

强化学习算法(Reinforcement Learning, RL)的训练过程通常需要大量的与环境互动的样本数据来支持。然而,在现实世界中,收集大量交互样本往往非常昂贵,或者无法确保采样过程的安全性,例如无人机空战训练和自动驾驶训练。这个问题限制了强化学习在许多实际应用中的应用范围。因此,研究人员一直在努力探索如何在样本效率和安全性之间取得平衡,以解决这个问题。一种可能的解决方法是使用模拟器或虚拟环境来生成大量的样本数据,从而避免了实际世界中的成本和安全风险。另外,还有
为了提高强化学习算法在训练过程中的样本效率,一些研究者利用表征学习技术设计了预测未来状态信号的辅助任务。通过这种方式,算法可以从原始的环境状态中提取与未来决策相关的特征进行编码。这种方法的目的是通过学习有关环境的更多信息,提供更好的决策依据,从而改善强化学习算法的性能。这样一来,算法在训练过程中可以更高效地利用样本数据,加速学习过程,提高决策的准确性和效率。
基于这个思路,该工作设计了一种预测未来多步的状态序列频域分布的辅助任务,以捕获更长远的未来决策特征,进而提升算法的样本效率。
该工作标题为State Sequences Prediction via Fourier Transform for Representation Learning,发表于NeurIPS 2023,并被接收为Spotlight。

作者列表:叶鸣轩,匡宇飞,王杰*,杨睿,周文罡,李厚强,吴枫
论文链接:https://openreview.net/forum?id=MvoMDD6emT
代码链接:https://github.com/MIRALab-USTC/RL-SPF/
深度强化学习算法在机器人控制[1]、游戏智能[2]、组合优化[3]等领域取得了巨大的成功。但是,当前的强化学习算法仍存在「样本效率低下」的问题,即机器人需要大量与环境交互的数据才能训得性能优异的策略。
为了提高样本效率,研究人员开始关注表征学习,希望通过训练得到的表征能够从环境的原始状态中提取出丰富而有用的特征信息,从而提高机器人在状态空间中的探索效率。
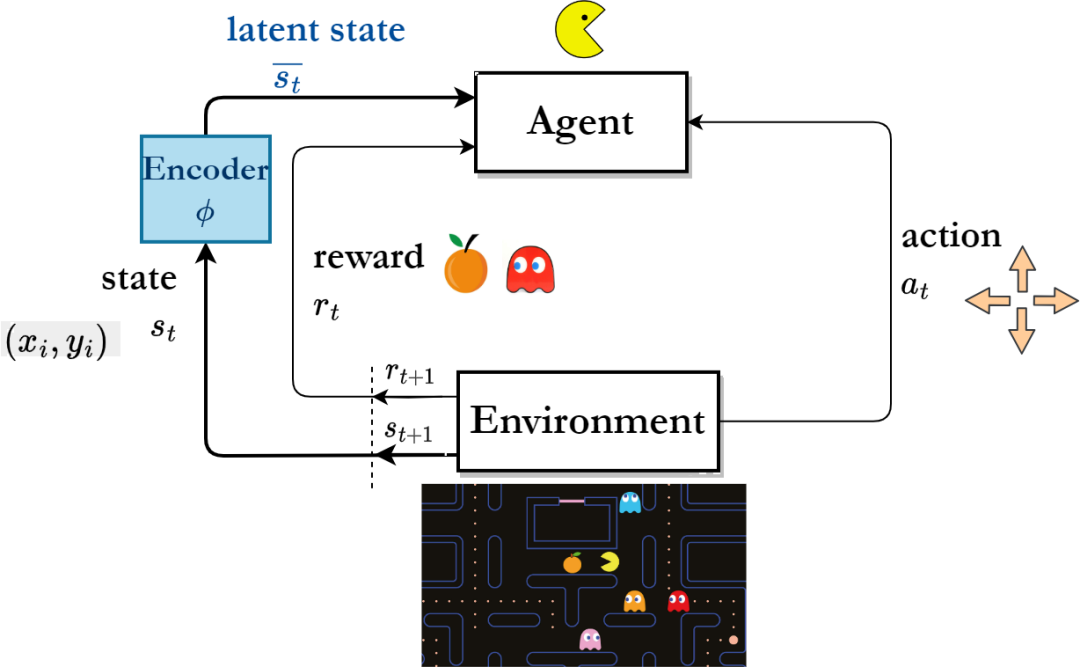
基于表征学习的强化学习算法框架
在序列决策任务中,「长期的序列信号」相对于单步信号包含更多有利于长期决策的未来信息。启发于这一观点,一些研究者提出通过预测未来多步的状态序列信号来辅助表征学习[4,5]。然而,直接预测状态序列来辅助表征学习是非常困难的。
现有的两类方法中,一类方法通过学习单步概率转移模型来逐步地产生单个时刻的未来状态,以间接预测多步的状态序列[6,7]。但是,这类方法对所训得的概率转移模型的精度要求很高,因为每步的预测误差会随预测序列长度的增加而积累。
另一类方法通过直接预测未来多步的状态序列来辅助表征学习[8],但这类方法需要存储多步的真实状态序列作为预测任务的标签,所耗存储量大。因此,如何有效从环境的状态序列中提取有利于长期决策的未来信息,进而提升连续控制机器人训练时的样本效率是需要解决的问题。
为了解决上述问题,我们提出了一种基于状态序列频域预测的表征学习方法(State Sequences Prediction via Fourier Transform, SPF),其思想是利用「状态序列的频域分布」来显式提取状态序列数据中的趋势性和规律性信息,从而辅助表征高效地提取到长期未来信息。
我们从理论上证明了状态序列存在「两种结构性信息」,一是与策略性能相关的趋势性信息,二是与状态周期性相关的规律性信息。
在具体分析两种结构性信息之前,我们先介绍产生状态序列的马尔科夫决策过程(Markov Decision Processes,MDP)的相关定义。
我们考虑连续控制问题中的经典马尔可夫决策过程,该过程可用五元组 表示。其中, 为相应的状态、动作空间, 为奖励函数, 为环境的状态转移函数, 为状态的初始分布, 为折扣因子。此外,我们用 表示策略在状态 下的动作分布。
我们将 时刻下智能体所处的状态记为 ,所选择的动作记为 .智能体做出动作后,环境转移到下一时刻状态 并反馈给智能体奖励 。我们将智能体与环境交互过程中所得到状态、动作对应的轨迹记为 ,轨迹服从分布 。
强化学习算法的目标是最大化未来预期的累积回报,我们用 表示当前策略 和 环境模型 下的平均累积回报,并简写为 ,定义如下:
显示了当前策略 的性能表现。
下面我们介绍状态序列的「第一种结构性特征」,其涉及状态序列和对应奖励序列之间的依赖关系,能显示出当前策略的性能趋势。
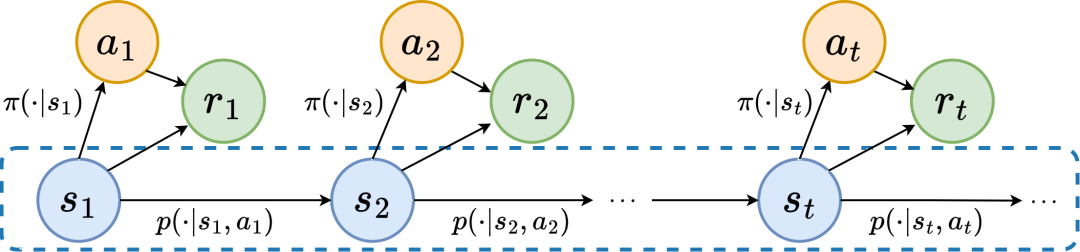
在强化学习任务中,未来的状态序列很大程度上决定了智能体未来采取的动作序列,并进一步决定了相应的奖励序列。因此,未来的状态序列不仅包含环境固有的概率转移函数的信息,也能辅助表征捕获反映当前策略的走向趋势。
启发于上述结构,我们证明了以下定理,进一步论证了这一结构性依赖关系的存在:
定理一:若奖励函数只与状态有关,那么对于任意两个策略 和 ,他们的性能差异可以被这两个策略所产生的状态序列分布差异所控制:
上述公式中, 表示在指定策略和转移概率函数条件下状态序列的概率分布, 表示 范数。
上述定理表明,两个策略的性能差异越大,其对应的两个状态序列的分布差异也越大。这意味着好策略和坏策略会产生出两个差异较大的状态序列,这进一步说明状态序列所包含的长期结构性信息能潜在影响搜索性能优异的策略的效率。
另一方面,在一定条件下,状态序列的频域分布差异也能为对应的策略性能差异提供上界,具体如以下定理所示:
定理二:若状态空间有限维且奖励函数是与状态有关的n次多项式,那么对于任意两个策略 和 ,他们的性能差异可以被这两个策略所产生的状态序列的频域分布差异所控制:
上述公式中, 表示由策略 所产生的状态序列的 次方序列的傅里叶函数, 表示傅里叶函数的第 个分量。
这一定理表明状态序列的频域分布仍包含与当前策略性能相关的特征。
下面我们介绍状态序列中存在的「第二种结构性特征」,其涉及到状态信号之间的时间依赖性,即一段较长时期内状态序列所表现出的规律性模式。
在许多的真实场景任务中,智能体也会表现出周期性行为,因为其环境的状态转移函数本身就是具有周期性的。以工业装配机器人为例,该机器人的训练目标是将零件组装在一起以创造最终产品,当策略训练达到稳定时,它就会执行一个周期性的动作序列,使其能够有效地将零件组装在一起。
启发于上面的例子,我们提供了一些理论分析,证明了有限状态空间中,当转移概率矩阵满足某些假设,对应的状态序列在智能体达到稳定策略时可能表现出「渐近周期性」,具体定理如下:
定理三:对于状态转移矩阵为 的有限维状态空间 ,假设 有 个循环类,对应的状态转移子矩阵为 。设这 个矩阵模为1的特征值个数为 ,则对于任意状态的初始分布 ,状态分布 呈现出周期为 的渐进周期性。
在MuJoCo任务中,策略训练达到稳定时,智能体也会表现出周期性的运动。下图中给出了MuJoCo任务中HalfCheetah智能体在一段时间内的状态序列示例,可以观察到明显的周期性。(更多MuJoCo任务中带周期性的状态序列示例可参考本论文附录第E节)
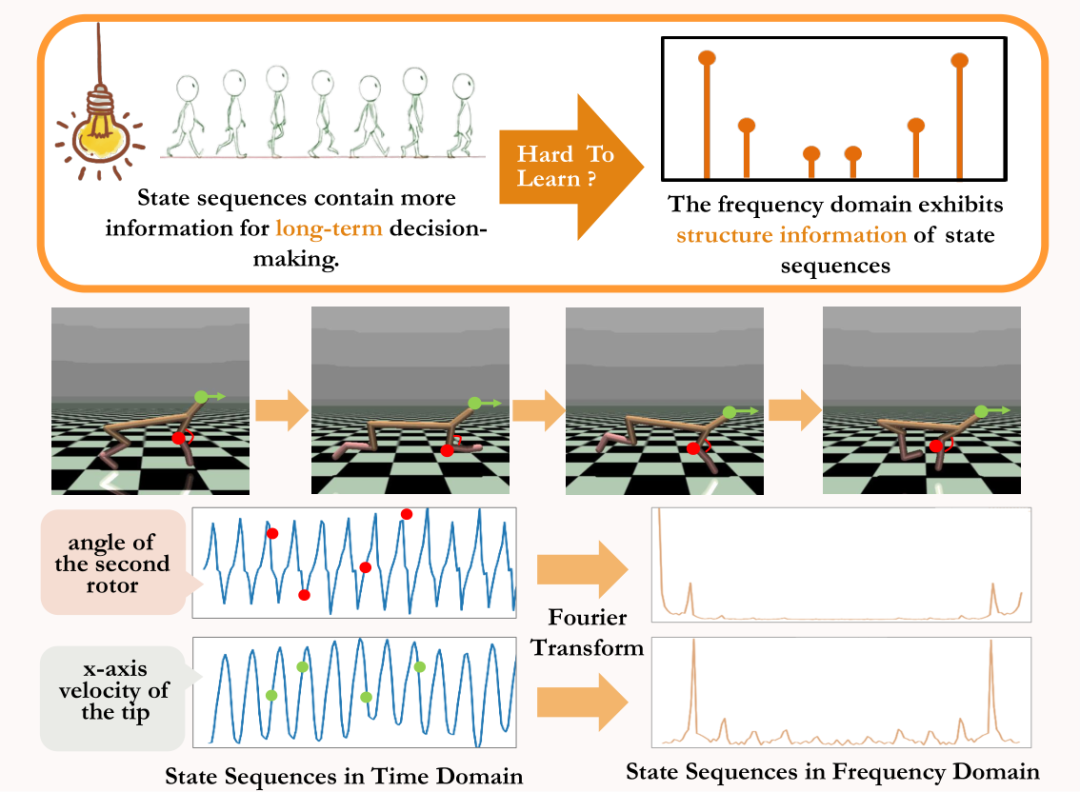
MuJoCo任务中HalfCheetah智能体在一段时间内状态所表现出的周期性
时间序列在时域中呈现的信息相对分散,但在频域中,序列中的规律性信息以更加集中的形式呈现。通过分析频域中的频率分量,我们能显式地捕获到状态序列中存在的周期性特征。
上一部分中,我们从理论上证明状态序列的频域分布能反映策略性能的好坏,并且通过在频域上分析频率分量我们能显式捕获到状态序列中的周期性特征。
启发于上述分析,我们设计了「预测无穷步未来状态序列傅里叶变换」的辅助任务来鼓励表征提取状态序列中的结构性信息。
下面介绍我们关于该辅助任务的建模。给定当前状态 和动作 ,我们定义未来的状态序列期望如下:
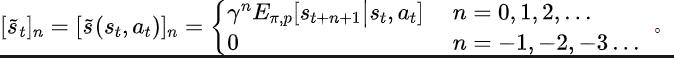
我们的辅助任务训练表征去预测上述状态序列期望的离散时间傅里叶变换(discrete-time Fourier transform, DTFT),即
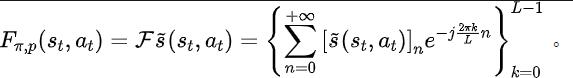
上述傅里叶变换公式可改写为如下的递归形式:
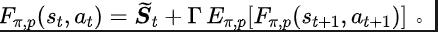
其中,
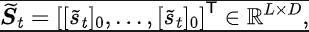

其中, 为状态空间的维度, 为所预测的状态序列傅里叶函数的离散化点的个数。
启发于Q-learning中优化Q值网络的TD-error损失函数[9],我们设计了如下的损失函数:
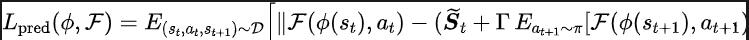
其中, 和 分别为损失函数要优化的表征编码器(encoder)和傅里叶函数预测器(predictor)的神经网络参数, 为存储样本数据的经验池。
进一步地,我们可以证明上述的递归公式可以表示为一个压缩映射:
定理四:令 表示函数族 ,并定义 上的范数为:
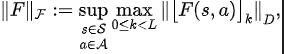
其中 表示矩阵 的第 行向量。我们定义映射 为
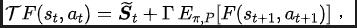
则可以证明 为一个压缩映射。
根据压缩映射原理,我们可以迭代地使用算子 ,使得 逼近真实状态序列的频域分布,且在表格型情况(tabular setting)下有收敛性保证。
此外,我们所设计的损失函数只依赖于当前时刻与下一时刻的状态,所以无需存储未来多步的状态数据作为预测标签,具有「实施简单且存储量低」的优点。
下面我们介绍本论文方法(SPF)的算法框架。
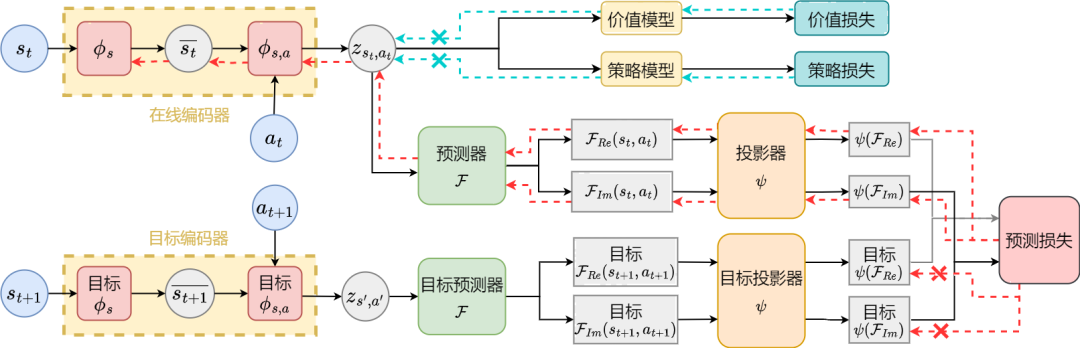 基于状态序列频域预测的表征学习方法(SPF)的算法框架图
基于状态序列频域预测的表征学习方法(SPF)的算法框架图
我们将当前时刻和下一时刻的状态-动作数据分别输入到在线(online)和目标(target)表征编码器(encoder)中,得到状态-动作表征数据,然后将该表征数据输入到傅里叶函数预测器(predictor)得到当前时刻和下一时刻下的两组状态序列傅里叶函数预测值。通过代入这两组傅里叶函数预测值,我们能计算出损失函数值。
我们通过最小化损失函数来优化更新表征编码器 和傅里叶函数预测器 ,使预测器的输出能逼近真实状态序列的傅里叶变换,从而鼓励表征编码器提取出包含未来长期状态序列的结构性信息的特征。
我们将原始状态和动作输入到表征编码器中,将得到的特征作为强化学习算法中actor网络和critic网络的输入,并用经典强化学习算法优化actor网络和critic网络。
实验结果
(注:本节仅选取部分实验结果,更详细的结果请参考论文原文第6节及附录。)
我们将 SPF 方法在 MuJoCo 仿真机器人控制环境上测试,对如下 6 种方法进行对比:
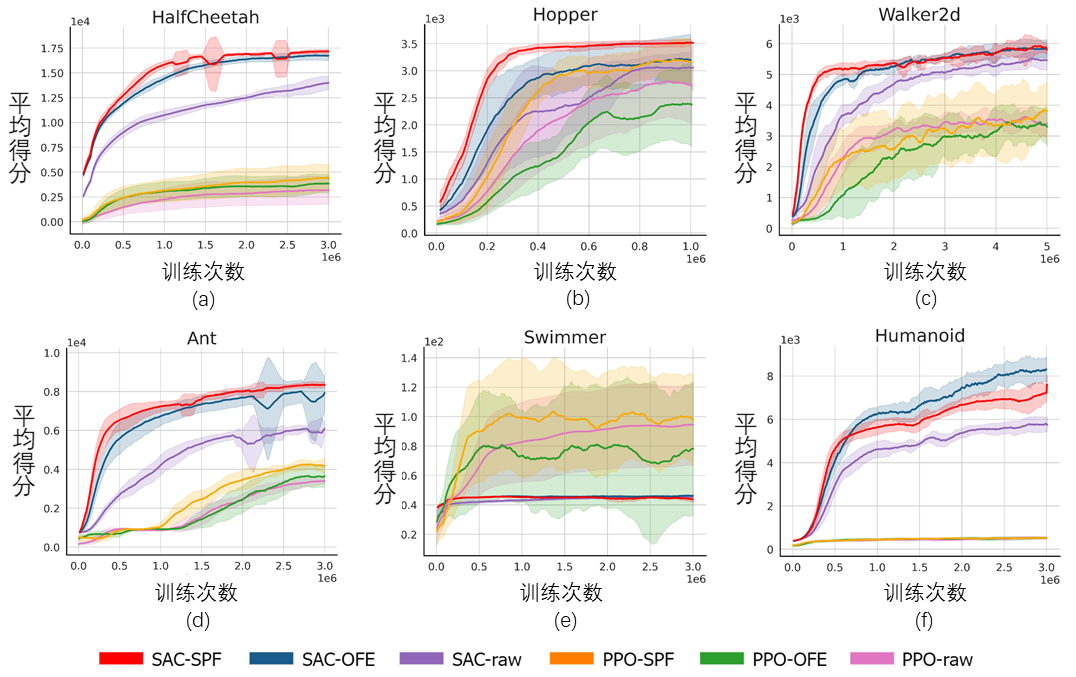
基于6种MuJoCo任务的对比实验结果
上图显示了在 6 种 MuJoCo 任务中,我们所提出的SPF方法(红线及橙线)与其他对比方法的性能曲线。结果显示,我们所提出的方法相比于其他方法能获得19.5%的性能提升。
我们对 SPF 方法的各个模块进行了消融实验,将本方法与不使用投影器模块(noproj)、不使用目标网络模块(notarg)、改变预测损失(nofreqloss)、改变特征编码器网络结构(mlp,mlp_cat)时的性能表现做比较。
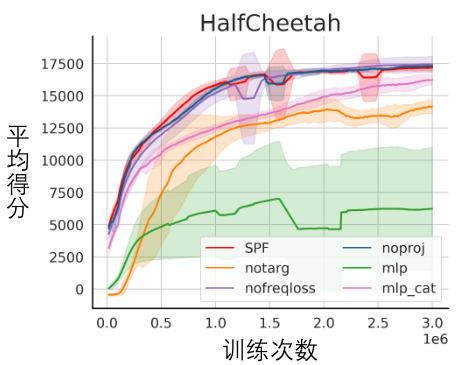
SPF方法应用于SAC算法的消融实验结果图,测试于HalfCheetah任务
我们使用 SPF 方法所训练好的预测器输出状态序列的傅里叶函数,并通过逆傅里叶变换恢复出的200步状态序列,与真实的200步状态序列进行对比。
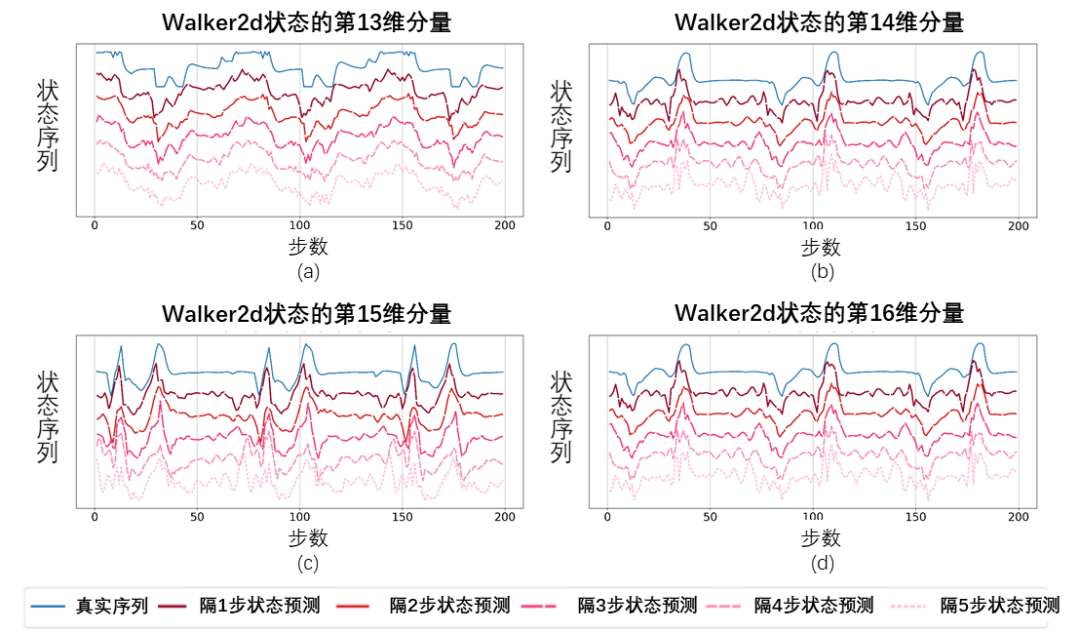 基于傅里叶函数预测值恢复出的状态序列示意图,测试于Walker2d任务。其中,蓝线为真实的状态序列示意图,5条红线为恢复出的状态序列示意图,越下方的、颜色越浅的红线表示利用越久远的历史状态所恢复出的状态序列。
基于傅里叶函数预测值恢复出的状态序列示意图,测试于Walker2d任务。其中,蓝线为真实的状态序列示意图,5条红线为恢复出的状态序列示意图,越下方的、颜色越浅的红线表示利用越久远的历史状态所恢复出的状态序列。
结果显示,即使用更久远的状态作为输入,恢复出的状态序列也和真实的状态序列非常相似,这说明 SPF 方法所学习出的表征能有效编码出状态序列中包含的结构性信息。
以上是中科大开发「状态序列频域预测」方法,性能提升20%,样本效率达到最大的详细内容。更多信息请关注PHP中文网其他相关文章!





















