

在定义语言模型时,常常使用基本的分词方法,将句子分为词、子词或字符。子词分词法一直以来都是最流行的选择,因为它在训练效率和处理词汇表外单词的能力之间取得了平衡。然而,一些研究指出了子词分词法的问题,例如对于错别字、拼写和大小写变化以及形态变化的处理缺乏稳健性。因此,在语言模型的设计中需要仔细考虑这些问题,以提高模型的准确性和鲁棒性。
因此,一些研究人员选择了一种使用字节序列的方法,即通过原始数据到预测结果的端到端映射,而不进行任何分词。与子词模型相比,基于字节级的语言模型更容易泛化到不同的写作形式和形态变化。然而,将文本建模为字节意味着生成的序列要比对应的子词更长。为了提高效率,需要通过改进架构来实现。
自回归Transformer在语言建模中占据主导地位,但是其效率问题尤为突出。它的计算成本随着序列长度的增加呈二次方增长,导致其对于长序列的扩展能力较差。为了解决这个问题,研究人员对Transformer的内部表示进行了压缩,以便处理长序列。其中一种方法是开发了长度感知建模方法,该方法在中间层内合并token组,从而减少了计算成本。最近,Yu等人提出了一种名为MegaByte Transformer的方法。它使用固定大小的字节片段来模拟压缩形式作为子词,从而降低了计算成本。然而,目前这可能还不是最佳的解决方案,还有待进一步的研究和改进。
在一项最新的研究中,康奈尔大学的学者们介绍了一种名为MambaByte的高效且简单的字节级语言模型。该模型是通过对最近推出的Mamba架构进行直接改进而得到的。Mamba架构是建立在状态空间模型(SSM)方法的基础上的,而MambaByte则引入了更有效的选择机制,使其在处理文本等离散数据时表现更加出色,并且还提供了高效的GPU实现。研究人员对使用未经修改的Mamba进行了简单观察,发现它能够缓解语言建模中的主要计算瓶颈,从而消除了修补补丁(patch)的需求,并能够充分利用可用的计算资源。

在实验中,他们对MambaByte与Transformers、SSM和MegaByte(patching)架构进行了比较。这些架构在固定参数和计算设置下,并在多个长篇文本数据集上进行了评估。图1总结了他们的主要发现。
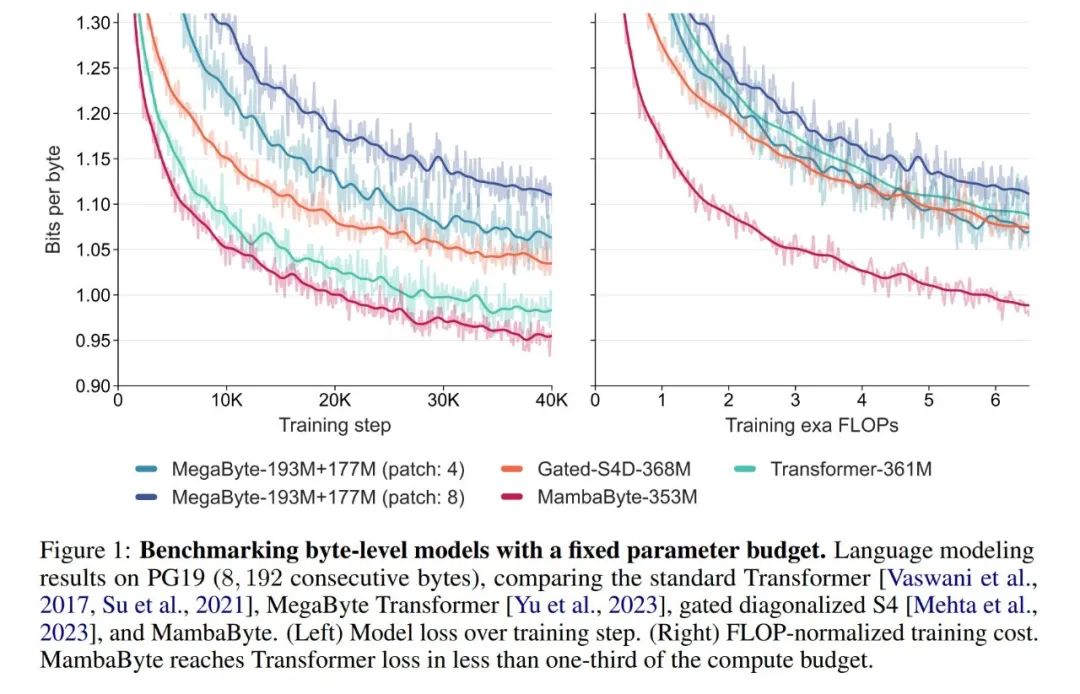
与字节级 Transformers 相比,MambaByte 提供了更快速且高性能的解决方案,同时计算效率也得到了明显的提升。研究人员还对无 token 语言模型与当前最先进的子词模型进行了比较,并发现 MambaByte 在这方面具有竞争力,而且能够处理更长的序列。这项研究结果表明,MambaByte 可以成为现有依赖分词器的有力替代品,有望推动端到端学习的进一步发展。
SSM使用一阶微分方程对隐藏状态的时间演变进行建模。线性时不变的SSM在多种深度学习任务中表现出良好的效果。然而,最近Mamba的作者Gu和Dao认为这些方法的恒定动态缺乏隐藏状态中依赖输入的上下文选择,而这对于语言建模等任务可能是必需的。因此,他们提出了Mamba方法,该方法通过将给定输入x(t) ∈ R、隐藏状态h(t) ∈ R^n和输出y(t) ∈ R在时间t的时变连续状态动态定义为:
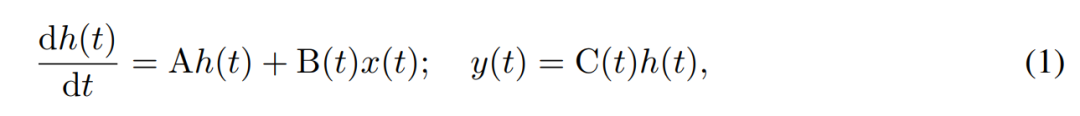
其参数为对角时不变系统矩阵 A∈R^(n×n),以及随时间变化的输入和输出矩阵 B (t)∈R^(n×1) 和 C (t)∈R^(1×n)。
要对字节等离散时间序列建模,必须通过离散化来逼近 (1) 中的连续时间动态。这就产生了离散时间隐态 recurrence,每个时间步都有新矩阵 A、B 和 C,即
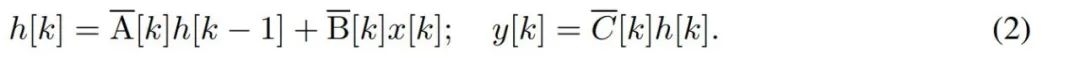
请注意,(2) 类似于循环神经网络的线性版本,可以在语言模型生成过程中以这种循环形式应用。离散化要求每个输入位置都有一个时间步,即 ∆[k],对应于 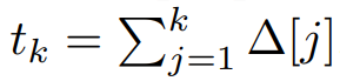 的 x [k] = x (t_k)。然后就可以根据 ∆[k] 计算出离散时间矩阵 A、B 和 C。图 2 展示了 Mamba 如何为离散序列建模。
的 x [k] = x (t_k)。然后就可以根据 ∆[k] 计算出离散时间矩阵 A、B 和 C。图 2 展示了 Mamba 如何为离散序列建模。
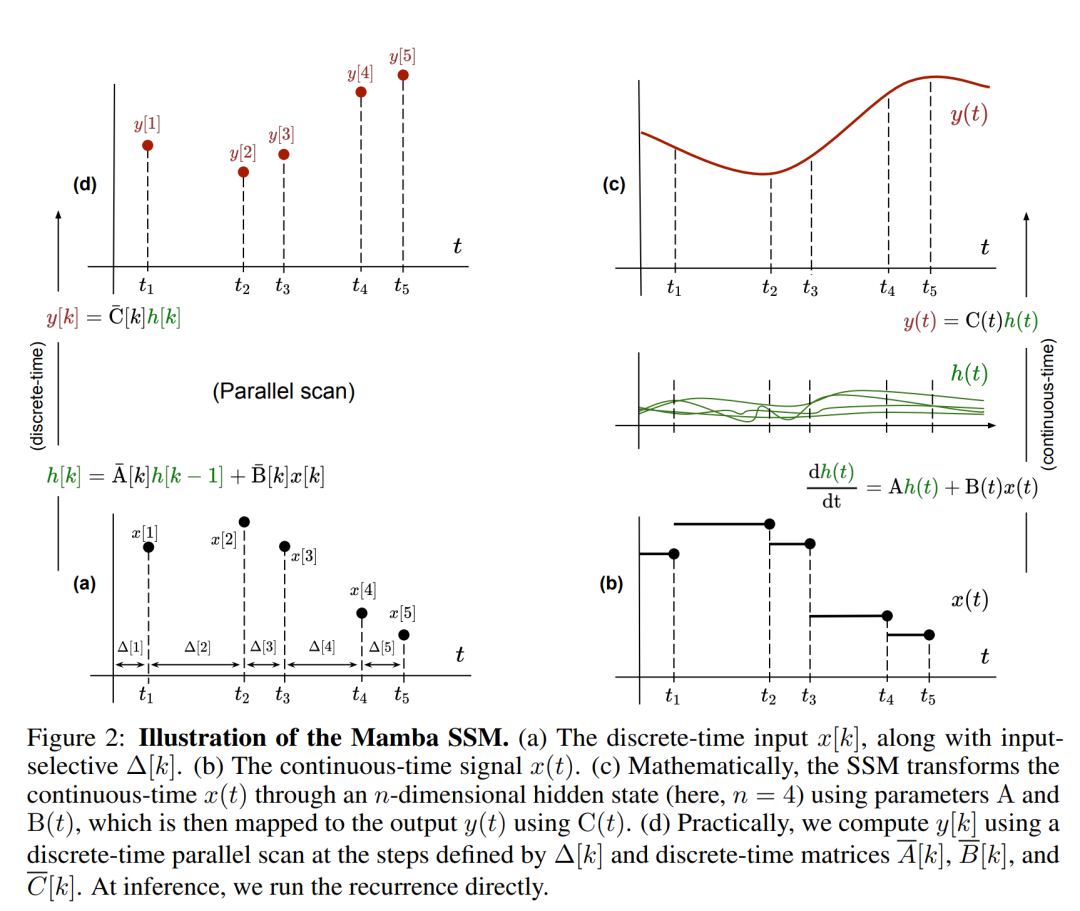
在 Mamba 中,SSM 项是输入选择性的,即 B、C 和 ∆ 被定义为输入 x [k]∈R^d 的函数:
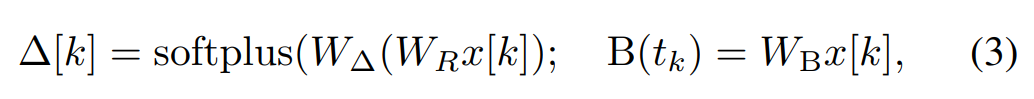
其中 W_B ∈ R^(n×d)(C 的定义类似),W_∆ ∈ R^(d×r) 和 W_R ∈ R^(r×d)(对于某个 r ≪d)是可学习的权重,而 softplus 则确保正向性。请注意,对于每个输入维度 d,SSM 参数 A、B 和 C 都是相同的,但时间步数 ∆ 是不同的;这导致每个时间步数 k 的隐藏状态大小为 n × d。
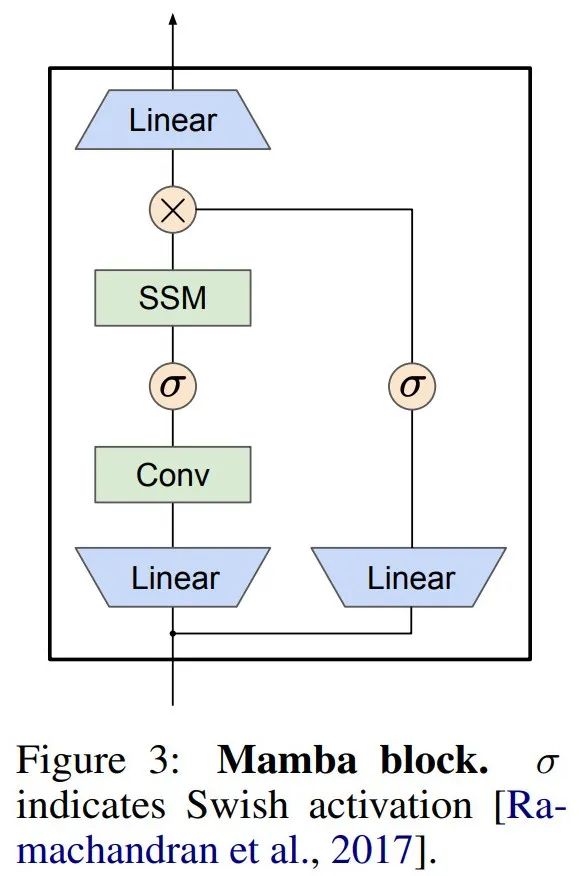
Mamba 将这个 SSM 层嵌入到一个完整的神经网络语言模型中。具体来说,该模型采用了一系列门控层,其灵感来源于之前的门控 SSM。图 3 显示了将 SSM 层与门控神经网络相结合的 Mamba 架构。
线性 recurrence 的并行扫描。在训练时,作者可以访问整个序列 x,从而更高效地计算线性 recurrence。Smith et al. [2023] 的研究证明,使用工作效率高的并行扫描可以高效计算线性 SSM 中的顺序 recurrence。对于 Mamba,作者首先将 recurrence 映射到 L 个元组序列,其中 e_k = ,然后定义一个关联算子
,然后定义一个关联算子  使得
使得 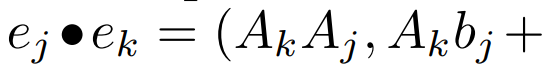
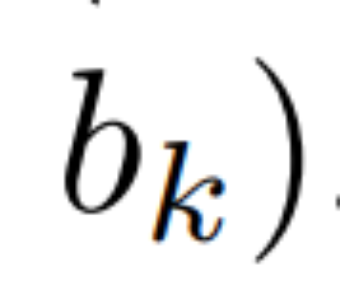 。最后,他们应用并行扫描计算序列
。最后,他们应用并行扫描计算序列 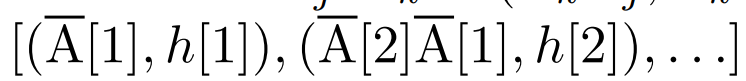 。一般来说,这需要
。一般来说,这需要 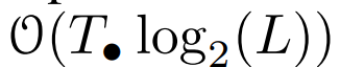 时间,使用 L/2 个处理器,其中
时间,使用 L/2 个处理器,其中 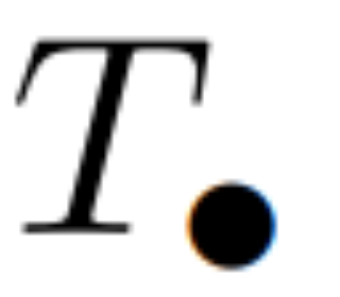 是矩阵乘法的成本。注意,A 是一个对角矩阵,线性 recurrence 可在
是矩阵乘法的成本。注意,A 是一个对角矩阵,线性 recurrence 可在 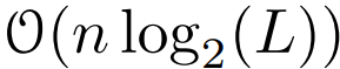 时间和 O (nL) 空间内并行计算。使用对角矩阵进行并行扫描的运行效率也很高,只需 O (nL) FLOPs。
时间和 O (nL) 空间内并行计算。使用对角矩阵进行并行扫描的运行效率也很高,只需 O (nL) FLOPs。
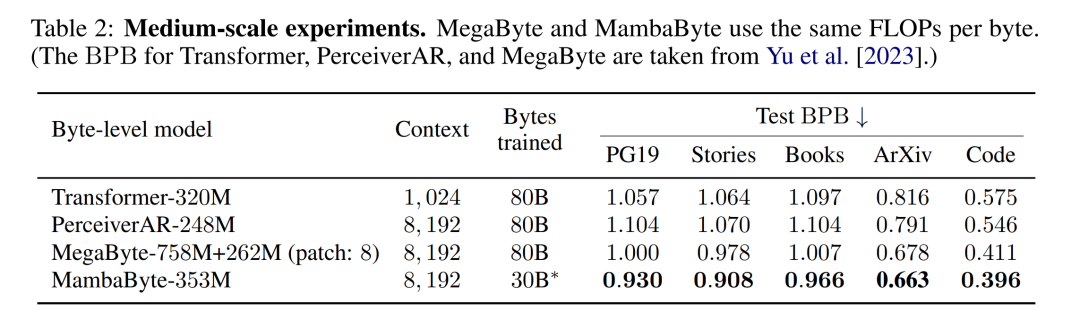
表 2 显示了每个数据集的每字节比特数(BPB)。在本实验中,MegaByte758M+262M 和 MambaByte 模型使用相同的每字节 FLOP 数(见表 1)。作者发现,在所有数据集上,MambaByte 的性能始终优于 MegaByte。此外,作者注意到,由于资金限制,他们无法对 MambaByte 进行完整的 80B 字节训练,但 MambaByte 在计算量和训练数据减少 63% 的情况下仍优于 MegaByte。此外,MambaByte-353M 还优于字节级 Transformer 和 PerceiverAR。
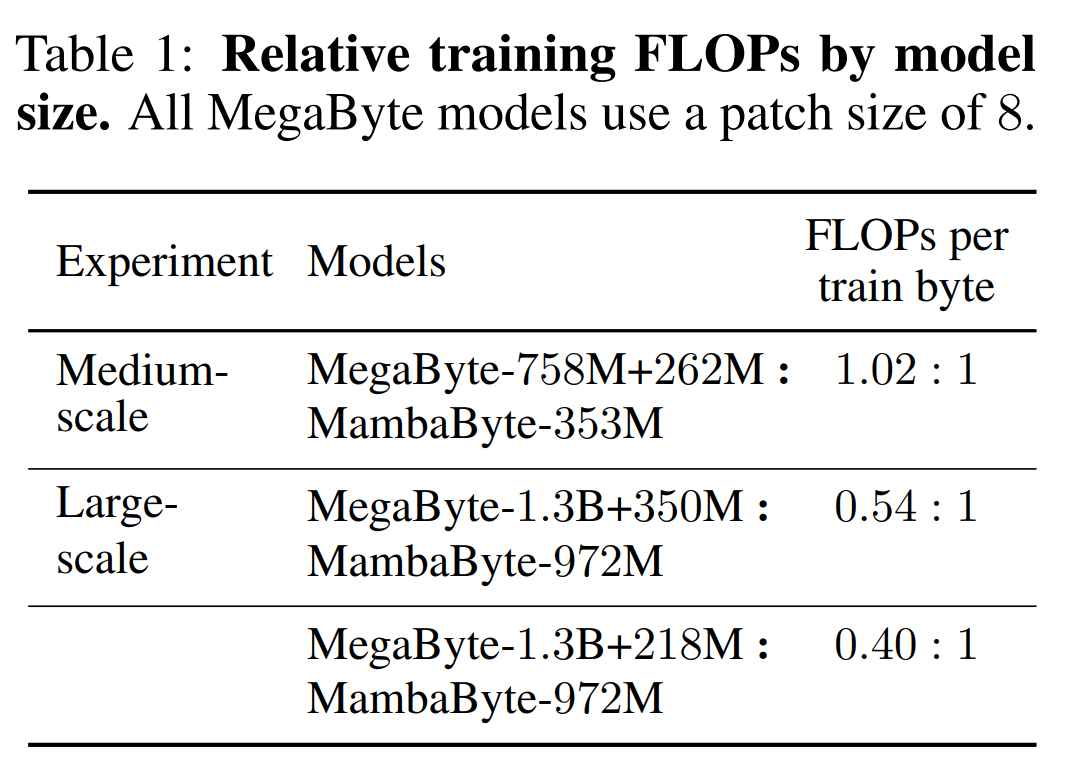
在如此少的训练步骤中,MambaByte 为什么比一个大得多的模型表现得更好?图 1 通过观察参数数量相同的模型进一步探讨了这种关系。图中显示,对于参数大小相同的 MegaByte 模型,输入 patching 较少的模型表现更好,但在计算归一化后,它们的表现类似。事实上,全长的 Transformer 虽然在绝对意义上速度较慢,但在计算归一化后,其性能也与 MegaByte 相似。相比之下,改用 Mamba 架构可以显著提高计算使用率和模型性能。
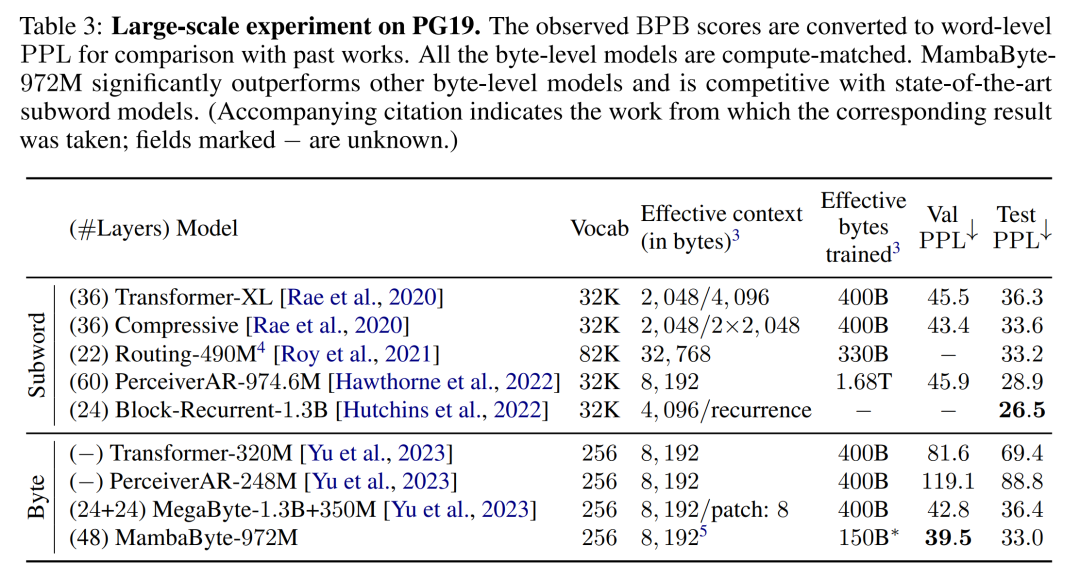
根据这些发现,表 3 比较了这些模型在 PG19 数据集上的较大版本。在这个实验中,作者将 MambaByte-972M 与 MegaByte-1.3B+350M 和其他字节级模型以及几个 SOTA 子词模型进行了比较。他们发现,MambaByte-972M 即使只训练了 150B 字节,其性能也优于所有字节级模型,并与子词模型相比具有竞争力。
文本生成。Transformer 模型中的自回归推理需要缓存整个上下文,这会大大影响生成速度。MambaByte 不存在这一瓶颈,因为它每层只保留一个随时间变化的隐藏状态,因此每生成一步的时间是恒定的。表 4 比较了 MambaByte-972M 和 MambaByte-1.6B 与 MegaByte-1.3B+350M 在 A100 80GB PCIe GPU 上的文本生成速度。虽然 MegaByte 通过 patching 大大降低了生成成本,但他们观察到 MambaByte 由于使用了循环生成,在参数相似设置下速度达到了前者的 2.6 倍。

以上是不分割成token,直接从字节中高效学习,Mamba原来还能这样用的详细内容。更多信息请关注PHP中文网其他相关文章!





















