

近期,蚂蚁集团旗下AI创新研发部门NextEvo宣布全面开源AI Infra技术,该技术能够极大地提高大型模型训练的效率。根据数据显示,该技术能够将训练时间的有效占比提高至超过95%,实现了训练过程的自动化。这一突破性的进展显着推动了AI研发的效率提升。
图:蚂蚁集团的自动化分布式深度学习系统DLRover现已全面开源
DLRover是一个专为大规模分布式训练而设计的技术框架。在当前许多企业中,训练作业常常在复杂多变的混合部署集群中运行。无论环境多么复杂,DLRover都能轻松应对,就像在崎岖的地形上行驶一样。
2023年大模型技术的快速发展催生了工程实践的爆炸式增长。如何高效管理数据、优化训练和推理效率,充分利用现有算力,成为了关键问题。
完成一个千亿参数级别的大模型,例如GPT-3,用一张卡训练一次要耗时32年。因此,在训练过程中,充分利用算力是非常重要的。为了实现这一目标,有两种方法可以采用。首先,可以进一步提高已购买GPU的性能,以充分发挥其潜力。其次,可以利用以前无法利用的算力资源,例如CPU和内存。为了实现这一点,可以通过异构计算平台来解决这个问题。
DLRover最新集成了Flash Checkpoint(FCP)方案,用于模型训练时的Checkpoint打点。传统的Checkpoint打点方式存在耗时长、高频打点降低训练可用时间、低频打点恢复时丢失过多等问题。通过应用新方案FCP,在千亿参数模型训练后,Checkpoint导致的训练浪费时间降低了约5倍,并将持久化时间降低了约70倍。这一改进将有效训练时间从90%提升至95%。这意味着DLRover的模型训练效率得到了显着的提升。
我们还集成了三项新的优化器技术进去。优化器是机器学习的核心组件,用于更新神经网络参数以最小化损失函数。其中,蚂蚁的AGD(Auto-switchable optimizer with Gradient Difference of adjacent steps)优化器在大模型预训练任务中比传统的AdamW技术加速1.5倍。 AGD已在蚂蚁内部多个场景使用并取得显着效果,相关论文已被NeurIPS '23收录。
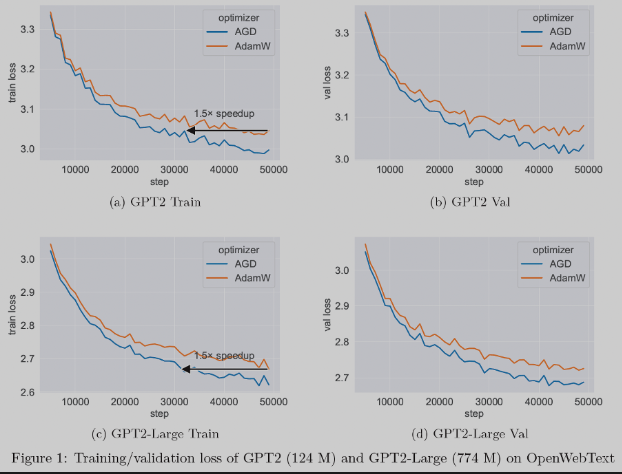
图:在大模型预训练任务中,AGD相比AdamW可以加速1.5倍
作为自动化分布式深度学习系统,DLRover的“自动驾驶”功能模块还包括:Atorch,一种PyTorch分布式训练扩展库,在千亿参数模型千卡级别规模下,训练的算力利用率可达60%,帮助开发者进一步压榨硬件算力。
DLRover以 “ML for System” 的理念来提升分布式训练的智能度,旨在通过一个系统,让开发者完全摆脱资源配置的束缚,专注于模型训练本身。在没有任何资源配置输入的情况下,DLRover 仍然可以为每个训练作业提供最佳资源配置。
据了解,蚂蚁集团在人工智能领域持续进行技术投入,最近,蚂蚁集团在内部成立了AI创新研发部门NextEvo,承担了蚂蚁AI的所有核心技术研发,包含百灵大模型的所有研发工作,涉及AI算法、AI工程、NLP、AIGC等核心技术,并在布局多模态大模型、数字人等领域的技术研发和产品创新。
同时,蚂蚁集团还加速开源节奏,填补了国内相关技术空白,推动人工智能行业快速发展。
DLRover开源地址://m.sbmmt.com/link/cf372cbe6eae54c6a6dfb3ebbcdc3404
以上是蚂蚁集团NextEvo全面开源AI Infra技术,可实现大模型训练'自动驾驶”的详细内容。更多信息请关注PHP中文网其他相关文章!





















