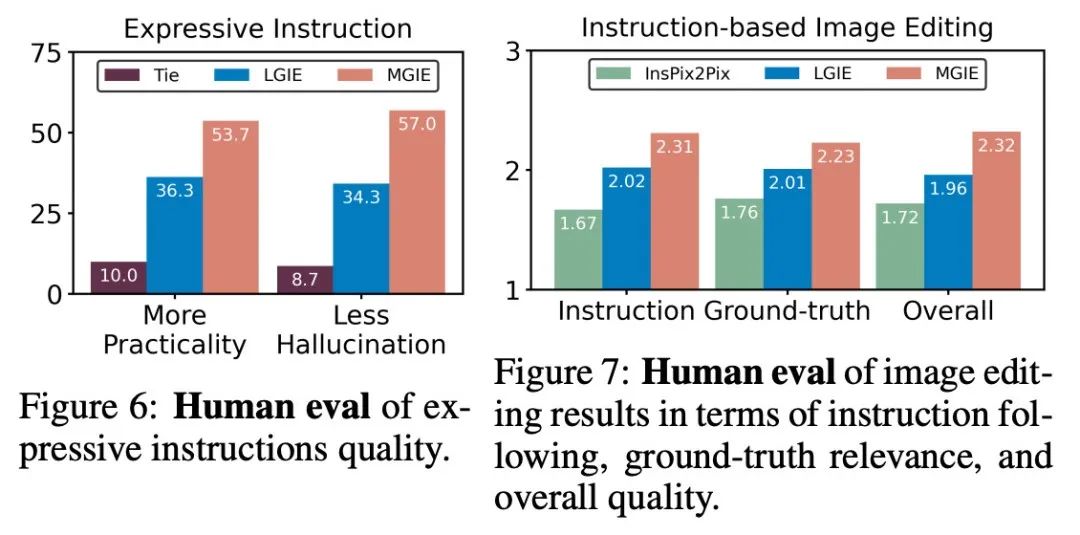
人工评估。除了自动指标外,研究者还进行了人工评估。图 6 显示了生成的表达指令的质量,图 7 对比了 InsPix2Pix、LGIE 和 MGIE 在指令遵循、ground-truth 相关性和整体质量方面的图像编辑结果。
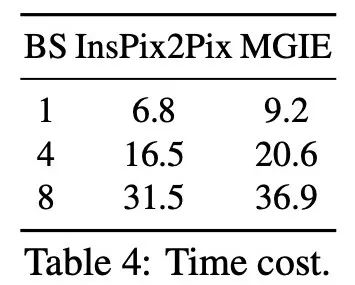
推理效率。尽管 MGIE 依靠 MLLM 来推动图像编辑,但它只推出了简明的表达式指令(少于 32 个 token),因此效率与 InsPix2Pix 不相上下。表 4 列出了在英伟达 A100 GPU 上的推理时间成本。对于单个输入,MGIE 可以在 10 秒内完成编辑任务。在数据并行化程度更高的情况下,所需的时间也差不多(当批大小为 8 时,需要 37 秒)。整个过程只需一个 GPU(40GB)即可完成。
定性比较。图 8 展示了所有使用数据集的可视化对比,图 9 进一步对比了 LGIE 或 MGIE 的表达指令。


在项目主页中,研究者还提供了更多 demo(https://mllm-ie.github.io/)。更多研究细节,可参考原论文。
以上是罕见!苹果开源图片编辑神器MGIE,要上iPhone?的详细内容。更多信息请关注PHP中文网其他相关文章!





















